JavaScriptдёӯDebuggerзҡ„еҺҹзҗҶеҲҶжһҗ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іJavaScriptдёӯDebuggerзҡ„еҺҹзҗҶеҲҶжһҗзҡ„еҶ…е®№гҖӮе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢдёҖиө·и·ҹйҡҸе°Ҹзј–иҝҮжқҘзңӢзңӢеҗ§гҖӮ
д»Јз ҒиҝҗиЎҢзҡ„еҺҹзҗҶжҳҜд»Җд№Ҳ
д»Јз Ғзҡ„иҝҗиЎҢж–№ејҸеҸҜд»ҘеҲҶдёәзӣҙжҺҘжү§иЎҢе’Ңи§ЈйҮҠжү§иЎҢдёӨзұ»гҖӮ
дёҚзҹҘйҒ“е№іж—¶дҪ жңүжІЎжңүжіЁж„ҸпјҢеҸҜжү§иЎҢж–Ү件зӣҙжҺҘ ./xxx е°ұеҸҜд»Ҙжү§иЎҢпјҢиҖҢжү§иЎҢ js ж–Ү件йңҖиҰҒ node ./xxxпјҢжү§иЎҢ python ж–Ү件йңҖиҰҒ python ./xxxпјҢиҝҷе°ұжҳҜзј–иҜ‘жү§иЎҢ(зӣҙжҺҘжү§иЎҢ)е’Ңи§ЈйҮҠжү§иЎҢзҡ„еҢәеҲ«гҖӮ
зӣҙжҺҘжү§иЎҢ
cpu жҸҗдҫӣдәҶдёҖеҘ—жҢҮд»ӨйӣҶпјҢеҹәдәҺиҝҷеҘ—жҢҮд»ӨйӣҶе°ұеҸҜд»ҘжҺ§еҲ¶ж•ҙдёӘи®Ўз®—жңәзҡ„иҝҗиҪ¬пјҢжңәеҷЁиҜӯиЁҖзҡ„д»Јз Ғе°ұжҳҜз”ұиҝҷдәӣжҢҮд»Өе’ҢеҜ№еә”зҡ„ж“ҚдҪңж•°жһ„жҲҗзҡ„пјҢиҝҷдәӣжңәеҷЁз ҒеҸҜд»ҘзӣҙжҺҘи·‘еңЁи®Ўз®—жңәдёҠпјҢд№ҹе°ұжҳҜеҸҜзӣҙжҺҘжү§иЎҢгҖӮз”ұе®ғ们жһ„жҲҗзҡ„ж–Ү件еҸ«еҒҡеҸҜжү§иЎҢж–Ү件гҖӮ
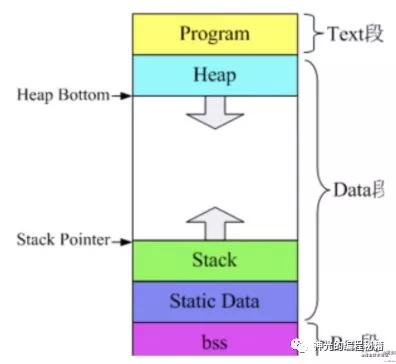
дёҚеҗҢж“ҚдҪңзі»з»ҹеҸҜжү§иЎҢж–Ү件зҡ„ж јејҸдёҚеҗҢпјҢеңЁ windows дёҠжҳҜ pe(Portable Executable) ж јејҸпјҢеңЁ linuxгҖҒunix зі»з»ҹдёҠжҳҜ elf(Executable Linkable Format) ж јејҸпјҢеңЁ mac дёҠжҳҜ mash-o ж јејҸгҖӮе®ғ们规е®ҡдәҶдёҚеҗҢзҡ„еҶ…е®№(.text жҳҜд»Јз ҒгҖҒ.data .bass зӯүжҳҜж•°жҚ®)ж”ҫеңЁж–Ү件дёӯзҡ„д»Җд№ҲдҪҚзҪ®гҖӮдҪҶе…¶дёӯзңҹжӯЈеҸҜжү§иЎҢзҡ„йғЁеҲҶиҝҳжҳҜз”ұ cpu жҸҗдҫӣзҡ„жңәеҷЁжҢҮд»Өжһ„жҲҗзҡ„гҖӮ
зј–иҜ‘еһӢиҜӯиЁҖдјҡз»ҸиҝҮзј–иҜ‘гҖҒжұҮзј–гҖҒй“ҫжҺҘзҡ„йҳ¶ж®өпјҢзј–иҜ‘жҳҜжҠҠжәҗд»Јз ҒиҪ¬жҲҗжұҮзј–иҜӯиЁҖжһ„жҲҗзҡ„дёӯй—ҙд»Јз ҒпјҢжұҮзј–жҳҜжҠҠдёӯй—ҙд»Јз ҒеҸҳжҲҗзӣ®ж Үд»Јз ҒпјҢй“ҫжҺҘдјҡжҠҠзӣ®ж Үд»Јз Ғз»„еҗҲжҲҗеҸҜжү§иЎҢж–Ү件гҖӮиҝҷдёӘеҸҜжү§иЎҢж–Ү件жҳҜеҸҜд»ҘеңЁж“ҚдҪңзі»з»ҹдёҠзӣҙжҺҘжү§иЎҢзҡ„гҖӮе°ұеӣ дёәе®ғжҳҜз”ұ cpu зҡ„жңәеҷЁжҢҮд»Өжһ„жҲҗзҡ„пјҢеҸҜд»ҘзӣҙжҺҘжҺ§еҲ¶ cpuгҖӮжүҖд»ҘеҸҜд»ҘзӣҙжҺҘ ./xxx е°ұеҸҜд»Ҙжү§иЎҢгҖӮ

и§ЈйҮҠжү§иЎҢ
зј–иҜ‘еһӢиҜӯиЁҖйғҪжҳҜз”ҹжҲҗеҸҜжү§иЎҢж–Ү件зӣҙжҺҘеңЁж“ҚдҪңзі»з»ҹдёҠжқҘжү§иЎҢзҡ„пјҢдёҚйңҖиҰҒе®үиЈ…и§ЈйҮҠеҷЁпјҢиҖҢ jsгҖҒpython зӯүи§ЈйҮҠеһӢиҜӯиЁҖзҡ„д»Јз ҒйңҖиҰҒз”Ёи§ЈйҮҠеҷЁжқҘи·‘гҖӮ
дёәд»Җд№ҲжңүдәҶи§ЈйҮҠеҷЁе°ұдёҚйңҖиҰҒз”ҹжҲҗжңәеҷЁз ҒдәҶпјҢcpu д»Қ然дёҚи®ӨиҜҶиҝҷдәӣд»Јз Ғе•Ҡ?
йӮЈжҳҜеӣ дёәи§ЈйҮҠеҷЁжҳҜйңҖиҰҒзј–иҜ‘жҲҗжңәеҷЁз Ғзҡ„пјҢcpu зҹҘйҒ“жҖҺд№Ҳжү§иЎҢи§ЈйҮҠеҷЁпјҢиҖҢи§ЈйҮҠеҷЁзҹҘйҒ“жҖҺд№Ҳжү§иЎҢжӣҙдёҠеұӮзҡ„и„ҡжң¬д»Јз ҒпјҢе°ұиҝҷж ·пјҢз”ұжңәеҷЁз Ғи§ЈйҮҠжү§иЎҢи§ЈйҮҠеҷЁпјҢеҶҚз”ұи§ЈйҮҠеҷЁи§ЈйҮҠжү§иЎҢдёҠеұӮд»Јз ҒпјҢиҝҷе°ұжҳҜи„ҡжң¬иҜӯиЁҖзҡ„еҺҹзҗҶгҖӮ еҢ…жӢ¬ jsгҖҒpython зӯүйғҪжҳҜиҝҷж ·гҖӮ
дҪҶжҳҜи§ЈйҮҠеҷЁжҜ•з«ҹеӨҡдәҶдёҖеұӮпјҢжүҖд»Ҙжңүзҡ„ж—¶еҖҷдјҡжҠҠе®ғзј–иҜ‘жҲҗжңәеҷЁз ҒжқҘзӣҙжҺҘжү§иЎҢпјҢиҝҷе°ұжҳҜ JIT зј–иҜ‘еҷЁгҖӮжҜ”еҰӮ js еј•ж“ҺдёҖиҲ¬е°ұжҳҜз”ұ parserгҖҒи§ЈйҮҠеҷЁгҖҒJIT зј–иҜ‘еҷЁгҖҒGC жһ„жҲҗпјҢеӨ§йғЁеҲҶд»Јз ҒжҳҜз”ұи§ЈйҮҠеҷЁи§ЈйҮҠжү§иЎҢзҡ„пјҢиҖҢзғӯзӮ№д»Јз Ғдјҡз»ҸиҝҮ JIT зј–иҜ‘еҷЁзј–иҜ‘жҲҗз”ұжңәеҷЁз ҒпјҢзӣҙжҺҘеңЁж“ҚдҪңзі»з»ҹдёҠжү§иЎҢд»ҘжҸҗй«ҳжҖ§иғҪгҖӮ
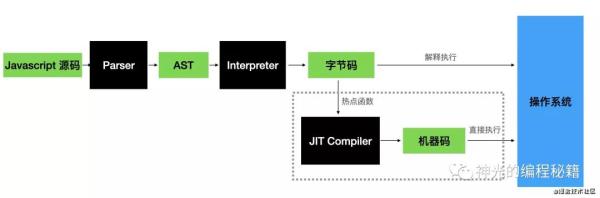
зј–иҜ‘жҲҗжңәеҷЁз ҒзӣҙжҺҘжү§иЎҢпјҢжҲ–иҖ…жҳҜд»Һжәҗз Ғи§ЈйҮҠжү§иЎҢпјҢд»Јз Ғе°ұиҝҷдёӨз§Қжү§иЎҢж–№ејҸгҖӮдёӨиҖ…еҗ„жңүеҗ„зҡ„еҘҪеӨ„пјҢзј–иҜ‘еһӢйҖҹеәҰеҝ«пјҢи§ЈйҮҠеһӢи·Ёе№іеҸ°гҖӮиҝҷе°ұжҳҜд»Јз ҒиҝҗиЎҢзҡ„еҺҹзҗҶгҖӮ
зҺӢеһ иҜҙиҝҮпјҢи®Ўз®—жңәзҡ„жң¬иҙЁе°ұжҳҜи§ЈйҮҠеҷЁгҖӮе°ұжҳҜиҜҙ cpu з”Ёз”өи·Ҝи§ЈйҮҠжңәеҷЁз ҒпјҢи§ЈйҮҠеҷЁз”ЁжңәеҷЁз Ғи§ЈйҮҠжӣҙдёҠеұӮзҡ„и„ҡжң¬д»Јз ҒпјҢжүҖд»Ҙи®Ўз®—жңәзҡ„жң¬иҙЁжҳҜи§ЈйҮҠеҷЁгҖӮ
дёәд»Җд№ҲйңҖиҰҒ debugger
жҲ‘们зҹҘйҒ“пјҢеӣҫзҒөе®ҢеӨҮзҡ„иҜӯиЁҖеҸҜд»Ҙи§ЈйҮҠд»»дҪ•еҸҜи®Ўз®—й—®йўҳпјҢжүҖд»ҘдёҚз®ЎжҳҜзј–иҜ‘еһӢиҝҳжҳҜи§ЈйҮҠеһӢйғҪиғҪеӨҹжҸҸиҝ°жүҖжңүеҸҜи®Ўз®—зҡ„дёҡеҠЎйҖ»иҫ‘гҖӮ
жҲ‘们еҲ©з”ЁдёҚеҗҢзҡ„иҜӯиЁҖжҸҸиҝ°дёҡеҠЎйҖ»иҫ‘пјҢ然еҗҺиҝҗиЎҢе®ғзңӢж•ҲжһңпјҢеҪ“д»Јз Ғзҡ„йҖ»иҫ‘жҜ”иҫғеӨҚжқӮзҡ„ж—¶еҖҷпјҢйҡҫе…ҚдјҡеҮәй”ҷпјҢжҲ‘们еёҢжңӣиғҪеӨҹдёҖжӯҘжӯҘиҝҗиЎҢжҲ–жҳҜиҝҗиЎҢеҲ°жҹҗдёӘзӮ№еҒңдёӢжқҘпјҢ然еҗҺзңӢдёҖдёӢеҪ“ж—¶зҡ„зҺҜеўғдёӯзҡ„еҸҳйҮҸпјҢжү§иЎҢжҹҗдёӘи„ҡжң¬гҖӮе®ҢжҲҗиҝҷдёӘеҠҹиғҪзҡ„е°ұжҳҜ debuggerгҖӮ
д№ҹи®ёиҝҳжңүеҫҲеӨҡеҲқзә§зЁӢеәҸе‘ҳеҸӘдјҡз”Ё console.log жү“ж—Ҙеҝ—пјҢдҪҶжҳҜж—Ҙеҝ—дёҚиғҪе®Ңе…Ёеұ•зҺ°еҪ“ж—¶зҡ„зҺҜеўғпјҢжңҖеҘҪзҡ„ж–№ејҸиҝҳжҳҜ debuggerгҖӮ
зӢјеҸ”иҜҙиҝҮпјҢжҳҜеҗҰдјҡз”Ё debugger жҳҜ nodejs ж°ҙе№ізҡ„дёҖдёӘжҳҺжҳҫзҡ„еҢәеҲҶгҖӮ
debugger зҡ„еҺҹзҗҶ
жҲ‘们зҹҘйҒ“дәҶ debugger жҳҜи°ғиҜ•зЁӢеәҸеҝ…дёҚеҸҜе°‘зҡ„пјҢйӮЈд№Ҳе®ғжҳҜжҖҺд№Ҳе®һзҺ°зҡ„е‘ў?
еҸҜжү§иЎҢж–Ү件зҡ„ debugger
е…¶е®һ cpuгҖҒж“ҚдҪңзі»з»ҹеңЁи®ҫи®Ўзҡ„ж—¶еҖҷе°ұж”ҜжҢҒдәҶ debugger зҡ„иғҪеҠӣ(еҸҜи§Ғ debugger зҡ„йҮҚиҰҒжҖ§)пјҢcpu йҮҢйқўжңү 4 дёӘеҜ„еӯҳеҷЁеҸҜд»ҘеҒҡзЎ¬дёӯж–ӯпјҢж“ҚдҪңзі»з»ҹжҸҗдҫӣдәҶзі»з»ҹи°ғз”ЁжқҘеҒҡиҪҜдёӯж–ӯгҖӮиҝҷжҳҜзј–иҜ‘еһӢиҜӯиЁҖзҡ„ debugger е®һзҺ°зҡ„еҹәзЎҖгҖӮ
дёӯж–ӯ
cpu еҸӘдјҡдёҚж–ӯзҡ„жү§иЎҢдёӢдёҖжқЎжҢҮд»ӨпјҢдҪҶзЁӢеәҸиҝҗиЎҢиҝҮзЁӢдёӯйҡҫе…ҚиҰҒеӨ„зҗҶдёҖдәӣеӨ–йғЁзҡ„ж¶ҲжҒҜпјҢжҜ”еҰӮ ioгҖҒзҪ‘з»ңгҖҒејӮеёёзӯүзӯүпјҢжүҖд»Ҙи®ҫи®ЎдәҶдёӯж–ӯзҡ„жңәеҲ¶пјҢcpu жҜҸжү§иЎҢе®ҢдёҖжқЎжҢҮд»ӨпјҢе°ұдјҡеҺ»зңӢдёӢдёӯж–ӯж Үи®°пјҢжҳҜеҗҰйңҖиҰҒдёӯж–ӯдәҶгҖӮе°ұеғҸ event loop жҜҸж¬Ў loop е®ҢйғҪиҰҒжЈҖжҹҘдёӢжҳҜеҗҰйңҖиҰҒжёІжҹ“дёҖж ·гҖӮ
INT жҢҮд»Ө
cpu ж”ҜжҢҒ INT жҢҮд»ӨжқҘи§ҰеҸ‘дёӯж–ӯпјҢдёӯж–ӯжңүзј–еҸ·пјҢдёҚеҗҢзҡ„зј–еҸ·жңүдёҚеҗҢзҡ„еӨ„зҗҶзЁӢеәҸпјҢи®°еҪ•зј–еҸ·е’Ңдёӯж–ӯеӨ„зҗҶзЁӢеәҸзҡ„иЎЁеҸ«еҒҡдёӯж–ӯеҗ‘йҮҸиЎЁгҖӮе…¶дёӯ INT 3 (3 еҸ·дёӯж–ӯ)еҸҜд»Ҙи§ҰеҸ‘ debuggerпјҢиҝҷжҳҜдёҖз§ҚзәҰе®ҡгҖӮ
йӮЈд№ҲеҸҜжү§иЎҢж–Ү件жҳҜжҖҺд№ҲеҲ©з”ЁиҝҷдёӘ 3 еҸ·дёӯж–ӯжқҘ debugger зҡ„е‘ў?е…¶е®һе°ұжҳҜиҝҗиЎҢж—¶жӣҝжҚўжү§иЎҢзҡ„еҶ…е®№пјҢdebugger зЁӢеәҸдјҡеңЁйңҖиҰҒи®ҫзҪ®ж–ӯзӮ№зҡ„дҪҚзҪ®жҠҠжҢҮд»ӨеҶ…е®№жҚўжҲҗ INT 3пјҢд№ҹе°ұжҳҜ 0xCCпјҢиҝҷе°ұж–ӯдҪҸдәҶгҖӮе°ұеҸҜд»ҘиҺ·еҸ–иҝҷж—¶еҖҷзҡ„зҺҜеўғж•°жҚ®жқҘеҒҡи°ғиҜ•гҖӮ
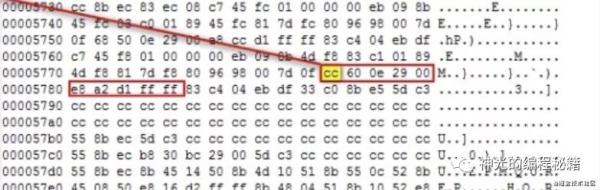
йҖҡиҝҮжңәеҷЁз ҒжӣҝжҚўжҲҗ 0xcc (INT 3)жҳҜжҠҠзЁӢеәҸж–ӯдҪҸдәҶпјҢеҸҜжҳҜжҖҺд№ҲжҒўеӨҚжү§иЎҢе‘ў?е…¶е®һд№ҹжҜ”иҫғз®ҖеҚ•пјҢжҠҠеҪ“ж—¶жӣҝжҚўзҡ„жңәеҷЁз Ғи®°еҪ•дёӢжқҘпјҢйңҖиҰҒйҮҠж”ҫж–ӯзӮ№зҡ„ж—¶еҖҷеҶҚжҚўеӣһеҺ»е°ұиЎҢдәҶгҖӮ
иҝҷе°ұжҳҜеҸҜжү§иЎҢж–Ү件зҡ„ debugger зҡ„еҺҹзҗҶдәҶпјҢжңҖз»ҲиҝҳжҳҜйқ cpu ж”ҜжҢҒзҡ„дёӯж–ӯжңәеҲ¶жқҘе®һзҺ°зҡ„гҖӮ
дёӯж–ӯеҜ„еӯҳеҷЁ
дёҠйқўиҜҙзҡ„ debugger е®һзҺ°ж–№ејҸжҳҜдҝ®ж”№еҶ…еӯҳдёӯзҡ„жңәеҷЁз Ғзҡ„ж–№ејҸпјҢдҪҶжңүзҡ„ж—¶еҖҷдҝ®ж”№дёҚдәҶд»Јз ҒпјҢжҜ”еҰӮ ROMпјҢиҝҷз§Қжғ…еҶөе°ұиҰҒйҖҡиҝҮ cpu жҸҗдҫӣзҡ„ 4 дёӘдёӯж–ӯеҜ„еӯҳеҷЁ(DR0 - DR3)жқҘеҒҡдәҶгҖӮиҝҷз§ҚеҸ«еҒҡзЎ¬дёӯж–ӯгҖӮ
жҖ»д№ӢпјҢINT 3 зҡ„иҪҜдёӯж–ӯпјҢиҝҳжңүдёӯж–ӯеҜ„еӯҳеҷЁзҡ„зЎ¬дёӯж–ӯпјҢжҳҜеҸҜжү§иЎҢж–Ү件е®һзҺ° debugger зҡ„дёӨз§Қж–№ејҸгҖӮ
и§ЈйҮҠеһӢиҜӯиЁҖзҡ„ debugger
зј–иҜ‘еһӢиҜӯиЁҖеӣ дёәзӣҙжҺҘеңЁж“ҚдҪңзі»з»ҹд№ӢдёҠжү§иЎҢпјҢжүҖд»ҘиҰҒеҲ©з”Ё cpu е’Ңж“ҚдҪңзі»з»ҹзҡ„дёӯж–ӯжңәеҲ¶е’Ңзі»з»ҹи°ғз”ЁжқҘе®һзҺ° debuggerгҖӮдҪҶжҳҜи§ЈйҮҠеһӢиҜӯиЁҖжҳҜиҮӘе·ұе®һзҺ°д»Јз Ғзҡ„и§ЈйҮҠжү§иЎҢзҡ„пјҢжүҖд»ҘдёҚйңҖиҰҒйӮЈдёҖеҘ—пјҢдҪҶжҳҜе®һзҺ°жҖқи·ҜиҝҳжҳҜдёҖж ·зҡ„пјҢе°ұжҳҜжҸ’е…ҘдёҖж®өд»Јз ҒжқҘж–ӯдҪҸпјҢж”ҜжҢҒзҺҜеўғж•°жҚ®зҡ„жҹҘзңӢе’Ңд»Јз Ғзҡ„жү§иЎҢпјҢеҪ“йҮҠж”ҫж–ӯзӮ№зҡ„ж—¶еҖҷе°ұ继з»ӯеҫҖдёӢжү§иЎҢгҖӮ
жҜ”еҰӮ javascript дёӯж”ҜжҢҒ debugger иҜӯеҸҘпјҢеҪ“и§ЈйҮҠеҷЁжү§иЎҢеҲ°иҝҷдёҖжқЎиҜӯеҸҘзҡ„ж—¶еҖҷе°ұдјҡж–ӯдҪҸгҖӮ
и§ЈйҮҠеһӢиҜӯиЁҖзҡ„ debugger зӣёеҜ№з®ҖеҚ•дёҖдәӣпјҢдёҚйңҖиҰҒдәҶи§Ј cpu зҡ„ INT 3 дёӯж–ӯгҖӮ
debugger е®ўжҲ·з«Ҝ
дёҠйқўжҲ‘们дәҶи§ЈдәҶзӣҙжҺҘжү§иЎҢе’Ңи§ЈйҮҠжү§иЎҢзҡ„д»Јз Ғзҡ„ debugger еҲҶеҲ«жҳҜжҖҺд№Ҳе®һзҺ°зҡ„гҖӮжҲ‘们зҹҘйҒ“дәҶд»Јз ҒжҳҜжҖҺд№Ҳж–ӯдҪҸзҡ„пјҢйӮЈд№Ҳж–ӯдҪҸд№ӢеҗҺе‘ў?жҖҺд№ҲжҠҠзҺҜеўғж•°жҚ®жҡҙйңІеҮәеҺ»пјҢжҖҺд№Ҳжү§иЎҢеӨ–йғЁд»Јз Ғ?
иҝҷе°ұйңҖиҰҒ debugger е®ўжҲ·з«ҜдәҶгҖӮ
жҜ”еҰӮ v8 еј•ж“ҺдјҡжҠҠи®ҫзҪ®ж–ӯзӮ№гҖҒиҺ·еҸ–зҺҜеўғдҝЎжҒҜгҖҒжү§иЎҢи„ҡжң¬зҡ„иғҪеҠӣйҖҡиҝҮ socket жҡҙйңІеҮәеҺ»пјҢsocket дј йҖ’зҡ„дҝЎжҒҜж јејҸе°ұжҳҜ v8 debug protocol гҖӮ
жҜ”еҰӮпјҡ
и®ҫзҪ®ж–ӯзӮ№пјҡ
{ "seq":117, "type":"request", "command":"setbreakpoint", "arguments":{ "type":"function", "target":"f" }еҺ»жҺүж–ӯзӮ№пјҡ
{ "seq":117, "type":"request", "command":"clearbreakpoint", "arguments": { "type":"function", "breakpoint":1 } }继з»ӯпјҡ
{ "seq":117, "type":"request", "command":"continue" }жү§иЎҢд»Јз Ғпјҡ
{ "seq":117, "type":"request", "command":"evaluate", "arguments":{ "expression":"1+2" } }ж„ҹе…ҙи¶Јзҡ„еҗҢеӯҰеҸҜд»ҘеҺ» v8 debug protocol зҡ„ж–ҮжЎЈдёӯеҺ»жҹҘзңӢе…ЁйғЁзҡ„еҚҸи®®гҖӮ
еҹәдәҺиҝҷдәӣеҚҸи®®е°ұеҸҜд»ҘжҺ§еҲ¶ v8 зҡ„ debugger дәҶпјҢжүҖжңүзҡ„иғҪеӨҹе®һзҺ° debugger зҡ„йғҪжҳҜеҜ№жҺҘдәҶиҝҷдёӘеҚҸи®®пјҢжҜ”еҰӮ chrome devtoolsгҖҒvscode debugger иҝҳжңүе…¶д»–еҗ„з§Қ ide зҡ„ debuggerгҖӮ
nodejs д»Јз Ғзҡ„и°ғиҜ•
nodejs еҸҜд»ҘйҖҡиҝҮж·»еҠ --inspect зҡ„ option жқҘеҒҡи°ғиҜ•(д№ҹеҸҜд»ҘжҳҜ --inspect-brkпјҢиҝҷдёӘдјҡеңЁйҰ–иЎҢе°ұж–ӯдҪҸ)гҖӮ
е®ғдјҡиө·дёҖдёӘ debugger зҡ„ websocket жңҚеҠЎз«ҜпјҢжҲ‘们еҸҜд»Ҙз”Ё vscode жқҘи°ғиҜ• nodejs д»Јз ҒпјҢд№ҹеҸҜд»Ҙз”Ё chrome devtools жқҘи°ғиҜ•(и§Ғ nodejs debugger ж–ҮжЎЈ)гҖӮ
вһң node --inspect test.js Debugger listening on ws://127.0.0.1:9229/db309268-623a-4abe-b19a-c4407ed8998d For help see https://nodejs.org/en/docs/inspector
еҺҹзҗҶе°ұжҳҜе®һзҺ°дәҶ v8 debug protocolгҖӮ
жҲ‘们еҰӮжһңиҮӘе·ұеҒҡи°ғиҜ•е·Ҙе…·гҖҒеҒҡ ideпјҢйӮЈе°ұиҰҒеҜ№жҺҘиҝҷдёӘеҚҸи®®гҖӮ
debugger adaptor protocol
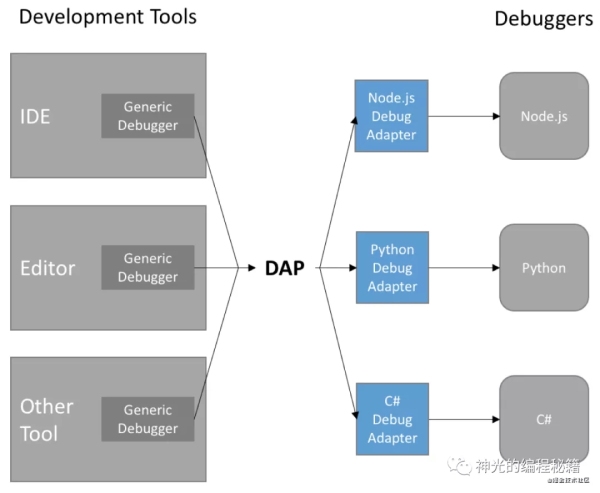
дёҠйқўд»Ӣз»Қзҡ„ v8 debug protocol еҸҜд»Ҙе®һзҺ° js д»Јз Ғзҡ„и°ғиҜ•пјҢйӮЈд№Ҳ pythonгҖҒc# зӯүиӮҜе®ҡд№ҹжңүиҮӘе·ұзҡ„и°ғиҜ•еҚҸи®®пјҢеҰӮжһңиҰҒе®һзҺ° ideпјҢйғҪиҰҒеҜ№жҺҘдёҖйҒҚеӨӘиҝҮйә»зғҰгҖӮжүҖд»ҘеҗҺжқҘеҮәзҺ°дәҶдёҖдёӘдёӯй—ҙеұӮеҚҸи®®пјҢDAP(debugger adaptor protocol)гҖӮ
debugger adaptor protocolпјҢ йЎҫеҗҚжҖқд№үпјҢе°ұжҳҜйҖӮй…Қзҡ„пјҢдёҖз«ҜйҖӮй…Қеҗ„з§Қ debugger еҚҸи®®пјҢдёҖз«ҜжҸҗдҫӣз»ҷе®ўжҲ·з«Ҝз»ҹдёҖзҡ„еҚҸи®®гҖӮиҝҷжҳҜйҖӮй…ҚеҷЁжЁЎејҸзҡ„дёҖдёӘеҫҲеҘҪзҡ„еә”з”ЁгҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒе…ідәҺвҖңJavaScriptдёӯDebuggerзҡ„еҺҹзҗҶеҲҶжһҗвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢи®©еӨ§е®¶еҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°еҗ§пјҒ





