作为一名应用开发者,数据库应用已经非常广泛了。你可能使用过关系型数据,比如MySQL、PostgreSQL,也可能使用过文档存储,比如MongoDB,或者key-value数据库,比如Redis。每一种数据库都有它的长处,也许你还正在考虑使用分布式数据库,比如Cassandra,来解决你手头上的工作。
使用这些数据产品并不是要取代原有的数据产品,而是为不同的应用场景提供更多的选择。NoSQL代表着:选择合适的方案处理合适的业务场景。
在“Cassandra基本介绍”这个课程,我们将讨论从关系型数据库转变为Cassandra的主要原因,以及Cassandra基本特点。 在本章结束后,你应该学些到:
RDBMS特点
RDBMS是否适合大数据
第三范式不可扩展
Sharding是一个恶梦
高可用..不是真实的
缺点总结
课程总结
下面我们就先介绍一下,关系型数据库:
RDBMS特点
RDBMS适合中型数据,在单台机器上工作良好,比如MySQL、PostgreSQL。
对于数百个并发用户支持较好。
ACID支持良好
RDBMS是否适合大数据
对于大数据,必然需要水平扩展,MySQL的master/slave模式,将导致ACID(A:原子性,C:一致性,I:隔离性,D:持久性)不复存在
第三范式不可扩展(没有冗余)
由于查询的复杂性,以及用户同时需要快速响应,因为用户是没有耐心的,导致数据必须反范式化设计。
Sharding是一个恶梦
数据位于每一个shard
join和聚合困难
需要反范式化
查询需要使用shard规则或路由,来命中shard
添加shard需要手动迁移数据

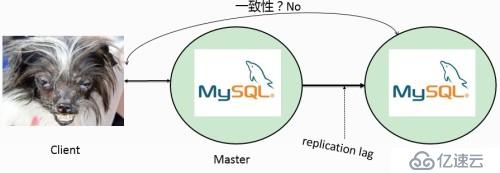
高可用..不是真实的
master为单点故障
不支持多数据中心

缺点总结
水平扩展是头疼的一件事
ACID在本地是best,多机存在一致性问题
重新sharding需要手动迁移数据
往往为了性能需要反范式化
高可用复杂,需要额外操作
课程总结
既然RDBMS有以上缺点,那我们就需要解决它们:
强一致性是不现实的:So,放弃他
重新sharding是困难的:So,我们需要自动完成
Master failover:So,我们应该不使用master/slave模式
数据分布式和聚合 no good:So,对于实时查询性能,需要进行反范式化,目的是让查询总是命中在1台机器上
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





