这篇文章主要介绍了如何使用python爬虫+正向代理实现链家数据收集,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
链[lian]家[jia]:https://bj.lianjia.com/
点击【租房】,进入租房首页: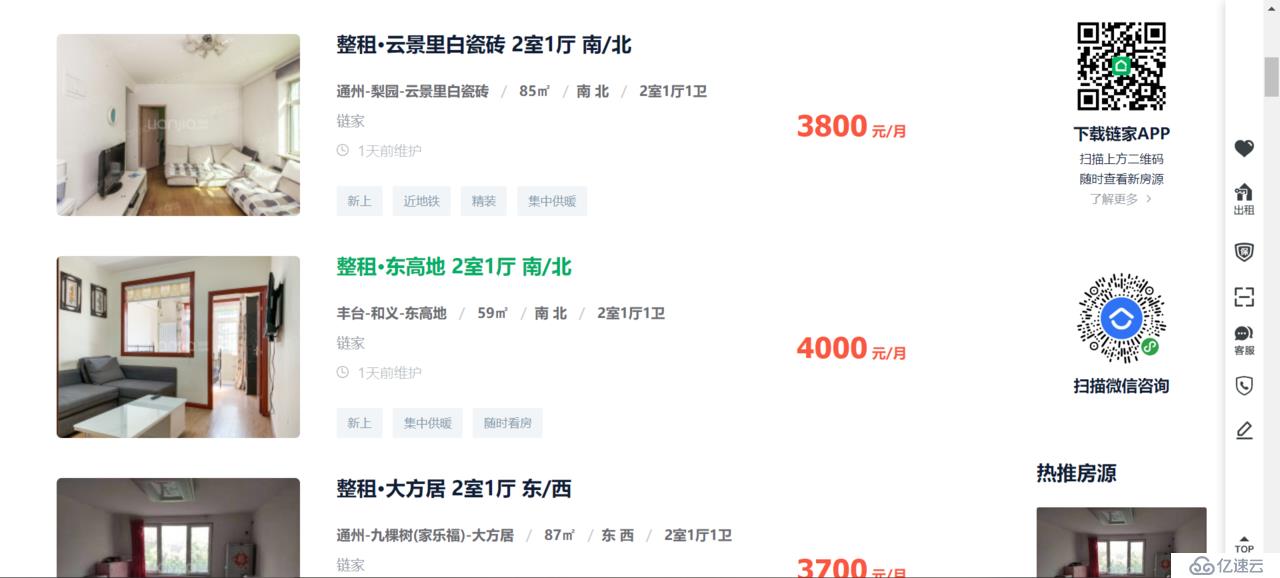
这就是要爬取的首页了;
1、分析页面
右击一个房源的链接,点击[检查],如图: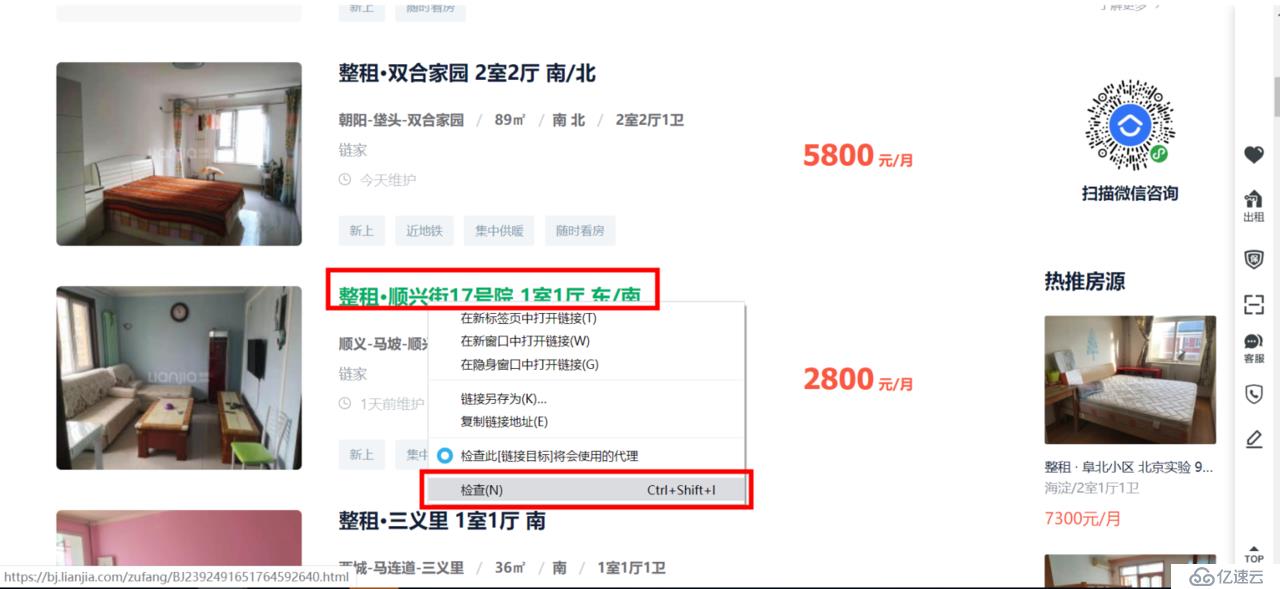
进入开发者模式,
此时可以看到 a 标签中的链接: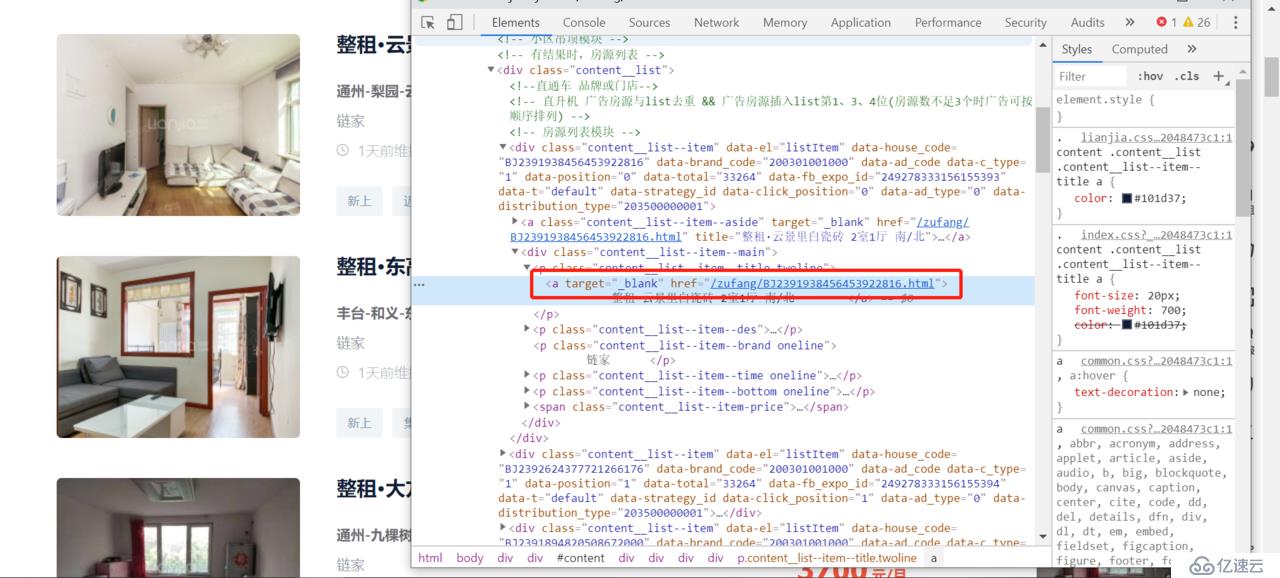
使用 xpath 就可以把链接提取出来,不过该链接是真实 url 的后半段,需要进行字符串拼接才能获取到真正的 url;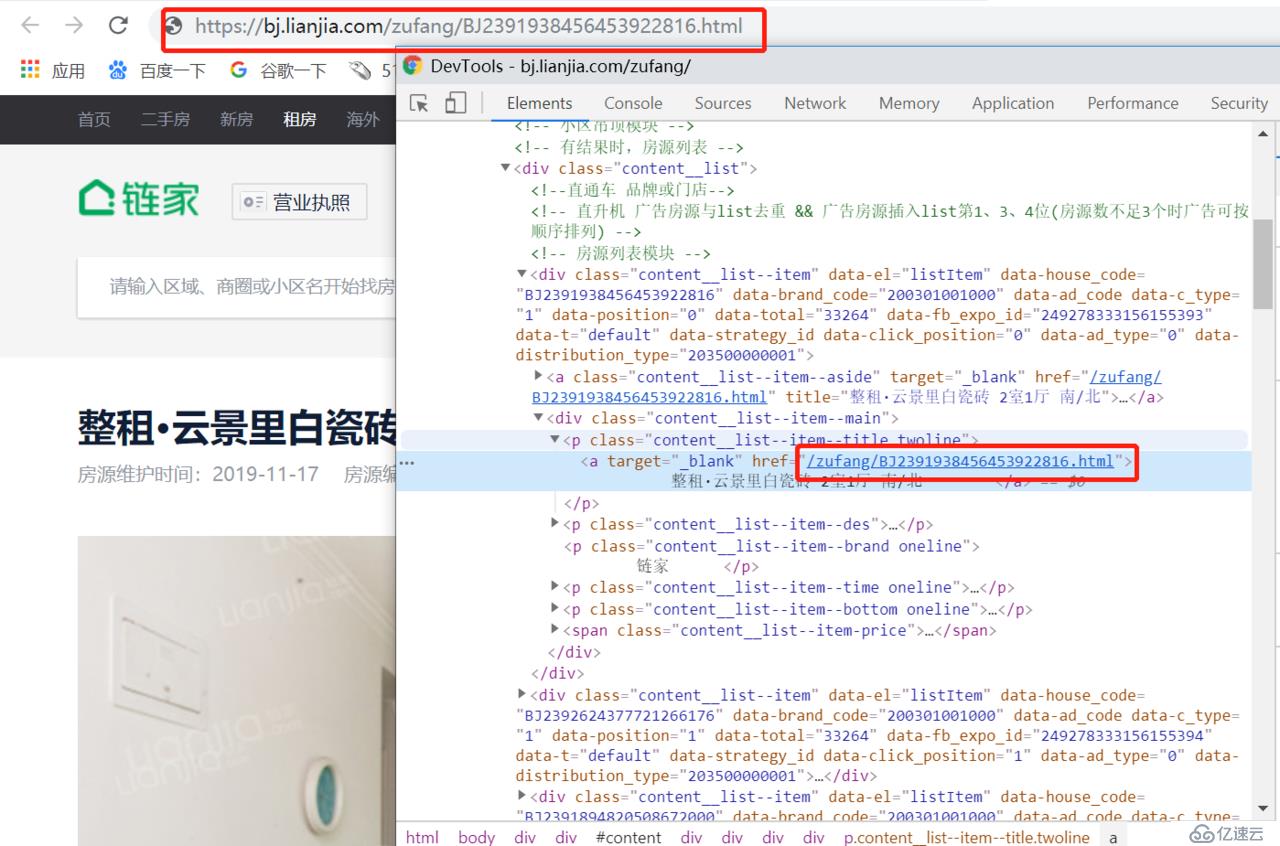
后面会在代码中体现;
爬取的信息暂且只对下图中标出的进行爬取: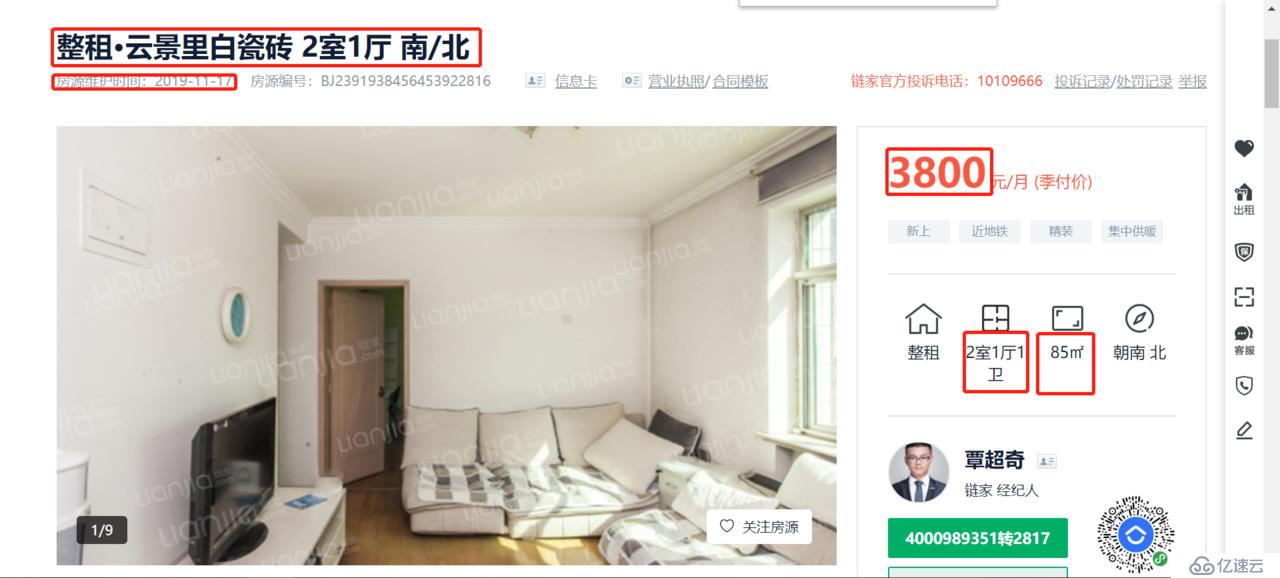
包括 标题、时间、价格、房间格局、面积 ;
1、分析页面 url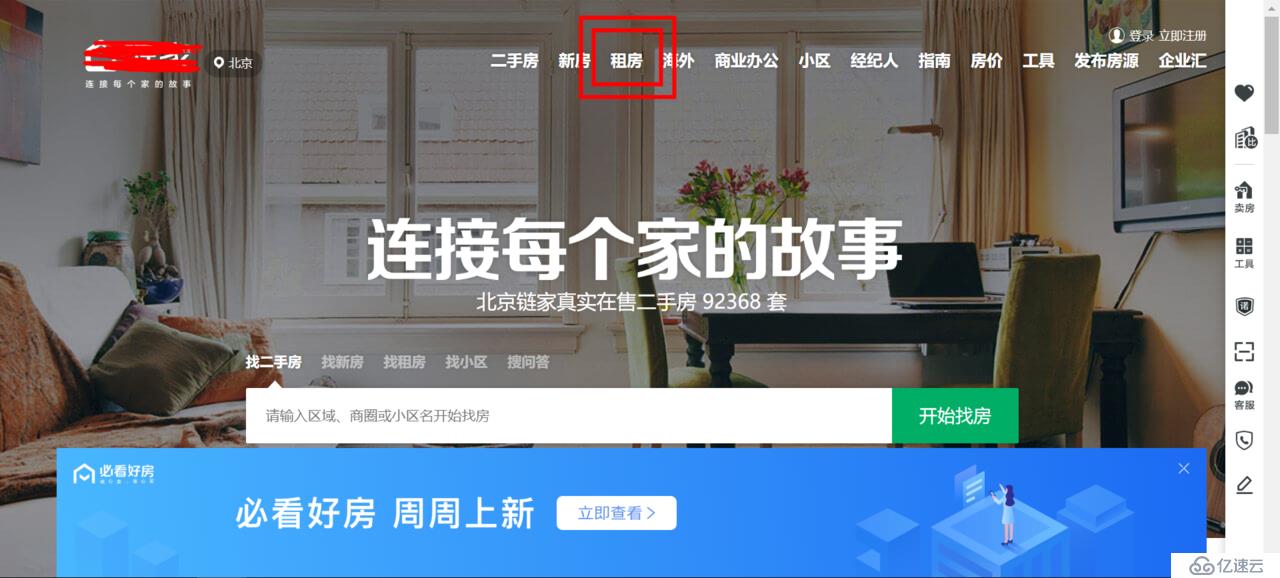
点击租房,找到其跳转到的网页:https://bj.lianjia.com/zufang/
对,这就是要爬取的首页:
我们往下拉到最底端,点击下一页或者其他页,
第 1 页:https://bj.lianjia.com/zufang/pg1/#contentList
第 2 也:https://bj.lianjia.com/zufang/pg2/#contentList
第 3 页:https://bj.lianjia.com/zufang/pg3/#contentList
.
.
.
第 100 页:https://bj.lianjia.com/zufang/pg100/#contentList
通过观察 url 可以发现规律:每一页只有 pg 后面的数字在变,且与页数相同;
拼接字符串后使用一个循环即可对所有页面进行爬取;
开发工具:pycharm
python版本:3.7.2
import requests
from lxml import etree
#编写了一个常用的方法,输入url即可返回text的文本;
def get_one_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
response = requests.get(url,headers=headers)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
else:
print("请求状态码 != 200,url错误.")
return None
for number in range(0,101): #利用range函数循环0-100,抓去第1页到100页。
initialize_url = "https://bj.lianjia.com/zufang/pg" + str(number) + "/#contentList" #字符串拼接出第1页到100页的url;
html_result = get_one_page(initialize_url) #获取URL的text文本
html_xpath = etree.HTML(html_result) #转换成xpath格式
#抓去首页中的url(每页有30条房源信息)
page_url = html_xpath.xpath("//div[@class='content w1150']/div[@class='content__article']//div[@class='content__list']/div/a[@class='content__list--item--aside']/@href")
for i in page_url: #循环每一条房源url
true_url = "https://bj.lianjia.com" + i #获取房源的详情页面url
true_html = get_one_page(true_url) #获取text文本
true_xpath = etree.HTML(true_html) #转换成xpath格式
#抓取页面题目,即:房源详情页的标题
title = true_xpath.xpath("//div[@class='content clear w1150']/p[@class='content__title']//text()")
#抓取发布时间并对字符串进行分割处理
release_date = true_xpath.xpath("//div[@class='content clear w1150']//div[@class='content__subtitle']//text()")
release_date_result = str(release_date[2]).strip().split(":")[1]
#抓取价格
price = true_xpath.xpath("//div[@class='content clear w1150']//p[@class='content__aside--title']/span//text()")
#抓取房间样式
house_type = true_xpath.xpath("//div[@class='content clear w1150']//ul[@class='content__aside__list']//span[2]//text()")
#抓取房间面积
acreage = true_xpath.xpath("//div[@class='content clear w1150']//ul[@class='content__aside__list']//span[3]//text()")
print(str(title) + " --- " + str(release_date_result) + " --- " + str(price) + " --- " + str(house_type) + " --- " + str(acreage))
#写入操作,将信息写入一个text文本中
with open(r"E:\admin.txt",'a') as f:
f.write(str(title) + " --- " + str(release_date_result) + " --- " + str(price) + " --- " + str(house_type) + " --- " + str(acreage) + "\n")最后将爬取的信息一边输出一边写入文本;当然也可以直接写入 JSON 文件或者直接存入数据库;
感谢你能够认真阅读完这篇文章,希望小编分享的“如何使用python爬虫+正向代理实现链家数据收集”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





