python еәҸеҲ—еҢ–е’ҢеҸҚеәҸеҲ—еҢ–
дёҖ жҰӮиҝ°
1 дёәд»Җд№ҲиҰҒеәҸеҲ—еҢ–
еӣ дёәTCP/IPеҚҸи®®еҸӘж”ҜжҢҒеӯ—иҠӮж•°з»„зҡ„дј иҫ“пјҢдёҚиғҪзӣҙжҺҘдј еҜ№иұЎгҖӮеҜ№иұЎеәҸеҲ—еҢ–зҡ„з»“жһңдёҖе®ҡжҳҜеӯ—иҠӮж•°з»„пјҒеҪ“дёӨдёӘиҝӣзЁӢеңЁиҝӣиЎҢиҝңзЁӢйҖҡдҝЎж—¶пјҢеҪјжӯӨеҸҜд»ҘеҸ‘йҖҒеҗ„з§Қзұ»еһӢзҡ„ж•°жҚ®гҖӮж— и®әжҳҜдҪ•з§Қзұ»еһӢзҡ„ж•°жҚ®пјҢйғҪдјҡд»ҘдәҢиҝӣеҲ¶еәҸеҲ—зҡ„еҪўејҸеңЁзҪ‘з»ңдёҠдј йҖҒгҖӮеҸ‘йҖҒж–№йңҖиҰҒжҠҠиҝҷдёӘеҜ№иұЎиҪ¬жҚўдёәеӯ—иҠӮеәҸеҲ—пјҢжүҚиғҪеңЁзҪ‘з»ңдёҠдј йҖҒпјӣжҺҘ收方еҲҷйңҖиҰҒжҠҠеӯ—иҠӮеәҸеҲ—еҶҚжҒўеӨҚдёәеҜ№иұЎгҖӮ
2 еәҸеҲ—еҢ–е’ҢеҸҚеәҸеҲ—еҢ–
еәҸеҲ—еҢ–(serialization)пјҡеҸҠжңүеәҸзҡ„еҲ—пјҢж•°жҚ®иҪ¬жҚўжҲҗдәҢиҝӣеҲ¶зҡ„жңүеәҸзҡ„иҝҮзЁӢ
еҚҸи®®пјҡ规е®ҡеәҸеҲ—еҢ–е’ҢеҸҚеәҸеҲ—еҢ–зҡ„иҪ¬жҚўж–№ејҸеҸҠе°ұжҳҜжҠҠж•°жҚ®дҝқеӯҳжҲҗдәҢиҝӣеҲ¶еӯҳеӮЁиө·жқҘпјҢе…¶жҳҜе®ҡд№үзҡ„规еҲҷпјҢ其规еҲҷз§°дёәеҚҸи®®еҰӮжһң规е®ҡдәҶеҚҸи®®пјҢеҲҷеҸҜд»ҘиҝӣиЎҢеәҸеҲ—еҢ–е’ҢеҸҚеәҸеҲ—еҢ–пјҢе…¶еҚҸи®®жҳҜз”ұзүҲжң¬зҡ„пјҢзәҰе®ҡеҚҸи®®еҗҺиҝӣиЎҢеӨ„зҗҶ
еҸҚеәҸеҲ—еҢ–(deserialization)пјҡе°ҶжңүеәҸзҡ„дәҢиҝӣеҲ¶еәҸеҲ—иҪ¬жҚўжҲҗжҹҗз§ҚеҜ№иұЎпјҲеӯ—е…ёпјҢеҲ—иЎЁзӯүпјүз§°дёәеҸҚеәҸеҲ—еҢ–
жҢҒд№…еҢ–пјҡеәҸеҲ—еҢ–дҝқеӯҳеҲ°ж–Ү件е°ұжҳҜжҢҒд№…еҢ–пјҢеәҸеҲ—еҢ–жңӘеҝ…дјҡжҢҒд№…еҢ–пјҢеәҸеҲ—еҢ–еҫҖеҫҖжҳҜдј иҫ“жҲ–еӯҳеӮЁгҖӮеҸҜд»Ҙе°Ҷж•°жҚ®еәҸеҲ—еҢ–еҗҺжҢҒд№…еҢ–пјҢжҲ–иҖ…зҪ‘з»ңдј иҫ“пјҢд№ҹеҸҜд»Ҙе°Ҷд»Һж–Ү件жҲ–зҪ‘з»ңжҺҘеҸ—еҲ°зҡ„еӯ—иҠӮеәҸеҲ—еҸҚеәҸеҲ—еҢ–гҖӮ
дәҢ python pickle
1 жҰӮиҝ°
pickle pythonдёӯзҡ„еәҸеҲ—еҢ–пјҢеҸҚеәҸеҲ—еҢ–жЁЎеқ—пјҢе…¶еұҖйҷҗжҳҜд»…йҷҗдәҺдј иҫ“зҡ„дёӨз«ҜйғҪжҳҜpythonзҡ„жғ…еҶөпјҢдё”е°ҪйҮҸдҝқжҢҒдёӨз«Ҝзҡ„зүҲжң¬дёҖиҮҙ
2 pickle еә“еҹәжң¬ж–№жі•
dumps еҜ№иұЎеәҸеҲ—еҢ–пјҢеңЁеҶ…еӯҳдёӯ
dump еҜ№иұЎеәҸеҲ—еҢ–еҲ°ж–Ү件еҜ№иұЎпјҢе°ұжҳҜеӯҳе…Ҙж–Ү件
loads еҜ№иұЎеҸҚеәҸеҲ—еҢ–
load еҜ№иұЎеҸҚеәҸеҲ—еҢ–пјҢд»Һж–Ү件дёӯиҜ»еҸ–ж•°жҚ®
3 е®һдҫӢ
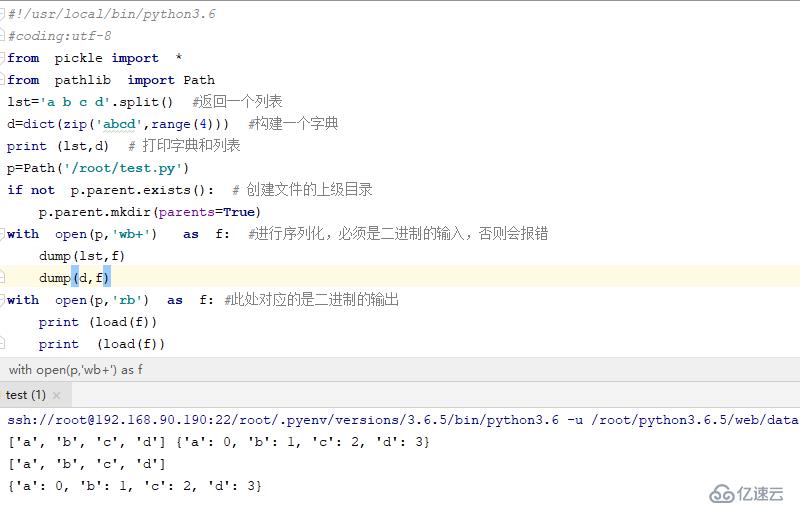
#!/usr/local/bin/python3.6
#coding:utf-8
from pickle import *
from pathlib import Path
lst='a b c d'.split() #иҝ”еӣһдёҖдёӘеҲ—иЎЁ
d=dict(zip('abcd',range(4))) #жһ„е»әдёҖдёӘеӯ—е…ё
print (lst,d) # жү“еҚ°еӯ—е…ёе’ҢеҲ—иЎЁ
p=Path('/root/test.py')
if not p.parent.exists(): # еҲӣе»әж–Ү件зҡ„дёҠзә§зӣ®еҪ•
p.parent.mkdir(parents=True)
with open(p,'wb+') as f: #иҝӣиЎҢеәҸеҲ—еҢ–пјҢеҝ…йЎ»жҳҜдәҢиҝӣеҲ¶зҡ„иҫ“е…ҘпјҢеҗҰеҲҷдјҡжҠҘй”ҷ
dump(lst,f)
dump(d,f)
with open(p,'rb') as f: #жӯӨеӨ„еҜ№еә”зҡ„жҳҜдәҢиҝӣеҲ¶зҡ„иҫ“еҮә
print (load(f))
print (load(f))
з»“жһңеҰӮдёӢ
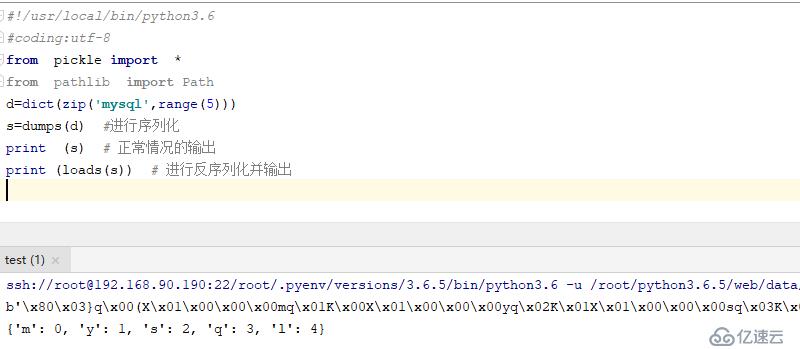
#!/usr/local/bin/python3.6
#coding:utf-8
from pickle import *
from pathlib import Path
d=dict(zip('mysql',range(5)))
s=dumps(d) #иҝӣиЎҢеәҸеҲ—еҢ–
print (s) # жӯЈеёёжғ…еҶөзҡ„иҫ“еҮә
print (loads(s)) # иҝӣиЎҢеҸҚеәҸеҲ—еҢ–并иҫ“еҮә
з»“жһңеҰӮдёӢ
еҲҮжҚў3.5зҺҜеўғиҝӣиЎҢжҹҘзңӢеӨ„зҗҶ
еҜ№зұ»зҡ„еӨ„зҗҶ
#!/usr/local/bin/python3.6
#coding:utf-8
from pickle import *
from pathlib import Path
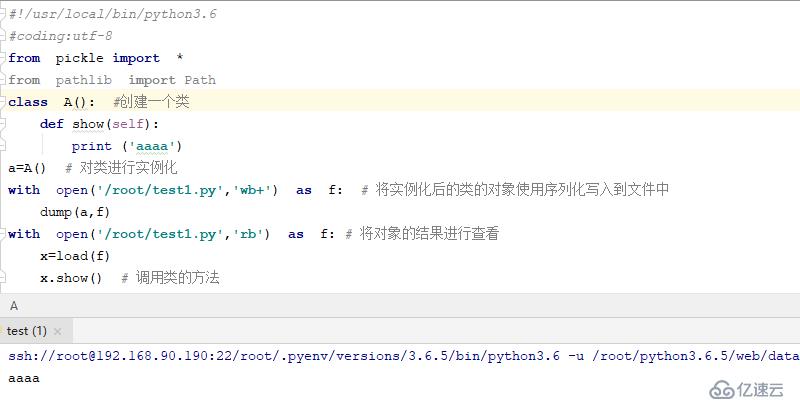
class A(): #еҲӣе»әдёҖдёӘзұ»
def show(self):
print ('aaaa')
a=A() # еҜ№зұ»иҝӣиЎҢе®һдҫӢеҢ–
with open('/root/test1.py','wb+') as f: # е°Ҷе®һдҫӢеҢ–еҗҺзҡ„зұ»зҡ„еҜ№иұЎдҪҝз”ЁеәҸеҲ—еҢ–еҶҷе…ҘеҲ°ж–Ү件дёӯ
dump(a,f)
with open('/root/test1.py','rb') as f: # е°ҶеҜ№иұЎзҡ„з»“жһңиҝӣиЎҢжҹҘзңӢ
x=load(f)
x.show()
з»“жһңеҰӮдёӢ

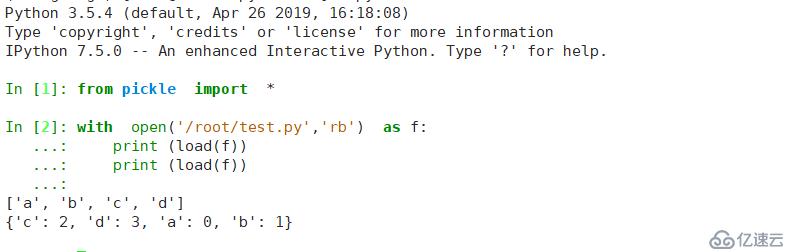
#!/usr/local/bin/python3.6
#coding:utf-8
from pickle import *
from pathlib import Path
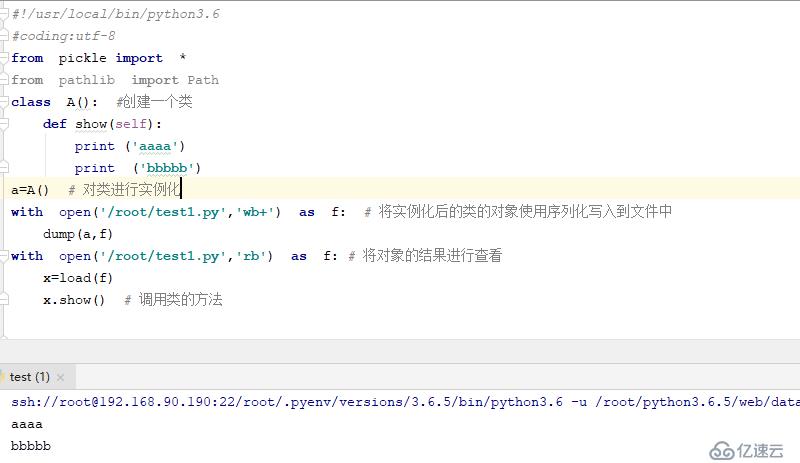
class A(): #еҲӣе»әдёҖдёӘзұ»
def show(self):
print ('aaaa')
print ('bbbbb')
a=A() # еҜ№зұ»иҝӣиЎҢе®һдҫӢеҢ–
with open('/root/test1.py','wb+') as f: # е°Ҷе®һдҫӢеҢ–еҗҺзҡ„зұ»зҡ„еҜ№иұЎдҪҝз”ЁеәҸеҲ—еҢ–еҶҷе…ҘеҲ°ж–Ү件дёӯ
dump(a,f)
with open('/root/test1.py','rb') as f: # е°ҶеҜ№иұЎзҡ„з»“жһңиҝӣиЎҢжҹҘзңӢ
x=load(f)
x.show() # и°ғз”Ёзұ»зҡ„ж–№жі•
жҹҘзңӢз»“жһң
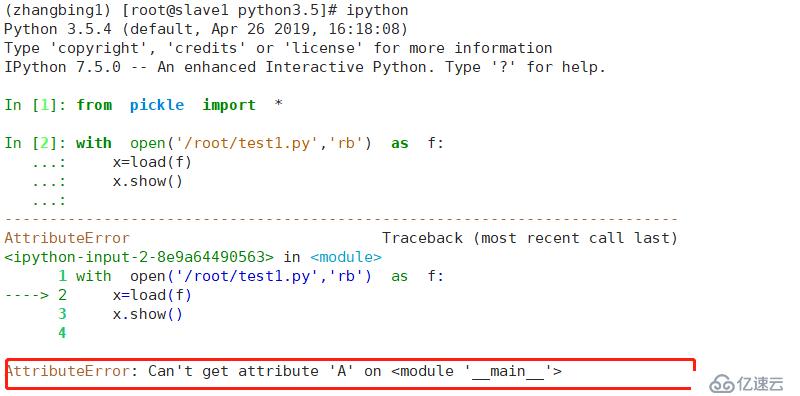
еҶҷе…Ҙзҡ„ж•°жҚ®еҰӮдёӢ

жӯӨеӨ„еҶҷе…Ҙзҡ„ж•°жҚ®жңӘеҸ‘з”ҹж”№еҸҳпјҢдҪҶе…¶еңЁзұ»дёӯеўһеҠ дәҶж•°жҚ®пјҢжӯӨеӨ„и®°еҪ•зҡ„жҳҜжЁЎеқ—еҗҚе’Ңзұ»еҗҚгҖӮиӢҘеңЁдёҚеҗҢзҡ„е№іеҸ°иҝӣиЎҢж“ҚдҪңпјҢеҲҷдјҡжҠҘй”ҷ
еҲҮжҚў3.5зҺҜеўғпјҢжҠҘй”ҷпјҢеӣ дёәе…¶дёӯжІЎжңүиҝҷдёӘtestзҡ„жЁЎеқ—еҗҚжІЎжңүеҜ№еә”зҡ„classAпјҢеӣ жӯӨдјҡжҠҘй”ҷгҖӮ
еҜ№иұЎеәҸеҲ—еҢ–
#!/usr/local/bin/python3.6
#coding:utf-8
from pickle import *
from pathlib import Path
class A(): #еҲӣе»әдёҖдёӘзұ»
def __init__(self): #еҜ№зұ»иҝӣиЎҢеҲқе§ӢеҢ–зҡ„ж“ҚдҪңпјҢеҸҠе°ұжҳҜеңЁеҜ№иұЎиөӢеҖјж—¶пјҢжӯӨзұ»дјҡиў«еёҰе…Ҙе…¶дёӯ
self.tttt='abcdf'
a=A() # еҜ№зұ»иҝӣиЎҢе®һдҫӢеҢ–
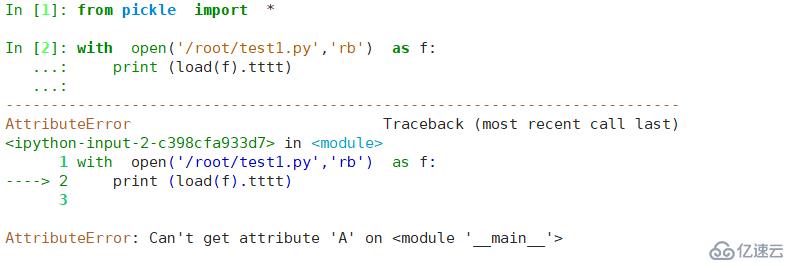
with open('/root/test1.py','wb+') as f: # е°Ҷе®һдҫӢеҢ–еҗҺзҡ„зұ»зҡ„еҜ№иұЎдҪҝз”ЁеәҸеҲ—еҢ–еҶҷе…ҘеҲ°ж–Ү件дёӯ
dump(a,f)
with open('/root/test1.py','rb') as f: # е°ҶеҜ№иұЎзҡ„з»“жһңиҝӣиЎҢжҹҘзңӢ
x=load(f)
print (x.tttt) # и°ғз”Ёзұ»зҡ„ж–№жі•
жҹҘзңӢеҰӮдёӢ
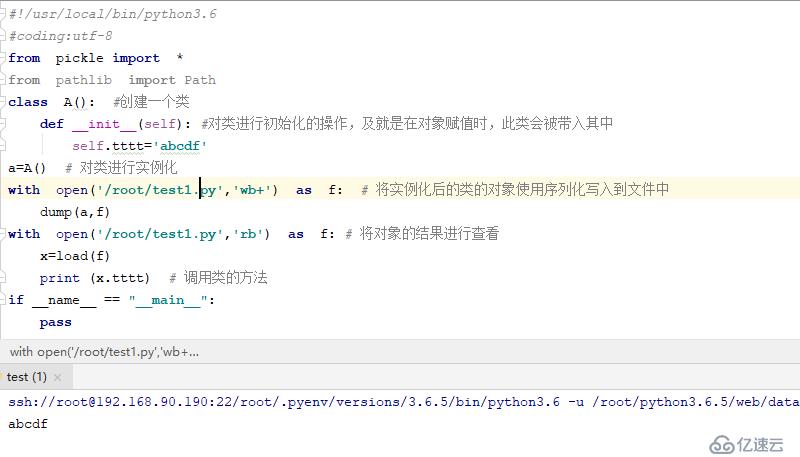
жҹҘзңӢеҶҷе…Ҙж•°жҚ®пјҢе…¶еҸ‘з”ҹдәҶеҸҳеҢ–
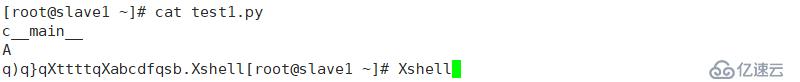
дҪҶе…¶еҲҮжҚўзҺҜеўғпјҢиҝҳжҳҜдёҚиғҪжүҫеҲ°
4 жҖ»з»“
RPC йӣҸеҪўпјҡ
иҝңзЁӢиҝҮзЁӢи°ғз”Ёпјҡ еҸҠиҝңзЁӢи°ғз”ЁжҹҗдёӘжЁЎеқ—зҡ„еҮҪж•°жқҘе®һзҺ°е…¶иҝҮзЁӢзҡ„и°ғз”Ё пјҢеҝ…йЎ»иҰҒдҝқиҜҒиҝңзЁӢзҡ„еҮҪж•°е’Ңжң¬ең°йңҖиҰҒзҡ„еҮҪж•°дёҖиҮҙ并且еҝ…йЎ»еӯҳеңЁпјҢеҗҰеҲҷдјҡжҠҘй”ҷ
йҖҡиҝҮзҪ‘з»ңдј иҫ“пјҢдёҚйңҖиҰҒжҢҒд№…еҢ–пјҢиҝӣиЎҢзұ»зҡ„дёҖиҮҙжҖ§
еҜ№дәҺйқһиҮӘе®ҡд№үзұ»пјҢдёӨиҫ№дёҖиҮҙпјҢдёҚйңҖиҰҒпјҢиӢҘжҳҜиҮӘе®ҡд№үзұ»пјҢеҲҷйңҖиҰҒдёӨз«ҜдҝқжҢҒдёҖиҮҙ
еә”з”Ёпјҡ
жң¬ең°еәҸеҲ—еҢ–зҡ„жғ…еҶөпјҢеә”з”Ёиҫғе°‘
дёҖиҲ¬жқҘиҜҙпјҢеӨ§еӨҡж•°еә”з”ЁеңәжҷҜеңЁзҪ‘з»ңдёӯпјҢе°Ҷж•°жҚ®еәҸеҲ—еҢ–еҗҺйҖҡиҝҮзҪ‘з»ңдј иҫ“еҲ°иҝңзЁӢз»“зӮ№пјҢиҝңзЁӢжңҚеҠЎеҷЁдёҠзҡ„жңҚеҠЎжҺҘеҸ—еҲ°ж•°жҚ®еҗҺиҝӣиЎҢеҸҚеәҸеҲ—еҢ–пјҢе°ұеҸҜд»ҘдҪҝз”ЁдәҶгҖӮ
дҪҶжҳҜпјҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢиҝңз«ҜжҺҘеҸ—з«ҜпјҢеҸҚеәҸеҲ—еҢ–ж—¶еҝ…йЎ»жңүеҜ№еә”зҡ„ж•°жҚ®зұ»еһӢпјҢеҗҰеҲҷе°ұдјҡжҠҘй”ҷпјҢе°Өе…¶жҳҜиҮӘе®ҡд№үзұ»пјҢеҝ…йЎ»иҝңзЁӢеӯҳеңЁ
зӣ®еүҚпјҢеӨ§еӨҡж•°йЎ№зӣ®йғҪдёҚжҳҜеҚ•жңәпјҢдёҚжҳҜеҚ•жңҚеҠЎпјҢйңҖиҰҒйҖҡиҝҮзҪ‘з»ңе°Ҷж•°жҚ®дј йҖҒеҲ°е…¶д»–з»“зӮ№дёҠпјҢиҝҷе°ұйңҖиҰҒеӨ§йҮҸзҡ„еәҸеҲ—еҢ–пјҢеҸҚеәҸеҲ—еҢ–гҖӮ
дҪҶжҳҜpythonзЁӢеәҸд№Ӣй—ҙиҝҳеҸҜд»ҘдҪҝз”Ёpickpleи§ЈеҶіеәҸеҲ—еҢ–пјҢеҸҚеәҸеҲ—еҢ–пјҢеҰӮжһңжҳҜи·Ёе№іеҸ°пјҢи·ЁиҜӯиЁҖпјҢи·ЁеҚҸи®®pickleе°ұдёҚйҖӮеҗҲдәҶпјҢе°ұйңҖиҰҒе…¬е…ұеҚҸи®®пјҢеҰӮXML/Json /protocol BufferзӯүгҖӮ
жҜҸз§ҚеҚҸи®®йғҪжңүиҮӘе·ұзҡ„иҙҹиҪҪпјҢе…¶жүҖдҪҝз”Ёзҡ„еңәжҷҜйғҪдёҚдёҖж ·пјҢдәҢиҝӣеҲ¶зҡ„ж“ҚдҪңдёҚдёҖе®ҡйҖӮз”ЁдәҺжүҖжңүзҡ„еңәжҷҜгҖӮдҪҶи¶ҠжҳҜеә•еұӮзҡ„еҚҸи®®пјҢи¶ҠйңҖиҰҒдәҢиҝӣеҲ¶дј иҫ“
дёү JSON
1 жҰӮиҝ°
JSON(JavaScript object notationпјҢJS еҜ№иұЎж Үи®°)жҳҜдёҖз§ҚиҪ»йҮҸзә§зҡ„ж•°жҚ®дәӨжҚўж јејҸпјҢе®ғеҹәдәҺECMAscript(w3cеҲ¶е®ҡзҡ„JS规иҢғ)зҡ„дёҖдёӘеӯҗйӣҶпјҢйҮҮз”Ёе®Ңе…ЁзӢ¬з«ӢдәҺзј–зЁӢиҜӯиЁҖзҡ„ж–Үжң¬ж јејҸжқҘеӯҳеӮЁе’ҢиЎЁзӨәж•°жҚ®
2 JSONзҡ„ж•°жҚ®зұ»еһӢ
е…¶keyеҝ…йЎ»жҳҜеӯ—з¬ҰдёІпјҢе…¶еҖјеҸҜд»ҘжҳҜдёӢйқўзұ»еһӢ
еҸҢеј•еҸ·еј•иө·жқҘзҡ„еӯ—з¬ҰдёІпјҢж•°еҖјпјҢtrueе’ҢfalseпјҢnullпјҲNoneпјүпјҢеҜ№иұЎпјҲеӯ—е…ёпјүпјҢж•°з»„пјҲеҲ—иЎЁпјүиҝҷдәӣйғҪжҳҜеҖј
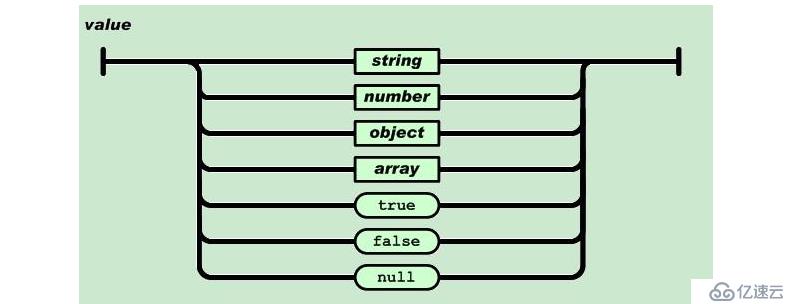
жӯӨеӨ„иЎЁзӨәдәҶJSONеҖјж”ҜжҢҒзҡ„ж•°жҚ®зұ»еһӢ
1 stringпјҡ
еӯ—з¬ҰдёІпјҢз”ұеҸҢеј•еҸ·еҢ…еӣҙиө·жқҘзҡ„д»»ж„Ҹеӯ—з¬Ұзҡ„з»„еҗҲпјҢеҸҜд»ҘжңүиҪ¬д№үеӯ—з¬Ұ
2 number пјҡ
ж•°еҖјпјҢжңүжӯЈиҙҹж•°пјҢж•ҙж•°пјҢжө®зӮ№ж•°
3 еҜ№иұЎпјҡ
ж— еәҸзҡ„й”®еҖјеҜ№йӣҶеҗҲ
ж јејҸ:{key1:value1,...keyn:valuen}
key еҝ…йЎ»жҳҜеӯ—з¬ҰдёІпјҢйңҖиҰҒдҪҝз”ЁеҸҢеј•еҸ·еҢ…еӣҙиҝҷдёӘеӯ—з¬ҰдёІпјҢvalueеҸҜд»ҘжҳҜд»»ж„ҸеҗҲжі•зҡ„еҖј
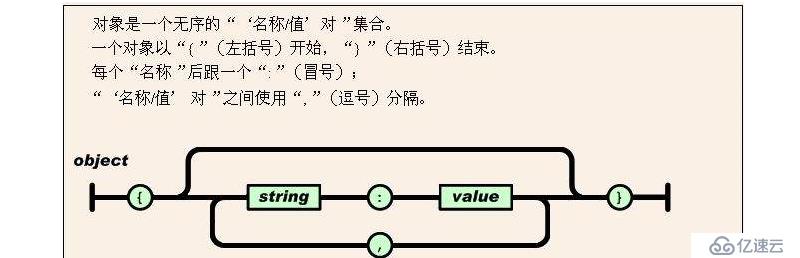
е…¶иЎЁзӨәиҰҒд№ҲжҳҜ{}пјҢиҰҒд№ҲжңүkeyпјҢvalue,иӢҘkey:valueе®ҢжҲҗпјҢеҲҷеҗҺйқўдёҚиғҪжңүйҖ—еҸ·пјҢдёҖж—ҰжңүйҖ—еҸ·пјҢеҲҷиЎЁзӨәеҗҺйқўиҝҳжңүж•°жҚ®
4 ж•°з»„ пјҡ
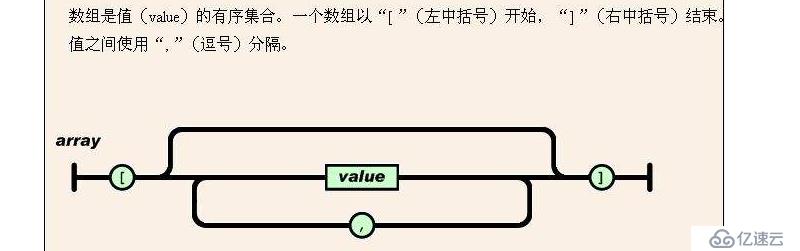
еҗҢдёҠпјҢдёҖж—ҰжңүйҖ—еҸ·пјҢеҲҷиЎЁзӨәеҗҺйқўиҝҳжңүж•°жҚ®
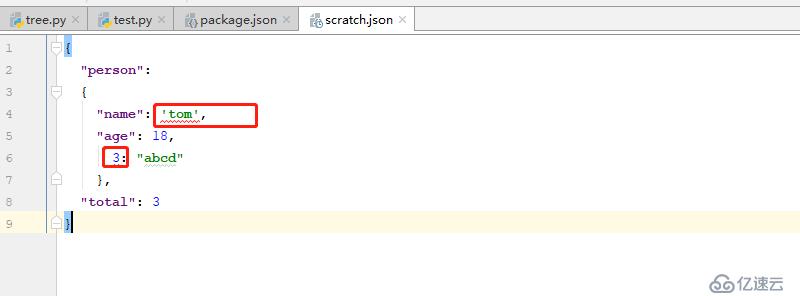
жӯӨеӨ„зҡ„й—®йўҳжҳҜпјҢе…¶jsonж–Ү件зҡ„й”®жҳҜйқһеӯ—з¬ҰдёІпјҢе…¶еҖјзҡ„еӯ—з¬ҰдёІдёҚжҳҜдҪҝз”ЁеҸҢеј•еҸ·жӢ¬иө·жқҘзҡ„пјҢеӣ жӯӨе…¶дјҡеҮәзҺ°жҠҘй”ҷзҡ„жғ…еҶө
5 null зӣёеҪ“дәҺpythonзҡ„None
6 еёғе°”еһӢ false(False) true(True)
3 еёёз”Ёж–№жі•
dumps json зј–з Ғ
dump json зј–з Ғ并еӯҳе…Ҙж–Ү件
loads json и§Јз Ғ
load json и§Јз ҒпјҢд»Һж–Ү件иҜ»еҸ–ж•°жҚ®
4 еә”з”Ё
#!/usr/local/bin/python3.6
#coding:utf-8
from json import *
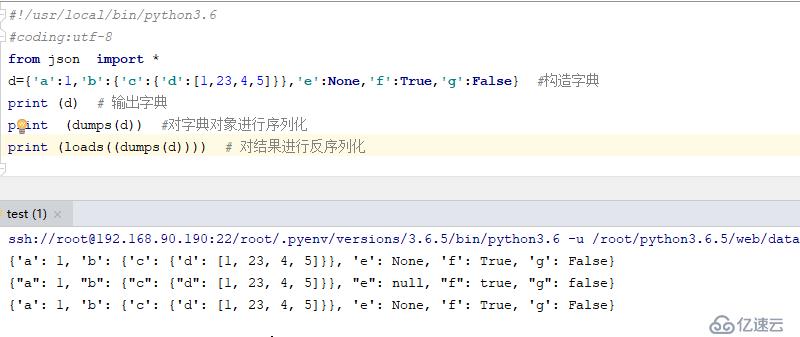
d={'a':1,'b':{'c':{'d':[1,23,4,5]}},'e':None,'f':True,'g':False} #жһ„йҖ еӯ—е…ё
print (d) # иҫ“еҮәеӯ—е…ё
print (dumps(d)) #еҜ№еӯ—е…ёеҜ№иұЎиҝӣиЎҢеәҸеҲ—еҢ–
print (loads((dumps(d)))) # еҜ№з»“жһңиҝӣиЎҢеҸҚеәҸеҲ—еҢ–
з»“жһңеҰӮдёӢ
#!/usr/local/bin/python3.6
#coding:utf-8
from json import *
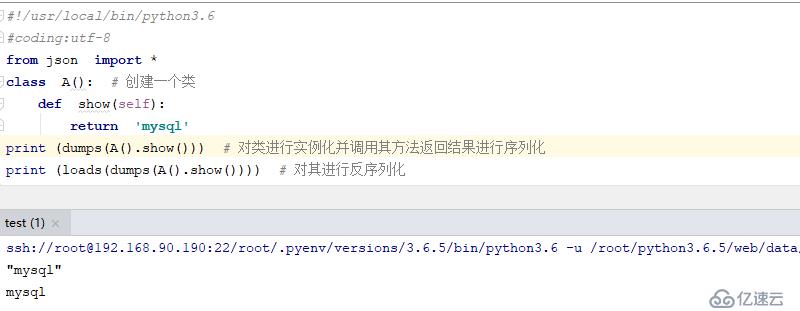
class A(): # еҲӣе»әдёҖдёӘзұ»
def show(self):
return 'mysql'
print (dumps(A().show())) # еҜ№зұ»иҝӣиЎҢе®һдҫӢеҢ–并и°ғз”Ёе…¶ж–№жі•иҝ”еӣһз»“жһңиҝӣиЎҢеәҸеҲ—еҢ–
print (loads(dumps(A().show()))) # еҜ№е…¶иҝӣиЎҢеҸҚеәҸеҲ—еҢ–
з»“жһңеҰӮдёӢ
дёҖиҲ¬зҡ„jsonзј–з Ғзҡ„ж•°жҚ®еҫҲе°‘иҗҪең°пјҢж•°жҚ®йғҪжҳҜйҖҡиҝҮзҪ‘з»ңдј иҫ“пјҢдј иҫ“зҡ„ж—¶еҖҷпјҢиҰҒиҖғиҷ‘еҺӢзј©е®ғпјҢжң¬иҙЁдёҠжқҘиҜҙе®ғе°ұжҳҜдёҖдёӘж–Үжң¬пјҢдёҖдёӘеӯ—з¬ҰдёІпјҢjsonеҫҲе№ҝжіӣпјҢеҮ д№ҺжүҖжңүзҡ„зј–зЁӢиҜӯиЁҖйғҪж”ҜжҢҒе®ғгҖӮ
еӣӣ messagepackпјҲ第дёүж–№еә“пјү
1 жҰӮиҝ°
messagepack жҳҜдёҖдёӘеҹәдәҺдәҢиҝӣеҲ¶й«ҳж•Ҳзҡ„еҜ№иұЎеәҸеҲ—еҢ–зұ»еә“пјҢеҸҜз”ЁдәҺи·ЁиҜӯиЁҖйҖҡдҝЎпјҢе…¶еҸҜд»ҘеғҸJSONйӮЈж ·пјҢеңЁи®ёеӨҡиҜӯиЁҖд№Ӣй—ҙдәӨжҚўз»“жһ„еҜ№иұЎпјҢдҪҶжҳҜе…¶жҜ”JSONжӣҙеҝ«йҖҹжӣҙиҪ»е·§гҖӮе…¶ж”ҜжҢҒpythonпјҢrubyпјҢJavaпјҢC/C++зӯүдј—еӨҡиҜӯиЁҖпјҢе…је®№JSONе’Ңpickle
2 е®үиЈ…
pip install msgpack-python
3 еёёз”Ёж–№жі•
packb еәҸеҲ—еҢ–еҜ№иұЎпјҢжҸҗдҫӣдәҶdumpsжқҘе…је®№pickleе’Ңjson
unpackb еҸҚеәҸеҲ—еҢ–еҜ№иұЎпјҢжҸҗдҫӣдәҶloadsжқҘе…је®№
packеәҸеҲ—еҢ–еҜ№иұЎдҝқеӯҳеҲ°ж–Ү件еҜ№иұЎпјҢжҸҗдҫӣдәҶdumpжқҘе…је®№
unpack еҸҚеәҸеҲ—еҢ–еҜ№иұЎдҝқеӯҳеҲ°ж–Ү件еҜ№иұЎпјҢжҸҗдҫӣдәҶloadжқҘе…је®№
4 еҹәжң¬еә”з”Ё
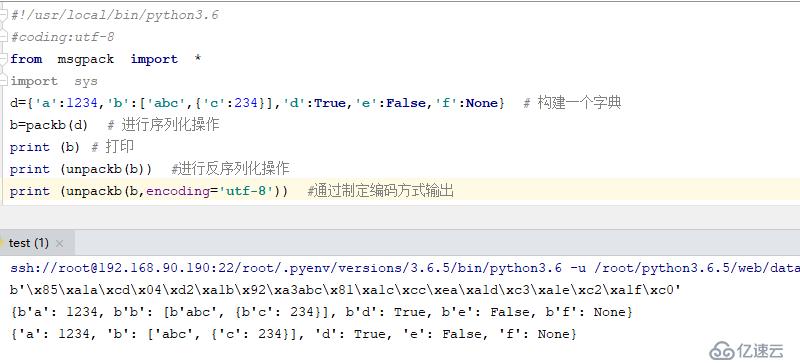
#!/usr/local/bin/python3.6
#coding:utf-8
from msgpack import *
import sys
d={'a':1234,'b':['abc',{'c':234}],'d':True,'e':False,'f':None} # жһ„е»әдёҖдёӘеӯ—е…ё
b=packb(d) # иҝӣиЎҢеәҸеҲ—еҢ–ж“ҚдҪң
print (b) # жү“еҚ°
print (unpackb(b)) #иҝӣиЎҢеҸҚеәҸеҲ—еҢ–ж“ҚдҪң
print (unpackb(b,encoding='utf-8')) #йҖҡиҝҮеҲ¶е®ҡзј–з Ғж–№ејҸиҫ“еҮә
з»“жһңеҰӮдёӢ