streamеҰӮдҪ•жӯЈзЎ®зҡ„еңЁjava8дёӯдҪҝз”Ё
иҝҷжңҹеҶ…е®№еҪ“дёӯе°Ҹзј–е°Ҷдјҡз»ҷеӨ§е®¶еёҰжқҘжңүе…іstreamеҰӮдҪ•жӯЈзЎ®зҡ„еңЁjava8дёӯдҪҝз”ЁпјҢж–Үз« еҶ…е®№дё°еҜҢдё”д»Ҙдё“дёҡзҡ„и§’еәҰдёәеӨ§е®¶еҲҶжһҗе’ҢеҸҷиҝ°пјҢйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еёҢжңӣеӨ§е®¶еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
йҰ–е…ҲпјҢжҲ‘们дёҖиө·зңӢзңӢstreamзҡ„继жүҝе…ізі»пјҡ

StreamгҖҒIntStreamгҖҒLongStreamгҖҒDoubleStreamзҡ„зҲ¶жҺҘеҸЈйғҪжҳҜBaseStreamгҖӮBaseStreamзҡ„еӣӣдёӘеӯҗжҺҘеҸЈж–№жі•йғҪе·®дёҚеӨҡпјҢеҸӘжҳҜIntStreamгҖҒLongStreamгҖҒDoubleStreamзӣҙжҺҘеӯҳеӮЁеҹәжң¬зұ»еһӢпјҢеҸҜд»ҘйҒҝе…ҚиҮӘеҠЁиЈ…/жӢҶз®ұпјҢж•ҲзҺҮдјҡжӣҙй«ҳдёҖдәӣгҖӮдҪҶжҳҜпјҢжҲ‘们е®һйҷ…дёҠдҪҝз”ЁStreamжӣҙеӨҡдёҖдәӣгҖӮ
жҲ‘们еҶҚзңӢзңӢstreamзҡ„е·ҘдҪңжөҒзЁӢеӣҫпјҡ

дёәд»Җд№ҲиҰҒеӯҰstreamзҡ„й“ҫејҸзј–зЁӢж–№ејҸ
дёҡеҠЎйңҖжұӮ1пјҡжҢҮе®ҡдёҖдёӘеӯ—з¬ҰдёІж•°з»„пјҢжүҫеҮәйҮҢйқўзӣёеҗҢзҡ„е…ғзҙ пјҢ并且з»ҹи®ЎйҮҚеӨҚзҡ„ж¬Ўж•°гҖӮ
жҲ‘们д»ҘеүҚеӨ§жҰӮжҳҜиҝҷж ·еҒҡзҡ„пјҡ
public class CountTest {
@Test
public void testCount1() {
List<String> list = Lists.newArrayList("a", "b", "ab", "abc", "a", "ab", "a", "abcd", "bd", "abc");
Map<String, Long> countMap = new HashMap<>();
for (String data : list) {
Long aLong = countMap.get(data);
if (Objects.isNull(aLong)) {
countMap.put(data, 1L);
} else {
countMap.put(data, ++aLong);
}
}
countMap.forEach((key, value) -> System.out.println("key:" + key + " value:" + value));
}
}жү§иЎҢз»“жһңпјҡ
key:a value:3
key:ab value:2
key:b value:1
key:bd value:1
key:abc value:2
key:abcd value:1
жҲ‘们еҶҚзңӢзңӢеҰӮжһңз”Ёjava8зҡ„streamеҸҜд»ҘжҖҺд№ҲеҒҡпјҡ
public class CountTest {
@Test
public void testCount2() {
List<String> list = Lists.newArrayList("a", "b", "ab", "abc", "a", "ab", "a", "abcd", "bd", "abc");
Map<String, Long> countMap = list.stream().collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
countMap.forEach((key, value) -> System.out.println("key:" + key + " value:" + value));
}
}жү§иЎҢз»“жһңпјҡ
key:a value:3
key:ab value:2
key:b value:1
key:bd value:1
key:abc value:2
key:abcd value:1
жҲ‘们еҸҜд»ҘзңӢеҲ°testCount1е’ҢtestCount2жү§иЎҢз»“жһңзӣёеҗҢпјҢд»…д»…дёҖиЎҢд»Јз Ғпјҡ
Map<String, Long> countMap = list.stream().collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
е°ұеҸҜд»Ҙе®һзҺ°дёҠйқўtestCount1дёӯеӨҡиЎҢд»Јз Ғзҡ„йҖ»иҫ‘гҖӮ
дёҡеҠЎйңҖжұӮ2пјҡд»ҺдёҖдёӘжҢҮе®ҡзҡ„еӯ—з¬ҰдёІж•°з»„дёӯпјҢжҹҘжүҫжҢҮе®ҡзҡ„еӯ—з¬ҰдёІжҳҜеҗҰеӯҳеңЁ
жҲ‘们д»ҘеүҚеӨ§жҰӮжҳҜиҝҷж ·еҒҡзҡ„пјҡ
public class FindTest {
@Test
public void testFind1() {
String findStr = "bd";
List<String> list = Lists.newArrayList("a", "b", "ab", "abc", "a", "ab", "a", "abcd", "bd", "abc");
boolean match = false;
for (String data : list) {
if (data.equals(findStr)) {
match = true;
break;
}
}
//з»“жһңпјҡmatch:true
System.out.println("match:" + match);
}
}жҲ‘们еҶҚзңӢзңӢеҰӮжһңз”Ёjava8зҡ„streamеҸҜд»ҘжҖҺд№ҲеҒҡпјҡ
public class MatchTest {
@Test
public void testFind2() {
String findStr = "bd";
List<String> list = Lists.newArrayList("a", "b", "ab", "abc", "a", "ab", "a", "abcd", "bd", "abc");
boolean match = list.stream().anyMatch(x -> x.equals(findStr));
//з»“жһңпјҡmatch:true
System.out.println("match:" + match);
}
}жҲ‘们еҸҜд»ҘзңӢеҲ°и°ғз”ЁtestFind1е’ҢtestFind2ж–№жі•жү§иЎҢз»“жһңд№ҹжҳҜдёҖж ·зҡ„гҖӮдҪҶжҳҜпјҢз”Ёjava8 streamзҡ„иҜӯжі•пјҢеҸҲеҸӘз”ЁдёҖиЎҢд»Јз Ғе°ұе®ҢжҲҗеҠҹиғҪдәҶпјҢзңҹжЈ’гҖӮ
java8 streamи¶…иҜҰз»Ҷз”Ёжі•жҢҮеҚ—
streamзҡ„ж“ҚдҪңз¬ҰеӨ§дҪ“дёҠеҲҶдёәдёӨз§Қпјҡдёӯй—ҙж“ҚдҪңз¬Ұе’Ңз»Ҳжӯўж“ҚдҪңз¬Ұ
дёӯй—ҙж“ҚдҪңпјҡ
1.filter(T-> boolean)
иҝҮж»Өж•°жҚ®пјҢдҝқз•ҷ boolean дёә true зҡ„е…ғзҙ пјҢиҝ”еӣһдёҖдёӘйӣҶеҗҲ
public class FilterTest {
@Test
public void testFilter() {
List<Integer> list = Lists.newArrayList(20, 23, 25, 28, 30, 33, 37, 40);
//д»ҺжҢҮе®ҡж•°жҚ®йӣҶеҗҲдёӯиҝҮж»ӨеҮәеӨ§дәҺзӯүдәҺ30зҡ„ж•°жҚ®йӣҶеҗҲ
List<Integer> collect = list.stream().filter(x -> x >= 30).collect(Collectors.toList());
//з»“жһңпјҡ[33, 37, 40]
System.out.println(collect);
}
}collect(Collectors.toList())еҸҜд»ҘжҠҠжөҒиҪ¬жҚўдёә List зұ»еһӢпјҢcollectе®һйҷ…дёҠжҳҜдёҖдёӘз»Ҳжӯўж“ҚдҪңгҖӮ
2.map(T -> R)
иҪ¬жҚўж“ҚдҪңз¬ҰпјҢеҸҜд»ҘеҒҡж•°жҚ®иҪ¬жҚўпјҢжҜ”еҰӮпјҡжҠҠеӯ—з¬ҰдёІиҪ¬жҚўжҲҗintгҖҒlongгҖҒdoubleпјҢжҲ–иҖ…жҠҠдёҖдёӘе®һдҪ“иҪ¬жҚўжҲҗеҸҰеӨ–дёҖдёӘе®һдҪ“гҖӮеҢ…еҗ«пјҡmapпјҢmapToIntгҖҒmapToLongгҖҒmapToDouble
public class MapTest {
@Test
public void testMap() {
List<String> list = Lists.newArrayList("1", "2", "3", "4", "5", "6");
List<Long> collect1 = list.stream().map(x -> Long.parseLong(x)).collect(Collectors.toList());
//з»“жһңпјҡ[1, 2, 3, 4, 5, 6]
System.out.println(collect1);
//з»“жһңпјҡ111111
list.stream().mapToInt(x -> x.length()).forEach(System.out::print);
System.out.println("");
//з»“жһңпјҡ111111
list.stream().mapToLong(x -> x.length()).forEach(System.out::print);
System.out.println("");
//з»“жһңпјҡ1.01.01.01.01.01.0
list.stream().mapToDouble(x -> x.length()).forEach(System.out::print);
}
}3.flatMap(T -> Stream)
е°ҶжөҒдёӯзҡ„жҜҸдёҖдёӘе…ғзҙ T жҳ е°„дёәдёҖдёӘжөҒпјҢеҶҚжҠҠжҜҸдёҖдёӘжөҒиҝһжҺҘжҲҗдёәдёҖдёӘжөҒ
public class FlatMapTest {
@Test
public void testFlatMap() {
List<List<String>> list = new ArrayList<List<String>>(){{
add(Lists.newArrayList("a","b","c"));
add(Lists.newArrayList("d","e","f"));
add(Lists.newArrayList("j","k","y"));
}};
//з»“жһңпјҡ[[a, b, c], [d, e, f], [j, k, y]]
System.out.println(list);
List<String> collect = list.stream().flatMap(List::stream).collect(Collectors.toList());
//з»“жһңпјҡ[a, b, c, d, e, f, j, k, y]
System.out.println(collect);
}
}жҲ‘们еҸҜд»ҘзңӢеҲ°flatMapеҸҜд»ҘиҪ»жқҫжҠҠеӯ—з¬ҰдёІзҡ„дәҢз»ҙж•°жҚ®еҸҳжҲҗдёҖдҪҚж•°з»„гҖӮ
4.distinct
еҺ»йҮҚпјҢзұ»дјјдәҺmsqlдёӯзҡ„distinctзҡ„дҪңз”ЁпјҢеә•еұӮдҪҝз”ЁдәҶequalsж–№жі•еҒҡжҜ”иҫғгҖӮ
public class DistinctTest {
@Test
public void testDistinct() {
List<String> list = Lists.newArrayList("a", "b", "ab", "abc", "a", "ab", "a", "abcd", "bd", "abc");
List<String> collect = list.stream().distinct().collect(Collectors.toList());
//з»“жһңпјҡ[a, b, ab, abc, abcd, bd]
System.out.println(collect);
}
}е…¶е®һпјҢеҺ»йҮҚиҝҳжңүеҸҰеӨ–дёҖз§ҚеҠһжі•пјҢеҸҜд»Ҙз”ЁCollectors.toSet()пјҢеҗҺйқўдјҡи®ІеҲ°гҖӮ
5.sorted
еҜ№е…ғзҙ иҝӣиЎҢжҺ’еәҸпјҢеүҚжҸҗжҳҜе®һзҺ°ComparableжҺҘеҸЈпјҢеҪ“然д№ҹеҸҜд»ҘиҮӘе®ҡд№үжҜ”иҫғеҷЁгҖӮ
public class SortTest {
@Test
public void testSort() {
List<Integer> list = Lists.newArrayList(5, 3, 7, 1, 4, 6);
List<Integer> collect = list.stream().sorted((a, b) -> a.compareTo(b)).collect(Collectors.toList());
//з»“жһңпјҡ[1, 3, 4, 5, 6, 7]
System.out.println(collect);
}
}6.limit
йҷҗжөҒж“ҚдҪңпјҢжңүзӮ№зұ»дјјдәҺmysqlдёӯзҡ„limitеҠҹиғҪпјҢжҜ”еҰӮпјҡжңү10дёӘе…ғзҙ пјҢеҸӘеҸ–еүҚйқў3дёӘе…ғзҙ
public class LimitTest {
@Test
public void testLimit() {
List<String> list = Lists.newArrayList("a", "b", "ab", "abc", "a", "ab", "a", "abcd", "bd", "abc");
List<String> collect = list.stream().limit(3).collect(Collectors.toList());
//з»“жһңпјҡ[a, b, ab]
System.out.println(collect);
}
}7.skip
и·іиҝҮж“ҚдҪңпјҢжҜ”еҰӮпјҡжңүдёӘ10дёӘе…ғзҙ пјҢд»Һ第5дёӘе…ғзҙ ејҖе§ӢеҺ»еҗҺйқўзҡ„е…ғзҙ
public class SkipTest {
@Test
public void testSkip() {
List<String> list = Lists.newArrayList("a", "b", "ab", "abc", "a", "ab", "a", "abcd", "bd", "abc");
List<String> collect = list.stream().skip(5).collect(Collectors.toList());
//з»“жһңпјҡ[ab, a, abcd, bd, abc]
System.out.println(collect);
}
}8.peek
жҢ‘еҮәж“ҚдҪңпјҢ
public class PeekTest {
@Test
public void testPeek() {
List<String> list = Lists.newArrayList("a", "b", "ab", "abc", "a", "ab", "a", "abcd", "bd", "abc");
//з»“жһңпјҡabababcaabaabcdbdabc
list.stream().peek(x -> x.toUpperCase()).forEach(System.out::print);
}
}зңје°–зҡ„жңӢеҸӢдјҡеҸ‘зҺ°пјҢиҝӣиЎҢx.toUpperCase()иҪ¬жҚўдёәеӨ§еҶҷеҠҹиғҪпјҢдҪҶжҳҜе®һйҷ…дёҠжІЎжңүз”ҹж•ҲгҖӮжҠҠpeekж”№жҲҗmapж–№жі•иҜ•иҜ•пјҡ
public class PeekTest {
@Test
public void testPeek() {
List<String> list = Lists.newArrayList("a", "b", "ab", "abc", "a", "ab", "a", "abcd", "bd", "abc");
//з»“жһңпјҡABABABCAABAABCDBDABC
list.stream().map(x -> x.toUpperCase()).forEach(System.out::print);
}
}жҲ‘们еҸҜд»ҘзңӢеҲ°пјҢз”Ёmapж“ҚдҪңиҪ¬жҚўжҲҗеӨ§еҶҷеҠҹиғҪз”ҹж•ҲдәҶпјҢдҪҶжҳҜз”Ёpeekж“ҚдҪңеҚҙжІЎжңүз”ҹж•ҲгҖӮpeekеҸӘжҳҜеҜ№Streamдёӯзҡ„е…ғзҙ иҝӣиЎҢжҹҗдәӣж“ҚдҪңпјҢдҪҶжҳҜж“ҚдҪңд№ӢеҗҺзҡ„ж•°жҚ®е№¶дёҚиҝ”еӣһеҲ°StreamдёӯпјҢжүҖд»ҘStreamдёӯзҡ„е…ғзҙ иҝҳжҳҜеҺҹжқҘзҡ„е…ғзҙ гҖӮ
з»Ҳжӯўж“ҚдҪңпјҡ
1.forEach
йҒҚеҺҶж“ҚдҪңпјҢеҢ…еҗ«пјҡforEach е’Ң forEachOrdered
forEachпјҡж”ҜжҢҒ并иЎҢеӨ„зҗҶ
forEachOrderedпјҡжҳҜжҢүйЎәеәҸеӨ„зҗҶзҡ„пјҢйҒҚеҺҶйҖҹеәҰиҫғж…ў
public class ForEachTest {
@Test
public void testForEach() {
List<String> list = Lists.newArrayList("a", "b", "ab");
//з»“жһңпјҡa b ab
list.stream().forEach(x-> System.out.print(x+' '));
System.out.println("");
//еҸҜд»Ҙз®ҖеҢ–
//з»“жһңпјҡa b ab
list.forEach(x-> System.out.print(x+' '));
System.out.println("");
//з»“жһңпјҡa b ab
list.stream().forEachOrdered(x-> System.out.print(x+' '));
}
}2.collect
收йӣҶж“ҚдҪңпјҢе°ҶжүҖжңүзҡ„е…ғзҙ 收йӣҶиө·жқҘпјҢCollectors жҸҗдҫӣдәҶйқһеёёеӨҡ收йӣҶеҷЁгҖӮеҢ…еҗ«пјҡtoMapгҖҒtoSetгҖҒtoListгҖҒjoiningпјҢgroupingByпјҢmaxByпјҢminByзӯүж“ҚдҪңгҖӮ
toMapпјҡе°Ҷж•°жҚ®жөҒиҪ¬жҚўдёәmapпјҢйҮҢйқўеҢ…еҗ«зҡ„е…ғзҙ жҳҜз”Ёkey/valueзҡ„еҪўејҸзҡ„
toSetпјҡе°Ҷж•°жҚ®жөҒиҪ¬жҚўдёәsetпјҢйҮҢйқўеҢ…еҗ«зҡ„е…ғзҙ дёҚеҸҜйҮҚеӨҚ
toListпјҡе°Ҷж•°жҚ®жөҒиҪ¬еҮәдёәlistпјҢйҮҢйқўеҢ…еҗ«зҡ„е…ғзҙ жҳҜжңүеәҸзҡ„
joiningпјҡжӢјжҺҘеӯ—з¬ҰдёІ
groupingByпјҡеҲҶз»„пјҢеҸҜд»Ҙе°ҶlistиҪ¬жҚўmap
coutingпјҡз»ҹи®Ўе…ғзҙ ж•°йҮҸ
maxByпјҡиҺ·еҸ–жңҖеӨ§е…ғзҙ
minByпјҡиҺ·еҸ–жңҖе°Ҹе…ғзҙ
summarizingInt: жұҮжҖ»intзұ»еһӢзҡ„е…ғзҙ пјҢиҝ”еӣһIntSummaryStatisticsпјҢеҶҚи°ғз”Ёе…·дҪ“зҡ„ж–№жі•еҜ№е…ғзҙ иҝӣиЎҢз»ҹи®ЎпјҡgetCountпјҲз»ҹи®Ўж•°йҮҸпјүпјҢgetSumпјҲжұӮе’ҢпјүпјҢgetMinпјҲиҺ·еҸ–жңҖе°ҸеҖјпјүпјҢgetMaxпјҲиҺ·еҸ–жңҖеӨ§еҖјпјүпјҢgetAverageпјҲиҺ·еҸ–е№іеқҮеҖјпјү
summarizingLongпјҡжұҮжҖ»longзұ»еһӢзҡ„е…ғзҙ пјҢз”Ёжі•еҗҢsummarizingInt
summarizingDoubleпјҡжұҮжҖ»doubleзұ»еһӢзҡ„е…ғзҙ пјҢз”Ёжі•еҗҢsummarizingInt
averagingIntпјҡиҺ·еҸ–intзұ»еһӢзҡ„е…ғзҙ зҡ„е№іеқҮеҖјпјҢиҝ”еӣһдёҖдёӘdoubleзұ»еһӢзҡ„ж•°жҚ®
averagingLongпјҡиҺ·еҸ–longзұ»еһӢзҡ„е…ғзҙ зҡ„е№іеқҮеҖјпјҢз”Ёжі•еҗҢaveragingInt
averagingDoubleпјҡиҺ·еҸ–doubleзұ»еһӢзҡ„е…ғзҙ зҡ„е№іеқҮеҖјпјҢз”Ёжі•еҗҢaveragingInt
mappingпјҡиҺ·еҸ–жҳ е°„пјҢеҸҜд»Ҙе°ҶеҺҹе§Ӣе…ғзҙ зҡ„дёҖйғЁеҲҶеҶ…е®№дҪңдёәдёҖдёӘж–°е…ғзҙ иҝ”еӣһ
public class CollectTest {
@Data
@AllArgsConstructor
class User {
private String name;
private Integer age;
}
@Test
public void testCollect() {
List<String> list0 = Lists.newArrayList("a", "b", "ab");
Map<String, String> collect0 = list0.stream().collect(Collectors.toMap(String::new, Function.identity()));
//з»“жһңпјҡ{ab=ab, a=a, b=b}
System.out.println(collect0);
List<String> list = Lists.newArrayList("a", "b", "ab", "a", "b", "ab");
List<String> collect1 = list.stream().collect(Collectors.toList());
//з»“жһңпјҡ[a, b, ab, a, b, ab]
System.out.println(collect1);
//з»“жһңпјҡ[a, ab, b]
Set<String> collect2 = list.stream().collect(Collectors.toSet());
System.out.println(collect2);
String collect3 = list.stream().collect(Collectors.joining(","));
//з»“жһңпјҡa,b,ab,a,b,ab
System.out.println(collect3);
Map<String, List<String>> collect4 = list.stream().collect(Collectors.groupingBy(Function.identity()));
//з»“жһңпјҡ{ab=[ab, ab], a=[a, a], b=[b, b]}
System.out.println(collect4);
Long collect = list.stream().collect(Collectors.counting());
//з»“жһңпјҡ6
System.out.println(collect);
String collect5 = list.stream().collect(Collectors.maxBy((a, b) -> a.compareTo(b))).orElse(null);
//з»“жһңпјҡb
System.out.println(collect5);
String collect6 = list.stream().collect(Collectors.minBy((a, b) -> a.compareTo(b))).orElse(null);
//з»“жһңпјҡa
System.out.println(collect6);
List<String> list2 = Lists.newArrayList("2", "3", "5");
IntSummaryStatistics summaryStatistics = list2.stream().collect(Collectors.summarizingInt(x -> Integer.parseInt(x)));
long sum = summaryStatistics.getSum();
//з»“жһңпјҡ10
System.out.println(sum);
Double collect7 = list2.stream().collect(Collectors.averagingInt(x -> Integer.parseInt(x)));
//з»“жһңпјҡ3.3333333333333335
System.out.println(collect7);
List<User> userList = new ArrayList<User>() {{
add(new User("jack",23));
add(new User("james",30));
add(new User("curry",28));
}};
List<String> collect8 = userList.stream().collect(Collectors.mapping(User::getName, Collectors.toList()));
//[jack, james, curry]
System.out.println(collect8);
}
}3.find
жҹҘжүҫж“ҚдҪңпјҢеҢ…еҗ«пјҡfindFirstгҖҒfindAny
findFirstпјҡжүҫеҲ°з¬¬дёҖдёӘпјҢиҝ”еӣһзҡ„зұ»еһӢдёәOptional
findAnyпјҡдҪҝз”Ё stream() ж—¶жүҫеҲ°зҡ„жҳҜ第дёҖдёӘе…ғзҙ пјҢдҪҝз”Ё parallelStream() 并иЎҢж—¶жүҫеҲ°зҡ„жҳҜе…¶дёӯдёҖдёӘе…ғзҙ пјҢиҝ”еӣһзҡ„зұ»еһӢдёәOptional
public class FindOpTest {
@Test
public void testFindOp() {
List<String> list = Lists.newArrayList("a", "b", "ab", "abc", "bc", "ab");
//жҹҘжүҫ第дёҖеҢ№й…Қзҡ„е…ғзҙ
String data1 = list.stream().findFirst().orElse(null);
//з»“жһң: a
System.out.println(data1);
String data2 = list.stream().findAny().orElse(null);
//з»“жһң: a
System.out.println(data2);
}
}4.match
еҢ№й…Қж“ҚдҪңпјҢеҢ…еҗ«пјҡallMatchгҖҒanyMatchгҖҒnoneMatch
allMatchпјҡжүҖжңүе…ғзҙ йғҪж»Ўи¶іжқЎд»¶пјҢиҝ”еӣһbooleanзұ»еһӢ
anyMatchпјҡд»»ж„ҸдёҖдёӘе…ғзҙ ж»Ўи¶іжқЎд»¶пјҢиҝ”еӣһbooleanзұ»еһӢ
noneMatchпјҡжүҖжңүе…ғзҙ йғҪдёҚж»Ўи¶іжқЎд»¶пјҢиҝ”еӣһbooleanзұ»еһӢ
public class MatchTest {
@Test
public void testMatch() {
List<Integer> list = Lists.newArrayList(2, 3, 5, 7);
boolean allMatch = list.stream().allMatch(x -> x > 1);
//з»“жһңпјҡtrue
System.out.println(allMatch);
boolean allMatch3 = list.stream().allMatch(x -> x > 2);
//з»“жһңпјҡfalse
System.out.println(allMatch3);
boolean anyMatch = list.stream().anyMatch(x -> x > 2);
//з»“жһңпјҡtrue
System.out.println(anyMatch);
boolean noneMatch2 = list.stream().noneMatch(x -> x > 5);
//з»“жһңпјҡfalse
System.out.println(noneMatch2);
boolean noneMatch3 = list.stream().noneMatch(x -> x > 7);
//з»“жһңпјҡtrue
System.out.println(noneMatch3);
}
}5.count
з»ҹи®Ўж“ҚдҪңпјҢж•Ҳжһңи·ҹи°ғз”ЁйӣҶеҗҲзҡ„size()ж–№жі•зұ»дјј
public class CountOpTest {
@Test
public void testCountOp() {
List<String> list = Lists.newArrayList("a", "b", "ab");
long count = list.stream().count();
//з»“жһңпјҡ3
System.out.println(count);
}
}6.minгҖҒmax
minпјҡиҺ·еҸ–жңҖе°ҸеҖјпјҢиҝ”еӣһOptionalзұ»еһӢзҡ„ж•°жҚ®
maxпјҡиҺ·еҸ–жңҖеӨ§еҖјпјҢиҝ”еӣһOptionalзұ»еһӢзҡ„ж•°жҚ®
public class MaxMinTest {
@Test
public void testMaxMin() {
List<Integer> list = Lists.newArrayList(2, 3, 5, 7);
Optional<Integer> max = list.stream().max((a, b) -> a.compareTo(b));
//з»“жһңпјҡ7
System.out.println(max.get());
Optional<Integer> min = list.stream().min((a, b) -> a.compareTo(b));
//з»“жһңпјҡ2
System.out.println(min.get());
}
}7.reduce
规зәҰж“ҚдҪңпјҢе°Ҷж•ҙдёӘж•°жҚ®жөҒзҡ„еҖји§„зәҰдёәдёҖдёӘеҖјпјҢcountгҖҒminгҖҒmaxеә•еұӮе°ұжҳҜдҪҝз”ЁreduceгҖӮ
reduce ж“ҚдҪңеҸҜд»Ҙе®һзҺ°д»ҺStreamдёӯз”ҹжҲҗдёҖдёӘеҖјпјҢе…¶з”ҹжҲҗзҡ„еҖјдёҚжҳҜйҡҸж„Ҹзҡ„пјҢиҖҢжҳҜж №жҚ®жҢҮе®ҡзҡ„и®Ўз®—жЁЎеһӢгҖӮ
public class ReduceTest {
@Test
public void testReduce() {
List<Integer> list = Lists.newArrayList(2, 3, 5, 7);
Integer sum1 = list.stream().reduce(0, Integer::sum);
//з»“жһңпјҡ17
System.out.println(sum1);
Optional<Integer> reduce = list.stream().reduce((a, b) -> a + b);
//з»“жһңпјҡ17
System.out.println(reduce.get());
Integer max = list.stream().reduce(0, Integer::max);
//з»“жһңпјҡ7
System.out.println(max);
Integer min = list.stream().reduce(0, Integer::min);
//з»“жһңпјҡ0
System.out.println(min);
Optional<Integer> reduce1 = list.stream().reduce((a, b) -> a > b ? b : a);
//2
System.out.println(reduce1.get());
}
}8.toArray
ж•°з»„ж“ҚдҪңпјҢе°Ҷж•°жҚ®жөҒзҡ„е…ғзҙ иҪ¬жҚўжҲҗж•°з»„гҖӮ
public class ArrayTest {
@Test
public void testArray() {
List<String> list = Lists.newArrayList("a", "b", "ab");
String[] strings = list.stream().toArray(String[]::new);
//з»“жһңпјҡa b ab
for (int i = 0; i < strings.length; i++) {
System.out.print(strings[i]+" ");
}
}
}streamе’ҢparallelStreamзҡ„еҢәеҲ«
streamпјҡжҳҜеҚ•з®ЎйҒ“пјҢз§°е…¶дёәжөҒпјҢе…¶дё»иҰҒз”ЁдәҺйӣҶеҗҲзҡ„йҖ»иҫ‘еӨ„зҗҶгҖӮ
parallelStreamпјҡжҳҜеӨҡз®ЎйҒ“пјҢжҸҗдҫӣдәҶжөҒзҡ„并иЎҢеӨ„зҗҶпјҢе®ғжҳҜStreamзҡ„еҸҰдёҖйҮҚиҰҒзү№жҖ§пјҢе…¶еә•еұӮдҪҝз”ЁFork/JoinжЎҶжһ¶е®һзҺ°
public class StreamTest {
@Test
public void testStream() {
List<Integer> list = Lists.newArrayList(1,2, 3,4, 5,6, 7);
//з»“жһңпјҡ1234567
list.stream().forEach(System.out::print);
}
}public class ParallelStreamTest {
@Test
public void testParallelStream() {
List<Integer> list = Lists.newArrayList(1,2, 3,4, 5,6, 7);
//з»“жһңпјҡ5726134
list.parallelStream().forEach(System.out::print);
}
}жҲ‘们еҸҜд»ҘзңӢеҲ°зӣҙжҺҘдҪҝз”ЁparallelStreamзҡ„forEachйҒҚеҺҶж•°жҚ®пјҢжҳҜжІЎжңүйЎәеәҸзҡ„гҖӮ
еҰӮжһңиҰҒи®©parallelStreamйҒҚеҺҶж—¶жңүйЎәеәҸжҖҺд№ҲеҠһе‘ўпјҹ
public class ParallelStreamTest {
@Test
public void testParallelStream() {
List<Integer> list = Lists.newArrayList(1,2, 3,4, 5,6, 7);
//з»“жһңпјҡ1234567
list.parallelStream().forEachOrdered(System.out::print);
}
}parallelStreamзҡ„е·ҘдҪңеҺҹзҗҶпјҡ
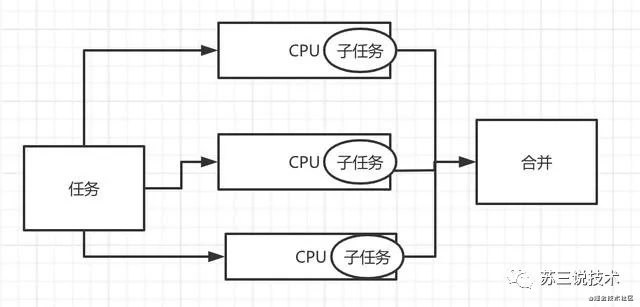
е®һйҷ…е·ҘдҪңдёӯзҡ„жЎҲдҫӢ
1.д»ҺдёӨдёӘйӣҶеҗҲдёӯжүҫзӣёеҗҢзҡ„е…ғзҙ гҖӮдёҖиҲ¬з”ЁдәҺжү№йҮҸж•°жҚ®еҜје…Ҙзҡ„еңәжҷҜпјҢе…ҲжҹҘиҜўеҮәж•°жҚ®пјҢеҶҚжү№йҮҸж–°еўһжҲ–дҝ®ж”№гҖӮ
public class WorkTest {
@Test
public void testWork1() {
List<String> list1 = Lists.newArrayList("a", "b", "ab");
List<String> list2 = Lists.newArrayList("a", "c", "ab");
List<String> collect = list1.stream()
.filter(x -> list2.stream().anyMatch(e -> e.equals(x)))
.collect(Collectors.toList());
//з»“жһңпјҡ[a, ab]
System.out.println(collect);
}
}2.жңүдёӨдёӘйӣҶеҗҲaе’ҢbпјҢиҝҮж»ӨеҮәйӣҶеҗҲaдёӯжңүпјҢдҪҶжҳҜйӣҶеҗҲbдёӯжІЎжңүзҡ„е…ғзҙ гҖӮиҝҷз§Қжғ…еҶөеҸҜд»ҘдҪҝз”ЁеңЁеҒҮеҰӮжҢҮе®ҡдёҖдёӘidйӣҶеҗҲпјҢж №жҚ®idйӣҶеҗҲд»Һж•°жҚ®еә“дёӯжҹҘиҜўеҮәж•°жҚ®йӣҶеҗҲпјҢеҶҚж №жҚ®idйӣҶеҗҲиҝҮж»ӨеҮәж•°жҚ®йӣҶеҗҲдёӯдёҚеӯҳеңЁзҡ„idпјҢиҝҷдәӣidе°ұжҳҜйңҖиҰҒж–°еўһзҡ„гҖӮ
@Test
public void testWork2() {
List<String> list1 = Lists.newArrayList("a", "b", "ab");
List<String> list2 = Lists.newArrayList("a", "c", "ab");
List<String> collect = list1.stream()
.filter(x -> list2.stream().noneMatch(e -> e.equals(x)))
.collect(Collectors.toList());
//з»“жһңпјҡ[b]
System.out.println(collect);
}3.ж №жҚ®жқЎд»¶иҝҮж»Өж•°жҚ®пјҢ并且еҺ»йҮҚеҒҡж•°жҚ®иҪ¬жҚў
@AllArgsConstructor
@Data
class User {
private String name;
private Integer age;
}
@Test
public void testWork3() {
List<User> userList = new ArrayList<User>() {{
add(new User("jack",23));
add(new User("james",30));
add(new User("curry",28));
add(new User("tom",27));
add(new User("sue",29));
}};
List<String> collect = userList.stream()
.filter(x -> x.getAge() > 27)
.sorted((a, b) -> a.getAge().compareTo(b.getAge()))
.limit(2)
.map(User::getName)
.collect(Collectors.toList());
//з»“жһңпјҡ[curry, sue]
System.out.println(collect);
}4.з»ҹи®ЎжҢҮе®ҡйӣҶеҗҲдёӯпјҢ姓еҗҚзӣёеҗҢзҡ„дәәдёӯе№ҙйҫ„жңҖе°Ҹзҡ„е№ҙйҫ„
@Test
public void testWork4() {
List<User> userList = new ArrayList<User>() {{
add(new User("tom", 23));
add(new User("james", 30));
add(new User("james", 28));
add(new User("tom", 27));
add(new User("sue", 29));
}};
userList.stream().collect(Collectors.groupingBy(User::getName))
.forEach((name, list) -> {
User user = list.stream().sorted((a, b) -> a.getAge().compareTo(b.getAge())).findFirst().orElse(null);
//з»“жһңпјҡname:sue,age:29
// name:tom,age:23
// name:james,age:28
System.out.println("name:" + name + ",age:" + user.getAge());
});
}дёҠиҝ°е°ұжҳҜе°Ҹзј–дёәеӨ§е®¶еҲҶдә«зҡ„streamеҰӮдҪ•жӯЈзЎ®зҡ„еңЁjava8дёӯдҪҝз”ЁдәҶпјҢеҰӮжһңеҲҡеҘҪжңүзұ»дјјзҡ„з–‘жғ‘пјҢдёҚеҰЁеҸӮз…§дёҠиҝ°еҲҶжһҗиҝӣиЎҢзҗҶи§ЈгҖӮеҰӮжһңжғізҹҘйҒ“жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





