前言
排序是数据库中的一个基本功能,MySQL也不例外。通过Order by语句即能达到将指定的结果集排序的目的,
其实不仅仅是Order by语句,Group by语句,Distinct语句都会隐含使用排序
在实际业务场景中,一些开发的大牛动不动来个orderby,SQL看起写的非常溜,而实际业务应用导致GAME OVER......
首先介绍MySQL实现排序的内部原理,并介绍与排序相关的参数,最后结合实际给出几个"奇怪"排序,来谈谈排序一致问题
1、排序实现的算法:
对于不能利用索引避免排序的 SQL,数据库不得不自己排序功能以满足业务需求,执行计划中会出现"USING TEMPORARY; USING filesort",
有时候filesore并不意味着就是文件排序也有可能是内存排序,只有由参数sort_buffer_size和结果集大小确定。
MySQL内部排序主要有3种方式:常规排序、优化排序和优先队列排序,假设表结构如下:
CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`col1` varchar(64) COLLATE utf8mb4_unicode_ci NOT NULL,
`col2` varchar(64) COLLATE utf8mb4_unicode_ci NOT NULL,
`col3` varchar(64) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `col1` (`col1`,`col2`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
SELECT col1,col2,col3 FROM t1 WHERE col1="100" ORDER BY col2;
a.常规排序
(1).从表t1中获取满足WHERE条件的记录
(2).对于每条记录,将记录的主键+排序键(id,col2)取出放入sort buffer
(3).如果sort buffer可以存放所有满足条件的(id,col2)对,则进行排序;否则sort buffer满后,进行排序并固化到临时文件中。(排序算法采用的是快速排序算法)
(4).若排序中产生了临时文件,需要利用归并排序算法,保证临时文件中记录是有序的
(5).循环执行上述过程,直到所有满足条件的记录全部参与排序
(6).扫描排好序的(id,col2)对,并利用id去捞取SELECT需要返回的列(col1,col2,col3)
(7).将获取的结果集返回
从上述流程来看,是否使用文件排序主要看sort buffer是否能容下需要排序的(id,col2)对,这个buffer的大小由sort_buffer_size参数控制。此外一次排序需要两次IO,一次是捞(id,col2),第二次是捞(col1,col2,col3),由于返回的结果集是按col2排序,因此id是乱序的,通过乱序的id去捞(col1,col2,col3)时会产生大量的随机IO。对于第二次MySQL本身一个优化,
即在捞之前首先将id排序,并放入缓冲区,这个缓存区大小由参数read_rnd_buffer_size控制,然后有序去捞记录,将随机IO转为顺序IO
b.优化排序
常规排序方式除了排序本身,还需要额外两次IO。优化的排序方式相对于常规排序,减少了第二次IO。主要区别在于,放入sort buffer不是(id,col2),而是(col1,col2,col3)。由于sort buffer中包含了查询需要的所有字段,因此排序完成后可以直接返回,无需二次捞数据。这种方式的代价在于,同样大小的sort buffer,能存放的(col1,col2,col3)数目要小于(id,col2),如果sort buffer不够大,可能导致需要写临时文件,造成额外的IO。当然MySQL提供了参数max_length_for_sort_data,
只有当排序元组小于max_length_for_sort_data时,才能利用优化排序方式,否则只能用常规排序方式
c.优先队列排序
为了得到最终的排序结果,无论怎样,我们都需要将所有满足条件的记录进行排序才能返回。那么相对于优化排序方式,
在空间层面做了优化黑盒加入了一种新的排序方式--优先队列,这种方式采用堆排序实现,堆排序算法特征正好可以解limit M,N 这类排序的问题,虽然仍然需要所有元素参与排序,但是只需要M+N个元组的sort buffer空间即可,对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。
对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素
2、排序优化与索引使用
为了优化SQL语句的排序性能,最好的情况是避免排序,合理利用索引是一个不错的方法。
因为索引本身也是有序的,如果在需要排序的字段上面建立了合适的索引,那么就可以跳过排序的过程,提高SQL的查询速度,\
通过一些典型SQL说明哪些可以利用索引减少排序,哪些不能,
1、select * from t1 order by col1,col2
2、select * from t1 where col1="100" order by col2
3、select *from t1 col1>"100" order by col1 asc
4、select * from t1 where col1="100" and col2>"100" order by col2
3、不能利用索引避免排序
通过索引扫描的记录数超过30%,变全表扫描
联合索引中,第一索引列使用范围查询
联合索引中,第一查询条件不是最左索引列
升降序不一致无法使用
排序字段在多个索引中无法使用(一个联合索引一个单列索引,一条SQL一次只能使用一个索引)
排序字段是单独的列无法使用索引
4、业务案例,添加合理的索引
1、业务DDL:
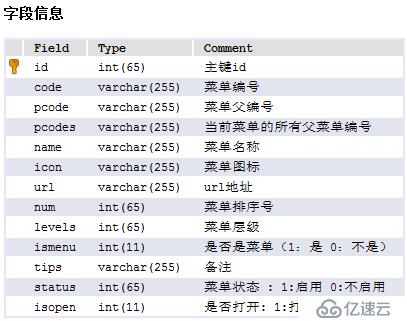
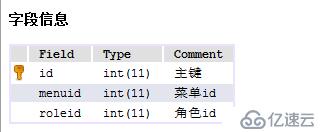
2、对原SQL执行计划的查看:
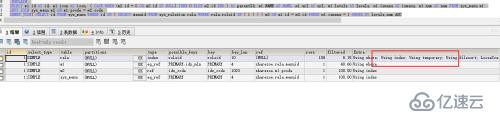
3、优化后的SQL执行计划-1
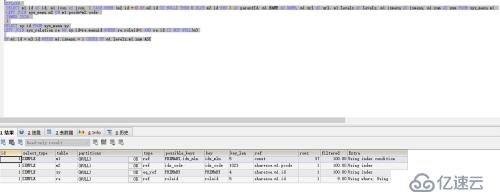
3、优化后的SQL执行计划-2
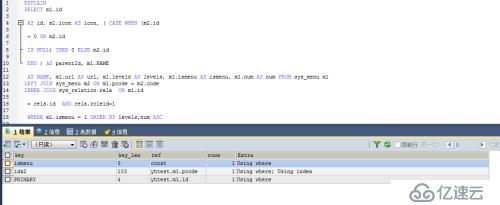
主要对原SQL进行改写以及添加相应的索引,即可实现SQL优化,运行效率的最优。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





