еҰӮдҪ•дҪҝз”Ёscrapy-splash
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶеҰӮдҪ•дҪҝз”Ёscrapy-splashпјҢдәҝйҖҹдә‘е°Ҹзј–и§үеҫ—дёҚй”ҷпјҢзҺ°еңЁеҲҶдә«з»ҷеӨ§е®¶пјҢд№ҹз»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢдёҖиө·и·ҹйҡҸдәҝйҖҹдә‘е°Ҹзј–жқҘзңӢзңӢеҗ§пјҒ
1.scrapy_splashжҳҜscrapyзҡ„дёҖдёӘ组件
scrapy_splashеҠ иҪҪjsж•°жҚ®еҹәдәҺSplashжқҘе®һзҺ°зҡ„
SplashжҳҜдёҖдёӘJavascrapyжёІжҹ“жңҚеҠЎпјҢе®ғжҳҜдёҖдёӘе®һзҺ°HTTP APIзҡ„иҪ»йҮҸзә§жөҸи§ҲеҷЁпјҢSplashжҳҜз”ЁPythonе’ҢLuaиҜӯиЁҖе®һзҺ°зҡ„пјҢеҹәдәҺTwistedе’ҢQTзӯүжЁЎеқ—жһ„е»ә
дҪҝз”Ёscrapy-splashжңҖз»ҲжӢҝеҲ°зҡ„responseзӣёеҪ“дәҺжҳҜеңЁжөҸи§ҲеҷЁе…ЁйғЁжёІжҹ“е®ҢжҲҗд»ҘеҗҺзҡ„зҪ‘йЎөжәҗд»Јз Ғ
2.scrapy_splashзҡ„дҪңз”Ё
scrpay_splashиғҪеӨҹжЁЎжӢҹжөҸи§ҲеҷЁеҠ иҪҪjsпјҢ并иҝ”еӣһjsиҝҗиЎҢеҗҺзҡ„ж•°жҚ®
3.scrapy_splashзҡ„зҺҜеўғе®үиЈ…
3.1 дҪҝз”Ёsplashзҡ„dockerй•ңеғҸ
docker info жҹҘзңӢdockerдҝЎжҒҜ
docker images жҹҘзңӢжүҖжңүй•ңеғҸ
docker pull scrapinghub/splash е®үиЈ…scrapinghub/splash
docker run -p 8050:8050 scrapinghub/splash & жҢҮе®ҡ8050з«ҜеҸЈиҝҗиЎҢ
3.2.pip install scrapy-splash
3.3.scrapy й…ҚзҪ®:
SPLASH_URL = 'http://localhost:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'3.4.scrapy дҪҝз”Ё
from scrapy_splash import SplashRequest
yield SplashRequest(self.start_urls[0], callback=self.parse, args={'wait': 0.5})4.жөӢиҜ•д»Јз Ғпјҡ
import datetime
import os
import scrapy
from scrapy_splash import SplashRequest
from ..settings import LOG_DIR
class SplashSpider(scrapy.Spider):
name = 'splash'
allowed_domains = ['biqugedu.com']
start_urls = ['http://www.biqugedu.com/0_25/']
custom_settings = {
'LOG_FILE': os.path.join(LOG_DIR, '%s_%s.log' % (name, datetime.date.today().strftime('%Y-%m-%d'))),
'LOG_LEVEL': 'INFO',
'CONCURRENT_REQUESTS': 8,
'AUTOTHROTTLE_ENABLED': True,
'AUTOTHROTTLE_TARGET_CONCURRENCY': 8,
'SPLASH_URL': 'http://localhost:8050',
'DOWNLOADER_MIDDLEWARES': {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
},
'SPIDER_MIDDLEWARES': {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
},
'DUPEFILTER_CLASS': 'scrapy_splash.SplashAwareDupeFilter',
'HTTPCACHE_STORAGE': 'scrapy_splash.SplashAwareFSCacheStorage',
}
def start_requests(self):
yield SplashRequest(self.start_urls[0], callback=self.parse, args={'wait': 0.5})
def parse(self, response):
"""
:param response:
:return:
"""
response_str = response.body.decode('utf-8', 'ignore')
self.logger.info(response_str)
self.logger.info(response_str.find('http://www.biqugedu.com/files/article/image/0/25/25s.jpg'))scrapy-splashжҺҘ收еҲ°jsиҜ·жұӮпјҡ
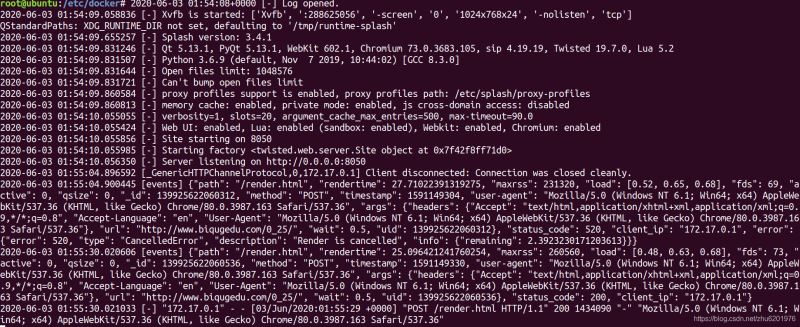
д»ҘдёҠе°ұжҳҜдәҝйҖҹдә‘е°Ҹзј–дёәеӨ§е®¶ж”¶йӣҶж•ҙзҗҶзҡ„еҰӮдҪ•дҪҝз”Ёscrapy-splashпјҢеҰӮдҪ•и§үеҫ—дәҝйҖҹдә‘зҪ‘з«ҷзҡ„еҶ…е®№иҝҳдёҚй”ҷпјҢж¬ўиҝҺе°ҶдәҝйҖҹдә‘зҪ‘з«ҷжҺЁиҚҗз»ҷиә«иҫ№еҘҪеҸӢгҖӮ





