PythonжҖҺд№Ҳе®һзҺ°ж–Ү件иҮӘеҠЁеҺ»йҮҚ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚPythonжҖҺд№Ҳе®һзҺ°ж–Ү件иҮӘеҠЁеҺ»йҮҚпјҢж–Үдёӯд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢе…·жңүдёҖе®ҡзҡ„еҸӮиҖғд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们дёҖе®ҡиҰҒзңӢе®ҢпјҒ
Python ж–Ү件иҮӘеҠЁеҺ»йҮҚ
е№іж—ҘйҮҢдёҖжқҘж— иҒҠпјҢдәҢжқҘжүӢе·§пјҢжһң然дёӢиҪҪдәҶеҘҪеӨҡж— (luan)жҜ”(qi)зҸҚ(ba)иҙө(zao)зҡ„иө„ж–ҷпјҢжҗһеҫ—жҲ‘е°Ҹе°Ҹзҡ„зЎ¬зӣҳпјҲе·Із»Ҹжү©еҲ°6TдәҶпјүжҚүиҘҹи§ҒиӮҳпјҢ
жңүж¬Ўж— ж„Ҹй—ҙпјҢеҸ‘зҺ°жңүдёӨдёӘеұ…然й•ҝеҫ—дёҖжҜӣдёҖж ·пјҢеңЁжҲҝеӯҗиҝҷд№Ҳе°Ҹзҡ„жғ…еҶөдёӢпјҢжҲ‘жҖҺиғҪеҝҚдёӨдёӘдёҖжҜӣдёҖж ·зҡ„дёңиҘҝдёҚиҰҒи„ёзҡ®зҡ„иәәеңЁжҲ‘зҡ„зЎ¬зӣҳйҮҢпјҢжһңж–ӯжҗһжҺүдёҖдёӘпјҢж•ҙзҗҶдёҖдёӢпјҢжң¬жқҘжғіж–Ү件еҗҚдёҖж ·зҡ„е°ұдҝқз•ҷдёҖд»ҪпјҢдҪҶй—®йўҳеҮәзҺ°дәҶпјҢеұ…然жңүеҗҚеӯ—дёҖж ·пјҢеҶ…е®№еҚҙе®Ңе…ЁдёҚдёҖж ·зҡ„ж–Ү件пјҢжғіжҲ‘иғҢжңқй»„еңҹйқўжңқеӨ©еҗ№зқҖз©әи°ғеҗғзқҖиҘҝз“ңдёӢиҪҪдёӢжқҘзҡ„дёңиҘҝпјҢеҲ йҷӨжҳҜдёҚеҸҜиғҪзҡ„пјҢиҝҷиҫҲеӯҗйғҪжҳҜдёҚеҸҜиғҪеҲ йҷӨзҡ„гҖӮеҸҜжҳҜжҲ‘д№ҹеҸҲдёҚиғҪжҠҠиҝҷж•°д»Ҙдәҝи®Ўзҡ„ж–Ү件жҢЁдёӘжү“ејҖзңӢзңӢйҮҢйқўдёҖж ·дёҚдёҖж ·еҗ§пјҢиҝҷдёӘе·ҘзЁӢжҲ‘еӨ§жҰӮеӨҹжҲ‘еҒҡдәҶеҘҪд№…еҘҪд№…дәҶпјҢжңүжІЎжңүеҠһжі•жҗһдёӘиҪҜ件帮帮жҲ‘е‘ўпјҢзӯ”жЎҲжҳҜиӮҜе®ҡзҡ„пјҢиҰҒдёҚ然жҲ‘д№ҹдёҚз”ЁеңЁиҝҷйҮҢеҶҷиҝҷдёӘеҚҡе®ўдәҶпјҲеә”иҜҘжҳҜиӢҰйҖјзҡ„дёҖдёӘдёҖдёӘжү“ејҖжҜ”иҫғеҗ§пјүпјҢиҜҙжӯЈйўҳпјҢPythonжҸҗдҫӣдәҶдёҖдёӘжҜ”иҫғж–Ү件еҶ…е®№зҡ„дёңиҘҝпјҢйӮЈе°ұжҳҜгҖӮгҖӮгҖӮгҖӮгҖӮгҖӮгҖӮгҖӮгҖӮгҖӮе“ҲеёҢз®—жі•
MD5ж¶ҲжҒҜж‘ҳиҰҒз®—жі•пјҲиӢұиҜӯпјҡMD5 Message-Digest AlgorithmпјүпјҢдёҖз§Қиў«е№ҝжіӣдҪҝз”Ёзҡ„еҜҶз Ғж•ЈеҲ—еҮҪж•°пјҢеҸҜд»Ҙдә§з”ҹеҮәдёҖдёӘ128дҪҚпјҲ16еӯ—иҠӮпјүзҡ„ж•ЈеҲ—еҖјпјҲhash valueпјүпјҢз”ЁдәҺзЎ®дҝқдҝЎжҒҜдј иҫ“е®Ңж•ҙдёҖиҮҙгҖӮMD5з”ұзҫҺеӣҪеҜҶз ҒеӯҰ家зҪ—зәіеҫ·В·жқҺз»ҙж–Ҝзү№пјҲRonald Linn Rivestпјүи®ҫи®ЎпјҢдәҺ1992е№ҙе…¬ејҖпјҢз”Ёд»ҘеҸ–д»ЈMD4з®—жі•гҖӮ
иҜҙдәҶиҝҷд№Ҳй•ҝпјҢжҖ»з»“еҮәжқҘе°ұдёҖеҸҘпјҢиҝҷзҺ©ж„Ҹе°ұжҳҜж–Ү件зҡ„жҢҮзә№пјҢеҮ д№ҺжҜҸдёӘж–Ү件жҳҜе”ҜдёҖзҡ„пјҲзў°еҲ°йҮҚеӨҚзҡ„пјҢжҒӯе–ңдҪ пјҢеҸҜд»ҘеҺ»д№°еҪ©зҘЁдәҶпјүпјҢйӮЈжҲ‘们е°ұжҠҠиҝҷдёӘжҢҮзә№жӢҝеҮәжқҘпјҢдёҖдёӘдёҖдёӘжҜ”еҜ№пјҢиӮҜе®ҡдёҚиғҪдјҡжңүжјҸзҪ‘зҡ„ж–Ү件пјҢж—ўдёҚдјҡй”ҷжқҖдёүеҚғпјҢд№ҹдёҚдҪҝдёҖж–Ү件жјҸзҪ‘пјҢеҺҹзҗҶдёҠйҖҡдәҶпјҢйӮЈд№ҲжҲ‘们е°ұиҰҒеҺ»жҗһдёӘд»Јз ҒжқҘеё®жҲ‘е®ҢжҲҗиҝҷдёӘе·ҘдҪңпјҢдҪңдёәжңҖеҘҪз”Ёзҡ„иҜӯиЁҖпјҢPythonе°ұиҝҷж ·иў«жҲ‘зҝ»дәҶзүҢеӯҗ
# -*- coding:utf-8 -*-
import os
import hashlib
import time
import sys
#жҗһеҲ°ж–Ү件зҡ„MD5
def get_ms5(filename):
m = hashlib.md5()
mfile = open(filename , "rb")
m.update(mfile.read())
mfile.close()
md5_value = m.hexdigest()
return md5_value
#жҗһеҲ°ж–Ү件зҡ„еҲ—иЎЁ
def get_urllist():
base = ("D:\\lwj\\spider\\pic\\")#иҝҷйҮҢе°ұжҳҜдҪ иҰҒжё…зјҙзҡ„ж–Ү件们дәҶ
list = os.listdir(base)
urllist = []
for i in list:
url = base + i
urllist.append(url)
return urllist
#дё»еҮҪж•°
if __name__ == '__main__':
md5list = []
urllist = get_urllist()
print("test1")
for a in urllist:
md5 = get_ms5(a)
if(md5 in md5list):
os.remove(a)
print("йҮҚеӨҚпјҡ%s" % a)
else:
md5list.append(md5)
print("дёҖе…ұ%sеј з…§зүҮ" % len(md5list))ж•Ҳжһң
python3 еӨ§ж–Ү件еҺ»йҮҚ
дёҖгҖҒз”ҹжҲҗеҫ…еҺ»йҮҚж•°жҚ®
жҜҸиЎҢжҳҜеӣәе®ҡдҪҚж•°зҡ„ж•°еӯ—дёІ
import os
from random import randint
#-- from u_е·Ҙе…· import *
print("вҖ”вҖ”вҖ”вҖ” ејҖе§Ӣ вҖ”вҖ”вҖ”вҖ”")
#-- жү“зӮ№()
# з”ЁжқҘй…ҚзҪ®зҡ„еҸҳйҮҸ
дҪҚж•° = 13
иЎҢж•° = 500 * 10000
иҫ“еҮәзӣ®еҪ• = "./a_иҫ“е…Ҙ"
иҫ“еҮәж–Ү件 = f"{иҫ“еҮәзӣ®еҪ•}/йҡҸжңәж•°.txt"
# йў„еӨ„зҗҶ
_00 = "".join(["0" for i in range(дҪҚж•° - 1)])
_100 = "1" + _00
жңҖе°ҸеҖј = int(_100)
_1000 = _100 + "0"
жңҖеӨ§еҖј = int(_1000)
if not os.path.exists(иҫ“еҮәзӣ®еҪ•):
os.makedirs(иҫ“еҮәзӣ®еҪ•)
#-- иҫ“еҮәж–Ү件 = ж–Ү件еҗҚйҳІйҮҚ_иҝҪеҠ ж•°еӯ—(иҫ“еҮәж–Ү件)
# е®һйҷ…еӨ„зҗҶ
with open(иҫ“еҮәж–Ү件,"a") as f:
for i in range(иЎҢж•°):
f.write(f"{randint(жңҖе°ҸеҖј, жңҖеӨ§еҖј)}\n")
зҷҫеҲҶжҜ” = (i+1) / иЎҢж•° * 100
if зҷҫеҲҶжҜ” == int(зҷҫеҲҶжҜ”):
print(f"е·Іе®ҢжҲҗ{int(зҷҫеҲҶжҜ”)}%")
#-- жү“зӮ№()
#-- print(f"\nжҖ»иҖ—ж—¶пјҡ{и®Ўж—¶(0)}")
print("вҖ”вҖ”вҖ”вҖ” з»“жқҹ вҖ”вҖ”вҖ”вҖ”")
дәҢгҖҒйҖҡиҝҮsetжҢүиЎҢеҺ»йҮҚ
1. жҢүеҺҹеҖјжҜ”иҫғ
пјҲ1пјүиҜ»еҸ–е…ЁйғЁж•°жҚ®
пјҲ2пјүз”ЁsplitжқҘеҲҶиЎҢ
пјҲ3пјүйҖҡиҝҮsetж•°жҚ®з»“жһ„жқҘеҺ»йҷӨйҮҚеӨҚж•°жҚ®
пјҲ4пјүе°Ҷsetзҡ„ж•°жҚ®еҶҷе…Ҙж–Ү件
import os
#-- from u_е·Ҙе…· import *
print("вҖ”вҖ”вҖ”вҖ” ејҖе§Ӣ вҖ”вҖ”вҖ”вҖ”")
#-- жү“зӮ№()
# з”ЁжқҘй…ҚзҪ®зҡ„еҸҳйҮҸ
иҫ“е…Ҙзӣ®еҪ• = "./a_иҫ“е…Ҙ"
иҫ“еҮәзӣ®еҪ• = "./b_иҫ“еҮә"
иҫ“еҮәж–Ү件 = f"{иҫ“еҮәзӣ®еҪ•}/еҺ»йҮҚз»“жһң.txt"
# йў„еӨ„зҗҶ
# зӣ®еҪ•дёҚеӯҳеңЁе°ұжүӢеҠЁе»әз«Ӣ
if not os.path.exists(иҫ“еҮәзӣ®еҪ•):
os.makedirs(иҫ“еҮәзӣ®еҪ•)
if not os.path.exists(иҫ“е…Ҙзӣ®еҪ•):
os.makedirs(иҫ“е…Ҙзӣ®еҪ•)
#-- иҫ“еҮәж–Ү件 = ж–Ү件еҗҚйҳІйҮҚ_иҝҪеҠ ж•°еӯ—(иҫ“еҮәж–Ү件)
# иҺ·еҸ–еҫ…еҺ»йҮҚж–Ү件
еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ = []
еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ = [f"{иҫ“е…Ҙзӣ®еҪ•}/{i}" for i in os.listdir(иҫ“е…Ҙзӣ®еҪ•)]
#-- getDeepFilePaths(еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ,иҫ“е…Ҙзӣ®еҪ•,"txt")
print(f"\nжҖ»е…ұ{len(еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ)}дёӘж–Ү件")
жҚўиЎҢз¬Ұ = b"\n"
if platform.system().lower() == 'windows':
жҚўиЎҢз¬Ұ = b"\r\n"
# е®һйҷ…еӨ„зҗҶ
all_lines = []
ж–Ү件дёӘж•° = 0
for ж–Ү件 in еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ:
ж–Ү件дёӘж•° += 1
print(f"\nеӨ„зҗҶ第{ж–Ү件дёӘж•°}дёӘж–Ү件")
#-- жү“зӮ№()
# (1)иҜ»е…ЁйғЁ
with open(ж–Ү件, "rb") as f:
data = f.read()
# (2)splitеҲҶиЎҢ
lines = data.split(жҚўиЎҢз¬Ұ)
all_lines.extend(lines)
#-- жү“зӮ№()
#-- print(f"еҲҶиЎҢе®ҢжҜ•пјҢиҖ—ж—¶пјҡ{и®Ўж—¶()}")
# (3)йӣҶеҗҲеҺ»йҮҚ
all_lines_set = set(all_lines)
all_lines_set.remove(b"")
#-- жү“зӮ№()
#-- print(f"\n\nеҺ»йҮҚе®ҢжҜ•пјҢиҖ—ж—¶пјҡ{и®Ўж—¶()}")
# (4)еҫӘзҺҜеҶҷе…Ҙ
with open(иҫ“еҮәж–Ү件,"ab") as f_rst:
for line in all_lines_set:
f_rst.write(line + жҚўиЎҢз¬Ұ)
#-- жү“зӮ№()
#-- print(f"\nеҶҷе…Ҙе®ҢжҜ•пјҢиҖ—ж—¶пјҡ{и®Ўж—¶()}")
print(f"\nиҫ“еҮәж–Ү件пјҡ{иҫ“еҮәж–Ү件}")
#-- жү“зӮ№()
#-- print(f"\n\nжҖ»иҖ—ж—¶пјҡ{и®Ўж—¶(0)}")
print("вҖ”вҖ”вҖ”вҖ” з»“жқҹ вҖ”вҖ”вҖ”вҖ”")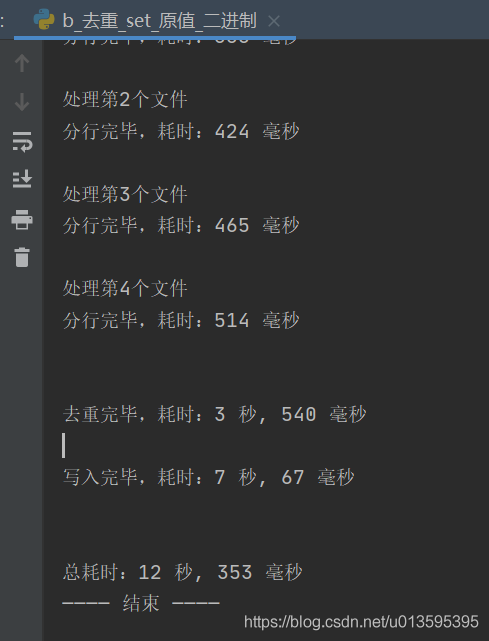
йҷ„пјҡ
пјҲ2пјүз”ЁжӯЈеҲҷиЎЁиҫҫејҸжқҘеҲҶиЎҢ
import re
# (2)жӯЈеҲҷеҲҶиЎҢ дәҢиҝӣеҲ¶зҡ„иҜқиҰҒеҠ bпјҢ b''' '''
regx = '''[\w\~`\!\@\#\$\%\^\&\*\(\)\_\-\+\=\[\]\{\}\:\;\,\.\/\<\>\?]+'''
lines = re.findall(regx, data)2. жҢүmd5жҜ”иҫғ
import hashlib
import os
#-- from u_е·Ҙе…· import *
print("вҖ”вҖ”вҖ”вҖ” ејҖе§Ӣ вҖ”вҖ”вҖ”вҖ”")
#-- жү“зӮ№()
# з”ЁжқҘй…ҚзҪ®зҡ„еҸҳйҮҸ
иҫ“е…Ҙзӣ®еҪ• = "./a_иҫ“е…Ҙ"
иҫ“еҮәзӣ®еҪ• = "./b_иҫ“еҮә"
иҫ“еҮәж–Ү件 = f"{иҫ“еҮәзӣ®еҪ•}/еҺ»йҮҚз»“жһң.txt"
# йў„еӨ„зҗҶ
# зӣ®еҪ•дёҚеӯҳеңЁе°ұжүӢеҠЁе»әз«Ӣ
if not os.path.exists(иҫ“еҮәзӣ®еҪ•):
os.makedirs(иҫ“еҮәзӣ®еҪ•)
if not os.path.exists(иҫ“е…Ҙзӣ®еҪ•):
os.makedirs(иҫ“е…Ҙзӣ®еҪ•)
#-- иҫ“еҮәж–Ү件 = ж–Ү件еҗҚйҳІйҮҚ_иҝҪеҠ ж•°еӯ—(иҫ“еҮәж–Ү件)
# иҺ·еҸ–еҫ…еҺ»йҮҚж–Ү件
еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ = [f"{иҫ“е…Ҙзӣ®еҪ•}/{i}" for i in os.listdir(иҫ“е…Ҙзӣ®еҪ•)]
#-- еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ = []
#-- getDeepFilePaths(еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ,иҫ“е…Ҙзӣ®еҪ•,"txt")
print(f"\nжҖ»е…ұ{len(еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ)}дёӘж–Ү件")
def gen_md5(data):
md5 = hashlib.md5()
if repr(type(data)) == "<class 'str'>":
data = data.encode('utf-8')
md5.update(data)
return md5.hexdigest()
# е®һйҷ…еӨ„зҗҶ
md5йӣҶ = set()
with open(иҫ“еҮәж–Ү件, "a") as f_rst:
ж–Ү件дёӘж•° = 0
for ж–Ү件 in еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ:
ж–Ү件дёӘж•° += 1
print(f"\nеӨ„зҗҶ第{ж–Ү件дёӘж•°}дёӘж–Ү件")
# и®Ўз®—жҖ»иЎҢж•°
with open(ж–Ү件, 'rb') as f:
иЎҢж•° = 0
buf_size = 1024 * 1024
buf = f.read(buf_size)
while buf:
иЎҢж•° += buf.count(b'\n')
buf = f.read(buf_size)
# иҜ»еҸ–гҖҒеҲҶиЎҢгҖҒеҺ»йҮҚгҖҒеҶҷе…Ҙ
#-- жү“зӮ№()
i = 0
for line_еёҰжҚўиЎҢ in open(ж–Ү件):
i += 1
line = line_еёҰжҚўиЎҢ.strip()
md5еҖј = gen_md5(line)
if md5еҖј not in md5йӣҶ:
md5йӣҶ.add(md5еҖј)
f_rst.write(line_еёҰжҚўиЎҢ)
зҷҫеҲҶжҜ” = i / иЎҢж•° * 10
if зҷҫеҲҶжҜ” == int(зҷҫеҲҶжҜ”):
print(f"е·Іе®ҢжҲҗ{int(зҷҫеҲҶжҜ”)*10}%")
#-- жү“зӮ№()
#-- print(f"иҖ—ж—¶пјҡ{и®Ўж—¶()}")
print(f"\nиҫ“еҮәж–Ү件пјҡ{иҫ“еҮәж–Ү件}")
#-- жү“зӮ№()
#-- print(f"\n\nжҖ»иҖ—ж—¶пјҡ{и®Ўж—¶(0)}")
print("вҖ”вҖ”вҖ”вҖ” з»“жқҹ вҖ”вҖ”вҖ”вҖ”")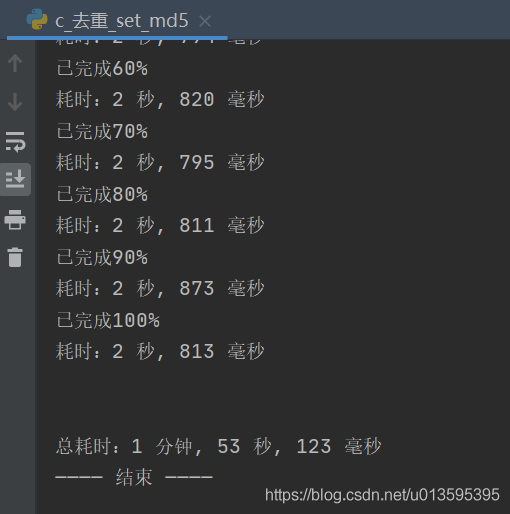
дёүгҖҒдәҢи·ҜеҪ’并
import hashlib
import os
import platform
import queue
import shutil
from uuid import uuid1
from u_е·Ҙе…· import *
print("вҖ”вҖ”вҖ”вҖ” ејҖе§Ӣ вҖ”вҖ”вҖ”вҖ”")
жү“зӮ№()
# 1.з”ЁжқҘй…ҚзҪ®зҡ„еҸҳйҮҸ
иҫ“е…Ҙзӣ®еҪ• = "./a_иҫ“е…Ҙ"
иҫ“еҮәзӣ®еҪ• = "./b_иҫ“еҮә"
иҫ“еҮәж–Ү件 = f"{иҫ“еҮәзӣ®еҪ•}/еҺ»йҮҚз»“жһң.txt"
дёҙж—¶зӣ®еҪ• = "./c_дёҙж—¶"
е°Ҹж–Ү件еӨ§е°Ҹ = 50 * 1024 * 1024 # 50M
# 2.йў„еӨ„зҗҶ
# зӣ®еҪ•дёҚеӯҳеңЁе°ұжүӢеҠЁе»әз«Ӣ
if not os.path.exists(иҫ“еҮәзӣ®еҪ•):
os.makedirs(иҫ“еҮәзӣ®еҪ•)
if not os.path.exists(иҫ“е…Ҙзӣ®еҪ•):
os.makedirs(иҫ“е…Ҙзӣ®еҪ•)
if not os.path.exists(дёҙж—¶зӣ®еҪ•):
os.makedirs(дёҙж—¶зӣ®еҪ•)
shutil.rmtree(дёҙж—¶зӣ®еҪ•)
os.makedirs(дёҙж—¶зӣ®еҪ•)
иҫ“еҮәж–Ү件 = ж–Ү件еҗҚйҳІйҮҚ_иҝҪеҠ ж•°еӯ—(иҫ“еҮәж–Ү件)
# иҺ·еҸ–еҫ…еҺ»йҮҚж–Ү件
# еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ = [f"{иҫ“е…Ҙзӣ®еҪ•}/{i}" for i in os.listdir(иҫ“е…Ҙзӣ®еҪ•)]
еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ = []
getDeepFilePaths(еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ,иҫ“е…Ҙзӣ®еҪ•,"txt")
print(f"жҖ»е…ұ{len(еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ)}дёӘж–Ү件")
жҚўиЎҢз¬Ұ = b"\n"
if platform.system().lower() == 'windows':
жҚўиЎҢз¬Ұ = b"\r\n"
# 3.е®һйҷ…еӨ„зҗҶ
# (1)еҲҶеүІеӨ§ж–Ү件
жү“зӮ№()
еҫ…жҺ’еәҸж–Ү件еҲ—иЎЁ = []
еҫ…иЎҘе…Ёж•°жҚ® = b""
for ж–Ү件 in еҫ…еҺ»йҮҚж–Ү件еҲ—иЎЁ:
with open(ж–Ү件, 'rb') as f:
buf = f.read(е°Ҹж–Ү件еӨ§е°Ҹ)
while buf:
data = buf.split(жҚўиЎҢз¬Ұ,1)
ж–°и·Ҝеҫ„ = f"{дёҙж—¶зӣ®еҪ•}/ж— еәҸ_{еәҸеҸ·(1)}_{uuid1()}.txt"
with open(ж–°и·Ҝеҫ„, 'ab') as ff:
ff.write(еҫ…иЎҘе…Ёж•°жҚ® + data[0])
еҫ…жҺ’еәҸж–Ү件еҲ—иЎЁ.append(ж–°и·Ҝеҫ„)
try:
еҫ…иЎҘе…Ёж•°жҚ® = data[1]
except:
еҫ…иЎҘе…Ёж•°жҚ® = b""
buf = f.read(е°Ҹж–Ү件еӨ§е°Ҹ)
ж–°и·Ҝеҫ„ = f"{дёҙж—¶зӣ®еҪ•}/ж— еәҸ_{еәҸеҸ·(1)}_{uuid1()}.txt"
with open(ж–°и·Ҝеҫ„, 'ab') as ff:
ff.write(еҫ…иЎҘе…Ёж•°жҚ® + жҚўиЎҢз¬Ұ)
еҫ…жҺ’еәҸж–Ү件еҲ—иЎЁ.append(ж–°и·Ҝеҫ„)
еҫ…иЎҘе…Ёж•°жҚ® = b""
del buf,data,еҫ…иЎҘе…Ёж•°жҚ®
жү“зӮ№()
print(f"\nеҲҶеүІеӨ§ж–Ү件е®ҢжҲҗпјҢе…ұиҖ—ж—¶пјҡ{и®Ўж—¶()}")
# (2)жҺ’еәҸе°Ҹж–Ү件
жү“зӮ№()
еәҸеҸ·_йҮҚзҪ®(1)
еҫ…еҪ’并ж–Ү件йҳҹеҲ— = queue.Queue()
for ж–Ү件 in еҫ…жҺ’еәҸж–Ү件еҲ—иЎЁ:
with open(ж–Ү件, "rb") as f:
data = f.read()
data = set(data.split(жҚўиЎҢз¬Ұ))
if b"" in data:
data.remove(b"")
if жҚўиЎҢз¬Ұ in data:
data.remove(жҚўиЎҢз¬Ұ)
data = sorted(data)
ж–°и·Ҝеҫ„ = f"{дёҙж—¶зӣ®еҪ•}/жңүеәҸ_{еәҸеҸ·(1)}_{uuid1()}.txt"
with open(ж–°и·Ҝеҫ„, 'ab') as ff:
for line in data:
ff.write(line + жҚўиЎҢз¬Ұ)
еҫ…еҪ’并ж–Ү件йҳҹеҲ—.put(ж–°и·Ҝеҫ„)
os.remove(ж–Ү件)
del data
жү“зӮ№()
print(f"\nжҺ’еәҸе°Ҹж–Ү件е®ҢжҲҗпјҢе…ұиҖ—ж—¶пјҡ{и®Ўж—¶()}")
# (3)еҪ’并е°Ҹж–Ү件
жү“зӮ№("еҪ’并еүҚ")
еәҸеҸ·_йҮҚзҪ®(1)
дёӘж•° = еҫ…еҪ’并ж–Ү件йҳҹеҲ—.qsize()
еҪ’并次数 = дёӘж•° - 1
print(f"\n\nеҪ’并е…ұ{еҪ’并次数}ж¬Ў")
еҪ“еүҚж¬Ўж•° = 0
while дёӘж•° > 1:
еҪ“еүҚж¬Ўж•° += 1
print(f"\nжү§иЎҢ第{еҪ“еүҚж¬Ўж•°}ж¬ЎеҪ’并")
ж–Ү件и·Ҝеҫ„a = еҫ…еҪ’并ж–Ү件йҳҹеҲ—.get()
ж–Ү件и·Ҝеҫ„b = еҫ…еҪ’并ж–Ү件йҳҹеҲ—.get()
ж–°ж–Ү件и·Ҝеҫ„ = f"{дёҙж—¶зӣ®еҪ•}/{еәҸеҸ·(1)}_{uuid1()}.txt"
if еҪ“еүҚж¬Ўж•° == еҪ’并次数:
ж–°ж–Ү件и·Ҝеҫ„ = иҫ“еҮәж–Ү件
with open(ж–Ү件и·Ҝеҫ„a,"rb") as ж–Ү件a, open(ж–Ү件и·Ҝеҫ„b,"rb") as ж–Ү件b, open(ж–°ж–Ү件и·Ҝеҫ„,"wb") as ff:
# region еҪ’并ж“ҚдҪң
is_a_over = False
is_b_over = False
a = ж–Ү件a.readline().strip()
b = ж–Ү件b.readline().strip()
last = None
while not (is_a_over and is_b_over):
if is_a_over:
b = ж–Ү件b.readline()
if not b:
is_b_over = True
else:
ff.write(b)
elif is_b_over:
a = ж–Ү件a.readline()
if not a:
is_a_over = True
else:
ff.write(a)
else:
# region еӨ„зҗҶеҲқе§ӢиөӢеҖј
if not a:
is_a_over = True
if not b:
is_b_over = True
continue
else:
ff.write(b + жҚўиЎҢз¬Ұ)
continue
if not b:
is_b_over = True
ff.write(a + жҚўиЎҢз¬Ұ)
continue
# endregion
if a <= b:
if a == b or a == last:
a = ж–Ү件a.readline().strip()
if not a:
is_a_over = True
ff.write(b + жҚўиЎҢз¬Ұ)
continue
else:
last = a
ff.write(last + жҚўиЎҢз¬Ұ)
a = ж–Ү件a.readline().strip()
if not a:
is_a_over = True
ff.write(b + жҚўиЎҢз¬Ұ)
continue
else:
if b == last:
b = ж–Ү件b.readline().strip()
if not b:
is_b_over = True
ff.write(a + жҚўиЎҢз¬Ұ)
continue
else:
last = b
ff.write(last + жҚўиЎҢз¬Ұ)
b = ж–Ү件b.readline().strip()
if not b:
is_b_over = True
ff.write(a + жҚўиЎҢз¬Ұ)
continue
# endregion
еҫ…еҪ’并ж–Ү件йҳҹеҲ—.put(ж–°ж–Ү件и·Ҝеҫ„)
os.remove(ж–Ү件и·Ҝеҫ„a)
os.remove(ж–Ү件и·Ҝеҫ„b)
дёӘж•° = еҫ…еҪ’并ж–Ү件йҳҹеҲ—.qsize()
жү“зӮ№()
print(f"иҖ—ж—¶пјҡ{и®Ўж—¶()}")
жү“зӮ№("еҪ’并еҗҺ")
print(f"\n\nеҪ’并е°Ҹж–Ү件е®ҢжҲҗпјҢе…ұиҖ—ж—¶пјҡ{и®Ўж—¶('еҪ’并еүҚ','еҪ’并еҗҺ')}")
print(f"\nиҫ“еҮәж–Ү件пјҡ{иҫ“еҮәж–Ү件}")
жү“зӮ№()
print(f"\n\nжҖ»иҖ—ж—¶пјҡ{и®Ўж—¶(0)}")
print("вҖ”вҖ”вҖ”вҖ” з»“жқҹ вҖ”вҖ”вҖ”вҖ”")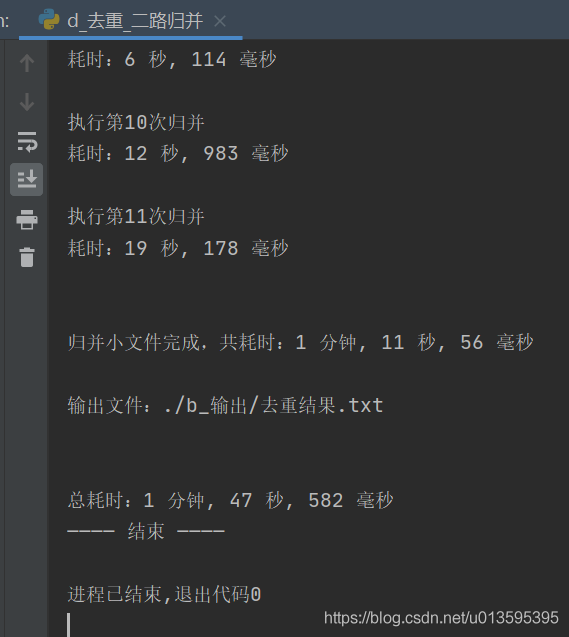
д»ҘдёҠжҳҜвҖңPythonжҖҺд№Ҳе®һзҺ°ж–Ү件иҮӘеҠЁеҺ»йҮҚвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





