本篇内容介绍了“Java代码是如何在机器上运行的”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
计算机能识别的是机器指令码,简称机器码。机器码是二进制的,计算机可以直接识别,但与人类的语言差别太大,不容易被人理解和记忆。后来,就诞生了各种高级语言,人们用高级语言编写程序,然后通过把程序解释或编译成机器码。
比如python,就是一种解释型语言。Python程序源码不需要编译,可以直接从源代码运行程序。Python解释器将源代码转换为字节码,然后把编译好的字节码转发到Python虚拟机(PVM)中进行执行。
而C语言就是典型的编译型语言,需要先用编译器编译成机器码,比如我们通常用gcc来编译C语言程序:
$ gcc hello.c # 编译 $ ./a.out # 执行 hello world!那Java是解释型语言还是编译型语言呢?
「Java是兼具编译型语言与解释型语言的特点的」。程序员写好Java程序后,需要先用javac编译成JVM可以使用的字节码class文件。然后JVM加载class文件,逐条解释执行。在运行过程中,部分热点代码会被即时编译器编译成机器码。
Java语言的源代码是.java为后缀的文件。当然现在有很多其它高级语言也架构在JVM上,比如groovy、kotlin等。源代码是给人看的,易于阅读、理解、维护。
源代码经过编译后得到字节码,字节码是给JVM用的,易于理解和识别。字节码是以.class为后缀,其格式是JVM的一套规划,字节码人类对照文档也是勉强能看懂的,只是相对Java代码来说要难以理解一些而已。
Java与Python不同,Python不需要编译字节码文件(当然,Python也提供了这种操作),编译是一个自动的过程,一般不会在意它的存在。而Java会先编译好字节码文件,这样JVM直接读字节码文件,可以节省加载模块的时间,提高效率。同时字节码的形式也增加了反向工程的难度,可以保护源代码(当然,也可以被反编译)。
熟悉JVM的小伙伴都知道,它有一个“类加载过程”,可以说是老八股文了,经常会被面试官问到。类加载过程其实就是指的JVM从读取一个class文件到准备好这个类,以及最后销毁的整个过程。
所以「class文件其实是以“类”为单位的,这跟java文件有一些不同」。如果我们在一个Java文件里面声明多个类,用Javac编译出来会发现有多个class文件。比如我们声明一个One.java文件:
public class One { public class OneInner {} private class OnePrivateInner {} public static class OneStaticInner {} private static class OneprivateStaticInner {} } class Two{}用Javac编译后,会出现6个class文件
➜ $ ls 'One$OneInner.class' 'One$OneStaticInner.class' One.class Two.class 'One$OnePrivateInner.class' 'One$OneprivateStaticInner.class' One.java加载和使用字节码
前面提到,JVM会加载class文件,然后加载后的Java类会被存放于方法区(Method Area)中。从指定的类的main方法作为入口开始运行。实际运行时,虚拟机会执行方法区内的代码,JVM会使用堆和栈来存储运行时数据。
每当进入一个方法,Java虚拟机会在当前线程的栈中生成一个栈帧,存放局部变量以及字节码的操作数,这个栈帧的大小是提前计算好的。

退出方法时,不管是正常返回还是异常返回,Java虚拟机均会「弹出当前线程的当前栈帧」,并将之舍弃。
Java虚拟机需要将字节码翻译成机器码,才能让机器执行。这个过程有两种形式,一种是解释执行,即逐条将字节码翻译成机器码并执行;另一种是即时编译(Just-In-Time compilation,JIT),即将「一个方法中」包含的所有字节码编译成机器码后再执行。
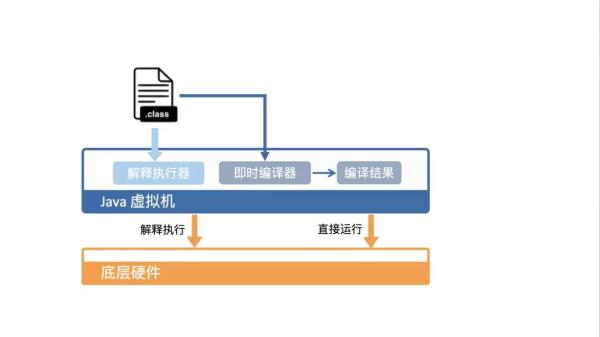
分层编译
这两种编译方式是怎么协作的呢?
HotSpot虚拟机包含多个即时编译器C1、C2和Graal。其中,Graal是一个实验性质的即时编译器,可以通过参数 -XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler启用,并且替换C2。
C1和C2各有优劣,适用于不同的场景。在Java 7以前,只能选择一种编译器。C1编译快,但生成的代码执行效率一般,常用于对于执行时间较短的,或者对启动性能有要求的程序,常用于客户端;C2编译慢,但生成的代码执行效率快,适用于对于执行时间较长的,或者对峰值性能有要求的程序,常用于服务端。实际上,C1对应的参数是client,C2对应的参数是server,也跟它们的应用场景比较匹配。
Java7引入了分层编译的概念,综合了C1的启动性能优势和C2的峰值性能优势。C1和C2编译出的机器码是不同的。C2代码的执行效率要比C1代码高出30%以上。机器码越快,需要的编译时间就越长。分层编译是一种折衷的方式,既能够满足部分不那么热的代码能够在短时间内编译完成,也能满足很热的代码能够拥有最好的优化。
热点代码
那怎么判定热点代码呢?
JVM会收集方法的运行时信息,主要包括调用次数和循环回边的次数。当「方法的调用次数和循环回边的次数的和,超过指定阈值时」,便会触发即时编译。
->
循环回边次数可以简单理解为方法内部代码的循环次数,比如方法内部有for循环或while循环。
<-
在分层编译出现前,这个阈值是由参数-XX:CompileThreshold指定的,使用C1时,该值为1500;使用C2时,该值为10000。
当启用分层编译时,JVM使用另一套阈值系统。在这套系统中,阈值的大小是动态调整的。JVM将阈值与某个系数 s 相乘。该系数与当前待编译的方法数目成正相关,与编译线程的数目成负相关。
编译线程
默认情况下编译线程的总数目是根据处理器数量来调整的。Java 虚拟机会将这些编译线程按照1:2的比例分配给 C1和C2(至少各为1个)。举个例子,对于一个四核机器来说,总的编译线程数目为3,其中包含一个C1编译线程和两个C2编译线程。
->
机器资源太少的时候,也可能各1个线程。
<-
用arthas可以看到编译线程:
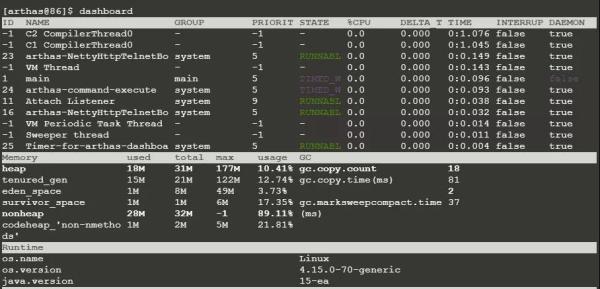
^arthas^
可以看到,它们的ID是-1,优先级也是-1。我们自己创建的线程优先级是0~10,所以编译线程的优先级会更高一些。
一句话来总结Java程序是怎么在机器上运行的呢?首先Java程序员编写Java代码,然后Java代码会被编译成class文件,多个class文件会被打包成jar包或者war包。然后JVM加载class文件,然后先解释执行为字节码。程序运行一段时间后,JVM会通过方法调用次数和循环持续判断一个方法是否为热点代码,如果是,会使用分层编译,通过编译线程编译成字节码,在机器上运行。
“Java代码是如何在机器上运行的”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/zNwvn9sYI7GfneNOHdddJw



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



