这篇文章主要讲解了“Facebook有哪些大数据处理架构及应用的软件”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Facebook有哪些大数据处理架构及应用的软件”吧!
Facebook大数据技术架构的演进路线
Facebook一直是大数据技术最积极的应用者,因为它拥有的数据量极其巨大,一份资料显示2011年它拥有的压缩数据已经有25PB,未压缩数据150PB,每天产生的未压缩的新数据有400TB。在Facebook,大数据技术被广泛应用在广告、新闻源、消息/聊天、搜索、站点安全、特定分析、报告等各个领域。Facebook也是Apache大数据开源项目的最大贡献者之一。Facebook是2007年前后正式转向Hadoop计算框架,随之它向Apache基金会贡献了大名鼎鼎的Hive、ZooKeeper、Scribe、Cassandra等开源工具,当前Facebook的开源进程仍在积极推进着。Facebook大数据技术架构经历了三个演变阶段。
Facebook早期的大数据技术架构是建立在Hadoop、HBase、Hive、Scribe等开源工具基础上的。日志数据流从HTTP服务器产生,通过日志收集系统Scribe耗费秒级时间传送到共享存储NFS文件系统,然后通过小时级的Copier/Loader(即MapReduce作业)将数据文件上传到Hadoop。数据摘要通过每天例行的流水作业产生,它是基于Hive的类SQL语言开发,结果会定期会更新到前端的Mysql服务器,以便通过OLTP工具产生报表。Hadoop集群节点有3000个,扩展性和容错性方面的问题能够很好地解决,但是早期系统的主要问题是整体的处理延迟较大,从日志产生起1~2天后才能得到最终的报表。
Facebook当前的大数据技术架构是在早期架构基础上对数据传输通道和数据处理系统进行了优化,如图所示,主要分为分布式日志系统Scribe、分布式存储系统HDFS和HBase、分布式计算和分析系统(MapReduce、Puma和Hive)等。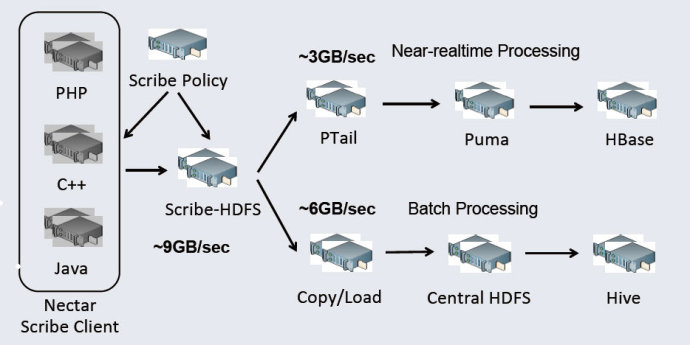
其中,Scribe日志系统用于聚合来自大量HTTP服务器的日志数据。Thrift是Facebook提供的软件框架,用于跨语言的服务开发,能够在C 、Java、PHP 、Python和Ruby等语言之间实现无缝的支持。采用Thrift RPC来调用Scribe日志收集服务进行日志数据汇总。Scribe Policy是日志流量和模型管理节点,将元数据传送给Scribe客户端和Scribe HDFS,采集的日志数据存储在Scribe HDFS。Facebook对早期系统优化后的数据通道称为Data Freeway,能够处理峰值9GB/s的数据并且端到端的延迟在10s以内,支持超过2500种的日志种类。Data Freeway主要包括4个组件,Scribe、Calligraphus、Continuous Copier和PTail。Scribe用于客户端,负责通过Thrift RPC发送数据;Calligraphus在中间层梳理数据并写到HDFS,它提供了日志种类的管理,利用Zookeeper进行辅助;Continuous Copier将文件从一个HDFS拷贝到另一个HDFS;PTail并行地tail多个HDFS上的目录,并写文件数据到标准输出。在当前架构中,一部分数据处理仍然以批处理的方式通过MapReduce进行小时级的处理,存储在中央的HDFS,每天通过Hive进行分析处理。另一部分接近实时的数据流则通过Puma来进行分钟级的处理。Facebook对专门分析提供Peregrine(Hipal)工具、对周期性分析提供Nocron工具进行分析。
Facebook未来的大数据技术架构的雏形已经出来。首先开源的是可能替代Hadoop系统中MapReduce的Corona,类似于Yahoo提出的YARN。Corona最大的一个进步是其集群管理器做到了基于CPU、内存和其他作业处理的需求资源的管理,这可以使得Corona既可以处理MapReduce 作业,也可以处理非MapReduce 作业,使Hadoop集群的应用领域更加广泛。二是Facebook最新的交互式大数据查询系统Presto,类似于Cloudera的Impala和Hortonworks的Stinger,解决了Facebook迅速膨胀的海量数据仓库快速查询需求。据Facebook称,使用Presto进行简单的查询只需要几百毫秒,即使是非常复杂的查询,也只需数分钟便可完成,它在内存中运行,并且不会向磁盘写入。第三是Wormhole流计算系统,类似于Twiitter的Storm和Yahoo的Storm-YARN。第四个重要项目是Prism,它能够运行一个超大的、能够将全球数据中心都连起来的Hadoop集群,可能在一个数据中心宕掉的时候即时的将数据重新分布,这是一个与Google的Spanner类似的项目。
Facebook的大数据技术架构演进路径代表了大数据技术的发展路线,难能可贵的是,开源是Facebook一贯的路线,它和Yahoo等公司一起为大数据技术的发展作出了巨大贡献。
Facebook所用的软件
从某些方面来说,Facebook还是属于LAMP类型网站,但是,为了配合其他大量的组件和服务,Facebook对已有的方法,已经做了必要的改变、拓展和修改。
比如:
Facebook依然使用PHP,但Facebook已重建新的编译器,以满足在其Web服务器上加载本地代码,从而提升性能;
Facebook使用Linux系统,但为了自身目的,也已做了必要的优化。(尤其是在网络吞吐量方面);
Facebook使用MySQL,但也对其做优化。
还有定制的系统,比如, Haystack — 高度可扩展的对象存储,用来处理Facebook的庞大的图片;Scribe — Facebook的日志系统。
下面展现给大家的是,全球最大的社交网站Facebook所使用到的软件。
Memcached
Memcached是一款相当有名的软件。它是分布式内存缓存系统。Facebook(还有大量的网站)用它作为Web服务器和MySQL服务器之间的缓存层。经过多年,Facebook已在Memcached和其相关软件(比如,网络栈)上做了大量优化工作。
Facebook运行着成千上万的Memcached服务器,借以及时处理TB级的缓存数据。可以这样说,Facebook拥有全球最大的Memcached设备。
HipHop for PHP
和运行在本地服务器上代码相比,PHP的运行速度相对较慢。HipHop把PHP代码转换成C++代码,提高编译时的性能。因为Facebook很依赖PHP来处理信息,有了HipHop,Facebook在Web服务器方面更是如虎添翼。
HipHop诞生过程:在Facebook,一小组工程师(最初是3位)用了18个月研发而成。
Haystack
Haystack是Facebook高性能的图片存储/检索系统。(严格来说,Haystack是一对象存储,所以它不一定要存储图片。)Haystack的工作量超大。Facebook上有超过2百亿张图片,每张图片以四种不同分辨率保存,所以,Facebook有超过8百亿张图片。
Haystack的作用不单是处理大量的图片,它的性能才是亮点。我们在前面已提到,Facebook每秒大概处理120万张图片,这个数据并不包括其CDN处理的图片数。这可是个惊人的数据!!!
BigPipe
BigPipe是Facebook开发的动态网页处理系统。为了达到最优,Facebook用它来处理每个网页的分块(也称“Pagelets”)。
比如,聊天窗口是独立检索的,新闻源也是独立检索的。这些Pagelets是可以并发检索,性能也随之提高。如此,即使网站的某部分停用或崩溃后,用户依然可以使用。
Cassandra
Cassandra是一个没有单点故障的分布式存储系统。它是前NoSQL运动的成员之一,现已开源(已加入Apache工程)。Facebook用它来做邮箱搜索。
除了Facebook之外,Cassandra也适用于很多其他服务,比如Digg。
Scribe
Scribe是个灵活多变的日志系统,Facebook把它用于多种内部用途。Scribe用途:处理Facebook级别日志,一旦有新的日志分类生成,Scribe将自动处理。(Facebook有上百个日志分类)。
Hadoop and Hive
Hadoop是款开源Map/Reduce框架,它可以轻松处理海量数据。Facebook用它来做数据分析。(前面就说到了,Facebook的数据量是超海量的。)Hive起源于Facebook,Hive可以使用SQL查询,让非程序员比较容易使用Hadoop。(注1: Hive是是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 )

Varnish
Varnish是一个HTTP加速器,担当负载均衡角色,同时也用于快速处理缓存内容。
Facebook用Varnish处理图片和用户照片,每天都要处理十亿级的请求。和Facebook其他的应用应用一样,Varnish也是开源的。
Facebook可以平稳运行,还得利于其他方面
虽然上面已经提到了一些构成Facebook系统的软件,但是处理如此庞大的系统,本身就是一项复杂的任务。所以,下面还将列出使Facebook能平稳运行的一些东西。
虽然这里无法过多深入硬件方面,但硬件绝对是Facebook能达到空前规模的重要因素。比如,和其他大型网站一样,Facebook也用CDN来处理静态内容。Facebook还在美国西部的俄勒冈州建有一超大的数据中心,可以随时增加服务器。
感谢各位的阅读,以上就是“Facebook有哪些大数据处理架构及应用的软件”的内容了,经过本文的学习后,相信大家对Facebook有哪些大数据处理架构及应用的软件这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.jb51.net/yunying/423057.html



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



