本篇内容介绍了“怎么理解Linux Kernel调度器”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
为什么需要调度
Linux 是一个多任务的操作系统,这就意味着它可以「同时」执行多个任务。在单核处理器上,任意时刻只能有一个进程可以执行(并发);而在多核处理器中,则允许任务并行执行。然而,不管是何种硬件类型的机器上,可能同时还有很多在内存中无法得到执行的进程,它们正在等待运行,或者正在睡眠。负责将 CPU 时间分配给进程的内核组件就是「进程调度器」。
调度器负责维护进程调度顺序,选择下一个待执行的任务。如同多数其它的现代操作系统,Linux 实现了抢占式多任务机制。也就是说,调度器可以随时决定任意进程停止运行,而让其它进程获得 CPU 资源。这种违背正在运行的进程意愿,停止其运行的行为就是所谓的「抢占」。抢占通常可以在定时器中断时发生,当中断发生时,调度器会检查是否需要切换任务,如果是,则会完成进程上下文切换。每个进程所获得的运行时间叫做进程的时间片(timeslice)。
任务通常可以区分为交互式(I/O 密集型)和非交互式(CPU 密集型)任务。交互式任务通常会重度依赖 I/O 操作(如 GUI 应用),并且通常用不完分配给它的时间片。而非交互式任务(如数学运算)则需要使用更多的 CPU 资源。它们通常会用完自己的时间片之后被抢占,并不会被 I/O 请求频繁阻塞。当然,现实中的应用程序可能同时包含上述两种分类任务。例如,文本编辑器,多数情况下,它会等待用户输入,但是在执行拼写检查时也会需要占用大量 CPU 资源。
操作系统的调度策略就需要均衡这两种类型的任务,并且保证每个任务都能得到足够的执行资源,而不会对其它任务产生明显的性能影响。 Linux 为了保证 CPU 利用率最大化,同时又能保证更快的响应时间,倾向于为非交互式任务分配更大的时间片,但是以较低的频率运行它们;而针对 I/O 密集型任务,则会在较短周期内频繁地执行。
调度有关的进程描述符
进程描述符(task_struct)中的很多字段会被调度机制直接使用。以下仅列出一些核心的部分,并在后文详细讨论。
struct task_struct { int prio, static_prio, normal_prio; unsigned int rt_priority; const struct sched_class *sched_class; struct sched_entity se; struct sched_rt_entity rt; … unsigned int policy; cpumask_t cpus_allowed; … };关于这些字段的说明如下:
prio 表示进程的优先级。进程运行时间,抢占频率都依赖于这些值。rt_priority 则用于实时(real-time)任务;
sched_class 表示进程位于哪个调度类;
sched_entity 的意义比较特殊。通常把一个线程(Linux 中的进程、任务同义词)叫作最小调度单元。但是 Linux 调度器不仅仅只能够调度单个任务,而且还可以将一组进程,甚至属于某个用户的所有进程作为整体进行调度。这就允许我们实现组调度,从而将 CPU 时间先分配到进程组,再在组内分配到单个线程。当引入这项功能后,可以大幅度提升桌面系统的交互性。比如,可以将编译任务聚集成一个组,然后进行调度,从而不会对交互性产生明显的影响。这里再次强调下,**Linux 调度器不仅仅能直接调度进程,也能对调度单元(schedulable entities)进行调度。这样的调度单元正是用 struct sched_entity 来表示的。需要说明的是,它并非一个指针,而是直接嵌套在进程描述符中的。当然,后面的谈论将聚焦在单进程调度这种简单场景。由于调度器是面向调度单元设计的,所以它会将单个进程也视为调度单元,因此会使用 sched_entity 结构体操作它们。sched_rt_entity 则是实时调度时使用的。
policy 表明任务的调度策略:通常意味着针对某些特定的进程组(如需要更长时间片,更高优先级等)应用特殊的调度决策。Linux 内核目前支持的调度策略如下:
SCHED_NORMAL:普通任务使用的调度策略;
SCHED_BATCH:不像普通任务那样被频繁抢占,可允许任务运行尽可能长的时间,从而更好地利用缓存,但是代价自然是损失交互性能。这种非常适合批量任务调度(批量的 CPU 密集型任务);
SCHED_IDLE:它要比 nice 19 的任务优先级还要低,但它并非真的空闲任务;
SCHED_FIFO 和 SCHED_RR 是软实时进程调度策略。它们是由 POSIX 标准定义的,由
cpus_allowed:用来表示任务的 CPU 亲和性。用户空间可以通过 sched_setaffinity 系统调用来设置。
优先级 Priority
进程优先级:
普通任务优先级:
所有的类 Unix 操作系统都实现了优先级调度机制。它的核心思想就是给任务设定一个值,然后通过该值决定任务的重要程度。如果任务的优先级一致,则一次重复运行它们。在 Linux 中,每一个普通任务都被赋予了一个 nice 值,它的范围是 -20 到 +19,任务默认 nice 值是 0。

nice 值越高,任务优先级越低(it's nice to others)。Linux 中可以使用 nice(int increment) 系统调用来修改当前进程的优先级。该系统调用的实现位于
实时任务优先级:
在 Linux 中,除了普通任务外,还有一类任务属于实时任务。实时任务是确保它们能够在一定时间范围内执行的任务,有两类实时任务,列举如下:
硬实时任务:会有严格的时间限制,任务必须在时限内完成。比如直升机的飞控系统,就需要及时响应驾驶员的操控,并做出预期的动作。然而,Linux 本身并不支持硬实时任务,但是有一些基于它修改的版本,如 RTLinux(它们通常被称为 RTOS)则是支持硬实时调度的。
软实时任务:软实时任务其实也会有时间限制,但不是那么严格。也就是说,任务晚一点运行任务,并不会造成不可挽回的灾难性事故。实践中,软实时任务会提供一定的时间限制保障,但是不要过度依赖这种特性。例如,VOIP 软件会使用软实时保障的协议传来送音视频信号,但是即便因为操作系统负载过高,而产生一点延迟,也不会造成很大影响。无论如何,软实时任务总会比普通任务的优先级更高。
Linux 中实时任务的优先级范围是 0~99,但是有趣的是,它和 nice 值的作用刚好相反,这里的优先级值越大,就意味着优先级越高。

类似其它的 Unix 系统,Linux 也是基于 POSIX 1b 标准定义的 「Real-time Extensions」实现实时优先级。可以通过如下的命令查看系统中的实时任务:
$ ps -eo pid, rtprio, cmd
也可通过 chrt -p pid 查看单个进程的详情。Linux 中可以通过 chrt -p prio pid 更改实时任务优先级。这里需要注意的是,如果操作的是一个系统进程(通常并不会将普通用户的进程设置为实时的),则必须有 root 权限才可以修改实时优先级。
内核视角下的进程优先级:
实时上,内核看到的任务优先级和用户看到的并不相同,在计算和管理优先级时也需要考虑很多方面。Linux 内核中使用 0~139 表示任务的优先级,并且,值越小,优先级越高(注意和用户空间的区别)。其中 0~99 保留给实时进程,100~139(映射成 nice 值就是 -20~19)保留给普通进程。

我们可以在
#define MAX_NICE 19 #define MIN_NICE -20 #define NICE_WIDTH (MAX_NICE - MIN_NICE + 1) … #define MAX_USER_RT_PRIO 100 #define MAX_RT_PRIO MAX_USER_RT_PRIO #define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH) #define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2) /* * Convert user-nice values [ -20 ... 0 ... 19 ] * to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ], * and back. */ #define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO) #define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO) /* * 'User priority' is the nice value converted to something we * can work with better when scaling various scheduler parameters, * it's a [ 0 ... 39 ] range. */ #define USER_PRIO(p) ((p)-MAX_RT_PRIO) #define TASK_USER_PRIO(p) USER_PRIO((p)->static_prio) #define MAX_USER_PRIO (USER_PRIO(MAX_PRIO))
优先级计算:
在 task_struct 中有几个字段用来表示进程优先级:
int prio, static_prio, normal_prio; unsigned int rt_priority;
static_prio 是由用户或系统设定的「静态」优先级映射成内核表示的优先级:
p->static_prio = NICE_TO_PRIO(nice_value);
normal_prio 存放的是基于 static_prio 和进程调度策略(实时或普通)决定的优先级,相同的静态优先级,在不同的调度策略下,得到的正常优先级是不同的。子进程在 fork 时,会继承父进程的 normal_prio。
prio 则是「动态优先级」,在某些场景下优先级会发生变动。一种场景就是,系统可以通过给某个任务优先级提升一段时间,从而抢占其它高优先级任务,一旦 static_prio 确定,prio 字段就可以通过下面的方式计算:
p->prio = effective_prio(p); // kernel/sched/core.c 中定义了计算方法 static int effective_prio(struct task_struct *p) { p->normal_prio = normal_prio(p); /* * If we are RT tasks or we were boosted to RT priority, * keep the priority unchanged. Otherwise, update priority * to the normal priority: */ if (!rt_prio(p->prio)) return p->normal_prio; return p->prio; } static inline int normal_prio(struct task_struct *p) { int prio; if (task_has_dl_policy(p)) prio = MAX_DL_PRIO-1; else if (task_has_rt_policy(p)) prio = MAX_RT_PRIO-1 - p->rt_priority; else prio = __normal_prio(p); return prio; } static inline int __normal_prio(struct task_struct *p) { return p->static_prio; }负载权重(Load Weights):
优先级会让一些任务比别的任务更重要,因此也会获得更多的 CPU 使用时间。nice 值和时间片的比例关系是通过负载权重(Load Weights)进行维护的,我们可以在 task_struct->se.load 中看到进程的权重,定义如下:
struct sched_entity { struct load_weight load; /* for load-balancing */ … } struct load_weight { unsigned long weight; u32 inv_weight; };为了让 nice 值的变化反映到 CPU 时间变化片上更加合理,Linux 内核中定义了一个数组,用于映射 nice 值到权重:
static const int prio_to_weight[40] = { /* -20 */ 88761, 71755, 56483, 46273, 36291, /* -15 */ 29154, 23254, 18705, 14949, 11916, /* -10 */ 9548, 7620, 6100, 4904, 3906, /* -5 */ 3121, 2501, 1991, 1586, 1277, /* 0 */ 1024, 820, 655, 526, 423, /* 5 */ 335, 272, 215, 172, 137, /* 10 */ 110, 87, 70, 56, 45, /* 15 */ 36, 29, 23, 18, 15, };来看看如何使用上面的映射表,假设有两个优先级都是 0 的任务,每个都能获得 50% 的 CPU 时间(1024 / (1024 + 1024) = 0.5)。如果突然给其中的一个任务优先级提升了 1 (nice 值 -1)。此时,一个任务应该会获得额外 10% 左右的 CPU 时间,而另一个则会减少 10% CPU 时间。来看看计算结果:1277 / (1024 + 1277) ≈ 0.55,1024 / (1024 + 1277) ≈ 0.45,二者差距刚好在 10% 左右,符合预期。完整的计算函数定义在
static void set_load_weight(struct task_struct *p) { int prio = p->static_prio - MAX_RT_PRIO; struct load_weight *load = &p->se.load; /* * SCHED_IDLE tasks get minimal weight: */ if (p->policy == SCHED_IDLE) { load->weight = scale_load(WEIGHT_IDLEPRIO); load->inv_weight = WMULT_IDLEPRIO; return; } load->weight = scale_load(prio_to_weight[prio]); load->inv_weight = prio_to_wmult[prio]; }调度类 Scheduling Classes
虽说 Linux 内核使用的 C 语言并非所谓的 OOP 语言(没有类似 C++/Java 中的 class 概念),但是我们可以在内核代码中看到一些使用 C 语言结构体 + 函数指针(Hooks)的方式来模拟面向对象的方式,抽象行为和数据。调度类也是这样实现的(此外,还有 inode_operations, super_block_operations 等),它的定义如下(位于
// 为了简单起见,隐藏了部分代码(如 SMP 相关的) struct sched_class { // 多个 sched_class 是链接在一起的 const struct sched_class *next; // 该 hook 会在任务进入可运行状态时调用。它会将调度单元(如一个任务)放到 // 队列中,同时递增 `nr_running` 变量(该变量表示运行队列中可运行的任务数) void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags); // 该 hook 会在任务不可运行时调用。它会将任务移出队列,同时递减 `nr_running` void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags); // 该 hook 可以在任务需要主动放弃 CPU 时调用,但是需要注意的是,它不会改变 // 任务的可运行状态,也就是说依然会在队列中等待下次调度。类似于先 dequeue_task, // 再 enqueue_task void (*yield_task) (struct rq *rq); // 该 hook 会在任务进入可运行状态时调用并检查是否需要抢占当前任务 void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags); // 该 hook 用来选择最适合运行的下一个任务 struct task_struct * (*pick_next_task) (struct rq *rq, struct task_struct *prev); // 该 hook 会在任务修改自身的调度类或者任务组时调用 void (*set_curr_task) (struct rq *rq); // 通常是在时钟中断时调用,可能会导致任务切换 void (*task_tick) (struct rq *rq, struct task_struct *p, int queued); // 当任务被 fork 时通知调度器 void (*task_fork) (struct task_struct *p); // 当任务挂掉时通知调度器 void (*task_dead) (struct task_struct *p); };关于调度策略的具体细节的实现有如下几个模块:
core.c 包含调度器的核心部分;
fair.c 实现了 CFS(Comple Faire Scheduler,完全公平任务调度器) 调度器,应用于普通任务;
rt.c 实现了实时调度,应用于实时任务;
idle_task.c 当没有其它可运行的任务时,会运行空闲任务。
内核是基于任务的调度策略(SCHED_*)来决定使用何种调度类实现,并会调用相应的方法。SCHED_NORMAL, SCHED_BATCH 和 SCHED_IDLE 进程会映射到 fair_sched_class (由 CFS 实现);SCHED_RR 和 SCHED_FIFO 则映射的 rt_sched_class (实时调度器)。
运行队列 runqueue
所有可运行的任务是放在运行队列中的,并且等待 CPU 运行。每个 CPU 核心都有自己的运行队列,每个任务任意时刻只能处于其中一个队列中。在多处理器机器中,会有负载均衡策略,任务就会转移到其它 CPU 上运行的可能。
运行队列数据结构定义如下(位于
// 为了简单起见,隐藏了部分代码(SMP 相关) // 这个是每个 CPU 都会有的一个任务运行队列 struct rq { // 表示当前队列中总共有多少个可运行的任务(包含所有的 sched class) unsigned int nr_running; #define CPU_LOAD_IDX_MAX 5 unsigned long cpu_load[CPU_LOAD_IDX_MAX]; // 运行队列负载记录 struct load_weight load; // 嵌套的 CFS 调度器运行队列 struct cfs_rq cfs; // 嵌套的实时任务调度器运行队列 struct rt_rq rt; // curr 指向当前正在运行的进程描述符 // idle 则指向空闲进程描述符(当没有其它可运行任务时,该任务才会启动) struct task_struct *curr, *idle; u64 clock; int cpu; }何时运行调度器?
实时上,调度函数 schedule() 会在很多场景下被调用。有的是直接调用,有的则是隐式调用(通过设置 TIF_NEED_RESCHED 来提示操作系统尽快运行调度函数)。以下三个调度时机值得关注下:时钟中断发生时,会调用 scheduler_tick() 函数,该函数会更新一些和调度有关的数据统计,并触发调度类的周期调度方法,从而间接地进行调度。以 2.6.39 源码为例,可能的调用链路如下:
scheduler_tick └── task_tick └── entity_tick └── check_preempt_tick └── resched_task └── set_tsk_need_resched
当前正在运行的任务进入睡眠状态。在这种情况下,任务会主动释放 CPU。通常情况下,该任务会因为等待指定的事件而睡眠,它可以将自己添加到等待队列,并启动循环检查期望的条件是否满足。在进入睡眠前,任务可以将自己的状态设置为 TASK_INTERRUPTABLE(除了任务要等待的事件可唤醒外,也可以被信号唤醒)或者 TASK_UNINTERRUPTABLE(自然是不会理会信号咯),然后调用 schedule() 选择下一个任务运行。
Linux 调度器
早期版本:
Linux 0.0.1 版本就已经有了一个简单的调度器,当然并非适合拥有特别多处理器的系统。该调度器只维护了一个全局的进程队列,每次都需要遍历该队列来寻找新的进程执行,而且对任务数量还有严格限制(NR_TASKS 在最初的版本中只有 32)。下面来看看这个调度器是如何实现的吧:
// 'schedule()' is the scheduler function. // This is GOOD CODE! There probably won't be any reason to change // this, as it should work well in all circumstances (ie gives // IO-bound processes good response etc)... void schedule(void) { int i, next, c; struct task_struct **p; // 遍历所有任务,如果有信号,则需要唤醒 `TASK_INTERRUPTABLE` 的任务 for (p = &LAST_TASK; p > &FIRST_TASK; --p) if (*p) { if ((*p)->alarm && (*p)->alarm < jiffies) { (*p)->signal |= (1 << (SIGALRM - 1)); (*p)->alarm = 0; } if ((*p)->signal && (*p)->state == TASK_INTERRUPTIBLE) (*p)->state = TASK_RUNNING; } while (1) { c = -1; next = 0; i = NR_TASKS; p = &task[NR_TASKS]; // 遍历所有任务,找到时间片最长的那个 while (--i) { if (!*--p) continue; if ((*p)->state == TASK_RUNNING && (*p)->counter > c) c = (*p)->counter, next = i; } if (c) break; // 遍历任务,重新设值时间片 for (p = &LAST_TASK; p > &FIRST_TASK; --p) if (*p) (*p)->counter = ((*p)->counter >> 1) + (*p)->priority; } // 切换到下一个需要执行的任务 switch_to(next); }O(n):
2.4 版本的 Linux 内核使用的调度算法非常简单和直接,由于每次在寻找下一个任务时需要遍历系统中所有的任务(链表),因此被称为 O(n) 调度器(时间复杂度)。
当然,该调度器要比 0.01 版本内核中的调度算法稍微复杂点,它引入了 epoch 概念。也就是将时间分成纪元(epochs),也就是每个进程的生命周期。理论上来说,每个纪元结束,每个进程都应该运行过一次了,而且通常用光了它当前的时间片。但实际上,有些任务并没有完全用完时间片,那么它剩余时间片的一半将会和新的时间片相加,从而在下一个纪元运行更长的时间。
我们来看下 schedule() 算法的核心源码:
// schedule() 算法会遍历所有的任务(O(N)),并且计算出每个任务的 // goodness 值,且挑选出「最好」的任务来运行。 // 以下是部分核心源码,主要是了解下它的思路。 asmlinkage void schedule(void) { // 任务(进程)描述符: // 1. prev: 当前正在运行的任务 // 2. next: 下一个将运行的任务 // 3. p: 当前正在遍历的任务 struct task_struct *prev, *next, *p; int this_cpu, c; // c 表示权重值 repeat_schedule: // 默认选中的任务 next = idle_task(this_cpu); c = -1000; list_for_each(tmp, &runqueue_head) { p = list_entry(tmp, struct task_struct, run_list); if (can_schedule(p, this_cpu)) { int weight = goodness(p, this_cpu, prev->active_mm); if (weight > c) c = weight, next = p; } } }源码中的 goodness() 函数会计算出一个权重值,它的算法基本思想就是基于进程所剩余的时钟节拍数(时间片),再加上基于进程优先级的权重值。返回值如下:
-1000 表示不要选择该进程运行
0 表示时间片用完了,需要重新计算 counters(可能会被选中运行)
正整数:表示 goodness 值(越大越好)
+1000 表示实时进程,接下来就要选择它运行
最后,针对 O(n) 调度器做下总结:算法实现非常简单,但是不高效(任务越多,遍历耗费时间越久)
没有很好的扩展性,多核处理器怎么办?
对于实时任务调度支持较弱(无论如何作为优先级高的实时任务都需要在遍历完列表后才可以知道)
O(1):
Ingo Molnár 大佬在 2.6 版本的内核中加入了全新的调度算法,它能够在常数时间内调度任务,因此被称为 O(1) 调度器。我们来看看它引入的一些新特性:
全局优先级单位,范围是 0~139,数值越低,优先级越高
将任务拆分成实时(099)和正常(100139)两部分。更高优先级任务获得更多时间片
即刻抢占(early preemption)。当任务状态变成 TASK_RUNNING 时,内核会检查其优先级是否比当前运行的任务优先级更高,如果是的话,则抢占当前正在运行的任务,切换到该任务
实时任务使用静态优先级
普通任务使用使用动态优先级。任务优先级会在其使用完自己的时间片后重新计算,内核会考虑它过去的行为,决定它的交互性等级。交互型任务更容易得到调度
O(n) 的调度器会在每个纪元结束后(所有任务的时间片都使用过),才会重新计算任务优先级。而 O(1) 则是在每个任务时间片配额用完后就重新计算优先级。O(1) 调度器为每个 CPU 维护了两个队列,即 active 和 expired。active 队列存放的是时间片尚未用完的任务,而 expired 则是时间片已经耗尽的任务。当一个任务的时间片用完后,就会被转到 expired 队列,而且会重新计算它的优先级。当 active 队列任务全部转移到 expired 队列后,会交换二者(让 active 指向 expired 队列,expired 指向 active 队列)。可以看到,优先级的计算,队列切换都和任务数量多寡无关,能够在 O(1) 时间复杂度下完成。
在先前介绍的调度算法中,如果想要取一个优先级最高的任务,还需要遍历整个任务链表才可以。而 O(1) 调度器则很特别,它为每种优先级提供了一个任务链表。所有的可运行任务会被分散在不同优先级队应的链表中。
接下来看看全新的 runqueue 是怎么定义的吧:
struct runqueue { unsigned long nr_running; /* 可运行的任务总数(某个 CPU) */ struct prio_array *active; /* 指向 active 的队列的指针 */ struct prio_array *expired; /* 指向 expired 的队列的指针 */ struct prio_array arrays[2]; /* 实际存放不同优先级对应的任务链表 */ }通过下面的图可以直观感受下任务队列:
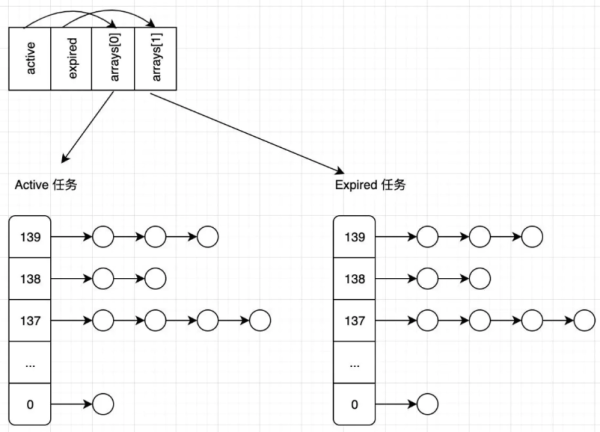
接下来看看 prio_array 是怎么定义的:
struct prio_array { int nr_active; /* 列表中的任务总数 */ unsigned long bitmap[BITMAP_SIZE]; /* 位图表示对应优先级链表是否有任务存在 */ struct list_head queue[MAX_PRIO]; /* 任务队列(每种优先级对应一个双向链表) */ };可以看到,在 prio_array 中存在一个位图,它是用来标记每个 priority 对应的任务链表是否存在任务的。接下来看看为何 O(1) 调度器可以在常数时间找到需要运行的任务:
常数时间确定优先级:首先会在位图中查找到第一个设置为 1 的位(总共有 140 bits,从第一个 bit 开始搜索,这样可以保证高优先级的任务先得到机会运行),如果找到了就可以确定哪个优先级有任务,假设找到后的值为 priority;
常数时间获得下一个任务:在 queue[priority] 对应的任务链表中提取第一个任务来执行(多个任务会轮转执行)。
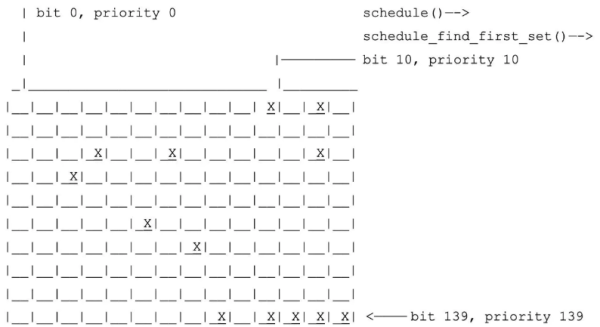
好了,是时候总结下 O(1) 调度器的优缺点了:设计上要比 O(n) 调度器更加复杂精妙;
相对来说扩展性更好,性能更优,在任务切换上的开销更小;
用来标记任务是否为交互类型的算法还是过于复杂,且容易出错。
CFS:单核调度
:CFS 的全称是 Complete Fair Scheduler,也就是完全公平调度器。它实现了一个基于权重的公平队列算法,从而将 CPU 时间分配给多个任务(每个任务的权重和它的 nice 值有关,nice 值越低,权重值越高)。每个任务都有一个关联的虚拟运行时间 vruntime,它表示一个任务所使用的 CPU 时间除以其优先级得到的值。相同优先级和相同 vruntime 的两个任务实际运行的时间也是相同的,这就意味着 CPU 资源是由它们均分了。为了保证所有任务能够公平推进,每当需要抢占当前任务时,CFS 总会挑选出 vruntime 最小的那个任务运行。
内核版本在 2.6.38 之前,每个线程(任务)会被当成独立的调度单元,并且和系统中其它线程共享资源,这就意味着一个多线程的应用会比单线程的应用获得更多的资源。之后,CFS 不断改进,目前已经支持将一个应用中的线程打包到 cgroup 结构中,cgroup 的 vruntime 是其中所有线程的 vuntime 之和。然后 CFS 就可以将它的算法应用于cgroup 之间,从而保证公平性。当某个 cgroup 被选中后,其中拥有最小 vruntime 的线程会被执行,从而保证 cgroup 中的线程之间的公平性。cgroup 还可以嵌套,例如 systemd 会自动配置 cgroup 来保证不同用户之间的公平性,然后在用户运行的多个应用之间维持公平性。
CFS 通过在一定时间内运行调度所有的线程来避免饥饿问题。当运行的 线程数在 8 个及以下时,默认的时间周期是 48ms;而当多于 8 个线程时,时间周期就会随着线程数量而增加(6ms * 线程数,之所以选择 6ms,是为了避免频繁抢占,导致上下文切换频繁切换的开销)。由于 CFS 总是会挑选 vruntime 最小的线程执行,它就需要避免某个线程的 vruntime 太小,以至于其它线程需要等待很久才能得到调度(会有饥饿问题)。所以在实践中,CFS 会保证所有线程之间的 vruntime 之差低于抢占时间(6ms),它是通过如下两点来保证的:
当线程创建时,它的 vruntime 值等于运行队列中等待执行线程的最大 vruntime;
当线程从睡眠中唤醒时,它的 vruntime 值会被更新为大于或等于所有待调度线程中最小的 vruntime。使用最小 vruntime 还可以保证频繁睡眠的线程优先被调度,这对于桌面系统非常适合,它会减少交互应用的响应延迟。
CFS 还引入了启发式调度思想来改善高速缓存利用率。例如,当线程被唤醒时,它会检查该线程的 vruntime 和正在运行的线程 vruntime 之差是否非常显著(临界值是 1ms),如果不是的话,则不会抢占当前正在运行的任务。但是这种做法还是以牺牲调度延迟为代价的,算是一种权衡吧。
多核负载均衡:
在多核环境中,Linux CFS 会将工作(work)分摊到多个处理器核心中执行。但是这不等同于将线程均分到多个处理器。比如,一个 CPU 密集型的线程和 10 个频繁睡眠的线程可能分别在两个核上执行,其中一个专门执行 CPU 密集型线程;而另一个则处理那 10 个频繁睡眠的线程。
为了多个处理器上的工作量均衡,CFS 使用了 load 指标来衡量线程和处理器的负载情况。线程的负载和线程的 CPU 平均使用率相关:经常睡眠的线程负载要低于不睡眠的线程负载。类似 vruntime,线程的负载也是线程的优先级加权得到的。而处理器的负载是在该处理器上可运行线程的负载之和。CFS 会尝试均衡处理器的负载。
CFS 会在线程创建和唤醒时关注处理器的负载情况,调度器首先要决定将任务放在哪个处理器的运行队列中。这里也会涉及到启发式思想,比如,如果 CFS 检查到生产者-消费者模型,那么它会将消费者线程尽可能地分散到机器的多个处理器上,因为多数核心都适合处理唤醒的线程。
负载均衡还会周期性发生,每隔 4ms,每个处理器都会尝试从其它处理器偷取一些工作。当然,这种 work-stealing 均衡方法还会考虑机器的拓扑结构:处理器会尝试从距离它们「更近」的其它处理器上尝试窃取工作,而非距离「更远」的处理器(如远程 NUMA 节点)。当处理器决定要从其它处理器窃取任务时,它会尝试在二者之间均衡负载,并且会窃取多达 32 个线程。此外,当处理器进入空闲状态时,它也会立刻调用负载均衡器。
在大型的 NUMA 机器上,CFS 并不会粗暴地比较所有 CPU 的负载,而是以分层的方式进行负载均衡。以一台有两个 NUMA 节点的机器为例,CFS 会先在 NUMA 节点内部的处理器之间进行负载均衡,然后比较 NUMA 节点之间的负载(通过节点内部处理器负载计算得到),再决定要不要在两个节点之间进行负载均衡。如果 NUMA 节点之间的负载差距在 25% 以内,则不会进行负载均衡。总结来说,如果两个处理器(或处理器组)之间的距离越远,那么只有在不平衡性差距越大的情况下才会考虑负载均衡。
运行队列:
CFS 引入了红黑树(本质上是一棵半平衡二叉树,对于插入和查找都有 O(log(N)) 的时间复杂度)来维护运行队列,树的节点值是调度单元的 vruntime,拥有最小 vruntime 的节点位于树的最左下边。
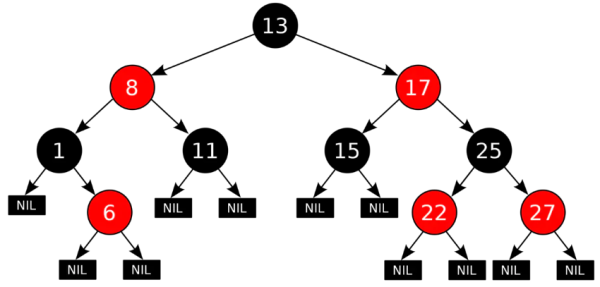
接下来看看 cfs_rq 数据结构的定义(位于 <kernel/sched/sched.h>
struct cfs_rq { // 所有任务的累计权重值 struct load_weight load; // 表示该队列中有多少个可运行的任务 unsigned int nr_running; // 运行队列中最小的 vruntime u64 min_vruntime; // 红黑树的根节点,指向运行任务队列 struct rb_root tasks_timeline; // 下一个即将被调度的任务 struct rb_node *rb_leftmost; // 指向当前正在运行的调度单元 struct sched_entity *curr; }CFS 算法实际应用于调度单元(这是一个更通用的抽象,可以是线程、cgroups 等),调度单元数据结构定义如下(位于
struct sched_entity { // 表示调度单元的负载权重(比如该调度单元是一个组,则该值就是该组下所有线程的负载权重的组合) struct load_weight load; /* for load-balancing */ // 表示红黑树的节点 struct rb_node run_node; // 表示当前调度单元是否位于运行队列 unsigned int on_rq; // 开始执行时间 u64 exec_start; // 总共运行的时间,该值是通过 `update_curr()` 更新的。 u64 sum_exec_runtime; // 基于虚拟时钟计算出该调度单元已运行的时间 u64 vruntime; // 用于记录之前运行的时间之和 u64 prev_sum_exec_runtime; };虚拟时钟:
前面提到的 vruntime 究竟是什么呢?为什么叫作虚拟运行时间呢?接下来就要揭开它的神秘面纱。为了更好地实现公平性,CFS 使用了虚拟时钟来测量一个等待的调度单元在一个完全公平的处理器上允许执行的时间。然而,虚拟时钟并没有真实的实现,它只是一个抽象概念。
我们可以基于真实时间和任务的负载权重来计算出虚拟运行时间,该算法是在 update_cur() 函数中实现的,它会更新调度单元的时间记账信息,以及 CFS 运行队列的 min_vruntime(完整定义位于
static void update_curr(struct cfs_rq *cfs_rq) { struct sched_entity *curr = cfs_rq->curr; u64 now = rq_clock_task(rq_of(cfs_rq)); u64 delta_exec; if (unlikely(!curr)) return; // 计算出调度单元开始执行时间和当前之间的差值,即真实运行时间 delta_exec = now - curr->exec_start; curr->vruntime += calc_delta_fair(delta_exec, curr); update_min_vruntime(cfs_rq); } static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se) { // 如果任务的优先级是默认的优先级(内部 nice 值是 120),那么虚拟运行时间 // 就是真实运行时间。否则,会基于 `__calc_delta` 计算出虚拟运行时间。 if (unlikely(se->load.weight != NICE_0_LOAD)) // 该计算过程基本等同于: // delta = delta_exec * NICE_0_LOAD / cur->load.weight; delta = __calc_delta(delta, NICE_0_LOAD, &se->load); return delta; } static void update_min_vruntime(struct cfs_rq *cfs_rq) { u64 vruntime = cfs_rq->min_vruntime; if (cfs_rq->curr) // 如果此时有任务在运行,就更新最小运行时间为当前任务的 vruntime vruntime = cfs_rq->curr->vruntime; if (cfs_rq->rb_leftmost) { // 获得下一个要运行的调度单元 struct sched_entity *se = rb_entry(cfs_rq->rb_leftmost, struct sched_entity, run_node); if (!cfs_rq->curr) vruntime = se->vruntime; else // 保证 min_vruntime 是二者之间较小的那个值 vruntime = min_vruntime(vruntime, se->vruntime); } // 这里之所以去二者之间的最大值,是为了保证 min_vruntime 能够单调增长 // 可以想想为什么需要这样做? cfs_rq->min_vruntime = max_vruntime(cfs_rq->min_vruntime, vruntime); }最后,来总结下使用虚拟时钟的意义:当任务运行时,它的虚拟时间总是会增加,从而保证它会被移动到红黑树的右侧;
对于高优先级的任务,虚拟时钟的节拍更慢,从而让它移动到红黑树右侧的速度就越慢,因此它们被再次调度的机会就更大些。
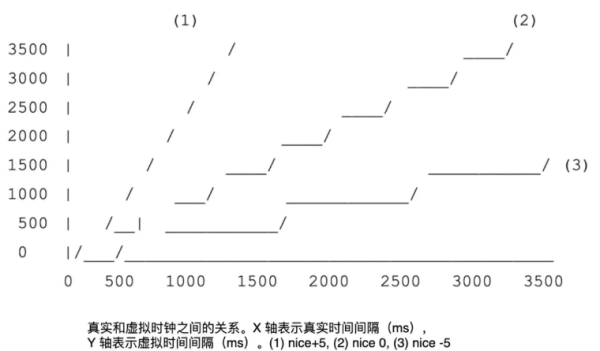
选择下一个任务:
CFS 可以在红黑树中一直找到最左(leftmost)边的节点作为下一个运行的任务。但是真正实现 __pick_first_entity() 的函数其实并没有真正地执行查找(虽然可以在 O(log(N)) 时间内找到),我们可以看下它的定义(完整定义位于
struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq) { // 其实这里取的是缓存的 leftmost 节点 // 所以执行就会更快了 struct rb_node *left = cfs_rq->rb_leftmost; if (!left) return NULL; return rb_entry(left, struct sched_entity, run_node); }实时调度器:
Linux 实时任务调度器实现位于 <kernel/sched/rt.c,对于系统而言,实时任务属于贵客,一旦存在实时任务需要调度,那就应当尽可能及时地为它们服务。对于实时任务而言,有两种调度策略存在:
SCHED_FIFO: 这个其实就是一个先到先服务的调度算法。这类任务没有时间片限制,它们会一直运行直到阻塞或者主动放弃 CPU,亦或者被更高优先级的实时任务抢占。该类任务总会抢占 SCHED_NORMAL 任务。如果多个任务具有相同的优先级,那它们会以轮询的方式调度(也就是当一个任务完成后,会被放到队列尾部等待下次执行);
SCHED_RR: 这种策略类似于 SCHED_FIFO,只是多了时间片限制。相同优先级的任务会以轮询的方式被调度,每个运行的任务都会一直运行,直到其用光自己的时间片,或者被更高优先级的任务抢占。当任务的时间片用光后,它会重新补充能量,并被加入到队列尾部。默认的时间片是 100ms,可以在 <include/linux/sched/rt.h> 找到其定义。
实时任务的优先级是静态的,不会像之前提到的算法,会重新计算任务优先级。用户可以通过 chrt 命令更改任务优先级。
实现细节:
实时任务有自己的调度单元数据结构(位于
struct sched_rt_entity { struct list_head run_list; unsigned long timeout; unsigned long watchdog_stamp; unsigned int time_slice; struct sched_rt_entity *back; struct sched_rt_entity *parent; /* rq on which this entity is (to be) queued: */ struct rt_rq *rt_rq; };SCHED_FIFO 的时间片是 0,可以在
int sched_rr_timeslice = RR_TIMESLICE; static unsigned int get_rr_interval_rt(struct rq *rq, struct task_struct *task) { if (task->policy == SCHED_RR) return sched_rr_timeslice; else return 0; }而关于运行队列的定义如下:
/* Real-Time classes' related field in a runqueue: */ struct rt_rq { // 所有相同优先级的实时任务都保存在 `active.queue[prio]` 链表中 struct rt_prio_array active; unsigned int rt_nr_running; struct rq *rq; /* main runqueue */ }; /* * This is the priority-queue data structure of the RT scheduling class: */ struct rt_prio_array { /* include 1 bit for delimiter */ // 类似 O(1) 调度器,使用位图来标记对应优先级的链表是否为空 DECLARE_BITMAP(bitmap, MAX_RT_PRIO + 1); struct list_head queue[MAX_RT_PRIO]; };类似于 CFS 中的 update_curr() 函数,update_curr_rt() 函数用来跟踪实时任务的 CPU 占用情况,收集一些统计信息,更新时间片等,但这里使用的是真实时间,而没有虚拟时间的概念。完整定义可以参考 kernel/sched/rt.c。
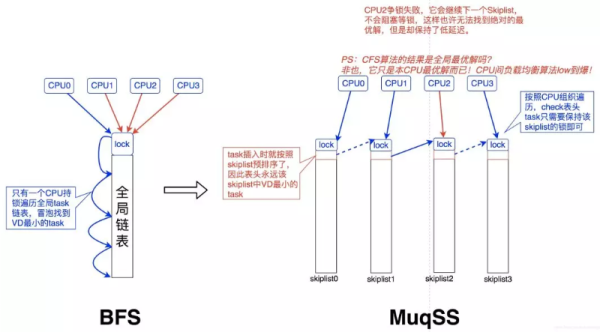
BFS & MuqSS调度器:
总体来说,BFS 是一个适用于桌面或移动设备的调度器,设计地比较简洁,用于改善桌面应用的交互性,减小响应时间,提升用户体验。它采用了全局单任务队列设计,不再让每个 CPU 都有独立的运行队列。虽然使用单个全局队列,需要引入队列锁来保证并发安全性,但是对于桌面系统而言,处理器通常都比较少,锁的开销基本可以忽略。BFS 每次会在任务链表中选择具有最小 virtual deadline 的任务运行。
MuqSS 是作者后来基于 BFS 改进的一款调度器,同样是用于桌面环境任务调度。它主要解决了 BFS 的两个问题:
每次需要在对应优先级链表中遍历查找需要执行任务,这个时间复杂度为 O(n)。所以新的调度器引入了跳表来解决该问题,从而将时间复杂度降低到 O(1)。
全局锁争夺的开销优化,采用 try_lock 替代 lock。
“怎么理解Linux Kernel调度器”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





