什么是临界点?
注意,我要说的问题是非聚集索引的执行计划从Seek+Lookup变成Table/Clustered Index Scan的临界点。SQL Server的访问数据的IO最小单元是页。
我们知道聚集索引的叶级是数据页,非聚集索引的叶级是指向数据行的指针。所以通过聚集索引获取数据时,就是直接访问聚集索引本身,而通过非聚集索引获取数据时,除了访问自身,还要通过指针去访问数据页。这个过程就是RID/Key Lookup。而此Lookup是一个单页操作,即每次使用一个RID/Key,然后去访问对应的一个数据页,然后获取页上的相应的数据行。可能当前数据页的有多个数据行是符合查询要求的,但是一次lookup,只能取当前的RID/Key指定的数据行。所以同一个数据页,可能要被访问很多次。例如,现在lookup要去找RID为2,3,5,7,9对应的数据行,而这5个数据行都存在数据页N上,则数据页N只少要被访问5次。
在Seek时,如果要返回N行数据,则Seek操作至少要访问N次数据页。当Lookup访问次数据超过了全表数据页的总数时,就会出现临界点。这个时候Scan操作成本要比Lookup低。超过这个临界点时,查询优化器一般会选择Scan替代Seek+Lookup。例如表T有100000行,每页存放100行,共有1000页。查询1000条数据,理论/理想情况下:Scan最少时只需要10次IO,Lookup只少需要1000次IO。
需要注意的是覆盖索引中不存在RID/Key,而是对应的列值,所以不会出现这个问题。
临界点什么时候出现?
前面说的理论和原理上的东西,而实际临界点的出现由很多因素决定。但主要与表的总页数相关。临界点大概出现在访问页占全表页数的25%~33%时。为了直观,通常把页数再转换成行数来分析。转换时需要注意,前面阐明Lookup是单页操作,所以页数=行数。
一个表总行数为1,000,000,每页存放2条行数,共500,000页。则25%=125,000,33%=166,000。临界点会出现在125,000页和166,000页间。转换成行表示就是125000/(2*500000)=12.5%,166000/(2*500000)=16.6%。也就是说当返回行数小于62400(500000*12.55)时,很可能会使用Lookup。当返回行数大于83000时,很可能会使用Scan。这个表的行太宽了,一个页只能存放2行数据,从百分比看起来没有什么太大感觉。
一个表总行数为1,000,000,每页存放100条行数,共10,000页。则25%=2500,33%=3300。转换成行2500/1000000=0.25%,3300/1000000=0.33%。它的临界点上限不超过0.5%。也就是说你查询表中不到0.5%的行数时,会全表扫描。
一个表总行数为1,000,000,每页存放20条行数,共50,000页。则25%=125,00,33%=166,00。转换成行表示就是125000/(2*500000)=1.25%,166000/(2*500000)=1.66%。
不难发现,临界点判断,对于大表的查询性能是有很大帮助的。而对于小表而言,几乎都会是Scan,但是数据库有缓存机制,小表会完整缓存,扫描影响也不大。
我们能做些什么?
1.很容易想到,既然表有Seek对应的索引,我们使用Hint强制使用Seek,问题不就解决了。这个不一定,本来这个问题的出现就是查询优化器认为Scan比Lookup的成本要低。如果你强制可能会适得其反。SQL Server的查询优化器是很强大和智能的,除非你严格测试过,证明ForceSeek性能更好一些。
2.建立一个覆盖索引消除Lookup操作。
示例分析
使用AdventureWorks2012的Sales.SalesOrderDetail。在ProductID列有一个非聚集索引IX_SalesOrderDetail_ProductID。
通过下的查询可以知道表有121317行,共1237个数据页,每页大约存放98行数据。由此我们可以预估一下临界点在(309行,408行)附近。
select page_count,record_count from sys.dm_db_index_physical_stats(db_id(),object_id(N'Sales.SalesOrderDetail'),1,null,'detailed') where index_level=0
然后再统计一下不同的ProductID在表中行数,好针对性的测试不同ProductID:
select ProductID,COUNT(*) as cnt from Sales.SalesOrderDetail group by ProductID order by cnt
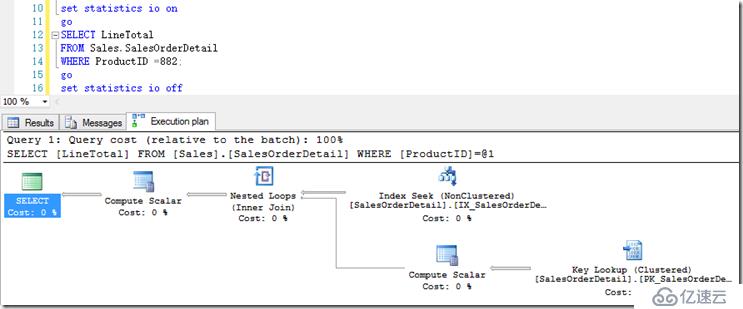
通过上面查询,我们知道ProductID=882在表中有407行,可以看到它还是使用Lookup的方式。它的IO计数为:
Table 'SalesOrderDetail'. Scan count 1, logical reads 1258
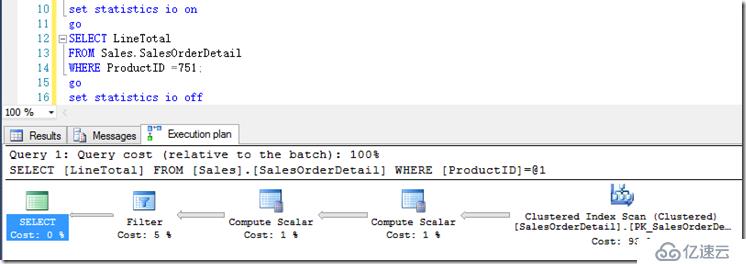
ProductID=751在表中有409行,它就使用了Scan的方式。它的IO计数为:
Table 'SalesOrderDetail'. Scan count 1, logical reads 1246
我们还可以测试其它的返回行数更多的ProductID,如果是扫描的方式则IO都是在1246,如果是Lookup则都会高于1246。证明跟理论还是契合的。
就算500行返回才会超过临界点,而500行也只占总行数的500/121317=0.41%。也就是说当返回行数超过全表的0.41%时,优化器就认为它的筛选度不够高了,不用seek+lookup,要扫描了。
总结
1. 当遇到"明明有索引,为什么会扫描?",临界点的问题可能是原因之一。
2. 因为存在临界点,所以非覆盖非聚集索引的使用率可能没有我们想象的高。
参考
http://www.sqlskills.com/blogs/kimberly/the-tipping-point-query-answers/
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





