参考博文https://www.cnblogs.com/shaosks/p/7278634.html
使用selenium的webdriver配合chrome实现了js页面的解析
配置了chrome×××面启动一直未生效
运行脚本发现启动chrome和登录过程都非常慢不明白原因
import datetime
import selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from time import sleep
from pyquery import PyQuery as pq
host=["https://192.40.0.6/iPages/i_login.asp","https://192.40.0.7/iPages/i_login.asp","https://192.40.0.8/iPages/i_login.asp","https://192.40.0.9/iPages/i_login.asp","https://192.40.0.10/iPages/i_login.asp",
"https://192.40.1.6/iPages/i_login.asp","https://192.40.1.7/iPages/i_login.asp","https://192.40.1.8/iPages/i_login.asp","https://192.40.1.9/iPages/i_login.asp","https://192.40.1.10/iPages/i_login.asp"]
for url in host:
opt = webdriver.ChromeOptions()
opt.set_headless()
browser = webdriver.Chrome(options=opt)
browser.get(url)
browser.find_element_by_id("username").send_keys("admin")
browser.find_element_by_id("password").send_keys("Passw0rd")
browser.find_element_by_id("loginButton").click()
sleep(1)
browser.switch_to.frame('mainFrame') #处理页面框架的切换
#sleep(1)
browser.switch_to.frame('treeFrame')
selenium_html = browser.execute_script("return document.documentElement.outerHTML") #返回页面的html元素
doc = pq(selenium_html)
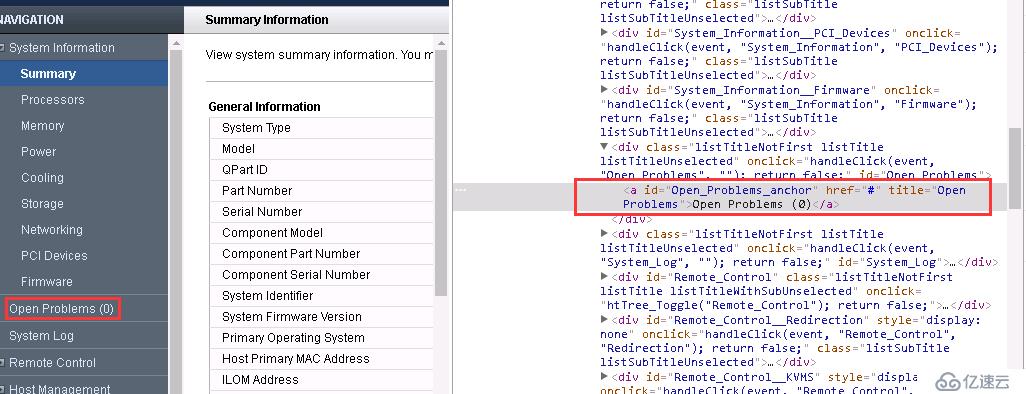
dochtml = doc('a[id="Open_Problems_anchor"]')
strSources = dochtml.text().encode('utf8').strip()
txtsource = strSources[strSources.find('Open Problems') + 0:] #提取指定元素的html
print (datetime.datetime.now().strftime('%m-%d %H;%M:%S'),url,txtsource)
browser.close()
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





