一个 .py文件 就是一个模块(Module)。
在开发过程中我们不会把所有的代码都写在一个 .py文件 中。随着代码量的增大,可以按照功能将函数或者类分开存放到不同的 .py文件 中。
这样代码更方便管理,以及后期的维护,也便于其他程序来调用当前已经实现的功能~
在开发过程中,我们也经常引用其他模块,例如:time,os,configparser,re 等等
在Python中模块一般有如下3种:
1)Python内置模块
2)第三方模块
3)自定义模块
导入模块的语句如下:
import module1[, module2[,... moduleN]
或
import module1
import module2
...
import moduleN具体使用哪一种方式根据个人习惯而定,导入模块后,模块中的方法或者类可以通过 模块名.方法() 直接调用~
>>> import time
>>> time.time() # time() 为 time模块中的方法
1545832129.4365451
>>> import datetime
>>> datetime.datetime.now() # datetime 为datetime模块中的类
datetime.datetime(2018, 12, 26, 21, 49, 2, 805953)当我们使用 import 语句导入模块时,Python解释器首先会去内置名称空间中寻找,即判断导入的模块是不是内置模块(例如time模块就是Python内置模块),然后再去 sys.path 列表中定义的路径从前往后寻找 .py文件
如下是在个人笔记本上输出的 sys.path列表:
# pycharm中进行输出:
['/Users/baby/PycharmProjects/untitled/module',
'/Users/baby/PycharmProjects/untitled',
'/usr/local/Cellar/python/3.7.1/Frameworks/Python.framework/Versions/3.7/lib/python37.zip',
'/usr/local/Cellar/python/3.7.1/Frameworks/Python.framework/Versions/3.7/lib/python3.7',
'/usr/local/Cellar/python/3.7.1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/lib-dynload', '/usr/local/lib/python3.7/site-packages',
'/Applications/PyCharm.app/Contents/helpers/pycharm_matplotlib_backend']
# 在终端进行输出:
>>> sys.path
['', '/usr/local/Cellar/python/3.7.1/Frameworks/Python.framework/Versions/3.7/lib/python37.zip',
'/usr/local/Cellar/python/3.7.1/Frameworks/Python.framework/Versions/3.7/lib/python3.7',
'/usr/local/Cellar/python/3.7.1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/lib-dynload',
'/usr/local/lib/python3.7/site-packages']➜ ~ ls /usr/local/Cellar/python/3.7.1/Frameworks/Python.framework/Versions/3.7/lib/python3.7
LICENSE.txt fileinput.py re.py
__future__.py fnmatch.py reprlib.py
__phello__.foo.py formatter.py rlcompleter.py
...
...现在我自己编辑了一个模块 sftp,内容如下:
server_ip = '192.168.0.30'
def get_file():
print('ddownload file ...')然后在 main.py文件(与sftp.py在同一个路径下) 中进行导入:
import sftp
在 import sftp 时,Python解释器会首先创建一个新的名称空间,这个名称空间用于存放 sftp 模块中定义的名字,然后在该名称空间中执行 sftp.py 文件。
例如现在在 sftp 模块中添加 print 语句,然后执行 main.py文件:
# sftp.py
server_ip = '192.168.0.30'
def get_file():
print('ddownload file ...')
print('hello ....')
# main.py
import sftp
# 执行 main.py 后会有如下输出:
hello ....import语句 可以理解为定义了一个变量,而该变量就指向对应的名称空间,通过使用这个变量来引用该名称空间中的方法及变量~
import sftp 之后,注意区分新创建的名称空间和当前的名称空间,示例如下:
# sftp.py
server_ip = '192.168.0.30'
def get_file():
print('ddownload file ...')
# main.py
import sftp
server_ip = '1.2.3.4'
print(server_ip)
print(sftp.server_ip)
# 执行 main.py 后会有如下输出:
1.2.3.4
192.168.0.30在导入模块的时候还可以对模块进行重命名,以方便使用;若是当前文件中存在同名的方法或变量,也可以通过这种方式避免冲突~
import datetime as date
date.datetime.now()from import 语法如下:
from modname import name1[, name2[, ... nameN]]import语句的导入会新建一个名称空间,将模块中的名称存放在该名称空间中,而 'from modname import name1, name2' 则会将name1 和 name2 单个导入到当前的名称空间中。既然是导入到当前的名称空间中,那就可以直接拿来使用,前面不需要再添加模块名称。
from datetime import datetime
print(datetime.now()) # 不需要写成 datetime.datetime.now()
若是 from … import 导致了名称重读,则哪一个后定义,就使用哪一个
def foo():
pass
from demo import foo
# 这里引用 foo 函数,会使用 demo 模块中的 foo函数
#############
from demo import foo
def foo():
pass
# 这里引用 foo 函数,会使用 当前文件中的 foo函数简单而言,Python中的包(Package)就是一个目录,里面存放了 .py文件,外加一个 __init__.py。通过目录的方式来组织众多的模块,包就是用来管理和分类模块的。引入包之后,还有一个好处就是 同名的模块可以放在不同的包下,以避免名称冲突~
例如现在有如下3个包,ROOT,pk_1,pk_2: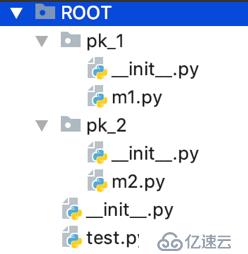
模块m1的全名是:ROOT.pk_1.m1;模块m2的全名则是:ROOT.pk_2.m2 ~
在每一个包目录下,都应该有一个 __init__.py 文件,若这个文件不存在,那么这个目录只是一个目录而不是一个包。__init__.py 文件可以是空文件,也可以有 Python 代码,原则是尽量保持 __init__.py 文件的精简~
导入包的语句如下:
import package
# 或引入包下的某一个模块
from package import moduleimport package 或者 from package import module 都会执行package 包下的 __init__ 文件
现在有如下目录结构:
├─ROOT
│ ├─pk_1
│ │ ├─__init__.py
│ │ ├─m1.py
│ ├─pk_2
│ │ ├─__init__.py
│ │ └─m2.py
│ ├─__init__.py
│ ├─test.pypk_1 和 pk_2 包中的 __init__.py 文件都为空,ROOT包下的 test.py 想要使用 pk_1 包下 m1模块中的方法,可以使用如下语句:
from pk_1 import m1
m1.fun_1() # fun_1() 为m1模块中的方法但是使用如下语句,就会抛出异常:
from pk_1 import *
m1.fun_1()
# 异常信息:
NameError: name 'm1' is not defined
##############################
import pk_1
pk_1.m1.fun_1()
# 异常信息:
AttributeError: module 'pk_1' has no attribute 'm1'这时候可以在 pk_1 包中的__init__.py 中 进行 包提升(在包中提升导入权限),pk_1 包的 __init__.py 文件内容如下:
from pk_1.m1 import fun_1然后在 test.py 文件中可以直接通过包名引入方法:
# 1)
from pk_1 import fun_1 # 或 from pk_1 import *
fun_1()
# 2)
import pk_1
pk_1.fun_1()
这个就是 包中 __init__.py 文件存在的意义,可以将相关的导入语句 或 提升导入权限的语句 写在 __init__.py文件中,这样使用者就不需要了解包中的内部结构,可以直接通过包名 调用该包(package)中某个模块的方法~
还可以在 包中 __init__.py 文件中使用 __all__ 列出需要导入的模块,例如在 pk_1 包中的 __init__.py文件中添加 __all__ 变量:
__all__ = ['m2']然后在 test.py 文件中就可以使用 from pk_2 import * 一次性导入 __all__变量中列出的模块:
from pk_2 import *
m2.fun_2()若是 pk_2 包的 __init__.py 文件已经对 fun_2 方法做了提升:
# pk_2 包的 \_\_init\_\_.py 内容
from pk_2.m2 import fun_2这样在 test.py 中 import * 后可直接使用该方法:
from pk_2 import *
fun_2()注意:当 __init__.py 中定义了 __all__ 变量时,import * 只会导入 __all__中列出的模块
现在有如下目录结构:
├─log
│ ├─util
│ │ ├─__init__.py
│ │ ├─a.py
│ │ ├─b.py
│ ├─__init__.py
│ ├─test.py在test中引入 a模块:
from util import a在 a 模块中又引入了 b 模块:
import b这样的话在执行 test 文件时就会报错,ModuleNotFoundError: No module named 'b',说无法找到b模块。
这是因为 在执行 test 时,sys.path 中的路径不包含 util 下的路径,所以在 a.py 文件中 import b 模块时就会报错(若是直接执行的是 a.py 文件就不会有问题)。在 a模块 中引入 b 模块的正确的写法是:
from util import b当然这个时候 a.py 文件就不能再单独运行了,运行时就会报错
Tip:在 a.py 文件中 使用 "from util import b" 导入模块 b,这个时候若是直接执行 a.py 文件就会报错,因为 a.py 文件本身就位于util路径下,sys.path(执行 a.py 时的sys.path)中有util路径,但是 'from util' 是找不到util的,util 位于 sys.path 的某个路径下时,'from util' 才能找到util ~
若是现在 主执行文件 本身就位于项目目录下的某个包中,要引入其他包中的模块,就需要通过在 os.path 中添加路径来实现: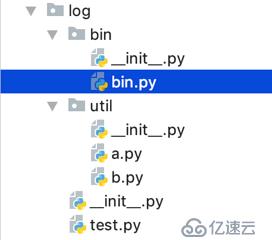
现在执行文件是 bin 目录下的 bin.py,在 bin.py 中要导入 util包 中的 a模块 和 b模块,为了保证通用性,可以使用如下方式获取 log 路径,并且添加到os.path中:
import sys, os
sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from util import a__name__ 与 __file__一样,是一个内置变量,这个变量记录了当前文件(使用 __name__ 变量的文件)是作为模块运行还是主执行文件~
示例:
a.py 文件内容
print(__name__)
# 直接执行 a.py 文件,输出:
# __main__
现在 在b.py文件中 import a。b.py 文件内容如下:
import a
# 现在运行 b.py 文件(这个过程会运行 a.py 文件),输出内容:
# a ## 即 a 的模块名称这个功能经常被用于代码的调试:
if __name__=='__main__':
pass可以将调试的代码写在 if 语句中,用于调试当前py文件中的代码,因为直接运行当前文件, __name__ 变量的值就是 __main__。当外部模块调用的时候,就不会执行 if 语句中的内容,因为 外部模块调用 __name__ 变量的值 为模块名称~
.................^_^
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





