本篇内容介绍了“什么是k8s的可观测性”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
“可观测性”这个名词其实是最近几年才从控制理论中借用的舶来概念,不过实际上,计算机科学中关于可观测性的研究内容已经有了很多年的实践积累。通常,人们会把可观测性分解为三个更具体的方向进行研究,分别是:日志收集、链路追踪和聚合度量。
在 2017 年的分布式追踪峰会(2017 Distributed Tracing Summit)结束后,彼得 · 波本(Peter Bourgon)撰写了总结文章《Metrics, Tracing, and Logging》,就系统地阐述了这三者的定义、特征,以及它们之间的关系与差异,受到了业界的广泛认可。
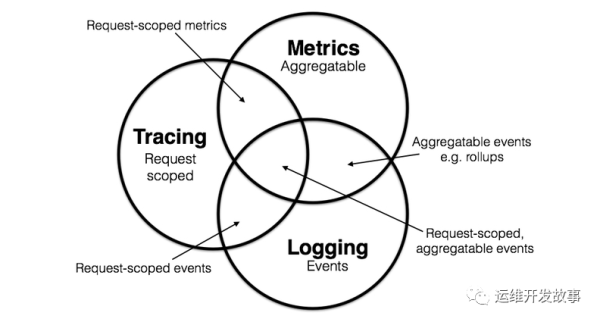
度量的主要目的是监控(Monitoring)和预警(Alert)。比如说,当某些度量指标达到了风险阈值时就触发事件,以便自动处理或者提醒管理员介入。监控数据格式标准化,做关联指标聚合,方便快速定位故障。
基础层:监控主机和底层资源,比如:CPU、内存、网络吞吐、硬盘 I/O、硬盘使用等。通信情况:这里是指主机与主机之间的网络情况。通信是互联网中最重要的基石之一,如果两台主机之间出现如网络延迟时间大、丢包率高这样的网络问题,会导致业务受阻。
中间层:VM 指标监控,指的是 JVM 监控,比如 GC 时间、线程数、FGC/YGC 耗时等信息。当然,其他语言也有其独特的统计指标信息。就是中间件层的监控,比如:Nginx、Redis、ActiveMQ、Kafka、MySQL、Tomcat 的资源消耗。
应用层:HTTP 访问的吞吐量、响应时间、返回码、性能瓶颈,还包括用户端的监控。
统一的监控告警平台:Prometheus+grafana
日志的职责是记录离散事件,通过这些记录事后分析出程序的行为,比如曾经调用过什么方法、曾经操作过哪些数据,等等。通常,打印日志被认为是程序中最简单的工作之一,你在调试问题的时候,可能也经历过这样的情景“当初这里记得打点日志就好了”,可见这就是一项举手之劳的任务。
当然,也有一部分系统是利用日志可追溯、结构化的特点,来实现相关功能的,比如我们最常见的 WAL(Write-Ahead Logging)。WAL 就是在操作之前先进行日志写入,再执行操作;如果没有执行操作,那么在下次启动时就可以通过日志中结构化的,有时间标记的信息恢复操作,其中最典型的就是 MySQL 中的 Redo log。
统一的日志数据化:在特定时间发生的事件,被以结构化的形式记录并产生的文本数据。
统一的日志分析:elk或者loki+grafana
在单体系统时代,追踪的范畴基本只局限于栈追踪(Stack Tracing)。比如说,你在调试程序的时候,在 IDE 打个断点,看到的 Call Stack 视图上的内容便是跟踪;在编写代码时,处理异常调用了 Exception::printStackTrace() 方法,它输出的堆栈信息也是追踪。
而在微服务时代,追踪就不只局限于调用栈了,一个外部请求需要内部若干服务的联动响应,这时候完整的调用轨迹就会跨越多个服务,会同时包括服务间的网络传输信息与各个服务内部的调用堆栈信息。因此,分布式系统中的追踪在国内通常被称为“全链路追踪”(后面我就直接称“链路追踪”了),许多资料中也把它叫做是“分布式追踪”(Distributed Tracing)。服务调用链跟踪。这个监控系统应该从对外的 API 开始,然后将后台的实际服务给关联起来,然后再进一步将这个服务的依赖服务关联起来,直到最后一个服务(如 MySQL 或 Redis),这样就可以把整个系统的服务全部都串连起来了。
最近几年,各种链路追踪产品层出不穷,市面上主流的工具,既有像 Datadog 这样的一揽子商业方案,也有像 AWS X-Ray 和 Google Stackdriver Trace 这样的云计算厂商产品,还有像 SkyWalking、Zipkin、Jaeger 这样来自开源社区的优秀产品。

链路追踪+统计指标(Request-scoped metrics)请求级别的统计:在链路追踪的基础上,与相关的统计数据结合,从而得知数据与数据、应用与应用之间的关系。
链路追踪+日志(Request-scoped events)请求级别的事件:这是链路中一个比较常见的组合模式。日志本身是每一条单独存在的,将链路追踪收集到的信息集成在日志中,可以让日志之间具备关联性,使其具有除了事件维度以外的另一个新的维度,上下文信息。
日志+统计指标(Aggregatable events)聚合级别的事件:这是在日志中的比较常见的组合。通过解析这部分具有统计指标的信息,我们可以获取相关的指标数据。
三者结合(Request-scoped,aggregatable events)三者结合可以理解为请求级别+聚合级别的事件,由此就形成了一个丰富的、全局的观测体系。
1.事件日志的职责是记录离散事件,通过这些记录事后分析出程序的行为;
2.追踪的主要目的是排查故障,比如分析调用链的哪一部分、哪个方法出现错误或阻塞,输入输出是否符合预期;
3.度量是指对系统中某一类信息的统计聚合,主要目的是监控和预警,当某些度量指标达到风险阈值时就触发事件,以便自动处理或者提醒管理员介入。
“什么是k8s的可观测性”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





