这篇文章将为大家详细讲解有关Python中怎么实现一个感知器,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
什么是感知器?
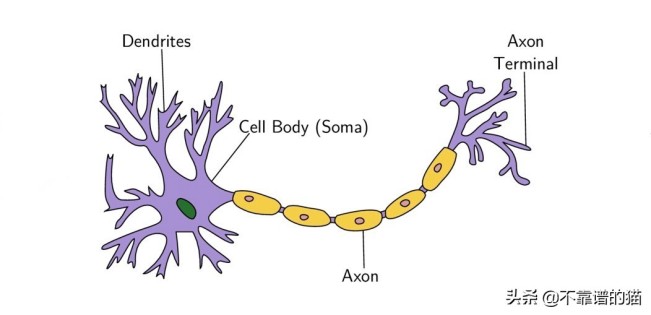
生物神经元示意图
感知器的概念类似于大脑基本处理单元神经元的工作原理。神经元由许多由树突携带的输入信号、胞体和轴突携带的一个输出信号组成。当细胞达到特定阈值时,神经元会发出一个动作信号。这个动作要么发生,要么不发生。
类似地,感知器具有许多输入(通常称为特征),这些输入被馈送到产生一个二元输出的线性单元中。因此,感知器可用于解决二元分类问题,其中样本将被识别为属于预定义的两个类之一。
算法
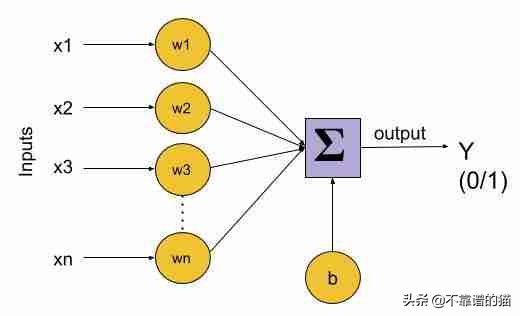
感知器原理图
由于感知器是二元类器(0/1),我们可以将它们的计算定义如下:
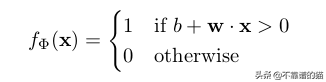
让我们回想一下,两个长度为n的向量的点积由下式给出:
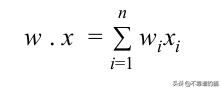
函数f(x)= b + w.x是权重和特征向量的线性组合。 因此,感知器是线性分类器-一种使用线性预测器函数进行预测的算法。
权重表示x中每个特征xᵢ 对机器学习模型行为的有效性。特征xᵢ的权重wᵢ越高,对输出的影响就越大。偏差“ b”类似于线性方程式中的截距,它是一个常数,可以帮助机器学习模型以最适合数据的方式进行调整。偏差项假设虚拟输入特征系数x₀= 1。
可以使用以下算法训练模型:

Python实现
我们考虑用于实现感知器的机器学习数据集是鸢尾花数据集。这个数据集包含描述花的4个特征,并将它们归类为属于3个类中的一个。我们剥离了属于类' Iris-virginica '的数据集的最后50行,只使用了两个类' Iris-setosa '和' Iris-versicolor ',因为这些类是线性可分的,算法通过最终找到最优权重来收敛到局部最小值。
import numpy as np import pandas as pd import matplotlib.pyplot as plt def load_data(): URL_='https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data' data = pd.read_csv(URL_, header = None) print(data) # make the dataset linearly separable data = data[:100] data[4] = np.where(data.iloc[:, -1]=='Iris-setosa', 0, 1) data = np.asmatrix(data, dtype = 'float64') return data data = load_data()
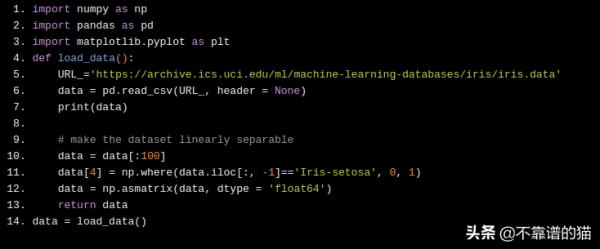
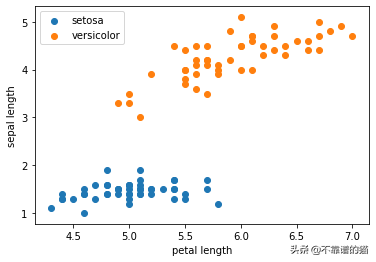
将具有两个特征的数据集可视化,我们可以看到,通过在它们之间画一条直线,可以清楚地分隔数据集。
我们的目标是编写一个算法来找到这条线并正确地对所有这些数据点进行分类。
plt.scatter(np.array(data[:50,0]), np.array(data[:50,2]), marker='o', label='setosa') plt.scatter(np.array(data[50:,0]), np.array(data[50:,2]), marker='x', label='versicolor') plt.xlabel('petal length') plt.ylabel('sepal length') plt.legend() plt.show()
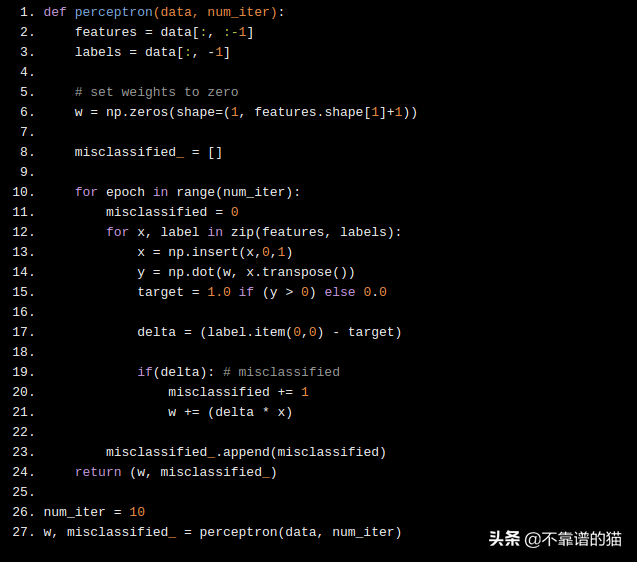
现在我们实现上面提到的算法,看看它是如何工作的。我们有4个特征,因此每个特征有4个权重。请记住,我们定义了一个偏置项w₀,假设x₀= 1,使其总共具有5个权重。
我们将迭代次数定义为10。这是超参数之一。在每次迭代时,算法都会为所有数据点计算类别(0或1),并随着每次错误分类更新权重。
如果样本分类错误,则权值将由向相反方向移动的增量更新。因此,如果再次对样本进行分类,结果就会“错误较少”。我们将任何label≤0归类为“0”(Iris-setosa),其它归类为“1”(Iris-versicolor)。
def perceptron(data, num_iter): features = data[:, :-1] labels = data[:, -1] # set weights to zero w = np.zeros(shape=(1, features.shape[1]+1)) misclassified_ = [] for epoch in range(num_iter): misclassified = 0 for x, label in zip(features, labels): x = np.insert(x,0,1) y = np.dot(w, x.transpose()) target = 1.0 if (y > 0) else 0.0 delta = (label.item(0,0) - target) if(delta): # misclassified misclassified += 1 w += (delta * x) misclassified_.append(misclassified) return (w, misclassified_) num_iter = 10 w, misclassified_ = perceptron(data, num_iter)
现在,让我们绘制每次迭代中分类错误的样本数。我们可以看到该算法在第4次迭代中收敛。也就是说,所有样本在第4次通过数据时都已正确分类。
感知器的一个特性是,如果数据集是线性可分离的,那么该算法一定会收敛!
epochs = np.arange(1, num_iter+1) plt.plot(epochs, misclassified_) plt.xlabel('iterations') plt.ylabel('misclassified') plt.show()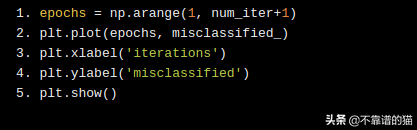
关于Python中怎么实现一个感知器就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





