这篇文章主要介绍“如何理解JAVA.IO、字符编码”,在日常操作中,相信很多人在如何理解JAVA.IO、字符编码问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”如何理解JAVA.IO、字符编码”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
1 JAVA.IO字节流
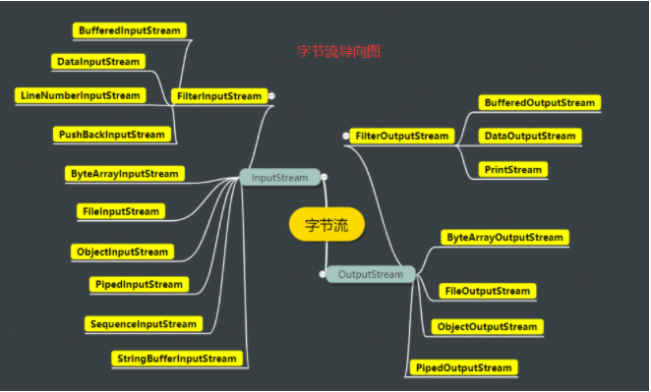
inputstream.png
LineNumberInputStream和StringBufferInputStream官方建议不再使用,推荐使用LineNumberReader和StringReader代替
ByteArrayInputStream和ByteArrayOutputStream 字节数组处理流,在内存中建立一个缓冲区作为流使用,从缓存区读取数据比从存储介质(如磁盘)的速率快
//用ByteArrayOutputStream暂时缓存来自其他渠道的数据
ByteArrayOutputStream data = new ByteArrayOutputStream(1024); //1024字节大小的缓存区
data.write(System.in.read()); // 暂存用户输入数据
//将data转为ByteArrayInputStream
ByteArrayInputStream in = new ByteArrayInputStream(data.toByteArray());
FileInputStream和FileOutputStream 访问文件,把文件作为InputStream,实现对文件的读写操作
ObjectInputStream和ObjectOutputStream 对象流,构造函数需要传入一个流,实现对JAVA对象的读写功能;可用于序列化,而对象需要实现Serializable接口
//java对象的写入 FileOutputStream fileStream = new FileOutputStream("example.txt"); ObjectOutputStream out = new ObjectOutputStream(fileStream); Example example = new Example(); out.writeObject(example); //java对象的读取 FileInputStream fileStream = new FileInputStream("example.txt"); ObjectInputStream in = new ObjectInputStream(fileStream); Example = (Example) in.readObject();PipedInputStream和PipedOutputStream 管道流,适用在两个线程中传输数据,一个线程通过管道输出流发送数据,另一个线程通过管道输入流读取数据,实现两个线程间的数据通信
// 创建一个发送者对象 Sender sender = new Sender(); // 创建一个接收者对象 Receiver receiver = new Receiver(); // 获取输出管道流 // 获取输入输出管道流 PipedOutputStream outputStream = sender.getOutputStream(); PipedInputStream inputStream = receiver.getInputStream(); // 链接两个管道,这一步很重要,把输入流和输出流联通起来 outputStream.connect(inputStream); sender.start();// 启动发送者线程 receiver.start();// 启动接收者线程
SequenceInputStream 把多个InputStream合并为一个InputStream,允许应用程序把几个输入流连续地合并起来
InputStream in1 = new FileInputStream("example1.txt"); InputStream in2 = new FileInputStream("example2.txt"); SequenceInputStream sequenceInputStream = new SequenceInputStream(in1, in2); //数据读取 int data = sequenceInputStream.read();FilterInputStream和FilterOutputStream 使用了装饰者模式来增加流的额外功能,子类构造参数需要一个InputStream/OutputStream
ByteArrayOutputStream out = new ByteArrayOutputStream(2014); //数据写入,使用DataOutputStream装饰一个InputStream //使用InputStream具有对基本数据的处理能力 DataOutputStream dataOut = new DataOutputStream(out); dataOut.writeDouble(1.0); //数据读取 ByteArrayInputStream in = new ByteArrayInputStream(out.toByteArray()); DataInputStream dataIn = new DataInputStream(in); Double data = dataIn.readDouble();
DataInputStream和DataOutputStream (Filter流的子类) 为其他流附加处理各种基本类型数据的能力,如byte、int、String
BufferedInputStream和BufferedOutputStream (Filter流的子类) 为其他流增加缓冲功能
PushBackInputStream (FilterInputStream子类) 推回输入流,可以把读取进来的某些数据重新回退到输入流的缓冲区之中
PrintStream (FilterOutputStream子类) 打印流,功能类似System.out.print
2 JAVA.IO字符流
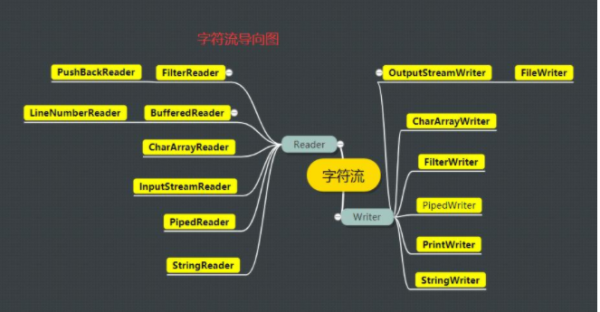
21.png
从字节流和字符流的导向图来,它们之间是相互对应的,比如CharArrayReader和ByteArrayInputStream
字节流和字符流的转化:InputStreamReader可以将InputStream转为Reader,OutputStreamReader可以将OutputStream转为Writer
//InputStream转为Reader InputStream inputStream = new ByteArrayInputStream("程序".getBytes()); InputStreamReader reader = new InputStreamReader(inputStream, StandardCharsets.UTF_8); //OutputStream转为Writer OutputStream out = new FileOutputStream("example.txt"); OutputStreamWriter writer = new OutputStreamWriter(out); //以字符为单位读写 writer.write(reader.read(new char[2]));区别:字节流读取单位是字节,字符流读取单位是字符;一个字符由字节组成,如变字长编码UTF-8是由1~4个字节表示
3 乱码问题和字符流
字符以不同的编码表示,它的字节长度(字长)是不一样的。如“程”的utf-8编码格式,由[-25][-88][-117]组成。而ISO_8859_1编码则是单个字节[63]
平时工作对资源的操作都是面向字节流的,然而数据资源根据不同的字节编码转为字节时,它们的内容是不一样,容易造成乱码问题
两种出现乱码场景 encode和decode使用的字符编码不一致:资源使用UTF-8编码,而在代码里却使用GBK解码打开使用字节流读取字节数不符合字符规定字长:字符是由字节组成的,比如“程”的utf-8格式是三个字节;如果在InputStream里以每两个字节读取流,再转为String(java默认编码是utf-8),此时会出现乱码(半个中文,你猜是什么)
ByteArrayInputStream in = new ByteArrayInputStream("程序大法好".getBytes());
byte[] buf = new byte[2]; //读取流的两个字节
in.read(buf); //读取数据
System.out.println(new String(buf)); //乱码
---result----
� //乱码
乱码场景1,知道资源的字符编码,就可以使用对应的字符编码来解码解决
乱码场景2,可以一次性读取所有字节,再一次性编码处理。但是对于大文件流,这是不现实的,因此有了字符流的出现
字节流使用InputStreamReader、OutputStreamReader转化为字符流,其中可以指定字符编码,再以字符为单位来处理,可解决乱码
InputStreamReader reader = new InputStreamReader(inputStream, StandardCharsets.UTF_8);
4 字符集和字符编码的概念区分
字符集和字符编码的关系,字符集是规范,字符编码是规范的具体实现;字符集规定了符号和二进制代码值的唯一对应关系,但是没有指定具体的存储方式;
unicode、ASCII、GB2312、GBK都是字符集;其中ASCII、GB2312、GBK既是字符集也是字符编码;注意不混淆这两者区别;而unicode的具体实现有UTF-8,UTF-16,UTF-32
最早出现的ASCII码是使用一个字节(8bit)来规定字符和二进制映射关系,标准ASCII编码规定了128个字符,在英文的世界,是够用的。但是中文,日文等其他文字符号怎么映射呢?因此其他更大的字符集出现了
unicode(统一字符集),早期时它使用2个byte表示1个字符,整个字符集可以容纳65536个字符。然而仍然不够用,于是扩展到4个byte表示一个字符,现支持范围是U+010000~U+10FFFF
unicode是两个字节的说法是错误的;UTF-8是变字长的,需要用1~4个字节存储;UTF-16一般是两个字节(U+0000~U+FFFF范围),如果遇到两个字节存不下,则用4个字节;而UTF-32是固定四个字节
unicode表示的字符,会用“U+”开头,后面跟着十六进制的数字,如“字”的编码就是U+5B57
UTF-8 编码和unicode字符集
范围 Unicode(Binary) UTF-8编码(Binary) UTF-8编码byte长度 U+0000~U+007F 00000000 00000000 00000000 0XXXXXXX 0XXXXXX 1 U+0080~U+07FF 00000000 00000000 00000YYY YYXXXXXX 110YYYYY 10XXXXXX 2 U+0800~U+FFFF 00000000 00000000 ZZZZYYYY YYXXXXXX 1110ZZZZ 10YYYYYY 10XXXXXX 3 U+010000~U+10FFFF 00000000 000AAAZZ ZZZZYYYY YYXXXXXX 11110AAA 10ZZZZZZ 10YYYYYY 10XXXXXX 4
程序是分内码和外码,java的默认编码是UTF-8,其实指的是外码;内码倾向于使用定长码,和内存对齐一个原理,便于处理。外码倾向于使用变长码,变长码将常用字符编为短编码,罕见字符编为长编码,节省存储空间与传输带宽
JDK8的字符串,是使用char[]来存储字符的,char是两个字节大小,其中使用的是UTF-16编码(内码)。而unicode规定的中文字符在U+0000~U+FFFF内,因此使用char(UTF-16编码)存储中文是不会出现乱码的
JDK9后,字符串则使用byte[]数组来存储,因为有一些字符一个char已经存不了,如emoji表情字符,使用字节存储字符串更容易拓展
JDK9,如果字符串的内容都是ISO-8859-1/Latin-1字符(1个字符1字节),则使用ISO-8859-1/Latin-1编码存储字符串,否则使用UTF-16编码存储数组(2或4个字节)
System.out.println(Charset.defaultCharset()); //输出java默认编码 for (byte item : "程序".getBytes(StandardCharsets.UTF_16)) { System.out.print("[" + item + "]"); } System.out.println(""); for (byte item : "程序".getBytes(StandardCharsets.UTF_8)) { System.out.print("[" + item + "]"); } ----result---- UTF-8 //java默认编码UTF-8 [-2][-1][122][11][94][-113] //UTF_16:6个字节? [-25][-88][-117][-27][-70][-113] //UTF_8:6个字节 正常“程序”的UTF-16编码竟是输出6个字节,多出了两个字节,这是什么情况?再试试一个字符的输
for (byte item : "程".getBytes(StandardCharsets.UTF_16)) {
System.out.print("[" + item + "]");
}
---result--
[-2][-1][122][11]
可以看出UTF-16编码的字节是多了[-2][-1]两个字节,十六进制是0xFEFF。而它用来标识编码顺序是Big endian还是Little endian。以字符'中'为例,它的unicode十六进制是4E2D,存储时4E在前,2D在后,就是Big endian;2D在前,4E在后,就是Little endian。FEFF表示存储采用Big endian,FFFE表示使用Little endian
为什么UTF-8没有字节序的问题呢?个人看法,因为UTF-8是变长的,由第一个字节的头部的0、110、1110、11110判断是否需后续几个字节组成字符,使用Big endian易读取处理,反过来不好处理,因此强制用Big endian
其实感觉UTF-16可以强制规定用Big endian;但这其中历史问题。。。
到此,关于“如何理解JAVA.IO、字符编码”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





