字符串处理
1,字符串分割
(a)split 方法
str1 = "http:// www.qwe, qwe; qwe,qwe"
import re
re.split(r'[,;\s]\s*',str1)
>>> ['http://', 'www.qwe', 'qwe', 'qwe', 'qwe']一般简单的可以使用 str.split("xxx")进行分割。但是re.split( ) 用起来更加的灵活。
2, 字符串开头和结尾
(a) str.startswith( )/str.endswith( )
filename = "http://zaixiankefu.txt"
filename.endswith(".txt")
>>>True
filename.startswith("http:")
>>>True
# startswith( )和 endswith( )可以接收一个元组数据,注意是元组。
choice = (".txt",".avi")
filename.endswith(choice)
>>>True(b) 也可以使用切片来判断
if filename[:4] == "http" and filename[-4:] == ".txt":
return True
3,字符串匹配
简单的就是str.startswith( ),str.endswith( ),str.find(),前两种返回时bool 值,find是返回第一次匹配的下标值。
使用正则进行匹配(更多方法参考正则文档)。
(a)re.match( )
match 总是从字符串开始去匹配 。如匹配则返回一个匹配对象,失败返回None。
str1 = "2018/12/20"
import re
re.match(r'\d*/',str1)
>>> <_sre.SRE_Match object; span=(0, 5), match='2018/'>(b) re.search( )
search 会匹配整个字符串。如匹配则返回一个匹配对象,失败返回None。
re.search(r'/\d*/',str1)
>>> <_sre.SRE_Match object; span=(4, 8), match='/12/'>(c) re.findall( )
如果返回的值过多,可以使用 finditer( )来替代。
str1 = "www.baidu.com"
import re
re.finditer(r'w',str1) #会返回一个可迭代对象
>>> <callable_iterator at 0x5be230>忽略大小写进行匹配
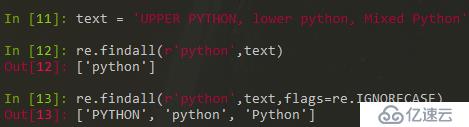
4,字符串替换
简单的替换可以使用 str.replace(old,new) 进行操作。
re.sub( )可以更加灵活处理。
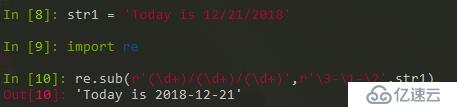
反斜杠数字,例如 \3 指向前面模式的捕获组号。
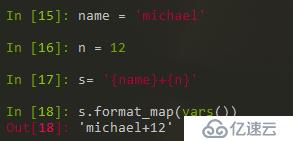
5,字符串中插入变量
使用 format 和 format_map( ) + vars( )来进行处理。
vars( )实现的是在变量域中找到所需的变量。
缺点是,变量缺失后,会直接报错。如果变量未找到

可以使用类进行包装。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



