phpеҰӮдҪ•е®һзҺ°зҲ¬иҷ«ејҖеҸ‘
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іphpеҰӮдҪ•е®һзҺ°зҲ¬иҷ«ејҖеҸ‘пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
ејҖеҸ‘дёҖдёӘзҲ¬иҷ«пјҢйҰ–е…ҲдҪ иҰҒзҹҘйҒ“дҪ зҡ„иҝҷдёӘзҲ¬иҷ«жҳҜиҰҒз”ЁжқҘеҒҡд»Җд№Ҳзҡ„гҖӮжҲ‘жҳҜиҰҒз”ЁжқҘеҺ»дёҚеҗҢзҪ‘з«ҷжүҫзү№е®ҡе…ій”®еӯ—зҡ„ж–Үз« пјҢ并иҺ·еҸ–е®ғзҡ„й“ҫжҺҘпјҢд»ҘдҫҝжҲ‘еҝ«йҖҹйҳ…иҜ»гҖӮ
жҢүз…§дёӘдәәд№ жғҜпјҢжҲ‘йҰ–е…ҲиҰҒеҶҷдёҖдёӘз•ҢйқўпјҢзҗҶжё…дёӢжҖқи·ҜгҖӮ
1гҖҒеҺ»дёҚеҗҢзҪ‘з«ҷгҖӮйӮЈд№ҲжҲ‘们йңҖиҰҒдёҖдёӘurlиҫ“е…ҘжЎҶгҖӮ
2гҖҒжүҫзү№е®ҡе…ій”®еӯ—зҡ„ж–Үз« гҖӮйӮЈд№ҲжҲ‘们йңҖиҰҒдёҖдёӘж–Үз« ж Үйўҳиҫ“е…ҘжЎҶгҖӮ
3гҖҒиҺ·еҸ–ж–Үз« й“ҫжҺҘгҖӮйӮЈд№ҲжҲ‘们йңҖиҰҒдёҖдёӘжҗңзҙўз»“жһңзҡ„жҳҫзӨәе®№еҷЁгҖӮ
<div class="jumbotron" id="mainJumbotron">
<div class="panel panel-default">
<div class="panel-heading">ж–Үз« URLжҠ“еҸ–</div>
<div class="panel-body">
<div class="form-group">
<label for="article_title">ж–Үз« ж Үйўҳ</label>
<input type="text" class="form-control" id="article_title" placeholder="ж–Үз« ж Үйўҳ">
</div>
<div class="form-group">
<label for="website_url">зҪ‘з«ҷURL</label>
<input type="text" class="form-control" id="website_url" placeholder="зҪ‘з«ҷURL">
</div>
<button type="submit" class="btn btn-default">жҠ“еҸ–</button>
</div>
</div>
<div class="panel panel-default">
<div class="panel-heading">ж–Үз« URL</div>
<div class="panel-body">
<h4></h4>
</div>
</div>
</div>
зӣҙжҺҘдёҠд»Јз ҒпјҢ然еҗҺеҠ дёҠиҮӘе·ұзҡ„дёҖдәӣж ·ејҸи°ғж•ҙпјҢз•Ңйқўе°ұе®ҢжҲҗе•Ұпјҡ
йӮЈд№ҲжҺҘдёӢжқҘе°ұжҳҜеҠҹиғҪзҡ„е®һзҺ°дәҶпјҢжҲ‘з”ЁPHPжқҘеҶҷпјҢйҰ–е…Ҳ第дёҖжӯҘе°ұжҳҜиҺ·еҸ–зҪ‘з«ҷзҡ„htmlд»Јз ҒпјҢиҺ·еҸ–htmlд»Јз Ғзҡ„ж–№ејҸд№ҹжңүеҫҲеӨҡпјҢжҲ‘е°ұдёҚдёҖдёҖд»Ӣз»ҚдәҶпјҢиҝҷйҮҢз”ЁдәҶcurlжқҘиҺ·еҸ–пјҢдј е…ҘзҪ‘з«ҷurlе°ұиғҪеҫ—еҲ°htmlд»Јз Ғе•Ұпјҡ
private function get_html($url){
$ch = curl_init();
$timeout = 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$html = curl_exec($ch);
return $html;
}иҷҪ然еҫ—еҲ°дәҶhtmlд»Јз ҒпјҢдҪҶжҳҜеҫҲеҝ«дҪ дјҡйҒҮеҲ°дёҖдёӘй—®йўҳпјҢйӮЈе°ұжҳҜзј–з Ғй—®йўҳпјҢиҝҷеҸҜиғҪи®©дҪ дёӢдёҖжӯҘзҡ„еҢ№й…Қж— еҠҹиҖҢиҝ”пјҢжҲ‘们иҝҷйҮҢз»ҹдёҖжҠҠеҫ—еҲ°зҡ„htmlеҶ…е®№иҪ¬дёәutf8зј–з Ғпјҡ
$coding = mb_detect_encoding($html);
if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8"))
$html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
еҫ—еҲ°зҪ‘з«ҷзҡ„htmlпјҢиҰҒиҺ·еҸ–ж–Үз« зҡ„urlпјҢйӮЈд№ҲдёӢдёҖжӯҘе°ұжҳҜиҰҒеҢ№й…ҚиҜҘзҪ‘йЎөдёӢзҡ„жүҖжңүaж ҮзӯҫпјҢйңҖиҰҒз”ЁеҲ°жӯЈеҲҷиЎЁиҫҫејҸпјҢз»ҸиҝҮеӨҡж¬ЎжөӢиҜ•пјҢжңҖз»Ҳеҫ—еҲ°дёҖдёӘжҜ”иҫғйқ и°ұзҡ„жӯЈеҲҷиЎЁиҫҫејҸпјҢдёҚз®Ўaж ҮзӯҫдёӢз»“жһ„еӨҡеӨҚжқӮпјҢеҸӘиҰҒжҳҜaж Үзӯҫзҡ„йғҪдёҚж”ҫиҝҮпјҡ(жңҖе…ій”®зҡ„дёҖжӯҘ)
$pattern = '|<a[^>]*>(.*)</a>|isU';
preg_match_all($pattern, $html, $matches);
еҢ№й…Қзҡ„з»“жһңеңЁ$matchesдёӯпјҢе®ғеӨ§жҰӮжҳҜиҝҷж ·зҡ„дёҖдёӘеӨҡз»ҙзҙ з»„пјҡ
array(2) {
[0]=>
array(*) {
[0]=>
string(*) "е®Ңж•ҙзҡ„aж Үзӯҫ"
.
.
.
}
[1]=>
array(*) {
[0]=>
string(*) "дёҺдёҠйқўдёӢж ҮзӣёеҜ№еә”зҡ„aж Үзӯҫдёӯзҡ„еҶ…е®№"
}
}еҸӘиҰҒиғҪеҫ—еҲ°иҝҷдёӘж•°жҚ®пјҢе…¶д»–е°ұе®Ңе…ЁеҸҜд»Ҙж“ҚдҪңе•ҰпјҢдҪ еҸҜд»ҘйҒҚеҺҶиҝҷдёӘзҙ з»„пјҢжүҫеҲ°дҪ жғіиҰҒaж ҮзӯҫпјҢ然еҗҺиҺ·еҸ–aж Үзӯҫзӣёеә”зҡ„еұһжҖ§пјҢжғіжҖҺд№Ҳж“ҚдҪңе°ұжҖҺд№Ҳж“ҚдҪңе•ҰпјҢдёӢйқўжҺЁиҚҗдёҖдёӘзұ»пјҢи®©дҪ жӣҙж–№дҫҝж“ҚдҪңaж Үзӯҫпјҡ
$dom = new DOMDocument();
@$dom->loadHTML($a);//$aжҳҜдёҠйқўеҫ—еҲ°зҡ„дёҖдәӣaж Үзӯҫ
$url = new DOMXPath($dom);
$hrefs = $url->evaluate('//a');
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href'); //иҝҷйҮҢиҺ·еҸ–aж Үзӯҫзҡ„hrefеұһжҖ§
}еҪ“然пјҢиҝҷеҸӘжҳҜдёҖз§Қж–№ејҸпјҢдҪ д№ҹеҸҜд»ҘйҖҡиҝҮжӯЈеҲҷиЎЁиҫҫејҸеҢ№й…ҚдҪ жғіиҰҒзҡ„дҝЎжҒҜпјҢжҠҠж•°жҚ®зҺ©еҮәж–°иҠұж ·гҖӮ
еҫ—еҲ°е№¶еҢ№й…Қеҫ—еҮәдҪ жғіиҰҒзҡ„з»“жһңпјҢдёӢдёҖжӯҘеҪ“然е°ұжҳҜдј еӣһеүҚз«Ҝе°Ҷ他们жҳҫзӨәеҮәжқҘе•ҰпјҢжҠҠжҺҘеҸЈеҶҷеҘҪпјҢ然еҗҺеүҚз«Ҝз”ЁjsиҺ·еҸ–ж•°жҚ®пјҢз”ЁjqueryеҠЁжҖҒж·»еҠ еҶ…е®№жҳҫзӨәеҮәжқҘпјҡ
var website_url = 'дҪ зҡ„жҺҘеҸЈең°еқҖ';
$.getJSON(website_url,function(data){
if(data){
if(data.text == ''){
$('#article_url').html('<div><p>жҡӮж— иҜҘж–Үз« й“ҫжҺҘ</p></div>');
return;
}
var string = '';
var list = data.text;
for (var j in list) {
var content = list[j].url_content;
for (var i in content) {
if (content[i].title != '') {
string += '<div class="item">' +
'<em>[<a href="http://' + list[j].website.web_url + '" target="_blank">' + list[j].website.web_name + '</a>]</em>' +
'<a href=" ' + content[i].url + '" target="_blank" class="web_url">' + content[i].title + '</a>' +
'</div>';
}
}
}
$('#article_url').html(string);
});дёҠжңҖз»Ҳж•Ҳжһңеӣҫпјҡ
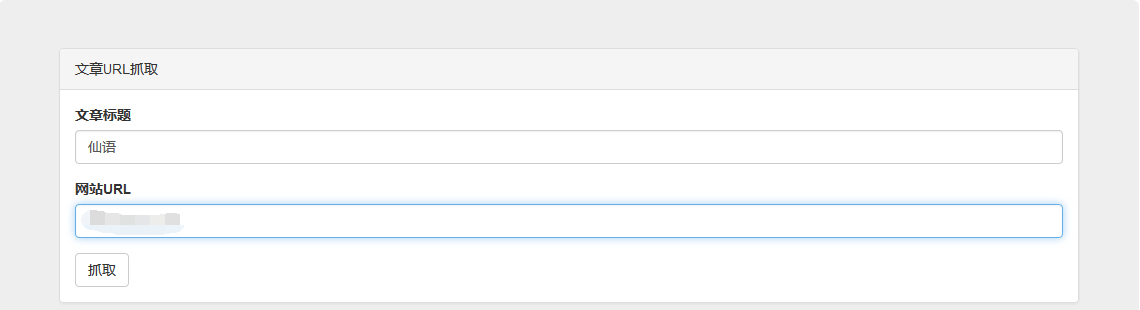

е…ідәҺвҖңphpеҰӮдҪ•е®һзҺ°зҲ¬иҷ«ејҖеҸ‘вҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





