本篇文章给大家分享的是有关如何在Python中使用SKlearn包,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
Sklearn(全称 SciKit-Learn),是基于 Python 语言的机器学习工具包。
Sklearn 主要用Python编写,建立在 Numpy、Scipy、Pandas 和 Matplotlib 的基础上,也用 Cython编写了一些核心算法来提高性能。
Sklearn 包括六大功能模块:
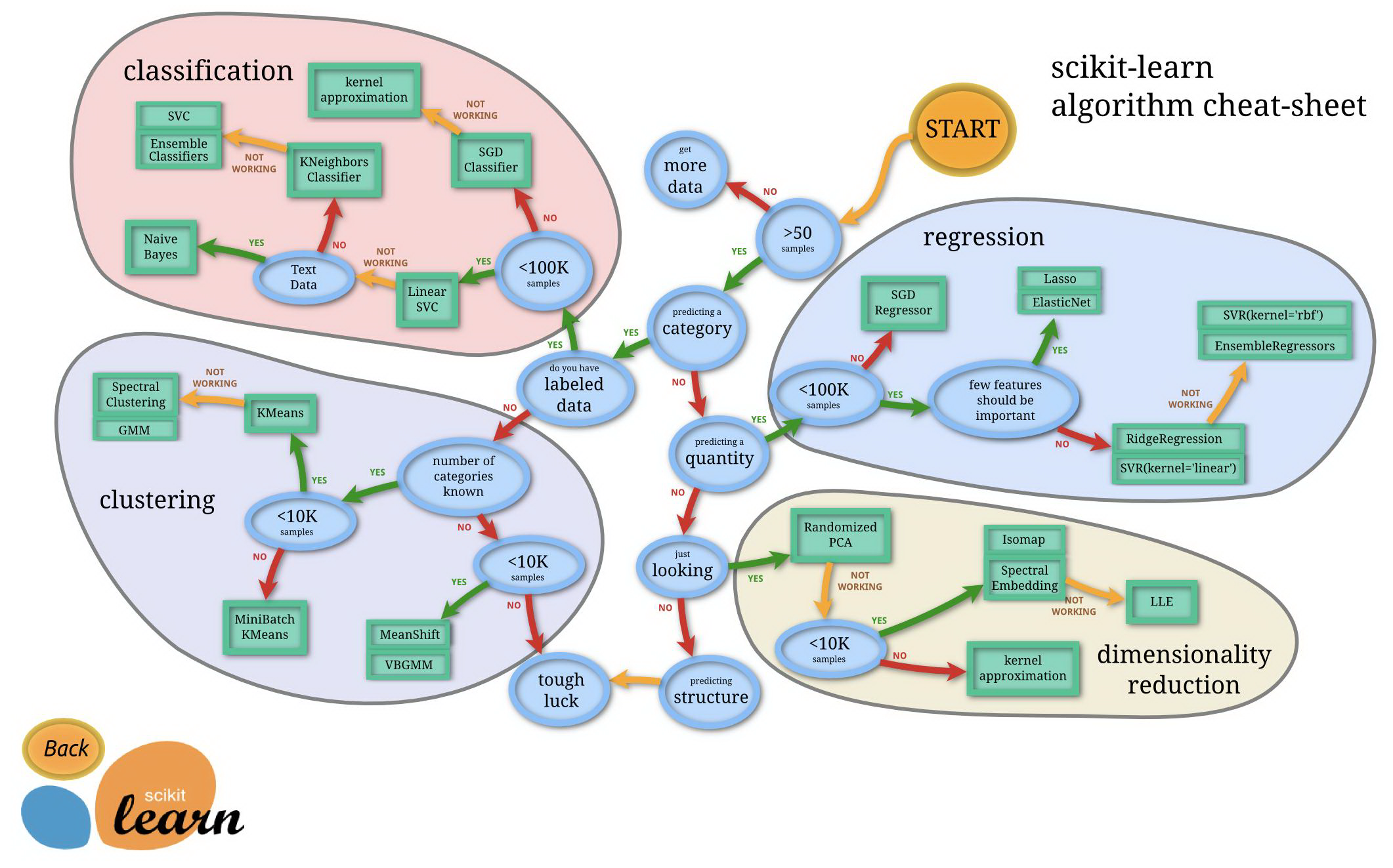
分类(Classification):识别样本属于哪个类别,常用算法有 SVM(支持向量机)、nearest neighbors(最近邻)、random forest(随机森林)
回归(Regression):预测与对象相关联的连续值属性,常用算法有 SVR(支持向量机)、 ridge regression(岭回归)、Lasso
聚类(Clustering):对样本进行无监督的自动分类,常用算法有 k-Means(k均值)、spectral clustering(特征聚类)、mean-shift(均值漂移)
数据降维(Dimensionality reduction):减少相关变量维数,常用算法有 PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解)
模型选择(Model Selection):比较,验证,选择参数和模型,常用模块有 grid search(网格搜索)、cross validation(交叉验证)、 metrics(度量)
数据处理 (Preprocessing):特征提取和归一化,常用模块有 preprocessing(预处理),feature extraction(特征提取)
这六个功能模块涉及 4类算法,分类、回归 属于监督学习,聚类属于非监督学习。

2、SKlearn 的安装
Sklearn 的安装要求:Python 3.5 以上版本,需要安装 NumPy、SciPy、Pandas 工具包的支持,部分内容需要使用 Matplotlib、joblib 工具包。
pip 安装命令:
pip3 install -U scikit-learn
pip3 install -U scikit-learn -i https://pypi.douban.com/simple
注意 Sklearn 建议安装 Numpy+mkl,可以在网址http://www.lfd.uci.edu/~gohlke/pythonlibs/ 找到你需要的numpy+mkl版本,下载后 pip3安装:
pip install numpy-1.11.1+mkl-cp27-cp27m-win_amd64.whl
Sklearn 内置了一些标准数据集可以用于练习和测试,都是经常被引用的经典问题,数据网址:https://scikit-learn.org/stable/datasets.html
Sklearn 标准数据集主要包括:
波士顿房价:Boston house prices dataset
鸢尾花问题:Iris plants dataset
糖尿病数据:Diabetes dataset
手写数字的识别:Optical recognition of handwritten digits dataset
体能训练:Linnerrud dataset
葡萄酒鉴别:Wine recognition dataset
威斯康星州癌症诊断:reast cancer wisconsin (diagnostic) dataset
人脸数据:The Olivetti faces dataset
20个新闻文本数据:The 20 newsgroups text dataset
标记的人脸数据:The Labeled Faces in the Wild face recognition dataset
森林覆盖类型:Forest covertypes
路透社新闻数据:RCV1 dataset
网络入侵检测数据:Kddcup 99 dataset
加州住房数据:California Housing dataset
粗略看看 Sklearn 的文档,是一个功能强大和丰富的机器学习库,远远超出了数学建模学习的范围。
基于数模教学的目的,本系列主要对应数模学习中的分类、聚类、降维问题,并不打算全面讲解 Sklearn 的各种算法,而是以典型问题为例来介绍原理简单、使用广泛的基本方法,以便新手入门。
python的数据类型:1. 数字类型,包括int(整型)、long(长整型)和float(浮点型)。2.字符串,分别是str类型和unicode类型。3.布尔型,Python布尔类型也是用于逻辑运算,有两个值:True(真)和False(假)。4.列表,列表是Python中使用最频繁的数据类型,集合中可以放任何数据类型。5. 元组,元组用”()”标识,内部元素用逗号隔开。6. 字典,字典是一种键值对的集合。7. 集合,集合是一个无序的、不重复的数据组合。
以上就是如何在Python中使用SKlearn包,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





