一、对数据库进行操作(DDL语句)。
1.创建数据库。
create database [if not exists] 数据库名称 character set 字符编码;
例:创建一个数据库,名字为db_1,字符编码为utf8
create database if not exists db_1 character set utf8;
2.查看数据库。
2.1查看所有数据库:show databases;
2.2 查看一个数据库的创建方式:show create database 数据库名称;
例:
show create database db_1;
3.修改数据库。
alter database db_name [character set xxx]
4.切换当前操作的数据库。
use 所要切换到的数据库名称。
例:use db_1
若要查看当前在哪个数据库下:
select database();
二、mysql中的数据类型。
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
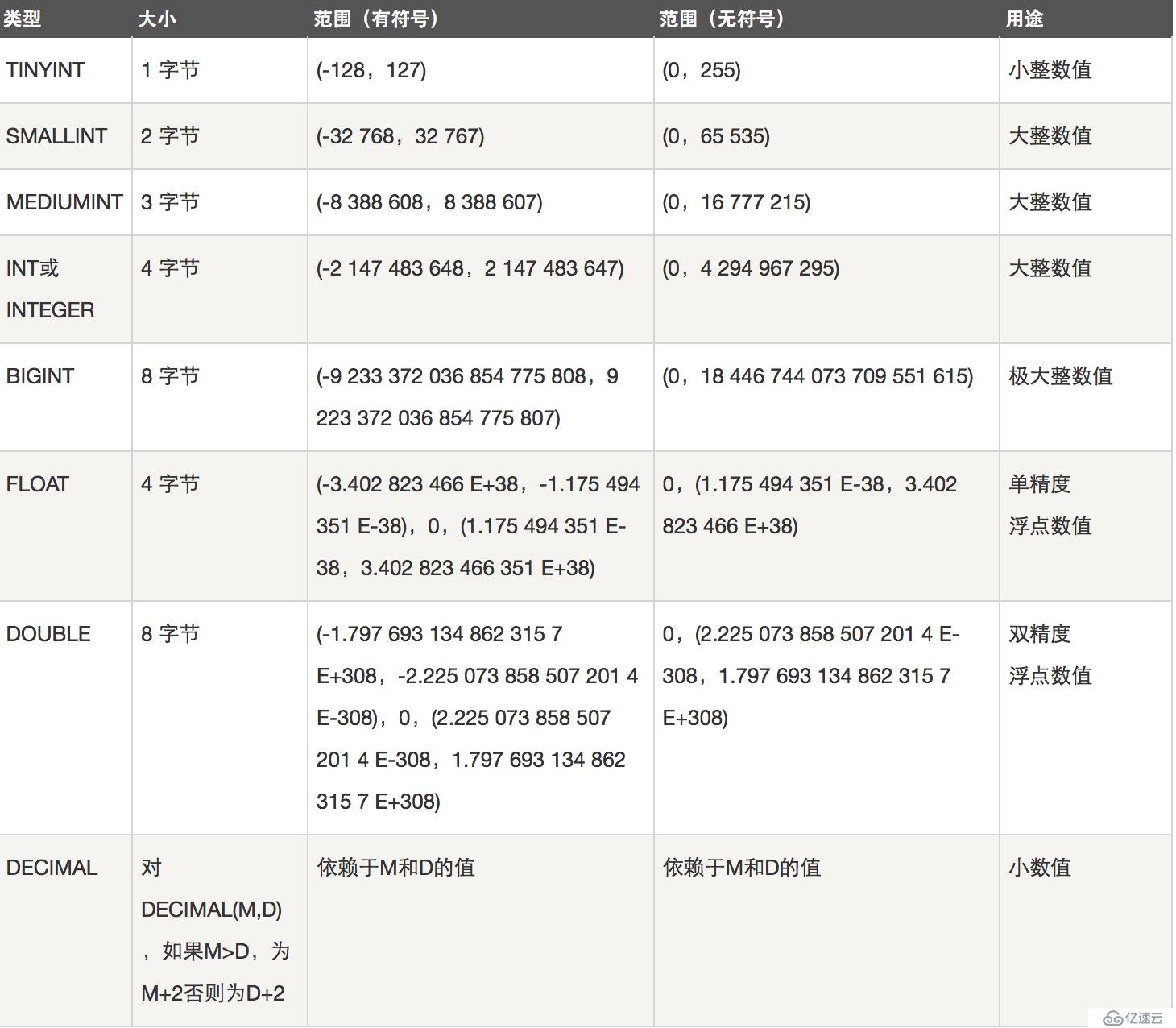
数值类型:
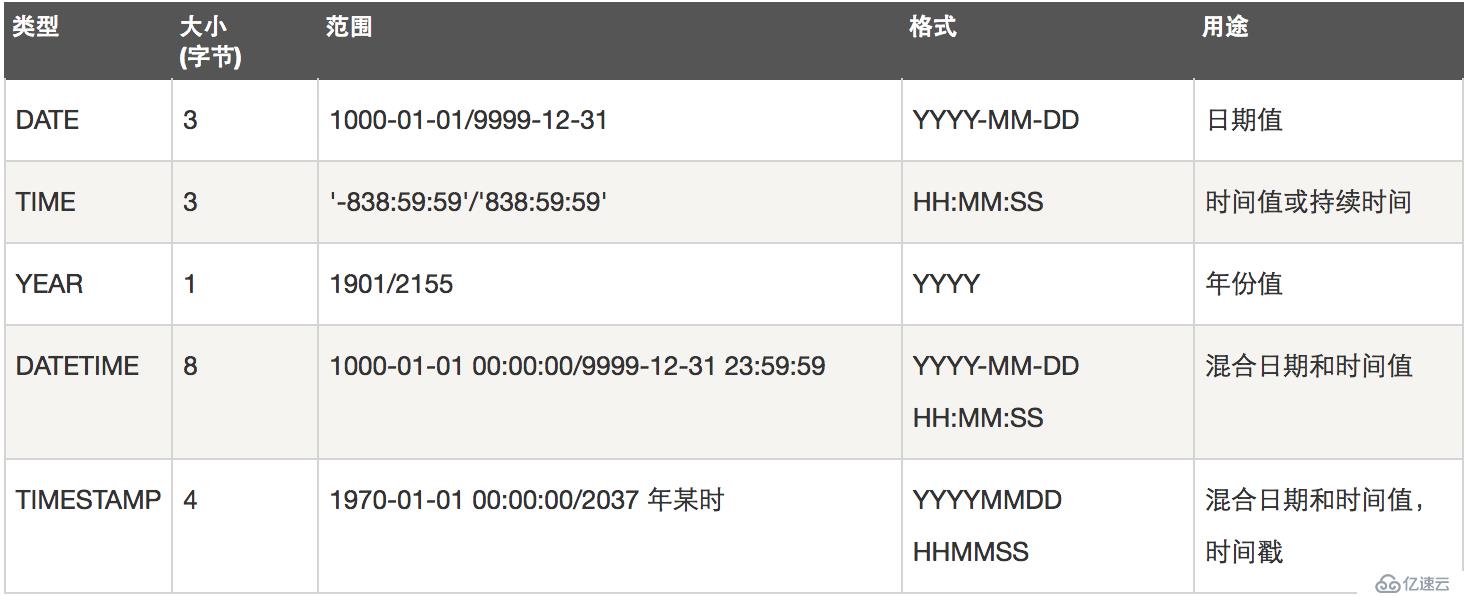
日期和时间类型:
字符串类型:
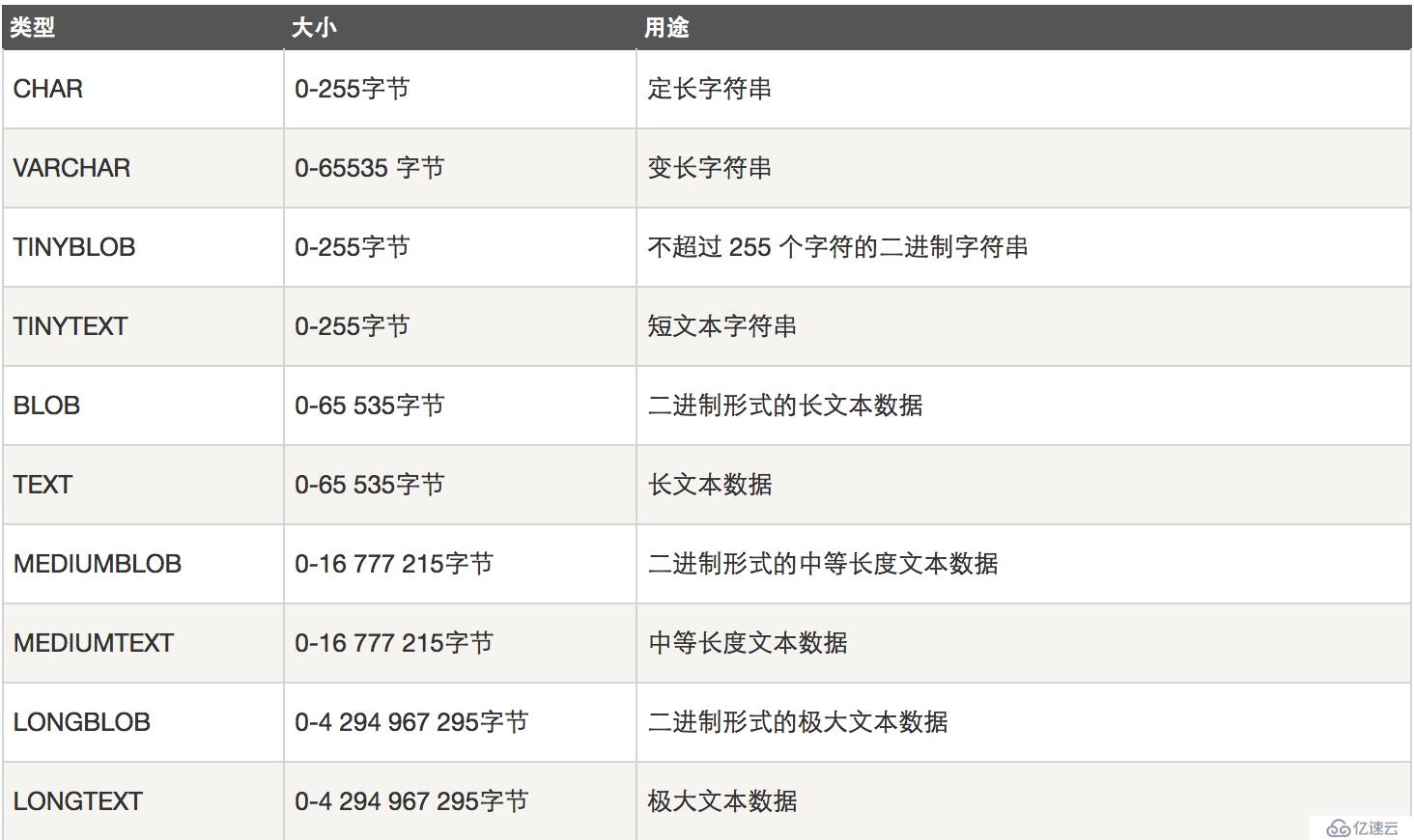
CHAR和VARCHAR类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY和VARBINARY类类似于CHAR和VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。
BLOB是一个二进制大对象,可以容纳可变数量的数据。有4种BLOB类型:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。它们只是可容纳值的最大长度不同。
有4种TEXT类型:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。这些对应4种BLOB类型,有相同的最大长度和存储需求。
三、数据库中的表操作。
1.在数据库中创建表。
create table 表名 (字段以及每个字段的属性,每个字段以逗号分隔)
例:
create table tb1( id int primary key auto_increment ,name char(20),gender bit default 1, birthday date,entry_date date,job char(20),salary double(4,2) unsigned, resume text );
!!这里的primary key 属性,就是主键了,那么什么是主键呢?
主键有两个特点,就是非空并且值唯一。
auto_increment这个属性是自增的意思,当主键字段是数字类型时可以使用,它可以让数值自增。
2.查看数据库中某个表的结构以及信息。
2.1查看一张表的表结构:desc tab_name;
例如:
desc tb1;
2.2 查看当前数据库中所有的表:
show tables;
2.3 查看创建表时使用的sql语句:
show create table 表名;
例如:
show create table tb1 \G;
3.修改表结构。
3.1 给表增加一个字段:
格式: alter table tab_name add [column] 列名 类型[完整性约束条件][first|after 字段名];
#其中的first和after是可选参数(可以不用,这两个参数,如果不写,默认添加的字段是在最后面)
#first是指添加到第一个字段的位置。
#after 是添加到某个字段的后面。
alter table user add addr varchar(20) not null unique first/after username
3.2 添加多个字段的示例:
alter table users2
add addr varchar(20),
add age int first,
add birth varchar(20) after name;
3.3 修改表中某个字段的类型:
alter table tab_name modify 列名 类型 [完整性约束条件][first|after 字段名];
例:
alter table users2 modify age tinyint default 20;
alter table users2 modify age int after id;
修改表中字段的名字:
alter table tab_name change [column] 列名 新列名 类型 [完整性约束条件][first|after 字段名];
alter table users2 change age Age int default 28 first;
3.4删除一个字段:
alter table tab_name drop [column] 列名;
3.5修改一个表名:
rename table 表名 to 新表名;
3.6修改表字符集:
alter table student character set utf8;
3.7 删除整张表:
drop table 表名;
3.8 为表中字段增加主键约束:
alter table tab_name add primary key(字段名称,...)
3.9 删除字段中的主键约束:
先删除自增长在删除主键
Alter table tb1 change id id int(11);//删除自增长
Alter table tb1 drop primary key;//删除主建
3.10 添加唯一索引:
格式:
alter table tab_name add unique [index|key] [索引名称](字段名称,...)
例:
alter table users add unique(name)
alter table users add unique key user_name(name);
3.11 添加联合索引:
alter table users add unique index name_age(name,age);#show create table users;
3.12 删除唯一索引:
alter table tab_name drop {index|key} index_name;
四.对表中的记录进行操作。
insert 在表中插入记录:
格式:insert [into] tab_name (field1,filed2,.......) values (value1,value2,.......)
例:
insert into employee_new (id,name,birthday) values(1,'ayumi','1978-10-02');
同时插入多条数据:
insert into employee_new values (4,'alvin1','1993-04-20'), (5,'alvin2','1995-05-12);
以键值对的方式插入数据:
格式:
insert [into] tab_name set 字段名=值
例:
insert into employee_new set id=130,name="bitch jolin"
2. update 修改表中记录:
格式:
update tab_name set field1=value1,field2=value2,......[where 语句]
例:
update employee_new set birthday="1995-09-05" WHERE id=1;
#PDATE语法可以用新值更新原有表行中的各列。
#SET子句指示要修改哪些列和要给予哪些值。
#WHERE子句指定应更新哪些行。如没有WHERE子句,则更新所有的行.
另外一个用法示例:
--- 将suhaozhi的薪水在原有基础上增加130元。
update employee_new set salary=salary+130 where name='suhaozhi';
3.delete 删除表中的一个记录:
格式:
delete from tab_name [where ....]
#delete语句如果不跟where语句则删除整张表中的数据
#delete只能用来删除一行记录
#delete语句只能删除表中的内容,不能删除表本身,想要删除表,用drop。
#TRUNCATE TABLE也可以删除表中的所有数据,词语句首先摧毁表,再新建表。此种方式删除的数据不能在事务中恢复。
例:
删除tb1这个表中,name字段为suhaozhi的记录。
delete from tb1 where name='suhaozhi';
删除表中的所有记录:
delete from tb1;
使用truncate删除表中记录:
truncate table tb1;
#TRUNCATE TABLE也可以删除表中的所有数据,词语句首先摧毁表,再新建表。此种方式删除的数据不能在事务中恢复。
4.select 查询语句:
select 查询语句的基本格式:
SELECT *|field1,filed2 ... FROM tab_name
WHERE 条件
GROUP BY field
HAVING 筛选
ORDER BY field
LIMIT 限制条数
下面是关于select 查询语句的示例:
create table tb2( id int primary key auto_increment, name varchar(20), yuwen DOUBLE, shuxue DOUBLE, yingyu double );
insert into tb2 values( 1,"aaa",98,98,99), (2,"bbb",35,98,66), (3,"ccc",59,59,62), (4,"ddd",88,89,87), (5,"eee",100,65,88);
现在有一张成绩表,表里有五条记录:
select * from tb2;
+----+------+-------+--------+--------+
| id | name | yuwen | shuxue | yingyu |
+----+------+-------+--------+--------+
| 1 | aaa | 98 | 98 | 99 |
| 2 | bbb | 35 | 98 | 66 |
| 3 | ccc | 59 | 59 | 62 |
| 4 | ddd | 88 | 89 | 87 |
| 5 | eee | 100 | 65 | 88 |
+----+------+-------+--------+--------+
5 rows in set (0.03 sec)
查看整张表:
select * from tb2;
查看name字段为ddd的语文和数学成绩:
select yuwen,shuxue from tb2 where name="ddd";
列出所有学员的语文和英语的成绩:
select yuwen,yingyu from tb2;
#其中from指定从哪张表筛选,*表示查找所有列,也可以指定一个列
#表明确指定要查找的列,distinct用来剔除重复行。
select 与数学计算表达式与as别名:
select name,yuwen+shuxue+yingyu from tb2; #显示每个学生,语文数学英语的总和。
+------+---------------------+
| name | yuwen+shuxue+yingyu |
+------+---------------------+
| aaa | 295 |
| bbb | 199 |
| ccc | 180 |
| ddd | 264 |
| eee | 253 |
+------+---------------------+
使用字段别名后:
select name as '姓名' ,yuwen+shuxue+yingyu as '总成绩' from tb2;
+--------+-----------+
| 姓名 | 总成绩 |
+--------+-----------+
| aaa | 295 |
| bbb | 199 |
| ccc | 180 |
| ddd | 264 |
| eee | 253 |
+--------+-----------+
使用where语句,进行查询过滤:
例1:找出英语成绩大于90分的学员:
select * from tb2 where yingyu > 90;
例2:找出总成绩大于200分的所有学员的名字和成绩:
select name as '姓名' ,yuwen+shuxue+yingyu as '总成绩' from tb2 where yuwen+shuxue+yingyu > 200;
+--------+-----------+
| 姓名 | 总成绩 |
+--------+-----------+
| aaa | 295 |
| ddd | 264 |
| eee | 253 |
+--------+-----------+
where语句中可以使用的比较运算符补充:
> < >= <= <> !=
between 80 and 100 值在10到20之间
in(80,90,100) 值是10或20或30
like 'yuan%'
like 模糊匹配
在多个条件直接可以使用逻辑运算符 and or not
例1:显示出语文成绩在70~100分之间的学员姓名以及语文成绩。
select name,yuwen from tb2 where yuwen between 70 and 100;
+------+-------+
| name | yuwen |
+------+-------+
| aaa | 98 |
| ddd | 88 |
| eee | 100 |
+------+-------+
例2:显示出数学成绩为98,65,59的学员分之间的学员姓名以及数学成绩。
select name,shuxue from tb2 where shuxue in (98,65,59);
+------+--------+
| name | shuxue |
+------+--------+
| aaa | 98 |
| bbb | 98 |
| ccc | 59 |
| eee | 65 |
+------+--------+
例3:显示所有name为a开头的成绩信息。
select * from tb2 where name like 'a%';
+----+------+-------+--------+--------+
| id | name | yuwen | shuxue | yingyu |
+----+------+-------+--------+--------+
| 1 | aaa | 98 | 98 | 99 |
+----+------+-------+--------+--------+
例4:找出所有语文成绩和数学成绩都小于90分的学员信息。
select * from tb2 where yuwen < 90 and shuxue < 90;
+----+------+-------+--------+--------+
| id | name | yuwen | shuxue | yingyu |
+----+------+-------+--------+--------+
| 3 | ccc | 59 | 59 | 62 |
| 4 | ddd | 88 | 89 | 87 |
+----+------+-------+--------+--------+
例5:找出成绩为空的学员。
select name from tb2 where yuwen is null
!排序:Order by 指定排序的列,排序的列即可是表中的列名,也可以是select 语句后指定的别名。
基本格式:
select *|field1,field2... from tab_name order by field [Asc|Desc]
#Asc 升序、Desc 降序,其中asc(升序)为默认值 ORDER BY 子句应位于SELECT语句的结尾。
例:以数学成绩为基准排列。
select * from tb2 order by shuxue;
+----+------+-------+--------+--------+
| id | name | yuwen | shuxue | yingyu |
+----+------+-------+--------+--------+
| 3 | ccc | 59 | 59 | 62 |
| 5 | eee | 100 | 65 | 88 |
| 4 | ddd | 88 | 89 | 87 |
| 1 | aaa | 98 | 98 | 99 |
| 2 | bbb | 35 | 98 | 66 |
+----+------+-------+--------+--------+
例2:把所有学生的总成绩,从高到低输出:
select name as '姓名',yuwen+shuxue+yingyu as '总成绩' from tb2 order by 总成绩 desc;
+--------+-----------+
| 姓名 | 总成绩 |
+--------+-----------+
| aaa | 295 |
| ddd | 264 |
| eee | 253 |
| bbb | 199 |
| ccc | 180 |
+--------+-----------+
分组查询:
示例准备:
create table test_menu( id int primary key auto_increment, product_name varchar(20), price float(6,2), born_date DATE, class varchar(20) );
INSERT INTO test_menu (product_name,price,born_date,class) VALUES
("苹果",20,20170612,"水果"),
("香蕉",80,20170602,"水果"),
("水壶",120,20170612,"电器"),
("被罩",70,20170612,"床上用品"),
("音响",420,20170612,"电器"),
("床单",55,20170612,"床上用品"),
("草莓",34,20170612,"水果");
#注意,按分组条件分组后每一组只会显示第一条记录.
#group by字句,其后可以接多个列名,也可以跟having子句,对group by 的结果进行筛选。
现在有一张表:
+----+--------------+--------+------------+--------------+
| id | product_name | price | born_date | class |
+----+--------------+--------+------------+--------------+
| 1 | 苹果 | 20.00 | 2017-06-12 | 水果 |
| 2 | 香蕉 | 80.00 | 2017-06-02 | 水果 |
| 3 | 水壶 | 120.00 | 2017-06-12 | 电器 |
| 4 | 被罩 | 70.00 | 2017-06-12 | 床上用品 |
| 5 | 音响 | 420.00 | 2017-06-12 | 电器 |
| 6 | 床单 | 55.00 | 2017-06-12 | 床上用品 |
| 7 | 草莓 | 34.00 | 2017-06-12 | 水果 |
+----+--------------+--------+------------+--------------+
按照字段的位置进行分组:
select * from test_menu group by 5;
#这个5代表了当前表从左数第五个字段。
+----+--------------+--------+------------+--------------+
| id | product_name | price | born_date | class |
+----+--------------+--------+------------+--------------+
| 4 | 被罩 | 70.00 | 2017-06-12 | 床上用品 |
| 1 | 苹果 | 20.00 | 2017-06-12 | 水果 |
| 3 | 水壶 | 120.00 | 2017-06-12 | 电器 |
+----+--------------+--------+------------+--------------+
#从左数第5个字段是class,按分组条件分组后每一组只会显示第一条记录。
对购物表按类名class字段分组后显示每一组商品的价格总和:
select class,sum(price) from test_menu group by class;
+--------------+------------+
| class | sum(price) |
+--------------+------------+
| 床上用品 | 125.00 |
| 水果 | 134.00 |
| 电器 | 540.00 |
+--------------+------------+
对购物表按类名class字段分组后显示每一组商品价格总和超过150的商品。
select class,sum(price) from test_menu group by class having sum(price) > 150;
+--------+------------+
| class | sum(price) |
+--------+------------+
| 电器 | 540.00 |
+--------+------------+
#!!!! 在这里特别强调一点!having和where虽然都可以对查询结果做过滤!!但是它们是有区别的!
where只能用于分组前的筛选!! 而having则可以用于分组后的筛选!这是因为having可以使用聚合函数!!where中不可以!!!!!!这点牢记!
常用的聚合函数补充:
一般情况下,聚合函数会配合分组查询去使用。
#把要求的内容查出来再包上聚合函数即可。
count 统计行个数。
例1:统计这张表一共有多少行记录
select count(*) from test_menu;
例2:统计数学成绩大于70的有多少条记录。
select count(*) from tb2 where shuxue > 70;
例3:统计总分大于200的记录有多少?
select count(*) from tb2 where yuwen+shuxue+yingyu > 200;
2.sum 统计满足条件的行的和。
例1:统计这个班的语文总成绩。
select sum(yuwen) as '语文总成绩' from tb2;
+-----------------+
| 语文总成绩 |
+-----------------+
| 380 |
+-----------------+
例2:统计这个班各科的总成绩。
select sum(yuwen),sum(shuxue),sum(yingyu) from tb2;
例3:求班级语文成绩的平均值。
select sum(yuwen)/count(*) from tb2;
3.avg求平均值。
例1: 求班级语文成绩的平均值。
select avg(yuwen) from tb2;
例2: 求班级总和的平均分。
select avg(yuwen+shuxue+yingyu) from tb2;
4.max&min 求最高值或者最低值。
例:
select max(yuwen+shuxue+yingyu) from tb2;
select min(yuwen+shuxue+yingyu) from tb2;
5.ifnull 将空值转换为指定的值。
注意!!!!!null 和所有的数计算都是null,所以需要用ifnull将null转换为0!!!
例:ifnull(yuwen,0)
6.limit 指定查找出记录的数量。
select * from tb2 limit 1; #只显示出结果的第一行。
select * from tb2 limit 2,5; #跳过前两行,显示接下来的后5行。
7.REGEXP 使用正则表达式进行查询。
select * from tb2 where name regexp '^a';
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





