这篇文章主要讲解了“一些前端基础知识整理”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“一些前端基础知识整理”吧!
Call, bind, apply实现
// call Function.prototype.myCall = function (context) { context = context ? Object(context) : window context.fn = this; let args = [...arguments].slice(1); const result = context.fn(...args); delete context.fn; return result; } // apply Function.prototype.myApply = function (context) { context = context ? Object(context) : window; context.fn = this; let args = [...arguments][1]; let result; if (args.length === 0) { result = context.fn(); } else { result = context.fn(args); } delete context.fn; return result; } // bind Function.prototype.myBind = function (context) { let self = this; let args = [...arguments].slice(1); return function() { let newArgs = [...arguments]; return self.apply(context, args.concat(newArgs)); } }原型与原型链
每一个JavaScript对象(null除外)在创建的时候会关联另一个对象,这个被关联的对象就是原型。每一个JavaScript对象(除了 null)都具有的__proto__属性会指向该对象的原型。JavaScript中所有的对象都是由它的原型对象继承而来,而原型也是一个对象,它也有自己的原型对象,这样层层上溯,就形成了一个类似链表的结构,这就是原型链。每一个对象都会从原型"继承"属性。
实例对象和构造函数都可以指向原型, 原型可以指向构造函数,不能指向实例(因为可以有多个实例)。
原型对象有两个属性,constructor 和 __proto__。
function Person() {} var person = new Person(); // 实例原型 === 构造函数原型 person.__proto__ === Person.prototype // true // 原型构造函数 === 构造函数 Person.prototype.constructor === Person // truereact diff
React 通过制定大胆的 diff 策略,将 O(n3) 复杂度的问题转换成 O(n) 复杂度的问题;
React 通过分层求异的策略,对 tree diff 进行算法优化;
对树进行分层比较,两棵树只会对同一层次的节点进行比较。
React 通过相同类生成相似树形结构,不同类生成不同树形结构的策略,对 component diff 进行算法优化;
鸿蒙官方战略合作共建——HarmonyOS技术社区
如果是同一类型的组件,按照原策略继续比较 virtual DOM tree。
如果不是,则将该组件判断为 dirty component,从而替换整个组件下的所有子节点。
对于同一类型的组件,有可能其 Virtual DOM 没有任何变化,如果能够确切的知道这点那可以节省大量的 diff 运算时间,因此 React 允许用户通过 shouldComponentUpdate() 来判断该组件是否需要进行 diff。
React 通过设置唯一 key的策略,对 element diff 进行算法优化;
建议,在开发组件时,保持稳定的 DOM 结构会有助于性能的提升;
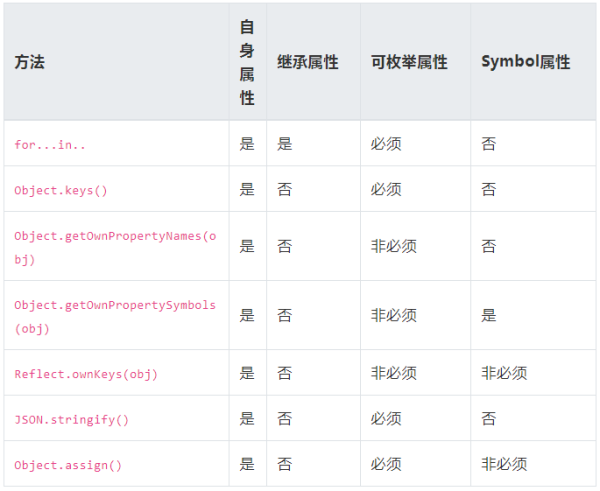
遍历对象
对象遍历方法总结:
for...in:遍历对象自身, 包含继承, 可枚举,不含 Symbol 的属性。
Object.keys(obj):遍历对象自身, 不含继承,可枚举,不含 Symbol 的属性。【values, entries】
Object.getOwnPropertyNames(obj):遍历对象自身, 不含继承, 不含 Symbol 的属性, 不管是否可枚举
Object.getOwnPropertySymbols(obj): 遍历对象自身, 不含继承, 所有 Symbol 的属性, 不管是否可枚举
Reflect.ownKeys(obj): 遍历对象自身,不含继承,所有键名,不管是否Symbol 和可枚举。
对象其他方法:
JSON.stringify():只串行化对象自身,不含继承,可枚举,不含 Symbol属性。【function,undefined, Symbol会丢失, set、map会处理成空对象】
Object.assign():只拷贝对象自身,不含继承, 可枚举属性, 不管是否是Symbol 。【全部数据类型属性值】
异步加载脚本
默认情况下,浏览器是同步加载 JavaScript 脚本,即渲染引擎遇到<script>标签就会停下来,等到执行完脚本,再继续向下渲染。如果是外部脚本,还必须加入脚本下载的时间。
异步加载脚本方法:defer与async。
defer与async的区别是:defer要等到整个页面在内存中正常渲染结束(DOM 结构完全生成,以及其他脚本执行完成),才会执行;async一旦下载完,渲染引擎就会中断渲染,执行这个脚本以后,再继续渲染。一句话,defer是“渲染完再执行”,async是“下载完就执行”。另外,如果有多个defer脚本,会按照它们在页面出现的顺序加载,而多个async脚本是不能保证加载顺序的。
浏览器对于带有type="module"的<script>,都是异步加载,不会造成堵塞浏览器,即等到整个页面渲染完,再执行模块脚本,等同于打开了<script>标签的defer属性。
ES6 模块与 CommonJS 模块的差异
CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
因为 CommonJS 加载的是一个对象(即module.exports属性),该对象只有在脚本运行完才会生成。而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
CommonJS 模块的require()是同步加载模块,ES6 模块的import命令是异步加载,有一个独立的模块依赖的解析阶段。
回流Reflow与重绘Repaint
回流:元素的大小或者位置发生了变化,触发了重新布局,导致渲染树重新计算布局和渲染。页面第一次加载的时候,至少发生一次回流。
鸿蒙官方战略合作共建——HarmonyOS技术社区
添加或删除可见的DOM元素;
元素的位置发生变化;
元素的尺寸发生变化;
内容发生变化(比如文本变化或图片被另一个不同尺寸的图片所替代);
页面一开始渲染的时候(这个无法避免);
浏览器的窗口尺寸变化, 因为回流是根据视口的大小来计算元素的位置和大小的;
重绘:元素的外观,风格改变,而不会影响布局(不包含宽高、大小、位置等不变)。
如:outline, visibility, color, background-color......等
Reflow 的成本比 Repaint 高得多的多。DOM Tree 里的每个结点都会有 reflow 方法,一个结点的 reflow 很有可能导致子结点,甚至父点以及同级结点的 reflow。。回流一定会触发重绘,而重绘不一定会回流
减少重绘与回流
1.CSS方法
使用 visibility 替换 display: none ,因为前者只会引起重绘,后者会引发回流
避免使用table布局,可能很小的一个小改动会造成整个 table 的重新布局。
避免设置多层内联样式,CSS 选择符从右往左匹配查找,避免节点层级过多。
将动画效果应用到position属性为absolute或fixed的元素上,避免影响其他元素的布局,这样只是一个重绘,而不是回流,同时,控制动画速度可以选择 requestAnimationFrame
避免使用CSS表达式,可能会引发回流。
将频繁重绘或者回流的节点设置为图层,图层能够阻止该节点的渲染行为影响别的节点,例如will-change、video、iframe等标签,浏览器会自动将该节点变为图层。
CSS3 硬件加速(GPU加速),使用css3硬件加速,可以让transform、opacity、filters这些动画不会引起回流重绘 。但是对于动画的其它属性,比如background-color这些,还是会引起回流重绘的,不过它还是可以提升这些动画的性能。
2.JavaScript方法
避免频繁操作样式,最好一次性重写style属性,或者将样式列表定义为class并一次性更改class属性。
避免频繁操作DOM,创建一个documentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中。
避免频繁读取会引发回流/重绘的属性,如果确实需要多次使用,就用一个变量缓存起来。
CSS3硬件加速(GPU加速)
CSS3 硬件加速又叫做 GPU 加速,是利用 GPU 进行渲染,减少 CPU 操作的一种优化方案。
render tree -> 渲染元素 -> 图层 -> GPU 渲染 -> 浏览器复合图层 -> 生成最终的屏幕图像。
浏览器在获取 render tree后,渲染树中包含了大量的渲染元素,每一个渲染元素会被分到一个个图层中,每个图层又会被加载到 GPU 形成渲染纹理。GPU 中 transform 是不会触发 repaint ,最终这些使用 transform 的图层都会由独立的合成器进程进行处理。
CSS3触发硬件加速的属性:
鸿蒙官方战略合作共建——HarmonyOS技术社区
transform
opacity
filter
will-change
http请求方法
HTTP1.0定义了三种请求方法:GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
鸿蒙官方战略合作共建——HarmonyOS技术社区
OPTIONS:即预检请求,可用于检测服务器允许的http方法。当发起跨域请求时,由于安全原因,触发一定条件时浏览器会在正式请求之前自动先发起OPTIONS请求,即CORS预检请求,服务器若接受该跨域请求,浏览器才继续发起正式请求。
HEAD: 向服务器索与GET请求相一致的响应,只不过响应体将不会被返回,用于获取报头。
GET:向特定的资源发出请求。注意:GET方法不应当被用于产生“副作用”的操作中
POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
PUT:向指定资源位置上传其最新内容
DELETE:请求服务器删除Request-URL所标识的资源
TRACE:回显服务器收到的请求,主要用于测试或诊断
CONNECT:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器
js判断数据类型
1. typeof 操作符
对于基本类型,除 null 以外,均可以返回正确的结果。
对于引用类型,除 function 以外,一律返回 object 类型。
对于 null ,返回 object 类型。
对于 function 返回 function 类型。
2. instanceof
用来判断 A 是否为 B 的实例,检测的是原型。instanceof 只能用来判断两个对象是否属于实例关系, 而不能判断一个对象实例具体属于哪种类型。
instanceof 主要的实现原理就是只要右边变量的 prototype 在左边变量的原型链上即可。
3. constructor
null 和 undefined 是无效的对象,不会有 constructor 存在的
函数的 constructor 是不稳定的,这个主要体现在自定义对象上,当开发者重写 prototype 后,原有的 constructor 引用会丢失,constructor 会默认为 Object。为了规范开发,在重写对象原型时一般都需要重新给 constructor 赋值。
4. toString
toString() 是 Object 的原型方法,调用该方法,默认返回当前对象的 [[Class]] 。这是一个内部属性,其格式为 [object Xxx] ,其中 Xxx 就是对象的类型。
浏览器事件模型
DOM事件流(event flow )存在三个阶段:事件捕获阶段、处于目标阶段、事件冒泡阶段。
// useCapture:true, 即采用事件捕获方式 window.addEventListener("click", function(e){ console.log("window 捕获"); }, true); // useCapture:false【默认为false】,即采用事件冒泡方式 window.addEventListener("click", function(e){ console.log("window 冒泡"); }, false);目标元素(被点击的元素)绑定的事件都会发生在目标阶段,在绑定捕获代码之前写了绑定的冒泡阶段的代码,所以在目标元素上就不会遵守先发生捕获后发生冒泡这一规则,而是先绑定的事件先发生。
不是目标元素,它上面绑定的事件会遵守先发生捕获后发生冒泡的规则。
e.stopPropagation():阻止事件传播。不仅可以阻止事件在冒泡阶段的传播,还能阻止事件在捕获阶段的传播。
e.preventDefault(): 阻止事件的默认行为。默认行为是指:点击a标签就转跳到其他页面、拖拽一个图片到浏览器会自动打开、点击表单的提交按钮会提交表单等
http缓存: 强制缓存和协商缓存
良好的缓存策略可以降低资源的重复加载提高网页的整体加载速度。
缓存原理
鸿蒙官方战略合作共建——HarmonyOS技术社区
浏览器在加载资源时,根据请求头的expires和cache-control判断是否命中强缓存,是则直接从缓存读取资源,不会发请求到服务器。
如果没有命中强缓存,浏览器会发送一个请求到服务器,通过last-modified和etag验证是否命中协商缓存。当向服务端发起缓存校验的请求时,服务端会返回 200 ok表示返回正常的结果或者 304 Not Modified(不返回body)表示浏览器可以使用本地缓存文件。304的响应头也可以同时更新缓存文档的过期时间
如果前面两者都没有命中,直接从服务器加载资源。
实现方式
强缓存通过Expires和Cache-Control实现。
协商缓存是利用的是【Last-Modified,If-Modified-Since】和【ETag、If-None-Match】这两对Header来管理的。
Expires
Expires是http1.0提出的一个表示资源过期时间的header,它是一个绝对时间,由服务器返回。Expires 受限于本地时间,如果修改了本地时间,可能会造成缓存失效。
Expires: Wed, 11 May 2018 07:20:00 GMT
Cache-Control
Cache-Control 出现于 HTTP / 1.1,优先级高于 Expires , 表示的是相对时间。
no-store:没有缓存。缓存中不得存储任何关于客户端请求和服务端响应的内容。每次由客户端发起的请求都会下载完整的响应内容。 no-cache: 缓存但重新验证。每次有请求发出时,缓存会将此请求发到服务器(译者注:该请求应该会带有与本地缓存相关的验证字段),服务器端会验证请求中所描述的缓存是否过期,若未过期(返回304),则缓存才使用本地缓存副本。 private:只允许客户端浏览器缓存。 public: 允许所有用户缓存。例如中间代理、CDN等 max-age=<seconds>:表示资源能够被缓存的最大时间。相对Expires而言,max-age是距离请求发起的时间的秒数。针对应用中那些不会改变的文件,通常可以手动设置一定的时长以保证缓存有效,例如图片、css、js等静态资源。 must-revalidate:触发缓存验证。验证它的状态,已过期的缓存将不被使用Last-Modified,If-Modified-Since
Last-Modifie表示本地文件最后修改日期,浏览器会在request header加 If-Modified-Since(上次返回的Last-Modified的值),询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来。
但是如果在本地打开缓存文件,就会造成 Last-Modified 被修改,所以在 HTTP / 1.1 出现了 ETag。
ETag、If-None-Match
Etag就像一个指纹,资源变化都会导致ETag变化,跟最后修改时间没有关系,ETag可以保证每一个资源是唯一的。
If-None-Match的header会将上次返回的Etag发送给服务器,询问该资源的Etag是否有更新,有变动就会发送新的资源回来。
ETag的优先级比Last-Modified更高。
具体为什么要用ETag,主要出于下面几种情况考虑:
一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
某些服务器不能精确的得到文件的最后修改时间。
防抖和节流
防抖:当你在频繁调用方法时,并不会执行,只有当你在指定间隔内没有再调用,才会执行函数。
节流:在一个单位时间内,只能触发一次函数。如果这个单位时间内触发多次函数,只有一次生效。
防抖
function debounce(fn, wait) { let time = null; return (function() { const context = this; const args = arguments; if (time) { clearTimeout(time); time = null; } time = setTimeout(() => { fn.call(context, args); }, wait); }); }节流
function throttle(fn, wait) { let lastTime; return ( function() { const context = this; const args = arguments; let nowTime = + new Date(); if (nowTime > lastTime + wait || !lastTime) { fn.call(context, args); lastTime = nowTime; } } );大小单位区别
px:像素。
em:参考物是父元素的font-size,具有继承的特点。如果自身定义了font-size按自身来计算,整个页面内1em不是一个固定的值。
rem:相对于根元素html的font-size计算,不会像em那样,依赖于父元素的字体大小,而造成混乱。
vw:视窗宽度,1vw等于视窗宽度的1%。
vh:视窗高度,1vh等于视窗高度的1%。
vm:min(vw, vh)。
%:是相对于父元素的大小设定的比率,position:absolute;的元素是相对于已经定位的父元素,position:fixed;的元素是相对可视窗口。
浏览器默认字体是16px, body设置font-size:62.5%, 那么1rem =62.5% * 16=10px 。
谷歌浏览器强制最小字体为12号,即使设置成 10px 最终都会显示成 12px,当把html的font-size设置成10px,子节点rem的计算还是以12px为基准。
Box-sizing
content-box:这是默认情况,整个元素的高度和宽度就是元素内容
border-box:这种情况下,你设置的width和height属性值就是针对整个元素,包括了border,padding,和元素内容。
函数声明和函数表达式
// 函数声明 function wscat(type){ return 'wscat'; } // 函数表达式 var oaoafly = function(type){ return "oaoafly"; }JavaScript 解释器中存在一种变量声明被提升的机制,也就是说函数声明会被提升到作用域的最前面,即使写代码的时候是写在最后面,也还是会被提升至最前面。
用函数表达式创建的函数是在运行时进行赋值,且要等到表达式赋值完成后才能调用
函数声明在JS解析时进行函数提升,因此在同一个作用域内,不管函数声明在哪里定义,该函数都可以进行调用。而函数表达式的值是在JS运行时确定,并且在表达式赋值完成后,该函数才能调用。这个微小的区别,可能会导致JS代码出现意想不到的bug,让你陷入莫名的陷阱中。
事件循环EventLoop
JavaScript是一个单线程的脚本语言。
所有同步任务都在主线程上执行,形成一个执行栈 (Execution Context Stack);而异步任务会被放置到 Task Table(异步处理模块),当异步任务有了运行结果,就将注册的回调函数移入任务队列(两种队列)。
一旦执行栈中的所有同步任务执行完毕,引擎就会读取任务队列,然后将任务队列中的第一个任务取出放到执行栈中运行。(所有会进入的异步都是指的事件回调中的那部分代码)
只要主线程空了,就会去读取任务队列,该过程不断重复,这就是所谓的 事件循环。
宏任务和微任务
宏任务会进入一个队列,微任务会进入到另一个队列,且微任务要优于宏任务执行。
宏任务:script(整体代码)、setTimeout、setInterval、I/O、事件、postMessage、 MessageChannel、setImmediate (Node.js)
微任务:Promise.then、 MutaionObserver、process.nextTick (Node.js)
宏任务会进入一个队列,而微任务会进入到另一个不同的队列,且微任务要优于宏任务执行。
Promise
1. Promise.all: 全部fulfilled, 才进入then, 否则 catch 2. Promise.race: 任一个返回,不管是fulfilled还是rejected, 进入相应的then/catch 3. Promise.allSettled: 全部返回,不管是fulfilled还是rejected, 进入then 4. Promise.any: 任一个返回fulfilled, 就进入then, 否则 catch虚拟dom原理
Virtual DOM是对DOM的抽象,本质上是JavaScript对象,这个对象就是更加轻量级的对DOM的描述.
箭头函数与普通函数区别
语法更加简洁、清晰
不绑定this,会捕获其所在的上下文的this值,作为自己的this值
箭头函数继承而来的this指向永远不变
.call()/.apply()/.bind()无法改变箭头函数中this的指向
不能作为构造函数使用, 因为没有自己的 this,无法调用 call,apply;没有 prototype 属性 ,而 new 命令在执行时需要将构造函数的 prototype 赋值给新的对象的__prpto__ 。
没有自己的arguments,在箭头函数中访问arguments实际上获得的是外层局部(函数)执行环境中的值。如果要用,可以用 rest 参数代替。
没有原型prototype, 指向 undefined
不能使用yeild关键字
new
new 关键字会进行如下的操作:
鸿蒙官方战略合作共建——HarmonyOS技术社区
创建一个空的简单JavaScript对象(即{});
链接该对象(设置该对象的__proto__)到构造器函数的原型 ;
将新创建的对象作为this的上下文 ;
返回。如果该函数没有返回对象,则返回this。
function newFunc(father, ...rest) { // 首先创建一个空对象 var result = {}; // 将空对象的原型赋值为构造器函数的原型 result.__proto__ = father.prototype; // 更改构造器函数内部this,将其指向新创建的空对象 var result2 = father.apply(result, rest); if ((typeof result2 === 'object' || typeof result2 === 'function') && result2 !== null) { return result2; } return result; }水平与垂直居中实现方式
水平居中
text-align: center; 行内元素适用
margin: 0 auto; 适用块级元素
width: fit-content; 若子元素包含 float:left 属性, 为了让子元素水平居中, 则可让父元素宽度设置为fit-content, 并且配合margin。
.parent { width:fit-content; margin:0 auto; }flex
.parent { display: flex; justify-content: center; }盒模型, 使用flex 2009年版本
.parent { display: box; box-orient: horizontal; box-pack: center; }transform
.son { position: absolute; left: 50%; transform: translate(-50%, 0); }两种不同的绝对定位方法
.son { position: absolute; width: 固定; left: 50%; margin-left: -0.5 * 宽度; } .son { position: absolute; width: 固定; left: 0; right: 0; margin: 0 auto; }垂直居中
单行文本, line-height
行内块级元素, 使用 display: inline-block, vertical-align: middle; 加上伪元素辅助实现
.parent::after, .son { display:inline-block; vertical-align:middle; } .parent::after { content:''; height:100%; }vertical-align。vertical-align只有在父层为 td 或者 th 时, 才会生效, 对于其他块级元素, 例如 div、p 等, 默认情况是不支持的. 为了使用vertical-align, 我们需要设置父元素display:table, 子元素 display:table-cell;vertical-align:middle;
flex
.parent { display: flex; align-items: center; }盒模型
.parent { display: box; box-orient: vertical; box-pack: center; }transform
.son { position: absolute; top: 50%; transform: translate(0, -50%); }两种不同的绝对定位方法
.son { position: absolute; height: 固定; top: 50%; margin-top: -0.5 * height; } .son { position: absolute; height: 固定; top: 0; bottom: 0; margin: auto 0; }flex, 盒模型, transform, 绝对定位, 这几种方法同时适用于水平居中和垂直居中
排序
冒泡排序
function bubbleSort(arr) { const len = arr.length; for (let i = 0; i < len - 1; i++) { for (let j = i + 1; j < len; j++) { if (arr[j] < arr[i]) { [arr[j], arr[i]] = [arr[i], arr[j]]; } } } return arr; }选择排序
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
function selectionSort(arr) { const len = arr.length; for (let i = 0; i < len - 1; i++) { let index = i; for (let j = i + 1; j < len; j++) { if (arr[j] < arr[index]) { index = j; } } if (index !== i) { [arr[i], arr[index]] = [arr[index], arr[i]]; } } return arr; }插入排序
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
function insertionSort(arr) { const len = arr.length; for (let i = 1; i < len; i++) { let j = i - 1; const value = arr[i]; while (arr[j] > value && j >= 0) { arr[j + 1] = arr[j]; j--; } arr[j + 1] = value; } return arr; }归并排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序是一种稳定的排序方法。先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
function mergeSort(arr) { //采用自上而下的递归方法 var len = arr.length; if (len < 2) return arr; const middle = Math.floor(len / 2); let left = arr.slice(0, middle); let right = arr.slice(middle); return merge(mergeSort(left), mergeSort(right)); } function merge(left, right) { let result = []; while (left.length && right.length) { if (left[0] <= right[0]) { result.push(left.shift()); } else { result.push(right.shift()); } } return result.concat(left).concat(right); }快速排序
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
function quickSort(arr) { if (arr.length <= 1) return arr; const pivotIndex = Math.floor(arr.length / 2); const pivot = arr.splice(pivotIndex, 1)[0]; let left = []; let right = []; for (let i = 0; i < arr.length; i++){ if (arr[i] < pivot) { left.push(arr[i]); } else { right.push(arr[i]); } } return quickSort(left).concat([pivot], quickSort(right)); }; };洗牌算法
function shuffle(arr){ const length = arr.length; while (length > 0) { const random = Math.floor(Math.random() * length); length--; [arr[length], arr[random]] = [arr[random], arr[length]]; } return arr; } // 或 arr.sort(function(){ return .5 - Math.random(); });感谢各位的阅读,以上就是“一些前端基础知识整理”的内容了,经过本文的学习后,相信大家对一些前端基础知识整理这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/6eybEbxbckQSPviK29hLwg



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



