今天就跟大家聊聊有关urllib库如何在python中使用,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
python2
import urllib2
response = urllib2.urlopen('http://httpbin.org/robots.txt')
python3
import urllib.request
res = urllib.request.urlopen('http://httpbin.org/robots.txt')
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urlopen()方法中的url参数可以是字符串,也可以是一个Request对象
#url可以是字符串
import urllib.request
resp = urllib.request.urlopen('http://www.baidu.com')
print(resp.read().decode('utf-8')) # read()获取响应体的内容,内容是bytes字节流,需要转换成字符串##url可以也是Request对象
import urllib.request
request = urllib.request.Request('http://httpbin.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))# coding:utf8
import urllib.request, urllib.parse
data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
resp = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(resp.read())# coding:utf8
#设置请求超时时间
import urllib.request
resp = urllib.request.urlopen('http://httpbin.org/get', timeout=0.1)
print(resp.read().decode('utf-8'))# coding:utf8
#响应类型
import urllib.request
resp = urllib.request.urlopen('http://httpbin.org/get')
print(type(resp))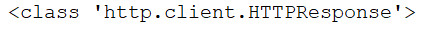
# coding:utf8
#响应的状态码、响应头
import urllib.request
resp = urllib.request.urlopen('http://www.baidu.com')
print(resp.status)
print(resp.getheaders()) # 数组(元组列表)
print(resp.getheader('Server')) # "Server"大小写不区分200
[('Bdpagetype', '1'), ('Bdqid', '0xa6d873bb003836ce'), ('Cache-Control', 'private'), ('Content-Type', 'text/html'), ('Cxy_all', 'baidu+b8704ff7c06fb8466a83df26d7f0ad23'), ('Date', 'Sun, 21 Apr 2019 15:18:24 GMT'), ('Expires', 'Sun, 21 Apr 2019 15:18:03 GMT'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('Server', 'BWS/1.1'), ('Set-Cookie', 'BAIDUID=8C61C3A67C1281B5952199E456EEC61E:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BIDUPSID=8C61C3A67C1281B5952199E456EEC61E; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'PSTM=1555859904; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'delPer=0; path=/; domain=.baidu.com'), ('Set-Cookie', 'BDSVRTM=0; path=/'), ('Set-Cookie', 'BD_HOME=0; path=/'), ('Set-Cookie', 'H_PS_PSSID=1452_28777_21078_28775_28722_28557_28838_28584_28604; path=/; domain=.baidu.com'), ('Vary', 'Accept-Encoding'), ('X-Ua-Compatible', 'IE=Edge,chrome=1'), ('Connection', 'close'), ('Transfer-Encoding', 'chunked')]
BWS/1.1
# coding:utf8
proxy_handler = urllib.request.ProxyHandler({'http': 'http://www.example.com:3128/'})
proxy_auth_handler = urllib.request.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', 'host', 'username', 'password')
opener = urllib.request.build_opener(proxy_handler, proxy_auth_handler)
# This time, rather than install the OpenerDirector, we use it directly:
resp = opener.open('http://www.example.com/login.html')
print(resp.read())# coding:utf8
from urllib import error, request
try:
resp = request.urlopen('http://www.blueflags.cn')
except error.URLError as e:
print(e.reason)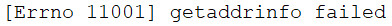
# coding:utf8
from urllib import error, request
try:
resp = request.urlopen('http://www.baidu.com')
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('request successfully')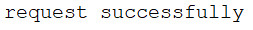
# coding:utf8
import socket, urllib.request, urllib.error
try:
resp = urllib.request.urlopen('http://www.baidu.com', timeout=0.01)
except urllib.error.URLError as e:
print(type(e.reason))
if isinstance(e.reason,socket.timeout):
print('time out')
# coding:utf8
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'Host': 'httpbin.org',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
dict = {'name': 'Germey'}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
resp = request.urlopen(req)
print(resp.read().decode('utf-8')){
"args": {},
"data": "",
"files": {},
"form": {
"name": "Thanlon"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "12",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
},
"json": null,
"origin": "117.136.78.194, 117.136.78.194",
"url": "https://httpbin.org/post"
}# coding:utf8
from urllib import request, parse
url = 'http://httpbin.org/post'
dict = {'name': 'Thanlon'}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, method='POST')
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36')
resp = request.urlopen(req)
print(resp.read().decode('utf-8'))# coding:utf8
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=1#comment')
print(type(result))
print(result)<class 'urllib.parse.ParseResult'>
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=1', fragment='comment')
from urllib.parse import urlparse
result = urlparse('www.baidu.com/index.html;user?id=1#comment', scheme='https')
print(type(result))
print(result)<class 'urllib.parse.ParseResult'>
ParseResult(scheme='https', netloc='', path='www.baidu.com/index.html', params='user', query='id=1', fragment='comment')
# coding:utf8
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=1#comment', scheme='https')
print(result)ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=1', fragment='comment')
# coding:utf8
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=1#comment',allow_fragments=False)
print(result)ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=1', fragment='comment')
# coding:utf8 from urllib.parse import urlunparse data = ['http', 'www.baidu.com', 'index.html', 'user', 'name=Thanlon', 'comment'] print(urlunparse(data))

# coding:utf8
from urllib.parse import urljoin
print(urljoin('http://www.bai.com', 'index.html'))
print(urljoin('http://www.baicu.com', 'https://www.thanlon.cn/index.html'))#以后面为基准
# coding:utf8
from urllib.parse import urlencode
params = {
'name': 'Thanlon',
'age': 22
}
baseUrl = 'http://www.thanlon.cn?'
url = baseUrl + urlencode(params)
print(url)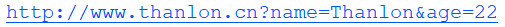
# coding:utf8
#cookie的获取(保持登录会话信息)
import urllib.request, http.cookiejar
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
res = opener.open('http://www.baidu.com')
for item in cookie:
print(item.name + '=' + item.value)
# coding:utf8
#将cookie保存为cookie.txt
import http.cookiejar, urllib.request
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
res = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)# coding:utf8
import http.cookiejar, urllib.request
filename = 'cookie.txt'
cookie = http.cookiejar.LWPCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
res = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)# coding:utf8
import http.cookiejar, urllib.request
cookie = http.cookiejar.LWPCookieJar()
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
resp = opener.open('http://www.baidu.com')
print(resp.read().decode('utf-8'))看完上述内容,你们对urllib库如何在python中使用有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





