这篇文章主要介绍“如何理解Python数据集与可视化”,在日常操作中,相信很多人在如何理解Python数据集与可视化问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”如何理解Python数据集与可视化”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
你的任务是提高销售团队的绩效。在我们假设的情况下,潜在客户有相当自发的需求。当这种情况发生时,您的销售团队会在系统中放置一个订单线索。然后,您的销售代表会设法安排一次会议,会议将在订单线索被注意到的时候举行。有时在前,有时在后。你的销售代表有一个把会议和餐费结合起来的开支预算。销售代表花费他们的成本,并将发票交给会计团队处理。在潜在客户决定是否接受您的报价后,销售代表会跟踪订单线索是否转化为销售。
对于分析,您可以访问以下三个数据源:
订单线索(包含所有订单线索和转换信息)
销售团队(包括公司和负责的销售代表)
发票(提供发票和参与者的信息)
需要安装标准库,此外,通过使用以下命令,在你的Notebook上安装seaborn.
!pip install seaborn
您可以按照上周的说明下载并合并数据,也可以从此处下载文件并将其加载到 Notebook中。



总转化率发展:
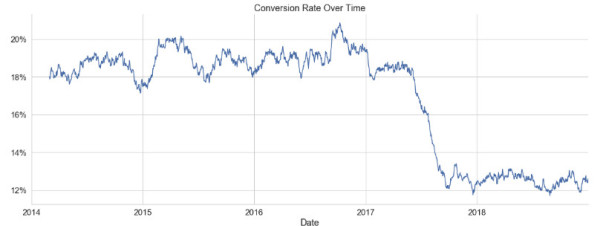
事情似乎在2017年初走下坡路。经过与首席销售官核实,发现大约在那个时候有一个竞争对手进入了这个市场。很高兴知道,但我们现在无能为力。
_ = order_leads.set_index(pd.DatetimeIndex(order_leads.Date)).groupby( pd.Grouper(freq='D') )['Converted'].mean() ax = _.rolling(60).mean().plot(figsize=(20,7),title='Conversion Rate Over Time') vals = ax.get_yticks() ax.set_yticklabels(['{:,.0f}%'.format(x*100) for x in vals]) sns.despine()鸿蒙官方战略合作共建——HarmonyOS技术社区
我们使用下划线_作为临时变量。对于以后不再使用的一次性变量,我通常会这样做。
我们在order_leads.Date上使用了pd.DateTimeIndex并将结果设置为索引,这使我们能够
使用pd.Grouped(freq ='D')按天对数据进行分组。 或者,您可以将频率更改为W,M,Q或Y(每周,每月,每季度或每年)
我们计算每天“转换”的平均值,这将给出当天订单的换算率。
我们使用.roll(60)和.mean()来获得60天的滚动平均值。
然后我们格式化yticklables,使它们显示一个百分号。
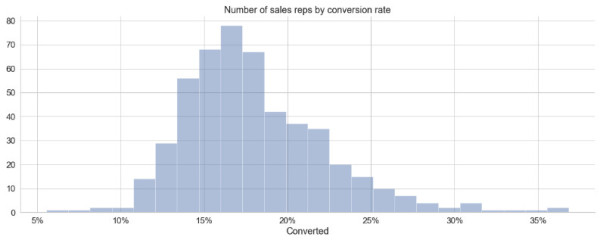
各个销售代表之间似乎存在很大的差异。 让我们对此进行更多调查。
就所使用的功能而言,这里没有太多新内容。 但是请注意我们如何使用sns.distplot将数据绘制到轴上。
如果我们回顾sales_team数据,我们会记住并非所有的销售代表都拥有相同数量的客户,这肯定会产生影响! 让我们检查。
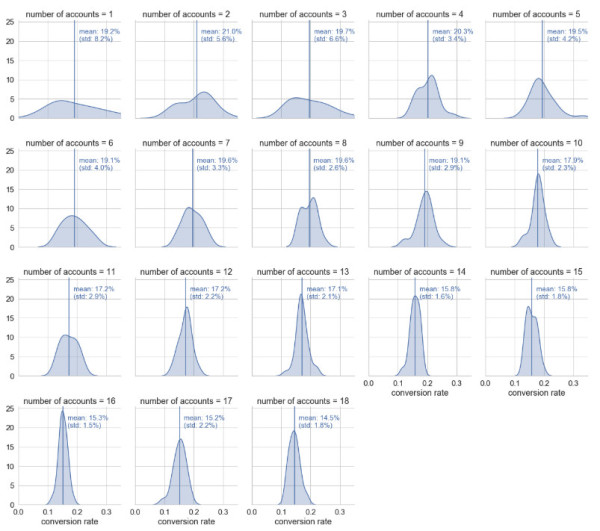
我们可以看到,转换率数字似乎与分配给销售代表的帐户数量成反比。 那些降低的转化率是有道理的。 毕竟,代表拥有的帐户越多,他可以花在每个人身上的时间就越少。
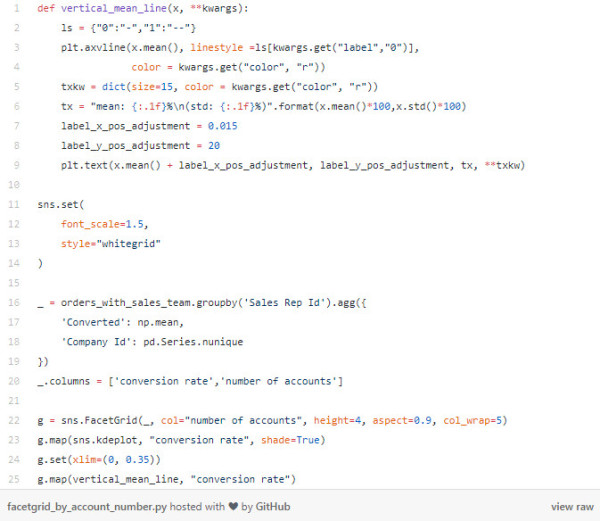
在这里,我们首先创建一个辅助函数,该函数将垂直线映射到每个子图中,并用数据的均值和标准差注释该线。然后我们设置一些seaborn绘图默认值,例如较大的font_scale和whitegrid设置为样式。

看来我们已经确定了用餐的日期和时间,让我们快速了解一下时间分布:
invoices['Date of Meal'] = pd.to_datetime(invoices['Date of Meal']) invoices['Date of Meal'].dt.time.value_counts().sort_index()
out: 07:00:00 5536 08:00:00 5613 09:00:00 5473 12:00:00 5614 13:00:00 5412 14:00:00 5633 20:00:00 5528 21:00:00 5534 22:00:00 5647
总结:
invoices['Type of Meal'] = pd.cut( invoices['Date of Meal'].dt.hour, bins=[0,10,15,24], labels=['breakfast','lunch','dinner'] )
注意,这里我们是如何使用pd.cut为数字数据分配类别的,这很有意义,因为毕竟,早餐是在8点还是9点开始,都没有关系。
另外,请注意我们如何使用.dt.hour,我们只能这样做,因为我们将
invoices['Date of Meal']转换为之前的日期时间。 .dt是所谓的访问器,其中有三个cat,str和dt。 如果您的数据类型正确,则可以使用这些访问器及其方法进行直接操作(计算有效且简洁)。不幸的是,invoices ['Participants']是一个字符串,我们必须首先将其转换为合法的JSON,以便我们 可以提取参与者的数量。
def replace(x): return x.replace("\n ",",").replace("' '","','").replace("'",'"') invoices['Participants'] = invoices['Participants'].apply(lambda x: replace(x)) invoices['Number Participants'] = invoices['Participants'].apply(lambda x: len(json.loads(x)))现在,我们合并数据。 为此,我们首先将公司ID上的所有发票左连接到order_leads。 但是,合并数据会导致所有餐点都加入所有订单。 也有古老的饭菜,以最近的订单。 为了缓解这种情况,我们计算了进餐和点餐之间的时间差,并且仅考虑订单周围五天的进餐。
仍然有一些订单已分配多餐。 当同时有两个订单和两餐时,可能会发生这种情况。 然后,两餐将分配给两个订单线索。 要删除这些重复项,我们仅使餐点最接近该订单。
我创建了一个绘图栏功能,其中已经包含一些样式。 通过该功能进行绘图可以使目视检查更快。 我们将在一秒钟内使用它。
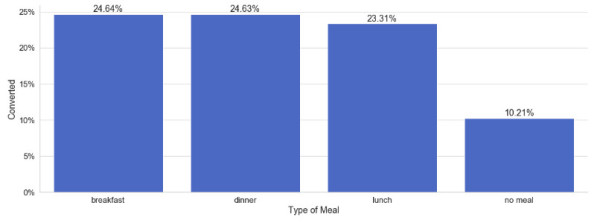
orders_with_meals['Type of Meal'].fillna('no meal',inplace=True) _ = orders_with_meals.groupby('Type of Meal').agg({'Converted': np.mean}) plot_bars(_,x_col='Type of Meal',y_col='Converted')哇! 用餐相关的订单与不用餐相关的订单之间的转换率差异非常大。 不过,看起来午餐的转化率略低于晚餐或早餐。
时间的影响(即进餐之前或之后进餐):
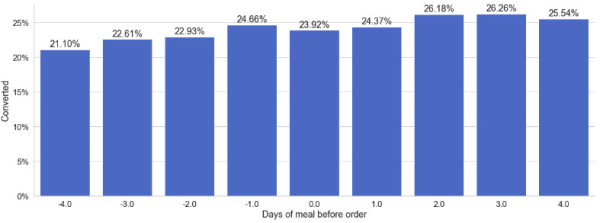
_ = orders_with_meals.groupby(['Days of meal before order']).agg( {'Converted': np.mean} ) plot_bars(data=_,x_col='Days of meal before order',y_col='Converted')“订购前用餐天数”为负数表示用餐是在订单线索输入之后进行的。我们可以看到,如果膳食在订单线索进入之前发生,则对转化率似乎有积极影响。 订单的先验知识似乎在这里给我们的销售代表带来了优势。
结合所有:
现在,我们将使用热图同时可视化数据的多个维度。 为此,首先创建一个辅助函数。
然后,我们使用一些最终数据进行争辩,以额外考虑餐食价格与订单价值的关系,并将交货时间分配到“订购前”,“订购前后”,“订购后”,而不是从负4到正4的天数,因为这在解释方面有些繁琐。
运行以下代码片段将产生多维热图。
draw_heatmap( data=data, outer_row='Timing of Meal', outer_col='Type of Meal', inner_row='Meal Price / Order Value', inner_col='Number Participants', values='Converted' )
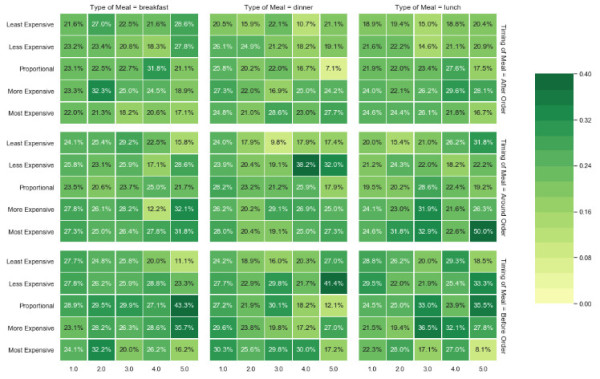
该热图当然很漂亮,尽管起初有点难读。 因此,让我们来看一下。 图表总结了4个不同维度的影响:
用餐时间:订购后,订购前后,订购前(外排)
用餐类型:早餐,晚餐,午餐(外栏)
餐单价格:最低价格,最低价格,比例价格,最高价格,最高价格(内排)
参加人数:1,2,3,4,5(内栏)
当然,图表底部的颜色似乎更深/更高,这表明:
在点餐之前用餐时,转化率会更高
当只有一名参与者时,晚餐转化率似乎更高
与订单价值相比,看起来更昂贵的餐食对转化率有积极影响
结果:
销售代表的帐户不要超过9个(转化率会迅速下降)
确保每个订单线索都伴随有会议/进餐(因为这会使转换率翻倍当只有一位员工来访时,晚餐最有效
您的销售代表应支付的餐费约为订单金额的8%至10%
时间是关键,理想情况下,您的销售代表应尽早知道即将达成交易。
单击此处查看代码: GitHub Repo / Jupyter Notebook
备注为热图:
要解决可能出现的格式错误,可以先卸载(然后在终端中必须这样做),然后运行以下命令,将matplotlib降级到3.1.0版:
!pip install matplotlib==3.1.0
到此,关于“如何理解Python数据集与可视化”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





