本篇文章给大家分享的是有关sed语句如何在shell脚本中使用,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
sed在处理文本时是逐行读取文件内容,读到匹配的行就根据指令做操作,不匹配就跳过。
sed是Linux下一款功能强大的非交互流式文本编辑器,可以对文本文件进行增、删、改、查等操作,支持按行、按字段、按正则匹配文本内容,灵活方便,特别适合于大文件的编辑。本文主要介绍sed的一些基本用法,并通过shell脚本演示sed的使用实例。
一.在命令行指定sed指令对文本进行处理:sed +选项 ‘指令' 文件
二.先将sed指令保存到文件中,将该文件作为参数进行调用:sed +选项 -f 包含sed指令的文件 文件
-r:使用扩展正则表达式
-e:它告诉sed将下一个参数解释为一个sed指令,只有当命令行上给出多个sed指令时才需要使用-e选项
-f:后跟保存了sed指令的文件
-i:直接对内容进行修改,不加-i时默认只是预览,不会对文件做实际修改
-n:取消默认输出,sed默认会输出所有文本内容,使用-n参数后只显示处理过的行
a:追加 向匹配行后面插入内容
c:更改 更改匹配行的内容
i:插入 向匹配行前插入内容
d:删除 删除匹配的内容
s:替换 替换掉匹配的内容
p:打印 打印出匹配的内容,通常与-n选项和用
=:用来打印被匹配的行的行号
n:读取下一行,遇到n时会自动跳入下一行
r,w:读和写编辑命令,r用于将内容读入文件,w用于将匹配内容写入到文件
sed '3ahello' 1.txt #向第三行后面添加hello,3表示行号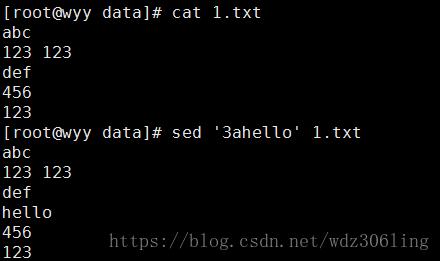
sed '/123/ahello' 1.txt #向内容123后面添加hello,如果文件中有多行包括123,则每一行后面都会添加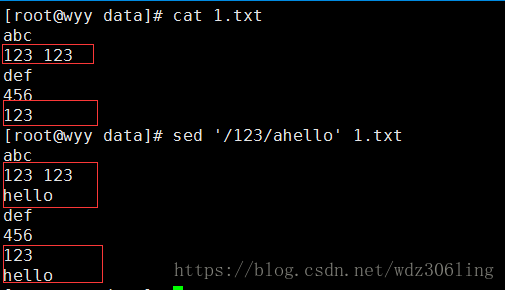
sed '$ahello' 1.txt #在最后一行添加hello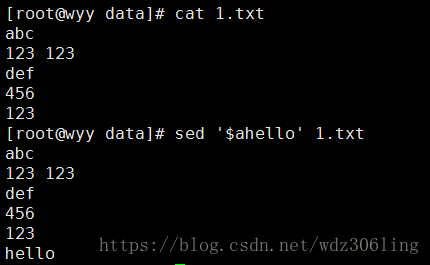
sed '3ihello' 1.txt #在第三行之前插入hello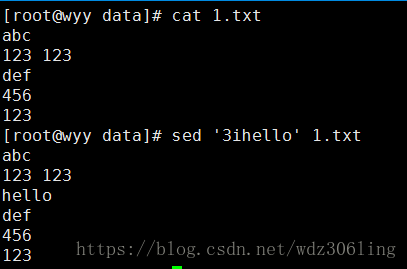
sed '/123/ihello' 1.txt #在包含123的行之前插入hello,如果有多行包含123,则包含123的每一行之前都会插入hello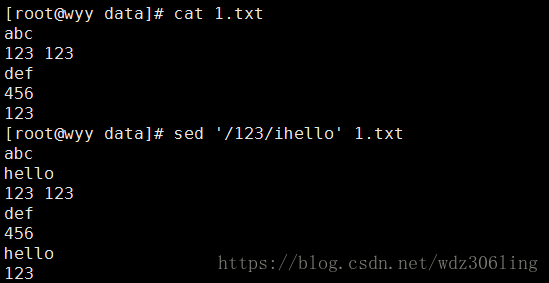
sed '$ihello' 1.txt #在最后一行之前插入hello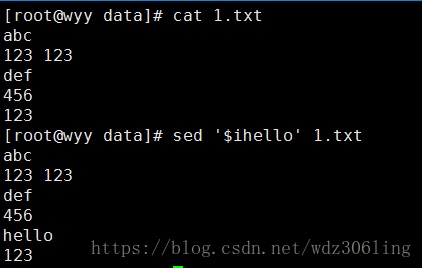
sed '1chello' 1.txt #将文件1.txt的第一行替换为hello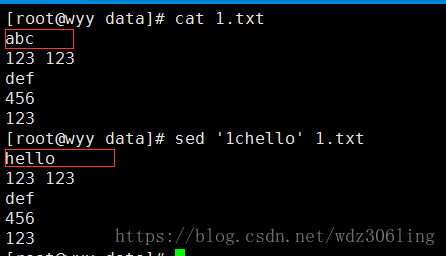
sed '/123/chello' 1.txt #将包含123的行替换为hello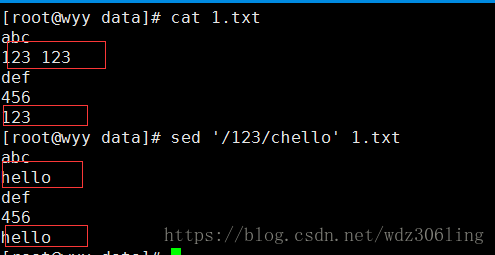
sed '$chello' 1.txt #将最后一行替换为hello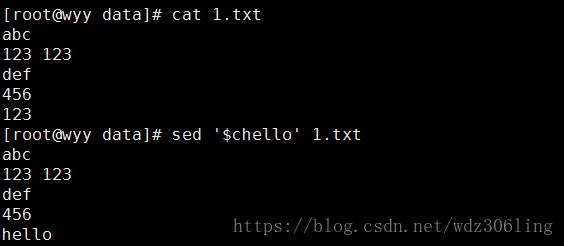
sed '4d' 1.txt #删除第四行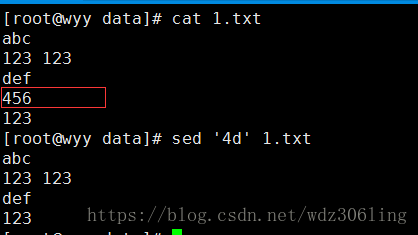
sed '1~2d' 1.txt #从第一行开始删除,每隔2行就删掉一行,即删除奇数行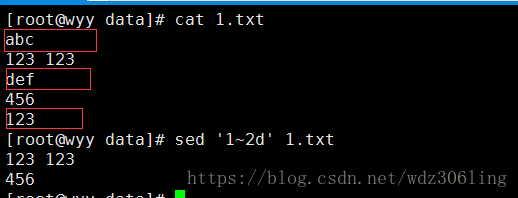
sed '1,2d' 1.txt #删除1~2行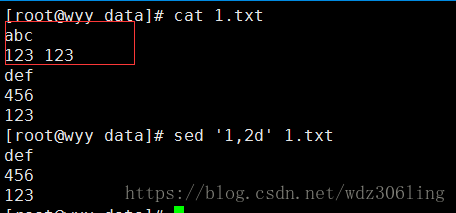
sed '1,2!d' 1.txt #删除1~2之外的所有行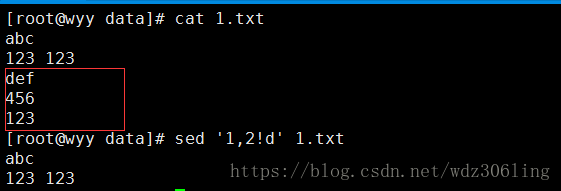
sed '$d' 1.txt #删除最后一行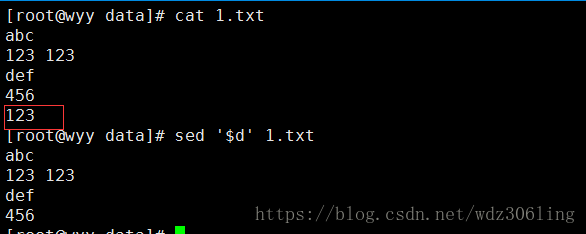
sed '/123/d' 1.txt #删除匹配123的行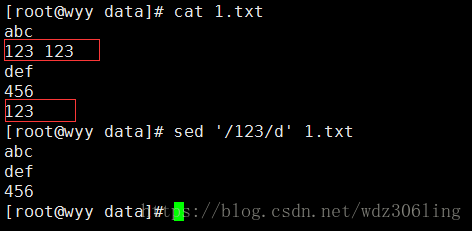
sed '/123/,$d' 1.txt #删除从匹配123的行到最后一行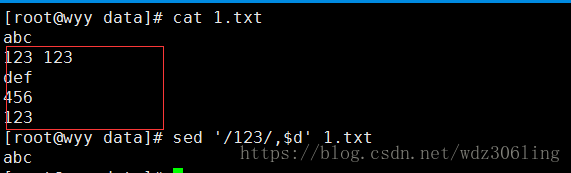
sed '/123/,+1d' 1.txt #删除匹配123的行及其后面一行
sed '/^$/d' 1.txt #删除空行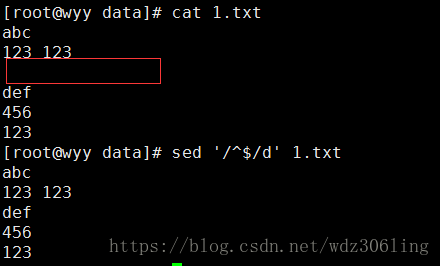
sed '/123\|abc/!d' 1.txt #删除不匹配123或abc的行,/123\|abc/ 表示匹配123或abc ,!表示取反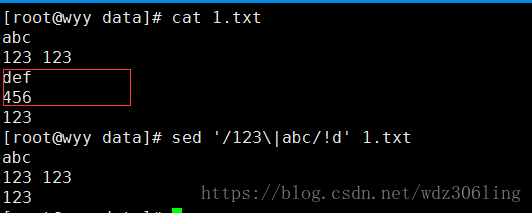
sed '1,3{/123/d}' 1.txt #删除1~3行中,匹配内容123的行,1,3表示匹配1~3行,{/123/d}表示删除匹配123的行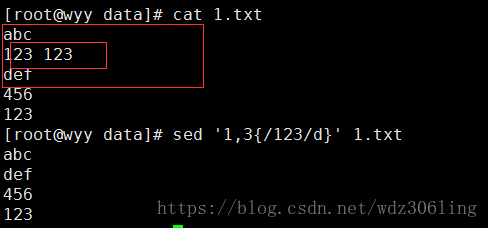
sed 's/123/hello/' 1.txt #将文件中的123替换为hello,默认只替换每行第一个123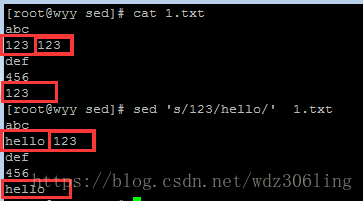
sed 's/123/hello/g' 1.txt #将文本中所有的123都替换为hello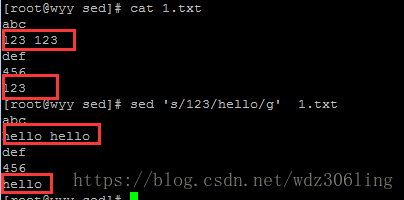
sed 's/123/hello/2' 1.txt #将每行中第二个匹配的123替换为hello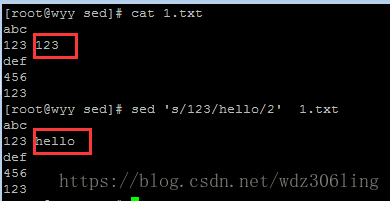
sed -n 's/123/hello/gpw 2.txt' 1.txt #将每行中所有匹配的123替换为hello,并将替换后的内容写入2.txt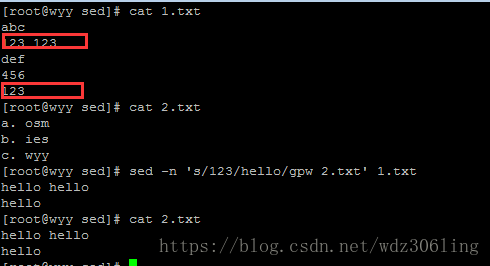
sed '/#/s/,.*//g' 1.txt #匹配有#号的行,替换匹配行中逗号后的所有内容为空 (,.*)表示逗号后的所又内容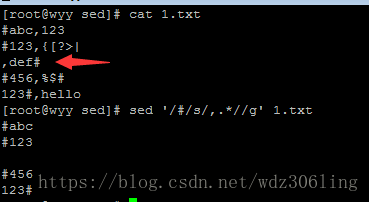
sed 's/..$//g' 1.txt #替换每行中的最后两个字符为空,每个点代表一个字符,$表示匹配末尾 (..$)表示匹配最后两个字符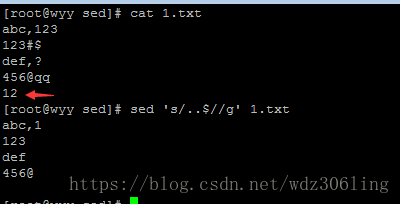
sed 's/^#.*//' 1.txt #将1.txt文件中以#开头的行替换为空行,即注释的行 ( ^#)表示匹配以#开头,(.*)代表所有内容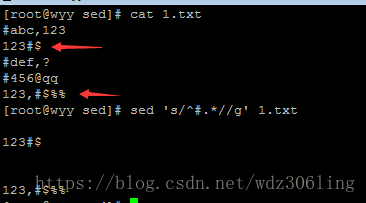
sed 's/^#.*//;/^$/d' 1.txt #先替换1.txt文件中所有注释的空行为空行,然后删除空行,替换和删除操作中间用分号隔开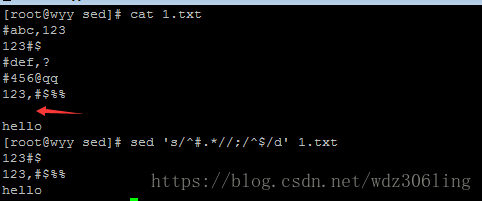
sed 's/^[0-9]/(&)/' 1.txt #将每一行中行首的数字加上一个小括号 (^[0-9])表示行首是数字,&符号代表匹配的内容
#或者
sed 's/\(^[0-9]\)/(\1)/' 1.txt #替换左侧特殊字符需钥转义,右侧不需要转义,\1代表匹配的内容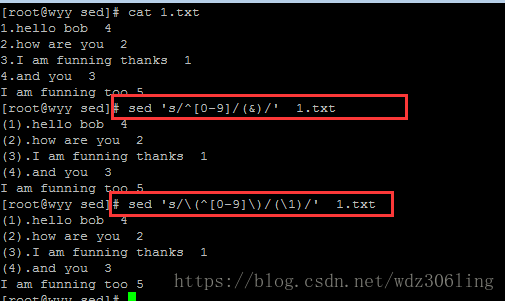
sed 's/$/&'haha'/' 1.txt # 在1.txt文件的每一行后面加上"haha"字段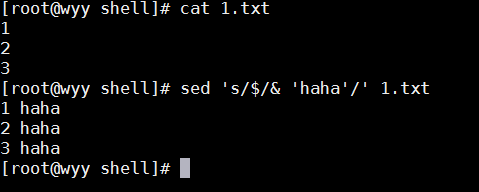
sed -n '3p' 1.txt #打印文件中的第三行内容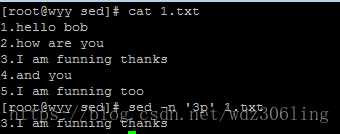
sed -n '2~2p' 1.txt #从第二行开始,每隔两行打印一行,波浪号后面的2表示步长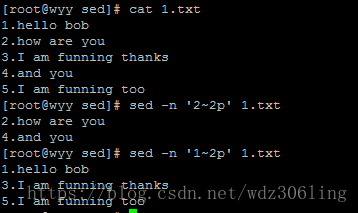
sed -n '$p' 1.txt #打印文件的最后一行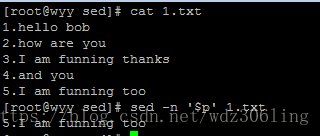
sed -n '1,3p' 1.txt #打印1到3行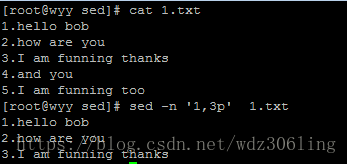
sed -n '3,$p' 1.txt #打印从第3行到最后一行的内容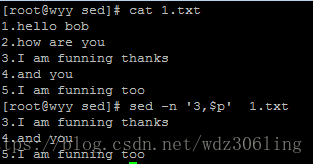
sed -n '/you/p' 1.txt #逐行读取文件,打印匹配you的行
sed -n '/bob/,3p' 1.txt #逐行读取文件,打印从匹配bob的行到第3行的内容
sed -n '/you/,3p' 1.txt #打印匹配you 的行到第3行,也打印后面所有匹配you 的行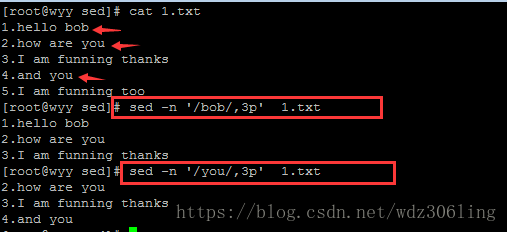
sed -n '1,/too/p' 1.txt #打印第一行到匹配too的行
sed -n '3,/you/p' 1.txt #只打印第三行到匹配you的行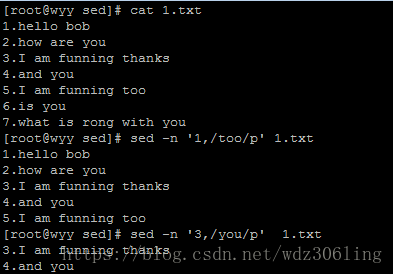
sed -n '/too/,$p' 1.txt #打印从匹配too的行到最后一行的内容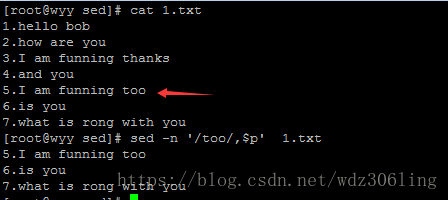
sed -n '/too/,+1p' 1.txt #打印匹配too的行及其向后一行,如果有多行匹配too,则匹配的每一行都会向后多打印一行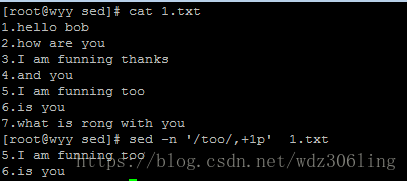
sed -n '/bob/,/too/p' 1.txt #打印从匹配内容bob到匹配内容too的行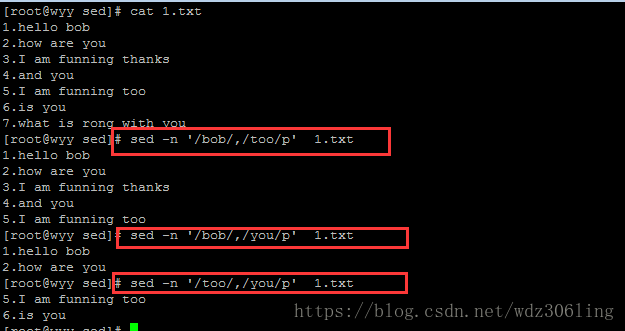
sed -n "$=" 1.txt #打印1.txt文件最后一行的行号(即文件有多少行,和wc -l 功能类似)
sed -n '/error/=' 1.txt #打印匹配error的行的行号
sed -n '/error/{=;p}' 1.txt #打印匹配error的行的行号和内容(可用于查看日志中有error的行及其内容)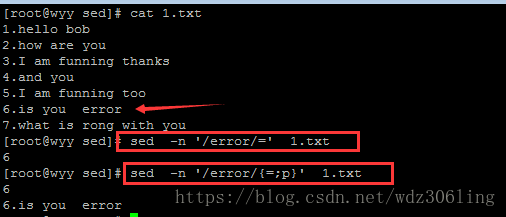
sed 'r 2.txt' 1.txt #将文件2.txt中的内容,读入1.txt中,会在1.txt中的每一行后都读入2.txt的内容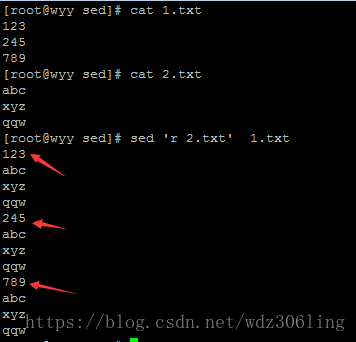
sed '3r 2.txt' 1.txt #在1.txt的第3行之后插入文件2.txt的内容(可用于向文件中插入内容)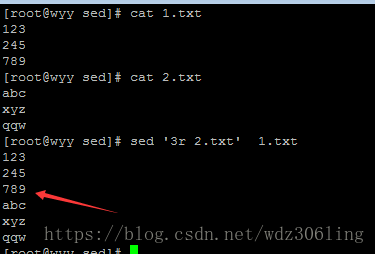
sed '/245/r 2.txt' 1.txt #在匹配245的行之后插入文件2.txt的内容,如果1.txt中有多行匹配456则在每一行之后都会插入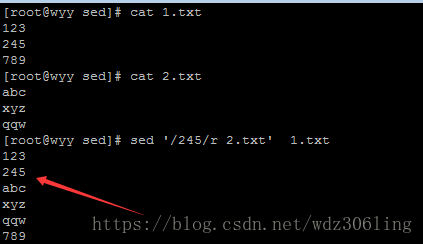
sed '$r 2.txt' 1.txt #在1.txt的最后一行插入2.txt的内容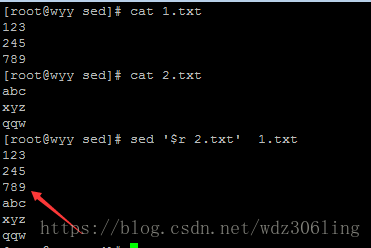
sed -n 'w 2.txt' 1.txt #将1.txt文件的内容写入2.txt文件,如果2.txt文件不存在则创建,如果2.txt存在则覆盖之前的内容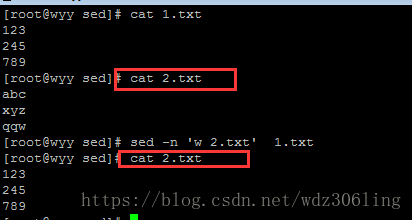
sed -n '2w 2.txt' 1.txt #将文件1.txt中的第2行内容写入到文件2.txt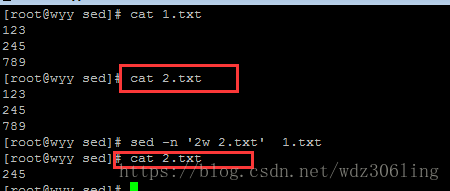
sed -n -e '1w 2.txt' -e '$w 2.txt' 1.txt #将1.txt的第1行和最后一行内容写入2.txt
sed -n -e '1w 2.txt' -e '$w 3.txt' 1.txt #将1.txt的第1行和最后一行分别写入2.txt和3.txt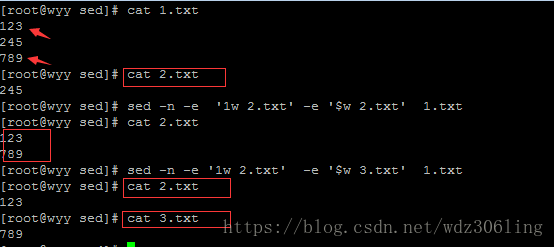
sed -n '/abc\|123/w 2.txt' 1.txt #将1.txt中匹配abc或123的行的内容,写入到2.txt中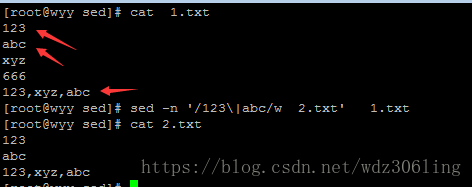
sed -n '/666/,$w 2.txt' 1.txt #将1.txt中从匹配666的行到最后一行的内容,写入到2.txt中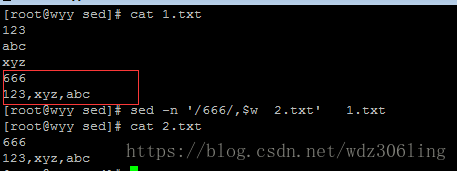
sed -n '/xyz/,+2w 2.txt' 1.txt #将1.txt中从匹配xyz的行及其后2行的内容,写入到2.txt中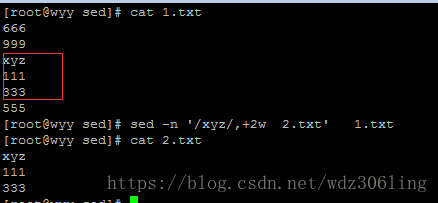
实例1:替换文件中的内容
#!/bin/bash
if [ $# -ne 3 ];then #判断参数个数
echo "Usage: $0 old-part new-part filename" #输出脚本用法
exit
fi
sed -i "s#$1#$2#" $3 #将 旧内容进行替换,当$1和$2中包含"/"时,替换指令中的定界符需要更换为其他符号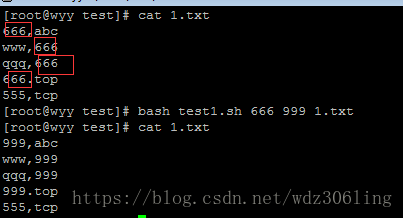
实例2:删除文件中的空白行
#!/bin/bash
if [ ! -f $1 ];then #判断参数是否为文件且存在
echo "$0 is not a file"
exit
fi
sed -i "/^$/d" $1 #将空白行删除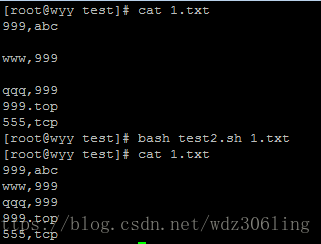
实例3:格式化文本内容
#!/bin/bash
a='s/^ *>// #定义一个变量a保存sed指令,'s/^ *>//':表示匹配以0个或多空格开头紧跟一个'>'号的行,将匹配内容替换
s/\t*// #'s/\t*//':表示匹配以0个或多个制表符开头的行,将匹配内容替换
s/^>// #'s/^>//' :表示匹配以'>'开头的行,将匹配内容替换
s/^ *//' #'s/^ *//':表示匹配以0个或多个空格开头的行,将匹配内容替换
#echo $a
sed "$a" $1 #对用户给定的文本文件进行格式化处理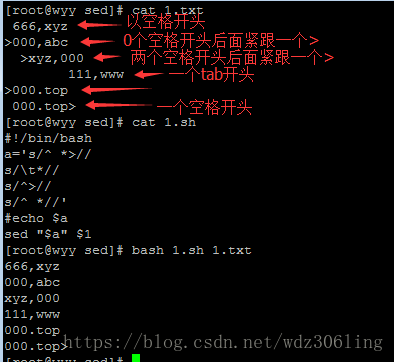
实用脚本:批量更改当前目录中的文件后缀名:
示例1:
#!/bin/bash
if [ $# -ne 2 ];then #判断用户的输入,如果参数个数不为2则打印脚本用法
echo "Usage:$0 + old-file new-file"
exit
fi
for i in *$1* #对包含用户给定参数的文件进行遍历
do
if [ -f $i ];then
iname=`basename $i` #获取文件名
newname=`echo $iname | sed -e "s/$1/$2/g"` #对文件名进行替换并赋值给新的变量
mv $iname $newname #对文件进行重命名
fi
done
exit 666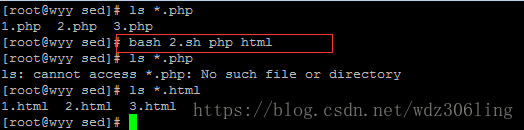
示例2:
#!/bin/bash
read -p "input the old file:" old #提示用户输入要替换的文件后缀
read -p "input the new file:" new
[ -z $old ] || [ -z $new ] && echo "error" && exit #判断用户是否有输入,如果没有输入怎打印error并退出
for file in `ls *.$old`
do
if [ -f $file ];then
newfile=${file%$old} #对文件进行去尾
mv $file ${newfile}$new #文件重命名
fi
done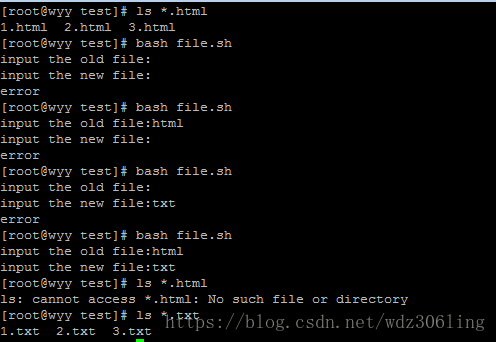
示例3:
#!/bin/bash
if [ $# -ne 2 ];then #判断位置变量的个数是是否为2
echo "Usage:$0 old-file new-file"
exit
fi
for file in `ls` #在当前目录中遍历文件
do
if [[ $file =~ $1$ ]];then #对用户给出的位置变量$1进行正则匹配,$1$表示匹配以变量$1的值为结尾的文件
echo $file #将匹配项输出到屏幕进行确认
new=${file%$1} #对文件进行去尾处理,去掉文件后缀保留文件名,并将文件名赋给变量new
mv $file ${new}$2 #将匹配文件重命名为:文件名+新的后缀名
fi
done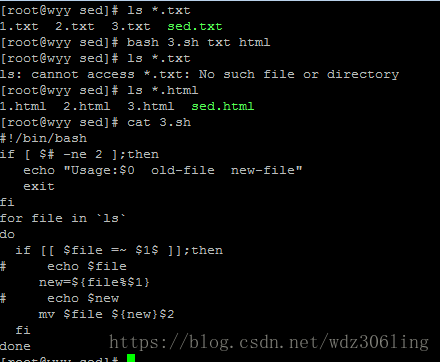
示例4:使用sed匹配文件中的IP地址
sed -nr '/([0-9]{1,3}\.){3}([0-9]{1,3})/p' 1.txt以上就是sed语句如何在shell脚本中使用,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



