本文主要给大家简单讲讲优化mysql性能及索引讲析,相关专业术语大家可以上网查查或者找一些相关书籍补充一下,这里就不涉猎了,我们就直奔优化mysql性能及索引讲析主题吧,希望可以给大家带来一些实际帮助。
一:数据库的优化方面
1商业需求的影响
比如说论坛里的帖子统计,并且实时更新
从功能上来说通过命令 select count(*) from 表名 可以得到结果,如果论坛每秒产生产生成千上万条帖子,我们没有采用myisam存储而用的是innodb存储;就算再好的设备也不可能很快的查询出来。
注:在where和count(*)使用中myisam比innodb要快的多;因为myisam内置了一个计数器,count(*)可以直接从计数器当中读取,而innodb则要扫描全表。
所以在innodb上执行count(*)时一般伴随where,而且where中要包含主键以外的索引列。
如果必须要实施更新就专门为这个功能创建一个表,要想查询结果就专门查看这个表就好了;到时候每秒产生的上万条帖子也是一种麻烦,反过来说但是到底有多少人会关注这个实时更新,如果把实时更新去掉就很容易实现;在通过创建统计表,每隔一定的时间去刷新便可以。这就是不合理的商业要求。
2:系统架构以及实现的影响
1)二进制多媒体数据
主要包括图片、视屏、其他二进制文件,如果放到数据库中数据空间资源消耗非常严重,另外一个就是消耗主机的cpu资源,因为数据库本就不是处理这些的优势,
解决办法:可以将这些二进制多媒体数据放到一个专门的文本文件中,然后给数据库做一个连接指向这个文本文件,实现数据库调用多媒体文件,有不用消耗数据库的空间和cpu资源。
2)超大文本数据
如果大的文本数据放到数据库当中也会造成空间的占用浪费问题。
解决方法:可以使用非关系型数据库进行存储
3)查询语句对性能的影响
每个sql语句在优化前后的性能差异也是各不相同
在数据库管理软件中,最大性能瓶颈就是在于磁盘io、也就是数据的存取操作上面,而对于同一份数据,当我们以不同的方式去查找某一点内容时候,所需的读取数据量可能会有天壤之别,搜消耗的资源也区别很大
首先进行编写一个脚本插入20000行的数据
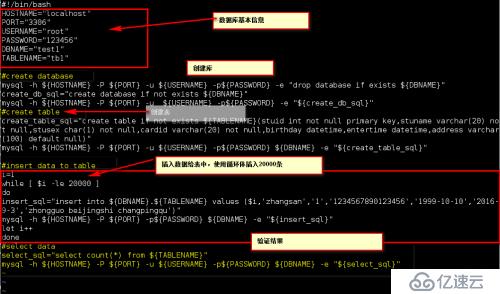

比如执行sql语句时可以用explain来查看执行计划:
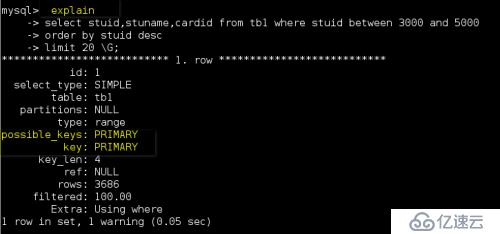
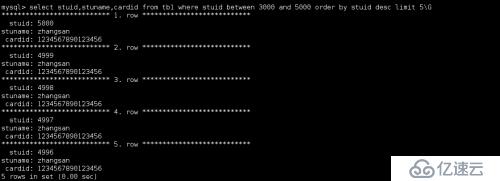
使用其他方式再次查询打开profiling功能,来查看sql的实际执行计划
打开功能

开始查询

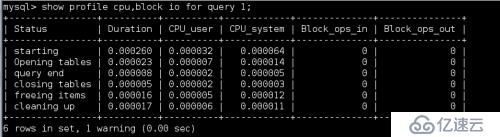
查看profile对数据库的cpu,block,以及io的使用情况:
4)数据库的schema(模式)设计对性能也有影响
5)硬件选择对性能的影响
数据库主机是存储数据的地方,所以io性能必须要优先考虑,无论是什么数据库都必须考虑的因素,当然和io相关的板卡
另外cpu的处理能力也不能忽视,企业中必须使用多核,另外内存也必须要大至少要64G
其实数据库的优化不单单从物理方面进行提高配置,也包括逻辑化如连接数。。。,和商业的需求。总之就是系统架构最优化、逻辑结构精简化、硬件设施理性化
二、索引的介绍以及创建和使用
什么是索引?
索引(index) 是帮助mysql高效获取数据结构,帮助dba快速定位,简单来说就相当于字典中的目录
索引的类型在上章讲过有三种{B-Tree、R-Tree、Full-Tree}类型、最常用的是B-Tree
这里主要介绍的是B-Tree的索引结构:
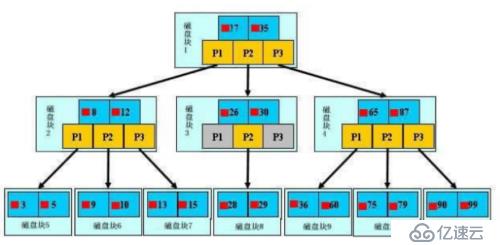
如图:这里只说重点、浅蓝色的我们成为磁盘块、可以看到每个磁盘块包含几个数据项,和指针(×××)其实真正的数据在叶子节点上,就是最下面的一层,而其他的不存放数据,只存放指引数据方向的索引而已。
例如:要查找29,首先把磁盘块1,加载到内存,发生一次io,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的p2指针,由此往下推算,直到第三层算出为止。
索引的优点:
让mysql高效的运行,可以大大提高mysql的查询效率,数据约束,快速定位
使用索引的代价:
1)需要加载到内存,以文件的形式存放在硬盘中,所以增加磁盘的开销
2)写数据,需要更新索引,对数据库是很大的开销,降低表更新、添加和删除的速度
不建议使用索引的情况:
1)表记录较少
2)索引的选择性较低,指不重复的索引与表记录数的比值,取值范围(0-1),选择性越高,索引价值越大
1:普通索引
最基本的索引,没有任何限制
create index index_name on tablename(columm1【column2,。。。。。】)
2:唯一索引
和普通索引类似,不同的就是索引列的值必须唯一,但允许空值,指的就是null,如果是组合索引,列的值必须唯一。
create table tablename(id int not null,username varchar(16) not null,primary key(id));
3:组合索引
为了进一步提升mysql的效率,可以使用组合索引
create index index_name on table_name(column1,column2,column3);
这样的组合索引效率高于单列的索引,而且采用的是最左前缀的结果。简单理解就是从最左边开始组合。
4:全文索引
只用于myisam表对文本域进行索引。字段包括char、varchar、text
不过切记大容量的数据表,生成全文索引是一个非常消耗时间和硬盘的做法
查看索引
show index from table_name
show keys from table_name
创建索引的时机:
一般在where和join子句中需要建立索引
使用索引的注意事项:
某些情况下like 才需要建立索引,因为在一通配符%和-开头查询时,mysql不会使用索引
select * from table-name where name like ‘%admin’;
另外还有就是不能再列上进行运算
select * from users where YEAR(adddate)<2000;
强每个行上进行运算,将导致索引失效而进行全表扫描
可修改为select * from users where adddate<2000-10-4;
总结:
索引的优化过程中主要用于存在where和join子句当中
索引中的列的基数越大,索引的效果越好
使用的短索引,如果对字符串进行索引,应该指定一个前缀长度,可节省大量的索引空间,提升查询的速度
优化mysql性能及索引讲析就先给大家讲到这里,对于其它相关问题大家想要了解的可以持续关注我们的行业资讯。我们的板块内容每天都会捕捉一些行业新闻及专业知识分享给大家的。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



