这篇文章主要讲解了“Java中对象的内存布局”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Java中对象的内存布局”吧!
作为一名Java程序员,我们在日常工作中使用这款面向对象的编程语言时,做的最频繁的操作大概就是去创建一个个的对象了。对象的创建方式虽然有很多,可以通过new、反射、clone、反序列化等不同方式来创建,但最终使用时对象都要被放到内存中,那么你知道在内存中的java对象是由哪些部分组成、又是怎么存储的吗?
本文将基于代码进行实例测试,详细探讨对象在内存中的组成结构。全文目录结构如下:
对象内存结构概述
JOL 工具简介
对象头
实例数据
对齐填充字节
总结
文中代码基于 JDK 1.8.0_261,64-Bit HotSpot 运行
在介绍对象在内存中的组成结构前,我们先简要回顾一个对象的创建过程:
1、jvm将对象所在的class文件加载到方法区中
2、jvm读取main方法入口,将main方法入栈,执行创建对象代码
3、在main方法的栈内存中分配对象的引用,在堆中分配内存放入创建的对象,并将栈中的引用指向堆中的对象
所以当对象在实例化完成之后,是被存放在堆内存中的,这里的对象由3部分组成,如下图所示:
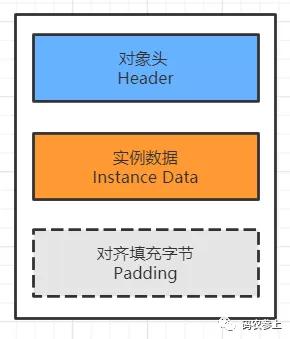
对各个组成部分的功能简要进行说明:
对象头:对象头存储的是对象在运行时状态的相关信息、指向该对象所属类的元数据的指针,如果对象是数组对象那么还会额外存储对象的数组长度
实例数据:实例数据存储的是对象的真正有效数据,也就是各个属性字段的值,如果在拥有父类的情况下,还会包含父类的字段。字段的存储顺序会受到数据类型长度、以及虚拟机的分配策略的影响
对齐填充字节:在java对象中,需要对齐填充字节的原因是,64位的jvm中对象的大小被要求向8字节对齐,因此当对象的长度不足8字节的整数倍时,需要在对象中进行填充操作。注意图中对齐填充部分使用了虚线,这是因为填充字节并不是固定存在的部分,这点在后面计算对象大小时具体进行说明
在具体开始研究对象的内存结构之前,先介绍一下我们要用到的工具,openjdk官网提供了查看对象内存布局的工具jol (java object layout),可在maven中引入坐标:
<dependency> <groupId>org.openjdk.jol</groupId> <artifactId>jol-core</artifactId> <version>0.14</version> </dependency>
在代码中使用jol提供的方法查看jvm信息:
System.out.println(VM.current().details());
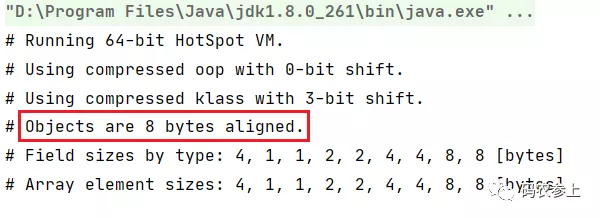
通过打印出来的信息,可以看到我们使用的是64位 jvm,并开启了指针压缩,对象默认使用8字节对齐方式。通过jol查看对象内存布局的方法,将在后面的例子中具体展示,下面开始对象内存布局的正式学习。
首先看一下对象头(Object header)的组成部分,根据普通对象和数组对象的不同,结构将会有所不同。只有当对象是数组对象才会有数组长度部分,普通对象没有该部分,如下图所示:
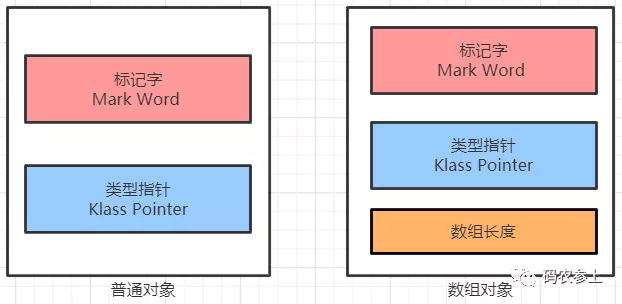
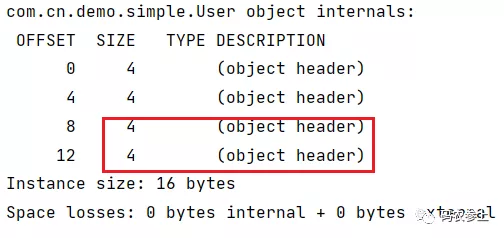
在对象头中mark word 占8字节,默认开启指针压缩的情况下klass pointer 占4字节,数组对象的数组长度占4字节。在了解了对象头的基础结构后,现在以一个不包含任何属性的空对象为例,查看一下它的内存布局,创建User类:
public class User { }使用jol查看对象头的内存布局:
public static void main(String[] args) { User user=new User(); //查看对象的内存布局 System.out.println(ClassLayout.parseInstance(user).toPrintable()); }执行代码,查看打印信息:

OFFSET:偏移地址,单位为字节
SIZE:占用内存大小,单位为字节
TYPE:Class中定义的类型
DESCRIPTION:类型描述,Obejct header 表示对象头,alignment表示对齐填充
VALUE:对应内存中存储的值
当前对象共占用16字节,因为8字节标记字加4字节的类型指针,不满足向8字节对齐,因此需要填充4个字节:
8B (mark word) + 4B (klass pointer) + 0B (instance data) + 4B (padding)
这样我们就通过直观的方式,了解了一个不包含属性的最简单的空对象,在内存中的基本组成是怎样的。在此基础上,我们来深入学习对象头中各个组成部分。
在对象头中,mark word 一共有64个bit,用于存储对象自身的运行时数据,标记对象处于以下5种状态中的某一种:
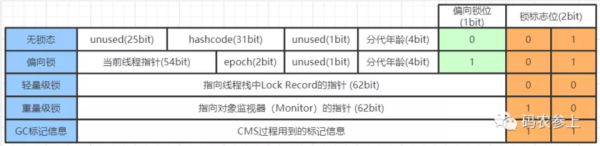
在jdk6 之前,通过synchronized关键字加锁时使用无差别的的重量级锁,重量级锁会造成线程的串行执行,并且使cpu在用户态和核心态之间频繁切换。随着对synchronized的不断优化,提出了锁升级的概念,并引入了偏向锁、轻量级锁、重量级锁。在mark word中,锁(lock)标志位占用2个bit,结合1个bit偏向锁(biased_lock)标志位,这样通过倒数的3位,就能用来标识当前对象持有的锁的状态,并判断出其余位存储的是什么信息。
基于mark word的锁升级的流程如下:
1、锁对象刚创建时,没有任何线程竞争,对象处于无锁状态。在上面打印的空对象的内存布局中,根据大小端,得到最后8位是00000001,表示处于无锁态,并且处于不可偏向状态。这是因为在jdk中偏向锁存在延迟4秒启动,也就是说在jvm启动后4秒后创建的对象才会开启偏向锁,我们通过jvm参数取消这个延迟时间:
-XX:BiasedLockingStartupDelay=0

这时最后3位为101,表示当前对象的锁没有被持有,并且处于可被偏向状态。
2、在没有线程竞争的条件下,第一个获取锁的线程通过CAS将自己的threadId写入到该对象的mark word中,若后续该线程再次获取锁,需要比较当前线程threadId和对象mark word中的threadId是否一致,如果一致那么可以直接获取,并且锁对象始终保持对该线程的偏向,也就是说偏向锁不会主动释放。
使用代码进行测试同一个线程重复获取锁的过程:
public static void main(String[] args) { User user=new User(); synchronized (user){ System.out.println(ClassLayout.parseInstance(user).toPrintable()); } System.out.println(ClassLayout.parseInstance(user).toPrintable()); synchronized (user){ System.out.println(ClassLayout.parseInstance(user).toPrintable()); } }执行结果:
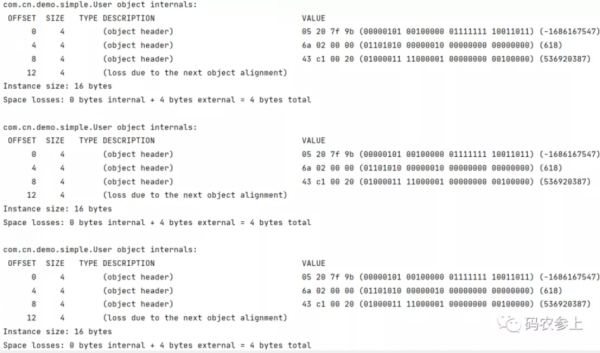
可以看到一个线程对一个对象加锁、解锁、重新获取对象的锁时,mark word都没有发生变化,偏向锁中的当前线程指针始终指向同一个线程。
3、当两个或以上线程交替获取锁,但并没有在对象上并发的获取锁时,偏向锁升级为轻量级锁。在此阶段,线程采取CAS的自旋方式尝试获取锁,避免阻塞线程造成的cpu在用户态和内核态间转换的消耗。测试代码如下:
public static void main(String[] args) throws InterruptedException { User user=new User(); synchronized (user){ System.out.println("--MAIN--:"+ClassLayout.parseInstance(user).toPrintable()); } Thread thread = new Thread(() -> { synchronized (user) { System.out.println("--THREAD--:"+ClassLayout.parseInstance(user).toPrintable()); } }); thread.start(); thread.join(); System.out.println("--END--:"+ClassLayout.parseInstance(user).toPrintable()); }先直接看一下结果:
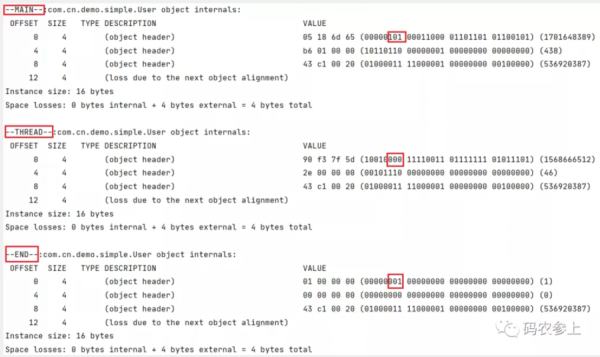
整个加锁状态的变化流程如下:
主线程首先对user对象加锁,首次加锁为101偏向锁
子线程等待主线程释放锁后,对user对象加锁,这时将偏向锁升级为00轻量级锁
轻量级锁解锁后,user对象无线程竞争,恢复为001无锁态,并且处于不可偏向状态。如果之后有线程再尝试获取user对象的锁,会直接加轻量级锁,而不是偏向锁
4、当两个或以上线程并发的在同一个对象上进行同步时,为了避免无用自旋消耗cpu,轻量级锁会升级成重量级锁。这时mark word中的指针指向的是monitor对象(也被称为管程或监视器锁)的起始地址。测试代码如下:
public static void main(String[] args) { User user = new User(); new Thread(() -> { synchronized (user) { System.out.println("--THREAD1--:" + ClassLayout.parseInstance(user).toPrintable()); try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } }).start(); new Thread(() -> { synchronized (user) { System.out.println("--THREAD2--:" + ClassLayout.parseInstance(user).toPrintable()); try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } }).start(); }查看结果:
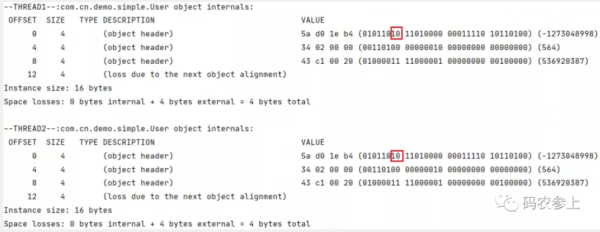
可以看到,在两个线程同时竞争user对象的锁时,会升级为10重量级锁。
对mark word 中其他重要信息进行说明:
hashcode:无锁态下的hashcode采用了延迟加载技术,在第一次调用hashCode()方法时才会计算写入。对这一过程进行验证:
public static void main(String[] args) { User user=new User(); //打印内存布局 System.out.println(ClassLayout.parseInstance(user).toPrintable()); //计算hashCode System.out.println(user.hashCode()); //再次打印内存布局 System.out.println(ClassLayout.parseInstance(user).toPrintable()); } 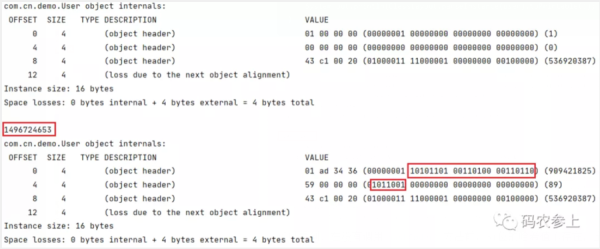
可以看到,在没有调用hashCode()方法前,31位的哈希值不存在,全部填充为0。在调用方法后,根据大小端,被填充的数据为:
1011001001101100011010010101101
将2进制转换为10进制,对应哈希值1496724653。需要注意,只有在调用没有被重写的Object.hashCode()方法或System.identityHashCode(Object)方法才会写入mark word,执行用户自定义的hashCode()方法不会被写入。
大家可能会注意到,当对象被加锁后,mark word中就没有足够空间来保存hashCode了,这时hashcode会被移动到重量级锁的Object Monitor中。
epoch:偏向锁的时间戳
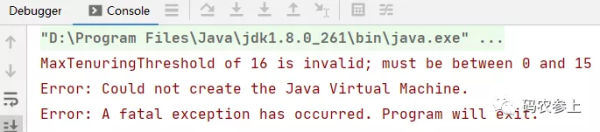
分代年龄(age):在jvm的垃圾回收过程中,每当对象经过一次Young GC,年龄都会加1,这里4位来表示分代年龄最大值为15,这也就是为什么对象的年龄超过15后会被移到老年代的原因。在启动时可以通过添加参数来改变年龄阈值:
-XX:MaxTenuringThreshold
当设置的阈值超过15时,启动时会报错:
Klass Pointer是一个指向方法区中Class信息的指针,虚拟机通过这个指针确定该对象属于哪个类的实例。在64位的JVM中,支持指针压缩功能,根据是否开启指针压缩,Klass Pointer占用的大小将会不同:
未开启指针压缩时,类型指针占用8B (64bit)
开启指针压缩情况下,类型指针占用4B (32bit)
在jdk6之后的版本中,指针压缩是被默认开启的,可通过启动参数开启或关闭该功能:
#开启指针压缩: -XX:+UseCompressedOops #关闭指针压缩: -XX:-UseCompressedOops
还是以刚才的User类为例,关闭指针压缩后再次查看对象的内存布局:

对象大小虽然还是16字节,但是组成发生了改变,8字节标记字加8字节类型指针,已经能满足对齐条件,因此不需要填充。
8B (mark word) + 8B (klass pointer) + 0B (instance data) + 0B (padding)
在了解了指针压缩的作用后,我们来看一下指针压缩是如何实现的。首先在不开启指针压缩的情况下,一个对象的内存地址使用64位表示,这时能描述的内存地址范围是:
0 ~ 2^64-1
在开启指针压缩后,使用4个字节也就是32位,可以表示2^32 个内存地址,如果这个地址是真实地址的话,由于CPU寻址的最小单位是Byte,那么就是4GB内存。这对于我们来说是远远不够的,但是之前我们说过,java中对象默认使用了8字节对齐,也就是说1个对象占用的空间必须是8字节的整数倍,这样就创造了一个条件,使jvm在定位一个对象时不需要使用真正的内存地址,而是定位到由java进行了8字节映射后的地址(可以说是一个映射地址的编号)。
映射过程也非常简单,由于使用了8字节对齐后每个对象的地址偏移量后3位必定为0,所以在存储的时候可以将后3位0抹除(转化为bit是抹除了最后24位),在此基础上再去掉最高位,就完成了指针从8字节到4字节的压缩。而在实际使用时,在压缩后的指针后加3位0,就能够实现向真实地址的映射。
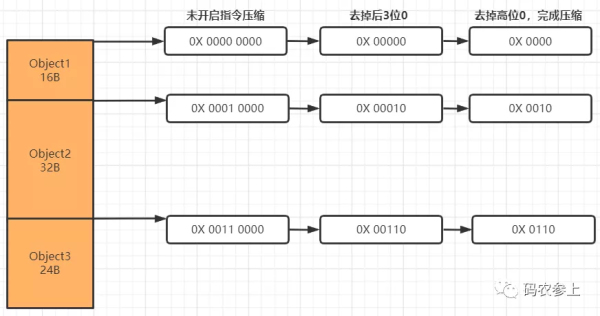
完成压缩后,现在指针的32位中的每一个bit,都可以代表8个字节,这样就相当于使原有的内存地址得到了8倍的扩容。所以在8字节对齐的情况下,32位最大能表示2^32*8=32GB内存,内存地址范围是:
0 ~ (2^32-1)*8
由于能够表示的最大内存是32GB,所以如果配置的最大的堆内存超过这个数值时,那么指针压缩将会失效。配置jvm启动参数:
-Xmx32g
查看对象内存布局:
此时,指针压缩失效,指针长度恢复到8字节。那么如果业务场景内存超过32GB怎么办呢,可以通过修改默认对齐长度进行再次扩展,我们将对齐长度修改为16字节:
-XX:ObjectAlignmentInBytes=16 -Xmx32g
可以看到指针压缩后占4字节,同时对象向16字节进行了填充对齐,按照上面的计算,这时配置最大堆内存为64GB时指针压缩才会失效。
对指针压缩做一下简单总结:
通过指针压缩,利用对齐填充的特性,通过映射方式达到了内存地址扩展的效果
指针压缩能够节省内存空间,同时提高了程序的寻址效率
堆内存设置时最好不要超过32GB,这时指针压缩将会失效,造成空间的浪费
此外,指针压缩不仅可以作用于对象头的类型指针,还可以作用于引用类型的字段指针,以及引用类型数组指针
如果当对象是一个数组对象时,那么在对象头中有一个保存数组长度的空间,占用4字节(32bit)空间。通过下面代码进行测试:
public static void main(String[] args) { User[] user=new User[2]; //查看对象的内存布局 System.out.println(ClassLayout.parseInstance(user).toPrintable()); }运行代码,结果如下:
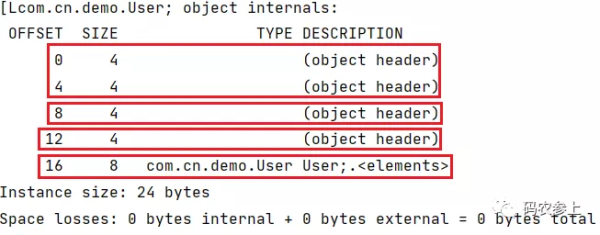
内存结构从上到下分别为:
8字节mark word
4字节klass pointer
4字节数组长度,值为2,表示数组中有两个元素
开启指针压缩后每个引用类型占4字节,数组中两个元素共占8字节
需要注意的是,在未开启指针压缩的情况下,在数组长度后会有一段对齐填充字节:
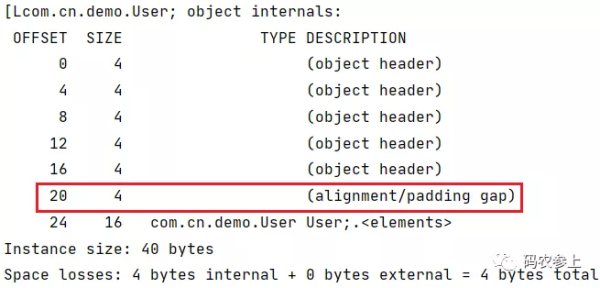
通过计算:
8B (mark word) + 8B (klass pointer) + 4B (array length) + 16B (instance data)=36B
需要向8字节进行对齐,这里选择将对齐的4字节添加在了数组长度和实例数据之间。
实例数据(Instance Data)保存的是对象真正存储的有效信息,保存了代码中定义的各种数据类型的字段内容,并且如果有继承关系存在,子类还会包含从父类继承过来的字段。
基本数据类型:
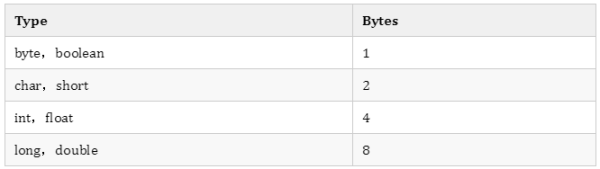
引用数据类型:
开启指针压缩情况下占8字节,开启指针压缩后占4字节。
给User类添加基本数据类型的属性字段:
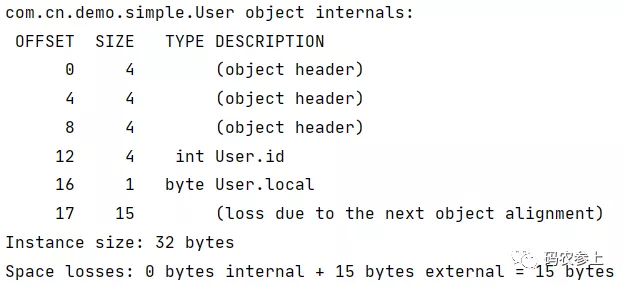
public class User { int id,age,weight; byte sex; long phone; char local; }查看内存布局:
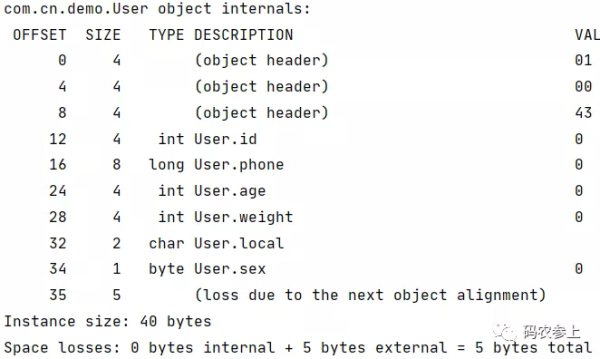
可以看到,在内存中,属性的排列顺序与在类中定义的顺序不同,这是因为jvm会采用字段重排序技术,对原始类型进行重新排序,以达到内存对齐的目的。具体规则遵循如下:
按照数据类型的长度大小,从大到小排列
具有相同长度的字段,会被分配在相邻位置
如果一个字段的长度是L个字节,那么这个字段的偏移量(OFFSET)需要对齐至nL(n为整数)
上面的前两条规则相对容易理解,这里通过举例对第3条进行解释:
因为long类型占8字节,所以它的偏移量必定是8n,再加上前面对象头占12字节,所以long类型变量的最小偏移量是16。通过打印对象内存布局可以发现,当对象头不是8字节的整数倍时(只存在8n+4字节情况),会按从大到小的顺序,使用4、2、1字节长度的属性进行补位。为了和对齐填充进行区分,可以称其为前置补位,如果在补位后仍然不满足8字节整数倍,会进行对齐填充。在存在前置补位的情况下,字段的排序会打破上面的第一条规则。
因此在上面的内存布局中,先使用4字节的int进行前置补位,再按第一条规则从大到小顺序进行排列。如果我们删除3个int类型的字段,再查看内存布局:
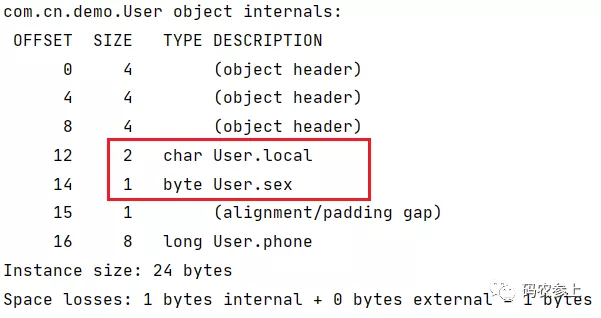
char和byte类型的变量被提到前面进行前置补位,并在long类型前进行了1字节的对齐填充。
当一个类拥有父类时,整体遵循在父类中定义的变量出现在子类中定义的变量之前的原则
public class A { int i1,i2; long l1,l2; char c1,c2; } public class B extends A{ boolean b1; double d1,d2; }查看内存结构:
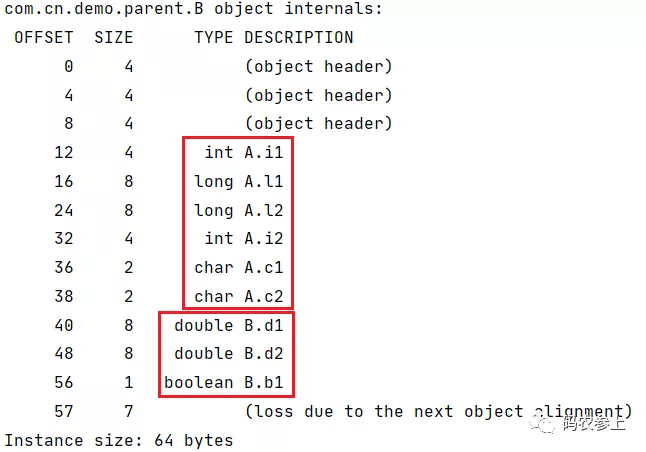
如果父类需要后置补位的情况,可能会将子类中类型长度较短的变量提前,但是整体还是遵循子类在父类之后的原则
public class A { int i1,i2; long l1; } public class B extends A { int i1,i2; long l1; }查看内存结构:
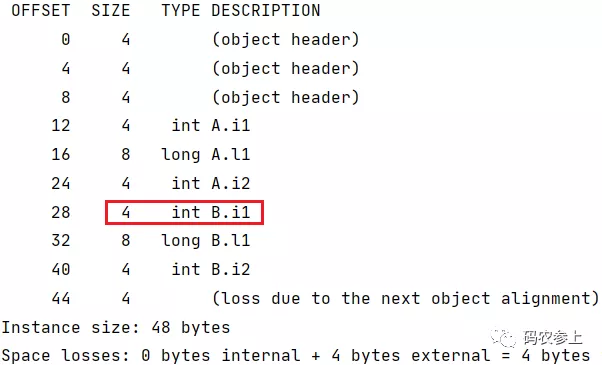
可以看到,子类中较短长度的变量被提前到父类后进行了后置补位。
父类的前置对齐填充会被子类继承
public class A { long l; } public class B extends A{ long l2; int i1; }查看内存结构:
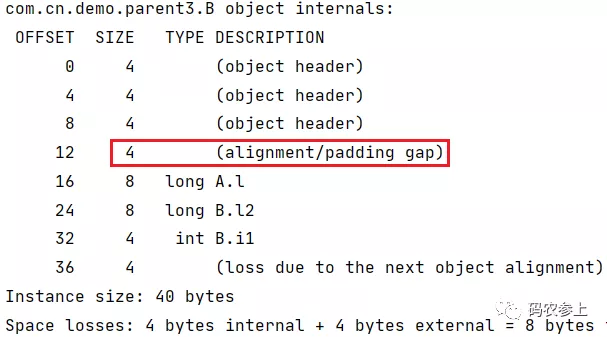
当B类没有继承A类时,正好满足8字节对齐,不需要进行对齐填充。当B类继承A类后,会继承A类的前置补位填充,因此在B类的末尾也需要对齐填充。
在上面的例子中,仅探讨了基本数据类型的排序情况,那么如果存在引用数据类型时,排序情况是怎样的呢?在User类中添加引用类型:
public class User { int id; String firstName; String lastName; int age; }查看内存布局:
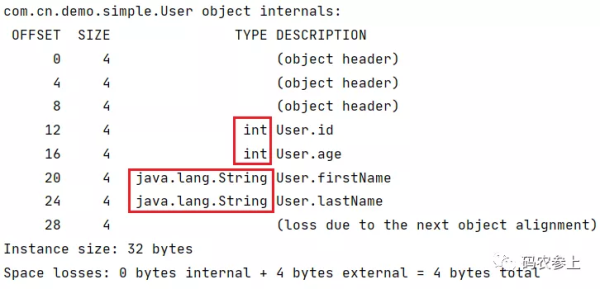
可以看到默认情况下,基本数据类型的变量排在引用数据类型前。这个顺序可以在jvm启动参数中进行修改:
-XX:FieldsAllocationStyle=0
重新运行,可以看到引用数据类型的排列顺序被放在了前面:
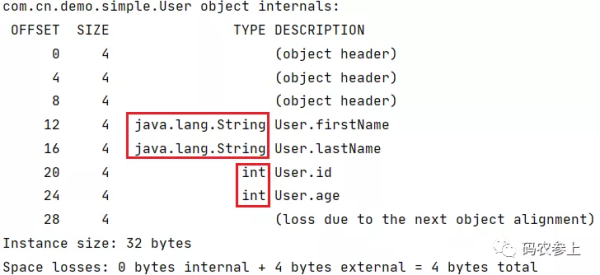
对FieldsAllocationStyle的不同取值简要说明:
0:先放入普通对象的引用指针,再放入基本数据类型变量
1:默认情况,表示先放入基本数据类型变量,再放入普通对象的引用指针
在上面的基础上,在类中加入静态变量:
public class User { int id; static byte local; }查看内存布局:
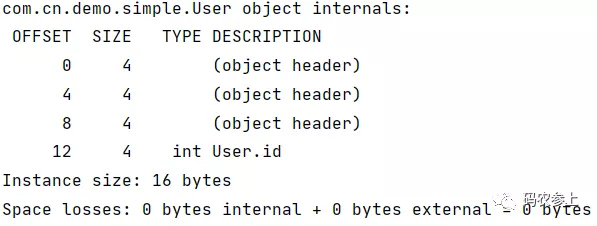
通过结果可以看到,静态变量并不在对象的内存布局中,它的大小是不计算在对象中的,因为静态变量属于类而不是属于某一个对象的。
在Hotspot的自动内存管理系统中,要求对象的起始地址必须是8字节的整数倍,也就是说对象的大小必须满足8字节的整数倍。因此如果实例数据没有对齐,那么需要进行对齐补全空缺,补全的bit位仅起占位符作用,不具有特殊含义。
在前面的例子中,我们已经对对齐填充有了充分的认识,下面再做一些补充:
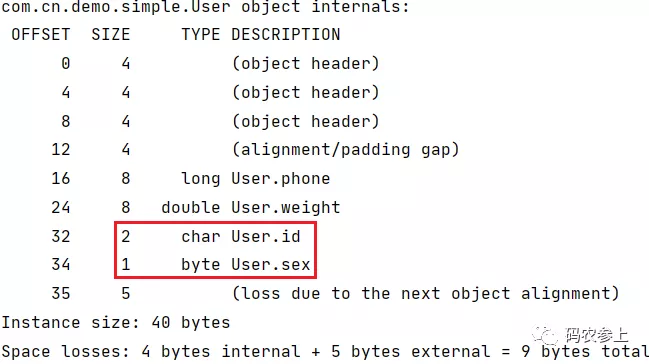
在开启指针压缩的情况下,如果类中有long/double类型的变量时,会在对象头和实例数据间形成间隙(gap),为了节省空间,会默认把较短长度的变量放在前边,这一功能可以通过jvm参数进行开启或关闭:
# 开启 -XX:+CompactFields # 关闭 -XX:-CompactFields
测试关闭情况,可以看到较短长度的变量没有前移填充:
在前面指针压缩中,我们提到了可以改变对齐宽度,这也是通过修改下面的jvm参数配置实现的:
-XX:ObjectAlignmentInBytes
默认情况下对齐宽度为8,这个值可以修改为2~256以内2的整数幂,一般情况下都以8字节对齐或16字节对齐。测试修改为16字节对齐:
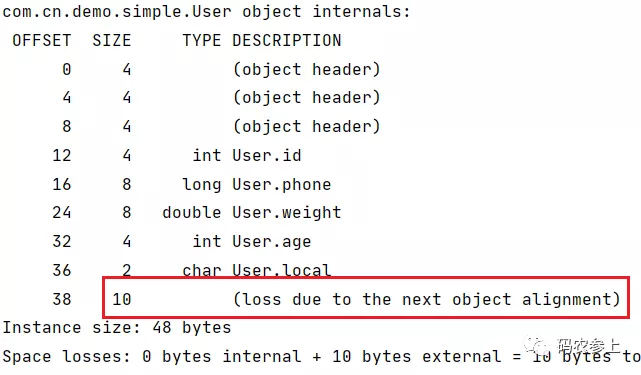
上面的例子中,在调整为16字节对齐的情况下,最后一行的属性字段只占了6字节,因此会添加10字节进行对齐填充。当然普通情况下不建议修改对齐长度参数,如果对齐宽度过长,可能会导致内存空间的浪费。
本文通过使用jol 对java对象的结构进行调试,学习了对象内存布局的基本知识。通过学习,能够帮助我们:
掌握对象内存布局,基于此基础进行jvm参数调优
了解对象头在synchronize 的锁升级过程中的作用
熟悉 jvm 中对象的寻址过程
通过计算对象大小,可以在评估业务量的基础上在项目上线前预估需要使用多少内存,防止服务器频繁gc
感谢各位的阅读,以上就是“Java中对象的内存布局”的内容了,经过本文的学习后,相信大家对Java中对象的内存布局这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





