这篇文章主要介绍Oracle优化器的示例分析,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
一、优化器的模式
优化器的模式用于决定在Oracle中解析目标SQL时所用优化器的类型,以及决定当使用CBO时计算成本值的侧重点。这里的“侧重点”是指当使用CBO来计算目标SQL各条执行路径的成本值时,计算成本值的方法会随着优化模式的不同而不同。
在Oracle数据库中,优化器的模式是由参数OPTIMIZER_MODE的值决定的,OPTIMIZER_MODE的值可能是RULE、CHOOSE、FIRST_ROWS_n(N=1,10,100,1000)、FIRST_ROWS或ALL_ROWS。
OPTIMIZER_MODE的各个可能的值的含义为如下所示:
1.RULE
RULE表示Oracle将使用RBO来解析目标SQL,此时目标SQL中所涉及的各个对象的统计信息对于RBO来说没有任何作用。
2.CHOOSE
CHOOSE是Oracle9i中OPTIMIZER_MODE的默认值,它表示Oracle在解析目标SQL是到底是使用RBO还是使用CBO取决于该SQL中所涉及的表对象是否有统计信息。具体来说就是:只要该SQL中所涉及的表对象中有一个有统计信息,那么Oracle在解析该SQL时就会使用CBO;如果该SQL中所涉及的所有表对象均没有统计信息,那么此时Oracle会使用RBO。
3.FIRST_ROWS_n(n=1,10,100,1000)
其含义是指当OPTIMIZER_MODE的值为FIRST_ROWS_n(n=1,10,100,1000)时,Oracle会使用CBO来解析目标SQL,且此时CBO在计算该SQL的各条执行路径的成本值时的侧重点在于以最快的响应速度返回头n(n=1,10,100,1000)条记录。Oracle会把那些最快的响应速度返回头(n=1,10,100,1000)条记录所对应的执行步骤的成本修改成一个很小的值(远小于默认情况下CBO对同样执行步骤所计算出的成本值)。这样Oracle就既没有违背CBO选择执行计划的总原则(成本值最小),同样又兼顾 了FIRST_ROWS_n(n=1,10,100,1000)的含义。
4.FIRST_ROWS
FIRST_ROWS是一个在Oracle9i中就已经过时的参数,它表示Oracle在解析目标SQL是会联合使用CBO和RBO。这里联合使用CBO和RBO的含义是指在大多数情况下,FIRST_ROWS还是会使用CBO来解析目标SQL,且此时CBO在计算该SQL的各条执行路径的成本值时的侧重点在于以最快的响应速度返回头几条记录(类似于FIRST_ROWS_n);但是,当出现一些特定情况时,FIRST_ROWS转而会使用RBO中的一些内置规则来选取执行计划而不再考试成本。比如当OPTIMIZER_MODE的值为FIRST_ROWS有一个内置的规则,就是如果Oracle发现能用相关的索引来避免排序,则Oracle就会选择该索引所对应的执行路径而不再考虑成本,这显然是不合理的。与这对应的,在当OPTIMIZER_MODE的值为FIRST_ROWS的情形下,你会发现索引全扫描出现的概率会比之前有所增加,这是因为走索引全面扫描能够避免排序的缘故。
5.ALL_ROWS
ALL_ROWS是Oracle 10g以及后续Oracle数据库版本中OPTIMIZER_MODE的默认值,它表示Oracle会使用CBO来解析目标SQL,且此时CBO在计算该SQL的各条执行路径的成本值时的侧重点在于最佳的吞吐量(即最小的系统I/O和CPU资源的消耗量)。
实际上,成本的计算方法随着优化器模式的不同而不同,主要体现在ALL_ROWS和FIRST_ROWS_n(n=1,10,100,1000)对成本值计算方法的影响上。当优化器模式为ALL_ROWS时,CBO计算成本的侧重点在于最佳的吞吐量;而当优化器模式为FIRST_ROWS_n(n=1,10,100,1000)时,CBO计算成本的侧重点会变为以最快的响应速度返回头n(n=1,10,100,1000)条记录。这意味着同样的执行步骤,在优化器模式不同时CBO分别计算出来的成本会存在巨大的差异,这也就意味着优化器对CBO计算成本(进而对CBO选择执行计划)有着决定性的影响。
二、结果集
结果集(Row Source)是指包含指定执行结果的集合。对于优化器而言(无论是RBO还是CBO),结果集和目标SQL执行计划的执行步骤相对应,一个执行步骤所产生的执行结果就是该执行步骤所对应的输出结果集。
对于目标SQL的执行计划而言,其中某个执行步骤的输出结果就是该执行步骤所对应的输出结果集,同时,该执行步骤所对应的输出结果集可能就是下一个执行步骤的输入结果集。这样一步一步执行下来,伴随的就是结果集在各个执行步骤之间的传递,等目标SQL执行计划的各个执行步骤全部执行完毕后,最后的输出结果集就是该SQL最终的执行结果。
对于RBO而言,我就在对应的执行计划中看不到相关执行步骤所对应的结果集的描述,虽然结果集的概念对于RBO来说也同样适用。
对于CBO而言,对应执行中的Rows列反映的就是CBO对于相关执行步骤所对应输出结果集的记录数(即Cardinality)的估算值。
三、访问数据的方法
对于优化器而言,它在解析目标SQL、得到其执行计划时至关重要的一点是决定访问数据的方法,即优化器要决定采用什么样的方式和方法去访问目标SQL所需要访问的存储在Oracle数据库中的数据。
目标SQL所需要访问的数据一般存储在表,而Oracle访问表中数据的方法有两种:一种是直接访问表;另一种是先访问索引,再回表(当然,如果目标SQL所访问的数据只通过访问相关的索引就可以得到,那么此时就不需要再回表了)。
3.1访问表的方法
Oracle数据库中直接访问表中数据的方法有两种:一种是全表扫描;另一种是ROWID扫描。
3.1.1 全表扫描
全表扫描是指Oracle在访问目标表里的数据时,会从该表所占用的第一个区(EXTENT)的第一个块(BLOCK)开始扫描,直接扫描到该表的高水位线(HWM,High Water Mark),这段范围内所有的数据块Oracle都必须读到。当然,Oracle会对这期间读到的所有数据施加目标SQL的where条件中指定的过滤条件,最后只返回那些满足过滤条件的数据。
不是说全表扫描不好,事实上Oracle在做全表扫描操作时会使用多块读,这在目标表的数据不大时执行效率是非常高的,但全表扫描最大的问题就在于走全表扫描的目标SQL执行时间会不稳定、不可控,这个执行时间一定会随着目标表数据量的递增而递增。因为随着目标表数据量的递增,它的高水位线会一直不段往上涨,所以全表扫描时所需要读取的数据块的数据也会不断增加。
在Oracle中如果对目标表不停地插入数据,当分配给该表的现有空间不足时高水位线就会向上移动,但如果你用DELETE语句从该表删除数据,则高水位线并不会随之往下移动。高水位线这种特性所带来的副作用是,即使使用DELETE删光了目标表中的所有数据,高水位线还是会在原来的位置,这意味着全表扫描该表时Oacle还是需要扫描该表高水位线下所有的数据块,此时对该表的全表扫描操作耗费的时间与之前相比并不会有明显的改观。
3.1.2 ROWID扫描
ROWID扫描是指Oracle在访问目标表里的数据时,直接通过数据所在的ROWID去定位并访问这些数据。ROWID表示的是Oracle中的数据行记录所在的物理存储地址,也就是说ROWID实际上是和Oracle数据块里的行记录一一对应的。
既然ROWID代表的就是表的数据行所在的物理存储地址,那么当Oracle知道待访问的数据行所在的ROWID后,自然就可以根据该RWOID去直接访问对应表的相关数据行,这就是ROWID扫描的含义。
从严格意义上来说,Oracle中的ROWID扫描有两层含义:一种是根据用户在SQL语句中输入的ROWID的值去直接访问对应的数据行记录;另外一种方法是先去访问相关的索引,然后根据访问索引后得到的ROWID再回表去访问对应的数据行。
对Oracle中的堆表而言,我们可以通过Oracle内置的ROWID伪列得到对应行记录所在的ROWID值,然后还可以通过DBMS_ROWID包中的相关方法将ROWID伪列的值翻译成对应数据行的实际物理存储地址。
3.2 访问索引的方法
这里提到的索引是指最常用的B*Tree索引
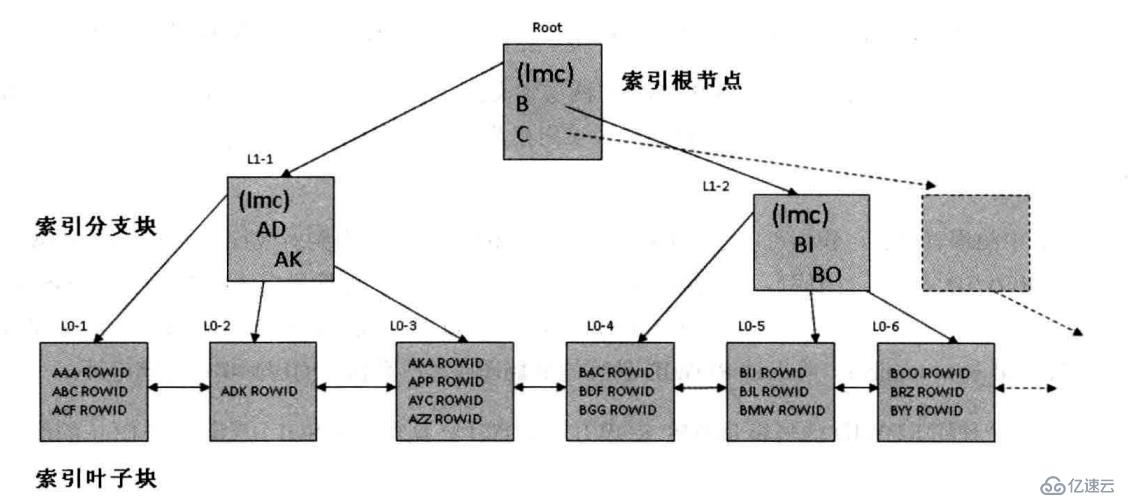
Oracle数据库的的B*Tree索引就好像一棵倒长的树,它包含两种类型的数据块,一种是索引分支块,另一种是索引叶子块。
索引分支块包含指向相应索引分支块/叶子块的指针和索引键值列(这里的指针是指相关分支块/叶子块的块地址RDBA。每个索引分支块都会有两种类型的指针,一种是lmc,另一种是索引分支块的索引行记录所记录的指针。lmc是Left Most Child的缩写,每个索引分支块都只有一个lmc,这个lmc指向的分支块/叶子块中的所有索引键值列中的最大值一定小于该lmc所在索引分支块的所有索引键值列中的最小值;而索引分支块的索引行记录所记录的指针所指向的分支块/叶子块的所有索引键值列中的最小值一定大于或等于该行记录的索引键值列的值)。这个索引列值不一定就是完整的被索引键值,它可能只是被索引键值的前缀,只要Oracle能通过这些前缀区分相应的索引分支块/叶子块就行,这样Oracle就能够既节省分支块的存储空间,又可以快速定位其下层的索引分支块/叶子块。索引分支块最上层的那个块就是所谓的索引根节点。在Oracle里访问B*Tree索引的操作都必须从根节点开始,即都会经历一个从根节点到分支块再到叶子块的过程。
索引叶子块包含被索引键值和用于定位该索引键值所在的数据行在表中实际物理存储位置的ROWID。对于唯一性的B*Tree索引而言,ROWID是存储在索引行的行头,所以此时Oracle并不需要额外礁该ROWID的长度。而对于非唯一性的B*Tree索引而言,ROWID被当作额外的列与被索引的键值列一起存储,所以此时Oracle既要存储ROWID,同时又要存储其长度,这意味着在同等条件下,唯一性B*Tree索引要比非唯一性B*Tree索引节省索引叶子块的存储空间。对于非唯一性索引而言,B*Tree索引的有序性体现在Oralce会按照被索引键值和相应的ROWID来联合排序。Oralce里的索引叶子块是左右互联的,即相当于有一个双向指针链表把这些索引叶子块互相连接在了一起。
3.2.1 索引唯一性扫描
索引唯一性扫描(INDEX UNIQUE SCAN)是针对唯一性索引(UNIQUE INDEX)的扫描,它仅仅适用于where条件里等值查询的目标SQL。因为扫描的对象是唯一性索引,所以索引唯一性扫描的结果至多只会返回一条记录。
3.2.2 索引范围扫描
索引范围扫描(INDEX RANGE SCAN)适用于所有类型的B*Tree索引,当扫描的对象是唯一性索引时,此时目标SQL的where条件一定是范围查询(谓词条件为BETWEEN、<、>等);当扫描的对象是非唯一性索引时,对目标SQL的where条件没有限制(可以是等值查询,也可以是范围查询)。索引范围扫描的结果可能会返回多条记录,其实这就是索引范围扫描中的“范围”二字的本质含义。
在同等条件下,当目标索引的索引行的数量大于1时,索引扫描范围所耗费的逻辑读至少会比生意人索引唯一性扫描的逻辑读多1。因为扫描结果可能会返回多条记录,又因为目标索引的索引行数量大于1,Oracle为了确定索引范围扫描的扫描终点,就不得不去多次访问相关的叶子块。
3.2.3 索引全扫描
索引全扫描(INDEX FULL SCAN)适用于所有类型的B*Tree索引(包括唯一性索引和非唯一性索引)。所谓的“索引全扫描”,就是指要扫描目标索引所有叶子块的所有索引行。这里需要注意的是,索引全扫描需要扫描目标索引的所有叶子块,但并不意味着需要扫描该索引的所有分支块。在默认情况下,Oracle在做索引全扫描时只需通过访问必要的分支块定位到位置该索引最左边的叶子块的第一行索引行,就可以利用该索引叶子块之间的双向指针链表,从左至右依次顺序扫描该索引所有叶子块的所有索引行了。由于索引是有序的,所以索引全扫描的执行结果也是有序的,并且是按照索引的索引键值列来排序,这也意味着走索引全扫描能够既达到排序的效果,又同时避免了对该索引的索引键值列的真正排序操作。
默认情况下,索引全扫描的扫描结果的有序性就决定了索引全扫描是不能够并行执行的,并且通常情况下索引全扫描使用的是单块读。
通常情况下,索引全扫描是不需要回表的,所以索引全扫描适用于目标SQL的查询全部是目标索引的索引键值列的情形。我们知道,对于Oracle数据库的B*Tree索引而言,当所有索引键值列全为NULL值时不入索引,这意味着Oracle中能做索引全扫描的前提条件是目标索引至少有一个索引键值列的属性是NOT NULL。这很显然,如果目标索引的所有索引键值列的属性均为允许NULL值,此时如果还走索引全扫描,就会漏掉目标表中那些索引值列均为NULL的记录,即此时走索引全扫描的结果就不准了!Oracle不允许这种事情发生。
3.2.4 索引快速全扫描
索引快速全扫描(INDEX FAST FULL SCAN)和索引全扫描极为类似,它也适用于所有类型的B*Tree索引。和索引全扫描一样,索引快速全扫描也需要扫描目标索引所有叶子块的所有索引行。
索引快速全扫描与索引全扫描相比有如下三点区别:
1)索引快速全扫描只适用于CBO。
2)索引快速全扫描可以使用多块读,也可以并行执行。
3)索引快速全扫描的执行结果不一定是有序的。这是因为索引快速全扫描时Orace是根据索引行在磁盘上的物理存储顺序来扫描,而不是根据索引行的逻辑顺序来扫描的,所以扫描结果才不一定有序(对于单个索引叶子块的索引行而言,其物理存储顺序和逻辑存储顺序一致;但对于物理存储位置相邻的索引叶子块而言,块与块之间索引行的物理存储顺序则不一定在逻辑上有序)。
3.2.5 索引跳跃式扫描
索引跳跃式扫描(INDEX SKIP SCAN)适用于所有类型的复合B*Tree索引,它使那些在where条件中没有对目标索引的前导列指定查询条件,但同时又对该索引的非前导列指定了查询条件的目标SQL依然可以使用上该索引,这就像是在扫描该索引时跳过了它的前导列,直接从该索引的非前导到开始扫描一样(实际执行过程并非如此),这民是索引跳跃式扫描中“跳跃”(SKIP)一词的含义。
Oracle中的索引跳跃式扫描仅仅适用于那些目标索引前导导列的distinct值数量较少,后续非前导列的可选择性又非常好的情形,因为索引跳跃式扫描的执行效率一定会随着目标索引前导列的distinct值数量的递增而递减。
以上是“Oracle优化器的示例分析”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





