这篇文章将为大家详细讲解有关knn和k-means有哪些区别,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
knn和k-means的区别:1、【k-means】算法典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大;2、knn算法没有明显的前期训练过程,程序开始运行时,把数据集加载到内存后开始分类。
knn和k-means的区别:
1. k-means聚类算法过程与原理
k-means算法(k-均值聚类算法)是一种基本的已知聚类类别数的划分算法。它是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。它是使用欧氏距离度量的(简单理解就是两点间直线距离,欧氏距离只是将这个距离定义更加规范化,扩展到N维而已)。它可以处理大数据集,且高效。聚类结果是划分为k类的k个数据集。根据聚类结果的表达方式又可以分为硬 k-means(H CM)算法、模糊k-means算法(F CM)和概率k-means算法(P CM)。
1.1.基本思想
它是基于给定的聚类目标函数,算法采用迭代更新的方法,每一次迭代过程都是向目标函数减小的方向进行,最终聚类结果使得目标函数取得极小值,达到较好的分类效果
1.2 原理
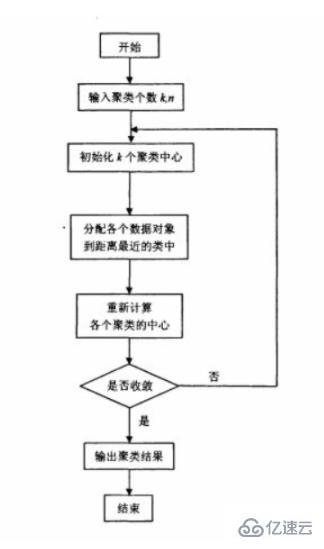
原始的k-means算法首先随机选取k个点作为初始聚类中心,然后计算各个数据对 象到各聚类中心的距离,把数据对象归到离它最近的那个聚类中心所在的类; 调整后的新类计算新的聚类中心,如果相邻两次的聚类中心没有任何变化,说明 数据对象调整结束,聚类准则函数f已经收敛。在每次迭 代中都要考察每个样本的分类是否正确,若不正确,就要调整。在全部数据调整 完后,再修改聚类中心,进入下一次迭代。如果在一次迭代算法中,所有的数据 对象被正确分类,则不会有调整,聚类中心也不会有任何变化,这标志着f已 经收敛,算法结束。
1.3 算法流程图
1.4 算法初始点怎么选择?
1) 选择批次距离尽可能远的K个点
首先随机选择一个点作为第一个初始类簇中心点,然后选择距离该点最远的那个点作为第二个初始类簇中心点,然后再选择距离前两个点的最近距离最大的点作为第三个初始类簇的中心点,以此类推,直至选出K个初始类簇中心点。
2) 选用层次聚类或者Canopy算法进行初始聚类,然后利用这些类簇的中心点作为K-Means算法初始类簇中心点。
1.5算法中的k如何选取?
只要我们假设的类簇的数目等于或者高于真实的类簇的数目时,该指标上升会很缓慢,而一旦试图得到少于真实数目的类簇时,该指标会急剧上升。类簇指标 作为一个重要的参考指标。
类簇的直径是指类簇内任意两点之间的最大距离。
类簇的半径是指类簇内所有点到类簇中心距离的最大值。
1.6 优缺点以及如何改进?
使用简单,是因为它使用了一个随机的元素,所以它不能保证找到最佳的类。 无需要一个合理初始化要聚类的个数:即要初始化K 。
2. K-最近邻分类算法(K N N)
2.1 问题引入
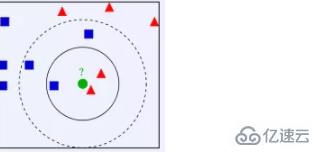
K N N的思想: 从上图中我们可以看到,图中的数据集是良好的数据,即都打好了label,一类是蓝色的正方形,一类是红色的三角形,那个绿色的圆形是我们待分类的数据。 如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形 如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形 即如果一个样本在特征空间中的k个最相邻的样本中,大多数属于某一个类别,则该样本也属于这个类别。我们可以看到,K N N本质是基于一种数据统计的方法!其实很多机器学习算法也是基于数据统计的。
2.2 K N N算法
介绍
K N N即K-Nearest Neighbor,是一种memory-based learning,也叫instance-based learning,属于lazy learning。即它没有明显的前期训练过程,而是程序开始运行时,把数据集加载到内存后,不需要进行训练,就可以开始分类了。 K N N也是一种监督学习算法,通过计算新数据与训练数据特征值之间的距离,然后选取K(K>=1)个距离最近的邻居进行分类判(投票法)或者回归。若K=1,新数据被简单分配给其近邻的类。
步骤
1)计算测试数据与各个训练数据之间的距离;可以使用欧式距离的公式来进行计算。
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点(k值是由自己来确定的)
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
特点
非参数统计方法:不需要引入参数 K的选择: K = 1时,将待分类样本划入与其最接近的样本的类。 K = |X|时,仅根据训练样本进行频率统计,将待分类样本划入最多的类。 K需要合理选择,太小容易受干扰,太大增加计算复杂性。 算法的复杂度:维度灾难,当维数增加时,所需的训练样本数急剧增加,一般采用降维处理。
2.3 算法的优缺点
优点:简单、有效
缺点:计算量较大。输出的可解释性不强。需要存储全部的训练样本。
3. K N N与k-means的区别
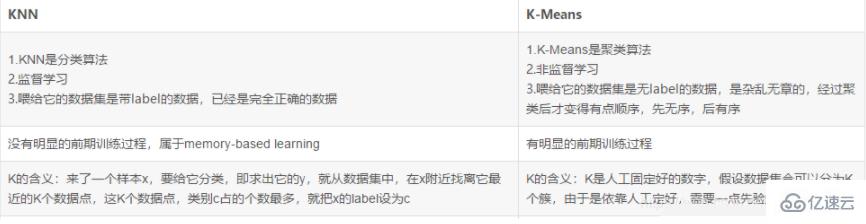
关于knn和k-means有哪些区别就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



