这篇文章将为大家详细讲解有关JavaScript如何实现常用数据结构,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
在 JavaScript 中数据结构通常总是被忽略,或者接触得不多。但是对于许多大厂而言,一般都需要你深刻了解如何管理数据。掌握数据结构也能够在解决问题时为你的工作提供帮助。
在本文中,我们将要讨论并实现的数据结构是:
栈
队列
链表
哈希表
树
第一个数据结构是栈。它与队列非常相似,你之前可能听说过调用栈,这是 JavaScript 用于处理事件的方法。
栈看起来像这样:

最后一个存入栈里的项目将是第一个被移除的项目。这被称为后进先出(LIFO)。 Web 浏览器中的后退按钮就是一个很好的例子:将你查看的每个页面添加到栈中,当你单击“返回”时,将从栈中弹出当前页面(最后添加的页面)。
理论足够多了。接下来看一些代码:
class Stack {
constructor() {
// 创建栈结构,这是一个空对象
this.stack = {}
}
// 把一个值压入栈的顶部
push(value) {
}
// 弹出栈顶的值并返回
pop() {
}
// 读取栈中的最后一个值,但是不删除
peek() {
}
}我已经对上面的代码进行了注释,现在咱们一起对其进行实现。第一种方法是 push。
先思考一下需要这个方法做的事情:
我们需要接受一个值
然后将该值添加到栈的顶部
还应该跟踪栈的长度,以便知道栈的索引
如果你能够先自己尝试一下,那就太好了,完整的 push 方法实现如下:
class Stack {
constructor() {
this._storage = {};
this._length = 0; // 这是栈的大小
}
push(value) {
// 将值添加到栈顶
this._storage[this._length] = value;
// 因为增加了一个值,所以也应该将长度加1
this._length++;
}
/// .....
}我敢打赌,这比你想象的要容易。有许多类似这样的结构,它们听起来比实际上要复杂得多。
现在是 pop 方法。 pop 方法的目标是删除最后一个添加到栈中的值,然后返回它。如果可以的话,请先自己尝试实现:
class Stack {
constructor() {
this._storage = {};
this._length = 0;
}
pop() {
// we first get the last val so we have it to return
const lastVal = this._storage[--this._length]
// now remove the item which is the length - 1
delete this._storage[--this._length]
// decrement the length
this._length--;
// now return the last value
return lastVal
}
}酷!快要完成了。最后一个是 peek 函数,该函数查看栈中的最后一项。这是最简单的功能:只需要返回最后一个值。实现是:
class Stack {
constructor() {
this._storage = {};
this._length = 0;
}
/*
* Adds a new value at the end of the stack
* @param {*} value the value to push
*/
peek() {
const lastVal = this._storage[--this._length]
return lastVal
}
}所以它与 pop 方法非常相似,但不删除最后一项。
Yes!第一个数据结构已经实现。接着是队列,队列与栈非常相似。
接下来讨论队列——希望栈在你的脑子仍然记得很清楚,因为它和队列非常相似。栈和队列之间的主要区别在于队列是先进先出(FIFO)。
可以用图形这样表示:
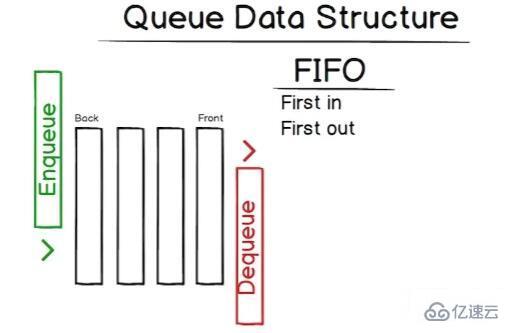
所以两个主要方法是 enqueue 与 dequeue。数据被添加到队尾,并从队首移除。为了更好的理解它,下面开始实现队列。
核心代码结构如下所示:
class Queue {
constructor() {
// 与前面类似,我们为数据结构提供了一个对象
// 并且还有一个变量来保存长度
this.queue = {}
this.length = 0
// 这是一个跟踪头部的新变量
this.head = 0
}
enqueue(value) {
}
dequeue() {
}
peek() {
}
}首先实现 enqueue 方法。其目的是向队尾添加一个项目。
enqueue(value) {
// 使用 value 参数将 length + head 的键添加到对象
this.queue[this.length + this.head] = value;
this.length++
}这是一个非常简单的方法,可以在队列的末尾添加一个值,但是你可能会对this.queue[this.length + this.head] = value;感到困惑。
假设队列看起来像这样的 {14 : 'randomVal'}。在添加这个内容时,我们希望的下一个值为 15,所以应该是 length(1) + head(14),即为 15。
下一个要实现的是 dequeue :
dequeue() {
// 获取第一个值的引用,以便将其返回
const firstVal = this.queue[this.head]
// 现在将其从队列中删除
delete this.queue[this.head]
this.length--;
// 最终增加我们的头成为下一个节点
this.head++;
}最后要实现的是 peek 方法,非常简单:
peek() {
// 只需要把值返回即可
return this.queue[this.head];
}队列实现完毕。
先让我们讨论一下强大的链表。这比上面的结构要复杂得多。
可能你第一个问题是为什么要使用链表?链表主要用于没有动态大小调整数组的语言。链表按顺序组织项目,一个项目指向下一个项目。
链表中的每个节点都有一个 data 值和一个 next 值。下图中 5 是 data 值,next 值指向下一个节点,即值为 10 的节点。
在视觉上,它看起来像这样:

在一个对象中,上面的 LinkedList 看起来像下面的样子
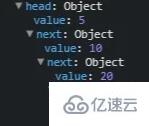
你会看到最后一个值 1 的 next 值为 null,因为这是 LinkedList 的结尾。
那么该如何实现呢?
让我们创建一个具有值 1、 2 和 37的 LinkedList。
const myLinkedList = {
head: {
value: 1
next: {
value: 2
next: {
value: 37
next: null
}
}
}
};现在我们知道了该怎样手动创建 LinkedList,但是还需要编码实现 LinkedList 的方法。
首先要注意的是,LinkedList 只是一堆嵌套对象!
当构造一个 LinkedList 时,我们需要一个 head 和一个 tail,它们最初都会指向头部(因为 head 是第一个也是最后一个)。
class LinkedList {
constructor(value) {
this.head = {value, next: null}
this.tail = this.head
}
}第一个要实现的方法是 insert ,该方法用来在链表的末尾插入一个值。
// insert 将添加到链接列表的末尾
insert(value) {
/* 创建一个节点 */
const node = {value, next: null}
/* 把 tail 的 next 属性设置为新节点的引用 */
this.tail.next = node;
/* 新节点现在是尾节点 */
this.tail = node;
}上面最混乱的一行可能是 this.tail.next = node。之所以这样做,是因为当添加一个新节点时,我们还希望当前的 tail 指向新的 node,该节点将成为新的 tail。第一次插入 node 时,头部的 next 指针将指向新节点,就像在构造函数中那样,在其中设置了 this.tail = this.head。
你还可以到这个网站来查看图形化的演示,这将帮你了解插入的过程(按 esc 摆脱烦人的弹出窗口)。
下一个方法是删除节点。我们首先要决定参数是值( value) 还是对节点(node)的引用(在面试中,最好先问问面试官)。我们的代码中传递了一个“值”。按值从列表中删除节点是一个缓慢的过程,因为必须要遍历整个列表才能找到值。
我这样做是这样的:
removeNode(val) {
/* 从 head 开始 */
let currentNode = this.head
/* 我们需要保留对上一个节点的引用 */
let previousNode
/* 当存在一个节点时,意味着没有到达尾部 */
while(currentNode) {
/* 如果发现自己想要的那个值,那么就退出循环 */
if(currentNode.value === val) {
break;
}
/* 没有找到值就将 currentNode 设置为 previousNode */
previousNode = currentNode
/* 得到下一个节点并将其分配给currentNode */
currentNode = currentNode.next
}
/* 返回undefined,因为没有找到具有该值的节点 */
if (currentNode=== null) {
return false;
}
// 如果节点是 head ,那么将 head 设置为下一个值
头节点的
if (currentNode === this.head) {
this.head = this.head.next;
return;
}
/* 通过将节点设置为前面的节点来删除节点 */
previousNode.next = currentNode.next
}removeNode 方法使我们对 LinkedList 的工作方式有了很好的了解。
所以再次说明一下,首先将变量 currentNode 设置为 LinkedList 的 head,因为这是第一个节点。然后创建一个名为 previousNode 的占位符变量,该变量将在 while 循环中使用。从条件 currentNode 开始 while 循环,只要存在 currentNode,就会一直运行。
在 while 循环中第一步是检查是否有值。如果不是,则将 previousNode 设置为 currentNode,并将 currentNode 设置为列表中的下一个节点。继续进行此过程,直到找到我需要找的值或遍历完节点为止。
在 while 循环之后,如果没有 currentNode,则返回 false,这意味着没有找到任何节点。如果确实存在一个 currentNode,则检查的 currentNode 是否为 head。如果是的话就把 LinkedList 的 head 设置为第二个节点,它将成为 head。
最后,如果 currentNode 不是头,就把 previousNode 设置为指向 currentNode 前面的 node,这将会从对象中删除 currentNode。
另一个常用的方法(面试官可能还会问你)是 removeTail 。这个方法如其所言,只是去掉了 LinkedList 的尾节点。这比上面的方法容易得多,但工作原理类似。
我建议你先自己尝试一下,然后再看下面的代码(为了使其更复杂一点,我们在构造函数中不使用 tail):
removeTail() {
let currentNode = this.head;
let previousNode;
while (currentNode) {
/* 尾部是唯一没有下一个值的节点,所以如果不存在下一个值,那么该节点就是尾部 */
if (!currentNode.next) {
break;
}
// 获取先前节点的引用
previousNode = currentNode;
// 移至下一个节点
currentNode = currentNode.next;
}
// 要删除尾部,将 previousNode.next 设置为 null
previousNode.next = null;
}这些就是 LinkedList 的一些主要方法。链表还有各种方法,但是利用以上学到的知识,你应该能够自己实现它们。
接下来是强大的哈希表。
哈希表是一种实现关联数组的数据结构,这意味着它把键映射到值。 JavaScript 对象就是一个“哈希表”,因为它存储键值对。
在视觉上,可以这样表示:
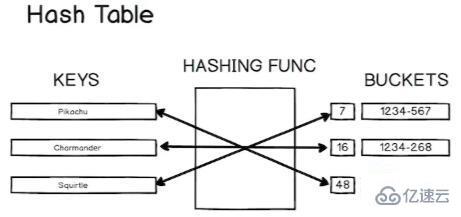
在讨论如何实现哈希表之前,需要讨论讨论哈希函数的重要性。哈希函数的核心概念是它接受任意大小的输入并返回固定长度的哈希值。
hashThis('i want to hash this') => 7哈希函数可能非常复杂或直接。 GitHub 上的每个文件都经过了哈希处理,这使得每个文件的查找都非常快。哈希函数背后的核心思想是,给定相同的输入将返回相同的输出。
在介绍了哈希功能之后,该讨论一下如何实现哈希表了。
将要讨论的三个操作是 insert、get最后是 remove。
实现哈希表的核心代码如下:
class HashTable {
constructor(size) {
// 定义哈希表的大小,将在哈希函数中使用
this.size = size;
this.storage = [];
}
insert(key, value) { }
get() {}
remove() {}
// 这是计算散列密钥的方式
myHashingFunction(str, n) {
let sum = 0;
for (let i = 0; i < str.length; i++) {
sum += str.charCodeAt(i) * 3;
}
return sum % n;
}
}现在解决第一个方法,即 insert。insert 到哈希表中的代码如下(为简单起见,此方法将简单的处理冲突问题):
insert(key, value) {
// 得到数组中的索引
const index = this.myHashingFunction(key, this.size);
// 处理冲突 - 如果哈希函数为不同的键返回相同的索引,
// 在复杂的哈希函数中,很可能发生冲突
if (!this.storage[index]) {
this.storage[index] = [];
}
// push 新的键值对
this.storage[index].push([key, value]);
}像这样调用 insert 方法:
const myHT = new HashTable(5);
myHT.insert("a", 1);
myHT.insert("b", 2);你认为我们的哈希表会是什么样的?
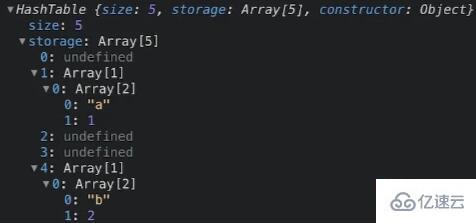
你可以看到键值对已插入到表中的索引 1 和 4 处。
现在实现从哈希表中删除
remove(key) {
// 首先要获取 key 的索引,请记住,
// 哈希函数将始终为同一 key 返回相同的索引
const index = this.myHashingFunction(key, this.size);
// 记住我们在一个索引处可以有多个数组(不太可能)
let arrayAtIndex = this.storage[index];
if (arrayAtIndex) {
// 遍历该索引处的所有数组
for (let i = 0; i < arrayAtIndex.length; i++) {
// get the pair (a, 1)
let pair = arrayAtIndex[i];
// 检查 key 是否与参数 key 匹配
if (pair[0] === key) {
delete arrayAtIndex[i];
// 工作已经完成,所以要退出循环
break;
}
}
}
}最后是 get 方法。这和 remove 方法一样,但是这次,我们返回 pair 而不是删除它。
get(key) {
const index = this.myHashingFunction(key, this.size);
let arrayAtIndex = this.storage[index];
if (arrayAtIndex) {
for (let i = 0; i < arrayAtIndex.length; i++) {
const pair = arrayAtIndex[i];
if (pair[0] === key) {
return pair[1];
}
}
}
}我认为不需要执行这个操作,因为它的作用与 remove 方法相同。
你可以认为它并不像最初看起来那样复杂。这是一种到处使用的数据结构,也是是一个很好理解的结构!
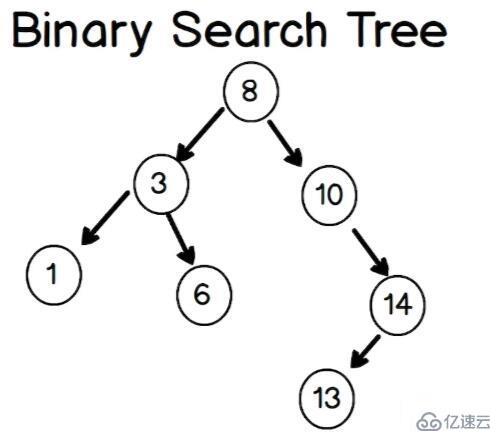
最后一个数据结构是臭名昭著的二叉搜索树。
在二叉搜索树中,每个节点具有零个、一个或两个子节点。左边的称为左子节点,右边的称为右子节点。在二叉搜索树中,左侧的子项必须小于右侧的子项。
你可以像这样描绘一个二叉搜索树:
树的核心类如下:
class Tree {
constructor(value) {
this.root = null
}
add(value) {
// 我们将在下面实现
}
}我们还将创建一个 Node 类来代表每个节点。
class Node {
constructor(value, left = null, right = null) {
this.value = value;
this.left = left;
this.right = right;
}
}下面实现 add 方法。我已经对代码进行了注释,但是如果你发现使你感到困惑,请记住,我们要做的只是从根开始并检查每个节点的 left 和 right。
add(value) {
// 如果没有根,那么就创建一个
if (this.root === null) {
this.root = new Node(value);
return;
}
let current = this.root;
// keep looping
while (true) {
// 如果当前值大于传入的值,则向左
if (current.value > value) {
// 如果存在左子节点,则再次进行循环
if (current.left) {
current = current.left;
} else {
current.left = new Node(value);
return;
}
}
// 值较小,所以我们走对了
else {
// 向右
// 如果存在左子节点,则再次运行循环
if (current.right) {
current = current.right;
} else {
current.right = new Node(value);
return;
}
}
}
}测试新的 add 方法:
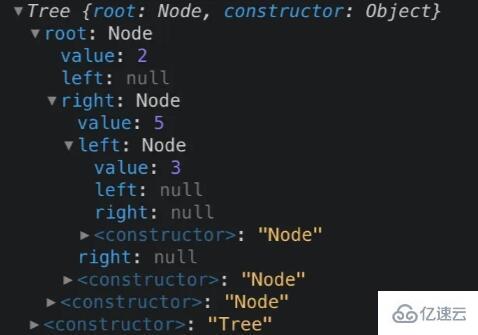
const t = new Tree();
t.add(2);
t.add(5);
t.add(3);现在树看起来是这样:
为了更好的理解,让我们实现一个检查树中是否包含值的方法。
contains(value) {
// 获取根节点
let current = this.root;
// 当存在节点时
while (current) {
// 检查当前节点是否为该值
if (value === current.value) {
return true; // 退出函数
}
// 通过将我们的值与 current.value 进行比较来决定下一个当前节点
// 如果小则往左,否则往右
current = value < current.value ? current.left : current.right;
}
return false;
}Add 和 Contains 是二进制搜索树的两个核心方法。对这两种方法的了解可以使你更好地解决日常工作中的问题。
我已经在本文中介绍了很多内容,并且掌握这些知识后在面试中将使你处于有利位置。希望你能够学到一些东西,并能够轻松地通过技术面试(尤其是讨厌的白板面试)。
关于“JavaScript如何实现常用数据结构”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



