本篇文章给大家分享的是有关Linux实时补丁是否即将合并进Linux 5.3,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
Linux PREEMPT_RT 补丁终于要合并进Linux 5.3了。意味着开发了十几年的实时补丁将得以和主线Linux 协同发展。
所谓实时,就是一个特定任务的执行时间必须是确定的,可预测的,并且在任何情况下都能保证任务的时限(最大执行时间限制)。实时又分软实时和硬实时,所谓软实时,就是对任务执行时限的要求不那么严苛,即使在一些情况下不能满足时限要求,也不会对系统本身产生致命影响,例如,媒体播放系统就是软实时的,它需要系统能够在1秒钟播放24帧,但是即使在一些严重负载的情况下不能在1秒钟内处理24帧,也是可以接受的。所谓硬实时,就是对任务的执行时限的要求非常严格,无论在什么情况下,任务的执行实现必须得到绝对保证,否则将产生灾难性后果,例如,飞行器自动驾驶和导航系统就是硬实时的,它必须要求系统能在限定的时限内完成特定的任务,否则将导致重大事故,如碰撞或爆炸等。
那么,如何判断一个系统是否是实时的呢?主要有以下两个指标:
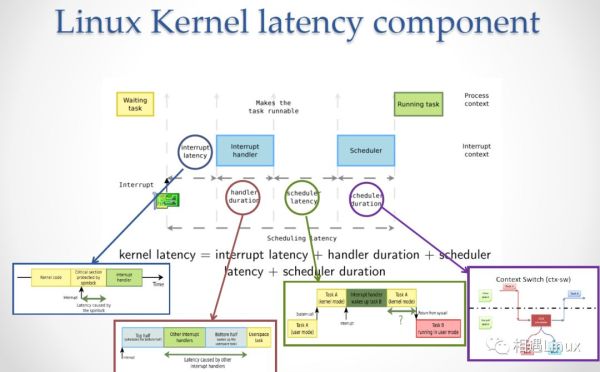
1. 中断延迟
中断延迟就是从一个外部事件发生到相应的中断处理函数的第一条指令开始执行所需要的时间。很多实时任务是靠中断驱动的,而且中断事件必须在限定的时限内处理,否则将产生灾难性后果,因此中断延迟对于实时系统来说,是一个非常重要的指标。
2. 抢占延迟
有时也称调度延迟,抢占延迟就是从一个外部事件发生到相应的处理该事件的任务的第一条命令开始执行的时间。大多数实时系统都是处理一些周期性的或非周期性的重复事件,事件产生的频度就确定了任务的执行时限,因此每次事件发生时,相应的处理任务必须及时响应处理,否则将无法满足时限。抢占延迟就反映了系统的响应及时程度。
如果以上两个指标是确定的,可预测的,那么就可以说系统是实时的。
对系统实时性的影响因素既有硬件方面的,也有软件方面的。
现代的高性能的硬件都使用了cache技术来弥补CPU和内存间的性能差距,但是cache却严重地影响着实时性,指令或数据在cache中的执行时间和指令或数据不在cache中的执行时间差距是非常巨大的,可能差几个数量级,因此为了保证执行时间的确定性和可预测性,来满足实时需要,一些系统就失效了cache或使用没有cache的CPU。
另一个硬件方面的影响因素就是虚存管理,对于多用户多任务的操作系统,它确实非常有用,它使得系统能够执行比物理内存更大的任务,而且各任务互不影响,完全有自己的独立的地址空间。但是虚存管理的缺页机制严重地影响了任务执行时间的可预测性和确定性,任务执行时使用缺页机制调入访问的指令或数据和被执行的指令和数据已经在内存中需要的执行时间的差距是非常大的。因此一些实时系统就不使用虚存技术,例如 Wind River的VxWorks。
在软件方面,影响因素包括关中断、不可抢占、一些O(n)的算法。
前面已经提到,中断延迟是衡量系统实时性的一个重要指标。关中断就导致了中断无法被响应,增加了中断延迟。
前面提到的抢占延迟也是衡量系统实时性的重要指标。如果发生实时事件时系统是不可抢占的,抢占延迟就会增加。
Linux在设计之初没有对实时性进行任何考虑,因此非实时性绝非偶然。Linus考虑的是资源共享,吞吐率最大化。但是随着Linux的快速发展,它的应用已经远远超出了Linus自己的想象。Linux的开放性已经对很多种架构的支持使得它在嵌入式系统中得到了广泛的应用,但是许多嵌入式系统的实时性要求使得Linux在嵌入式领域的应用受到了一定的障碍,因此人们要求Linux需要实时性的呼声越来越高。
Linux的开放性和低成本是实时Linux发展的优势,越来越多的研究机构和商业团体开展了实时Linux的研究与开发,其中最著名的就是FSMLab的Rtlinux和TimeSys Linux。还有一个就是Ingo's RT patch。
标准Linux有几个机制严重地影响了实时性。
1.内核不可抢占
在Linux 2.4和以前的版本,内核是不可抢占的,也就是说,如果当前任务运行在内核态,即使当前有更紧急的任务需要运行,当前任务也不能被抢占。因此那个紧急任务必须等到当前任务执行完内核态的操作返回用户态后或当前任务因需要等待某些条件满足而主动让出CPU才能被考虑执行,这很明显严重影响抢占延迟。
在Linux 2.6中,内核已经可以抢占,因而实时性得到了加强。但是内核中仍有大量的不可抢占区域, 如由自旋锁 (spinlock)保护的临界区,以及一些显式使用preempt_disable失效抢占的临界区。
2.中断关闭
Linux在一些同步操作中使用了中断关闭指令,中断关闭将增大中断延迟,降低系统的实时性。
3.自旋锁(spinlock)
自旋锁是在可抢占内核和SMP情况下对共享资源的一种同步机制,一般地一个任务对共享资源的访问是非常短暂的,如果两个任务竞争一个共享的资源时,没有得到资源的任务将自旋以等待另一个任务使用完该共享资源。这种锁机制是非常高效的,但是在保持自旋锁期间将失效抢占,这意味着抢占延迟将增加。在内核中,自旋锁的使用非常普遍,有的甚至对整个一个数组或链表的遍历过程都使用自旋锁。因此抢占延迟非常不确定。
4.中断总是最高优先级的
在Linux中,中断(包括软中断)是最高优先级的,不论在任何时刻,只要产生中断事件,内核将立即执行相应的中断处理函数以及软中断,等到所有挂起的中断和软中断处理完毕有才执行正常的任务。因此在标准的Linux系统上,实时任务根本不可能得到实时性保证。例如,假设在一个标准Linux系统上运行了一个实时任务(即使用了SCHED_FIFO调度策略),但是该系统有非常繁重的网络负载和I/O负载,那么系统可能一直处在中断处理状态而没有机会运行任何任务,这样实时任务将永远无法运行,抢占延迟将是无穷大。因此,如果这种机制不改,实时Linux将永远无法实现。
5.调度算法和调度点
即使内核是可抢占的,也不是在任何地方可以发生调度,例如在中断上下文,一个中断处理函数可能唤醒了某一高优先级进程,但是该进程并不能立即运行,因为在中断上下文不能发生调度,中断处理完了之后内核还要执行挂起的软中断,如果之前发生中断的时候是在spin_lock临界区,还有等待执行完临界区的代码,等它们全部处理完之后才有机会调度刚才唤醒的进程。
Ingo Molnar 的实时补丁是完全开源的,它采用的实时实现技术完全类似于Timesys Linux,而且中断线程化的代码是基于TimeSys Linux的中断线程化代码的。这些实时实现技术包括:中断线程化(包括IRQ和softirq)、用Mutex取代spinlock、优先级继承和死锁检测、等待队列优先级化等。
该实时实现包含了以前的VP补丁(在内核邮件列表这么称呼,即Voluntary Preemption),VP补丁由针对2.4内核的低延迟补丁(low latency patch)演进而来,它使用两种方法来实现低延迟:
一种就是锁分解,即把大循环中保持的锁分解为每一轮循环中都获得锁和释放锁,典型的代码结构示例如下:锁分解前:
spin_lock(&x_lock); for (…) { some operations; … } spin_unlock(&x_lock);锁分解后:
for (…) { spin_lock(&x_lock); some operations; … spin_unlock(&x_lock); }另一种是增加抢占点,即自愿被抢占,下面是一个鼠标驱动的例子:
未增加抢占点以前在文件driver/char/tty_io.c中的一段代码:
/* Do the write .. */ for (;;) { size_t size = count; if (size > chunk) size = chunk; ret = -EFAULT; if (copy_from_user(tty->write_buf, buf, size)) break; lock_kernel(); ret = write(tty, file, tty->write_buf, size); unlock_kernel(); if (ret <= 0) break; written += ret; buf += ret; count -= ret; if (!count) break; ret = -ERESTARTSYS; if (signal_pending(current)) break; }增加抢占点之后:
/* Do the write .. */ for (;;) { size_t size = count; if (size > chunk) size = chunk; ret = -EFAULT; if (copy_from_user(tty->write_buf, buf, size)) break; lock_kernel(); ret = write(tty, file, tty->write_buf, size); unlock_kernel(); if (ret <= 0) break; written += ret; buf += ret; count -= ret; if (!count) break; ret = -ERESTARTSYS; if (signal_pending(current)) break; cond_resched(); }语句cond_resched()将判断是否有进程需要抢占当前进程,如果是将立即发生调度,这就是增加的强占点。
为了能并入主流内核,Ingo Molnar的实时补丁也采用了非常灵活的策略,它支持四种抢占模式:
1.No Forced Preemption (Server),这种模式等同于没有使能抢占选项的标准内核,主要适用于科学计算等服务器环境。
2.Voluntary Kernel Preemption (Desktop),这种模式使能了自愿抢占,但仍然失效抢占内核选项,它通过增加抢占点缩减了抢占延迟,因此适用于一些需要较好的响应性的环境,如桌面环境,当然这种好的响应性是以牺牲一些吞吐率为代价的。
3.Preemptible Kernel (Low-Latency Desktop),这种模式既包含了自愿抢占,又使能了可抢占内核选项,因此有很好的响应延迟,实际上在一定程度上已经达到了软实时性。它主要适用于桌面和一些嵌入式系统,但是吞吐率比模式2更低。
4.Complete Preemption (Real-Time),这种模式使能了所有实时功能,因此完全能够满足软实时需求,它适用于延迟要求为100微秒或稍低的实时系统。
实现实时是以牺牲系统的吞吐率为代价的,因此实时性越好,系统吞吐率就越低。
它自2004年10月发布以来一直更新很频繁,几乎每天都有新版本发布中。
中断线程化是实现Linux实时性的一个重要步骤,在Linux标准内核中,中断是最高优先级的执行单元,不管内核当时处理什么,只要有中断事件,系统将立即响应该事件并执行相应的中断处理代码,除非当时中断关闭(即使用local_irq_disable失效了IRQ)。因此,如果系统有严重的网络或I/O负载,中断将非常频繁,实时任务将很难有机会运行,也就是说,毫无实时性可言。中断线程化之后,中断将作为内核线程运行而且赋予不同的实时优先级,实时任务可以有比中断线程更高的优先级,这样,实时任务就可以作为最高优先级的执行单元来运行,即使在严重负载下仍有实时性保证。
中断线程化的另一个重要原因是spinlock被mutex取代。中断处理代码中大量地使用了spinlock,当spinlock被mutex取代之后,中断处理代码就有可能因为得不到锁而需要被挂到等待队列上,但是只有可调度的进程才可以这么做,如果中断处理代码仍然使用原来的spinlock,则spinlock取代mutex的努力将大打折扣,因此为了满足这一要求,中断必须被线程化,包括IRQ和softirq。
在Ingo Molnar的实时补丁中,中断线程化的实现方法是:
对于IRQ,在内核初始化阶段init(该函数在内核源码树的文件init/main.c中定义)调用init_hardirqs(该函数在内核源码树的文件kernel/irq/manage.c中定义)来为每一个IRQ创建一个内核线程,IRQ号为0的中断赋予实时优先级49,IRQ号为1的赋予实时优先级48,依次类推直到25,因此任何IRQ线程的最低实时优先级为25。原来的 do_IRQ 被分解成两部分,架构相关的放在类似于arch/*/kernel/irq.c的文件中,名称仍然为do_IRQ,而架构独立的部分被放在IRQ子系统的位置kernel/irq/handle.c中,名称为__do_IRQ。当发生中断时,CPU将执行do_IRQ来处理相应的中断,do_IRQ将做了必要的架构相关的处理后调用__do_IRQ。函数__do_IRQ将判断该中断是否已经被线程化(如果中断描述符的状态字段不包含SA_NODELAY标志说明中断被线程化了),如果是将唤醒相应的处理线程,否则将直接调用handle_IRQ_event(在IRQ子系统位置的kernel/irq/handle.c文件中)来处理。对于已经线程化的情况,中断处理线程被唤醒并开始运行后,将调用do_hardirq(在源码树的IRQ子系统位置的文件kernel/irq/manage.c中定义)来处理相应的中断,该函数将判断是否有中断需要被处理(中断描述符的状态标志IRQ_INPROGRESS),如果有就调用handle_IRQ_event来处理。handle_IRQ_event将直接调用相应的中断处理句柄来完成中断处理。
如果某个中断需要被实时处理,它可以用SA_NODELAY标志来声明自己非线程化,例如:
系统的时钟中断就是,因为它被用来维护系统时间以及定时器等,所以不应当被线程化。
static struct irqaction irq0 = { timer_interrupt, SA_INTERRUPT | SA_NODELAY, CPU_MASK_NONE, "timer", NULL, NULL};这是在静态声明时指定不要线程化,也可以在调用request_irq时指定,如:
static struct irqaction irq0 = { timer_interrupt, SA_INTERRUPT | SA_NODELAY, CPU_MASK_NONE, "timer", NULL, NULL};对于softirq,标准Linux内核已经使用内核线程的方式来处理,只是Ingo Molnar的实时补丁做了修改使其易于被抢占,改进了实时性,具体的修改包括:
把ksoftirqd的优先级设置为nice值为-10,即它的优先级高于普通的用户态进程和内核态线程,但它不是实时线程,因此这样一来softirq对实时性的影响将显著减小。
在处理软中断期间,抢占是使能的,这使得实时性更进一步地增强。
在处理软中断的函数___do_softirq中,每次处理完一个待处理的软中断后,都将调用cond_resched_all(),这显著地增加了调度点数,提高了整个系统的实时性。
增加了两个函数_do_softirq和___do_softirq,其中___do_softirq就是原来的__do_softirq,只是增加了调度点。__do_softirq则是对___do_softirq的包装,_do_softirq是对do_softirq的替代,但保留do_softirq用于一些特殊需要。
spinlock是一个高效的共享资源同步机制,在SMP(对称多处理器Symmetric Multiple Proocessors)的情况下,它用于保护共享资源,如全局的数据结构或一个只能独占的硬件资源。但是spinlock保持期间将使抢占失效,用spinlock保护的区域称为临界区(Critical Section),在内核中大量地使用了spinlock,有大量的临界区存在,因此它们将严重地影响着系统的实时性。Ingo Molnar的实时补丁使用mutex来替换spinlock,它的意图是让spinlock可抢占,但是可抢占后将产生很多后续影响。
Spinlock失效抢占的目的是避免死锁。Spinlock如果可抢占了,一个spinlock的竞争者将可能抢占该spinlock的保持者来运行,但是由于得不到spinlock将自旋在那里,如果竞争者的优先级高于保持者的优先级,将形成一种死锁的局面,因为保持者无法得到运行而永远不能释放spinlock,而竞争者由于不能得到一个不可能释放的spinlock而永远自旋在那里。
由于中断处理函数也可以使用spinlock,如果它使用的spinlock已经被一个进程保持,中断处理函数将无法继续进行,从而形成死锁,这样的spinlock在使用时应当中断失效来避免这种死锁的情况发生。标准linux内核就是这么做的,中断线程化之后,中断失效就没有必要,因为遇到这种状况后,中断线程将挂在等待队列上并放弃CPU让别的线程或进程来运行。
等待队列就是解决这种死锁僵局的方法,在Ingo Molnar的实时补丁中,每个spinlock都有一个等待队列,该等待队列是按进程或线程的优先级排队的。如果一个进程或线程竞争的spinlock已经被另一个线程保持,它将把自己挂在该spinlock的优先级化的等待队列上,然后发生调度把CPU让给别的进程或线程。
需要特别注意,对于非线程化的中断,必须使用原来的spinlock,原因前面已经讲得很清楚。
原来的spinlock结构如下:
typedef struct { volatile unsigned long lock; # ifdef CONFIG_DEBUG_SPINLOCK unsigned int magic; # endif # ifdef CONFIG_PREEMPT unsigned int break_lock; # endif } spinlock_t;它非常简洁,替换成mutex之后,它的结构为:
typedef struct { struct rt_mutex lock; unsigned int break_lock; } spinlock_t;其中struct rt_mutex结构如下:
struct rt_mutex { raw_spinlock_t wait_lock; struct plist wait_list; struct task_struct *owner; int owner_prio; # ifdef CONFIG_RT_DEADLOCK_DETECT int save_state; struct list_head held_list; unsigned long acquire_eip; char *name, *file; int line; # endif };类型raw_spinlock_t就是原来的spinlock_t。在结构struct rt_mutex中的wait_list字段就是优先级化的等待队列。
原来的rwlock_t结构如下:
typedef struct { volatile unsigned long lock; # ifdef CONFIG_DEBUG_SPINLOCK unsigned magic; # endif # ifdef CONFIG_PREEMPT unsigned int break_lock; # endif } rwlock_t;被mutex化的rwlock结构如下:
typedef struct { struct rw_semaphore lock; unsigned int break_lock; } rwlock_t;其中rw_semaphore结构为:
struct rw_semaphore { struct rt_mutex lock; int read_depth; };rwlock_t和spinlock_t没有本质的不同,只是rwlock_t只能有一个写者,但可以有多个读者,因此使用了字段read_depth,其他都等同于spinlock_t。
如果必须使用原来的spinlock,可以把它声明为raw_spinlock_t,如果必须使用原来的rwlock_t,可以把它声明为raw_rwlock_t,但是对其进行锁或解锁操作时仍然使用同样的函数,静态初始化时必须分别使用RAW_SPIN_LOCK_UNLOCKED和RAW_RWLOCK_UNLOCKED。为什么不同的变量类型可以使用同样的函数操作呢?关键在于使用了gcc的内嵌函数__builtin_types_compatible_p,下面以spin_lock为例来说明其中的奥妙:
#define spin_lock(lock) PICK_OP(raw_spinlock_t, spin, _lock, lock)PICK_OP的定义为:
#define PICK_OP(type, optype, op, lock) \ do { \ if (TYPE_EQUAL((lock), type)) \ _raw_##optype##op((type *)(lock)); \ else if (TYPE_EQUAL(lock, spinlock_t)) \ _spin##op((spinlock_t *)(lock)); \ else __bad_spinlock_type(); \ } while (0)TYPE_EQUAL的定义为:
#define TYPE_EQUAL(lock, type) \ __builtin_types_compatible_p(typeof(lock), type *)gcc内嵌函数__builtin_types_compatible_p用于判断一个变量的类型是否为某指定的类型,如果是就返回1,否则返回0。
因此,如果一个spinlock的类型如果是spinlock_t,宏spin_lock的预处理结果将是:
do { if (0) _raw_spin_lock((raw_spinlock_t *)(lock)); else if (1) _spin_lock((spinlock_t *)(lock)); else __bad_spinlock_type; } while (0)如果一个spinlock的类型为raw_spinlock_t,宏spin_lock的预处理结果将是:
do { if (1) _raw_spin_lock((raw_spinlock_t *)(lock)); else if (0) _spin_lock((spinlock_t *)(lock)); else __bad_spinlock_type; } while (0)很明显,如果类型为spinlock_t,将运行函数_spin_lock,而如果类型为raw_spinlock_t,将运行函数_raw_spin_lock。
_spin_lock是新的spinlock的锁实现函数,而_raw_spin_lock就是原来的spinlock的锁实现函数。
等待队列优先级化的目的是为了更好地改善实时性,因为优先级化后,每次当spinlock保持者释放锁时总是唤醒排在最前面的优先级最高的进程或线程,而唤醒的时间复杂度为O(1)。
spinlock被mutex化后会产生优先级逆转(Priority Inversion)现象。所谓优先级逆转,就是优先级高的进程由于优先级低的进程保持了竞争资源被迫等待,而让中间优先级的进程运行,优先级逆转将导致高优先级进程的抢占延迟增大,中间优先级的进程的执行时间的不确定性导致了高优先级进程抢占延迟的不确定性,因此为了保证实时性,必须消除优先级逆转现象。
优先级继承协议(Priority Inheritance Protocol)和优先级顶棚协议(Priority Ceiling Protocol)就是专门针对优先级逆转问题提出的解决办法。
所谓优先级继承,就是spinlock的保持者将继承高优先级的竞争者进程的优先级,从而能先于中间优先级进程运行,尽可能快地释放锁,这样高优先级进程就能很快得到竞争的spinlock,使得抢占延迟更确定,更短。
所谓优先级顶棚,就是根据静态分析确定一个spinlock的可能拥有者的最高优先级,然后把spinlock的优先级顶棚设置为该确定的值,每次当进程获得该spinlock后,就将该进程的优先级设置为spinlock的优先级顶棚值。
Ingo Molnar的实时补丁实现了优先级继承协议,但没有实现优先级顶棚协议。
Spinlock被mutex化后引入的另一个问题就是死锁,典型的死锁有两种:
一种为自锁,即一个spinlock保持者试图获得它已经保持的锁,很显然,这会导致该进程无法运行而死锁。
另一种为非顺序锁而导致的,即进程 P1已经保持了spinlock LOCKA但是要获得进程P2已经保持的spinlock LOCKB,而进程P2要获得进程P1已经保持的spinlock LOCKA,这样进程P1和P2都将因为需要得到对方拥有的但永远不可能释放的spinlock而死锁。
Ingo Molnar的实时补丁对这两种情况进行了检测,一旦发生这种死锁,内核将输出死锁执行路径并panic。
Ingo Molnar的实时补丁支持的架构包括i386、x86_64、ppc和mips,基本上含盖了主流的架构,对于其他的架构,移植起来也是非常容易的。
架构移植主要涉及到以下几个方面:
1.中断线程化
中断线程化有两种做法,一种是利用IRQ子系统的代码,另一种是在架构相关的子树实现,前一种方法利用的是已有的中断线程化代码,因此移植时几乎不需要做什么工作,但是对一些架构,这种方法缺乏灵活性,尤其是一些架构中断处理比较特别时,可能会是IRQ子系统的中断线程化代码部分变的越来越丑陋,因此对于这种架构,后一种方法就有明显优势,当然在后一种方法中仍然可以拷贝IRQ子系统内的大部分线程化处理代码。
中断线程化要求一些spinlock或rwlock必须是raw_*类型的,而且一些IRQ必须是非线程化的,如时钟中断、级联中断等。这些是中断线程化的必要前提。
2.一些架构相关的代码
有一些变量定义在架构相关的子树下,如hardirq_preemption等,还有就是需要对entry.S做一些修改,因为增加了一个新的调用preempt_schedule_irq,它要求在调用之前失效中断。还有就是一些调试代码支持,那是完全架构相关的必须重新实现,如mcount。
3.架构相关的semaphore定义必须在第四种抢占模式下失效
前面已经讲过,如果使能第四种抢占模式,将使用新定义的semaphore,它是架构无关的,相应的处理代码也是架构无关的,因此原来的架构相关的定义和处理代码必须失效,这需要修改相应的.h、.c和Makefile。
4.一些spinlock必须声明为raw_*类型的
在架构相关的子树中,一些spinlock必须声明为raw_*类型的,静态初始化也必须修改为RAW_*,一些外部声名也得做相应的改动。
5.在打开第四种抢占模式或中断线程化使能之后,一些编程逻辑要求已经发生了变化。
中断线程化后,在中断处理函数中失效中断不在需要,因为如果中断处理线程在中断失效后想得到spinlock时,将可能发生上下文切换,新的实时实现认为这种状况不应当发生将输出警告信息。
原来用中断失效保护共享资源,现在完全可以用抢占失效来替代,因此不是万不得已,建议不使用中断失效。在网卡驱动的发送处理函数中不能失效中断,因此原来显式得失效中断的函数应当被替换,如:
local_irq_save应当变成为local_irq_save_nort local_irq_restore应当变成为local_irq_restore_nort
网络的核心代码将主动检测这种情况,如果中断失效了,将重新打开中断,但是将输出警告信息。
在保持了raw_spinlock之后不能在试图获得新的spinlock类型的锁,因为raw_spinlock是抢占失效的,但是新的spinlock却能够导致进程睡眠或发生抢占。
对于新的semaphore,必须要求执行down和up操作的是同一个进程,否则优先级继承和死锁检测将无法实现。而且代码本身也将操作失败。
以上就是Linux实时补丁是否即将合并进Linux 5.3,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/eVmky17T3jNznJouVa32XA



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



