жҖҺд№Ҳз”ЁPythonиҝӣиЎҢеӨҡе…ғзәҝжҖ§еӣһеҪ’
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңжҖҺд№Ҳз”ЁPythonиҝӣиЎҢеӨҡе…ғзәҝжҖ§еӣһеҪ’вҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
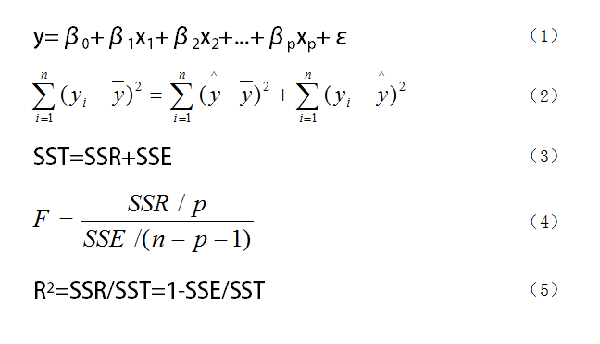
еӣҫ1. еӨҡе…ғеӣһеҪ’жЁЎеһӢдёӯиҰҒз”ЁеҲ°зҡ„е…¬ејҸ
еҰӮеӣҫ1жүҖзӨәпјҢжҲ‘们еҒҮи®ҫйҡҸжңәеҸҳйҮҸyдёҺдёҖиҲ¬еҸҳйҮҸx1гҖҒx2гҖҒ...гҖҒxpд№Ӣй—ҙзәҝжҖ§еӣһеҪ’жЁЎеһӢдёәпјҲ1пјүејҸпјҢејҸдёӯyдёәеӣ еҸҳйҮҸпјҢx1гҖҒx2гҖҒ...гҖҒxpжҳҜиҮӘеҸҳйҮҸпјҢβ1гҖҒβ2гҖҒ...гҖҒβpжҳҜеӣһеҪ’зі»ж•°пјҢβ0жҳҜеӣһеҪ’еёёж•°гҖӮеҜ№дәҺдёҖдёӘе®һйҷ…й—®йўҳпјҢеҰӮжһңжҲ‘们иҺ·еҫ—nз»„и§ӮжөӢж•°жҚ®пјҲxi1пјҢxi2пјҢ...пјҢxipпјӣyпјүпјҲi = 1пјҢ2пјҢ...пјҢnпјүпјҢеҲҷжҲ‘们еҸҜд»ҘжҠҠиҝҷnз»„и§ӮжөӢж•°жҚ®еҶҷжҲҗзҹ©йҳөеҪўејҸy=Xβ+εгҖӮ
еңЁжұӮеҮәдәҶеӣһеҪ’ж–№зЁӢд№ӢеҗҺпјҢжҲ‘们еҫҖеҫҖиҝҳиҰҒеҜ№еӣһеҪ’ж–№зЁӢиҝӣиЎҢжҳҫи‘—жҖ§жЈҖйӘҢгҖӮиҝҷйҮҢзҡ„жҳҫи‘—жҖ§жЈҖйӘҢдё»иҰҒеҢ…жӢ¬дёүйғЁеҲҶгҖӮ第дёҖдёӘжҳҜFжЈҖйӘҢпјҢд№ҹе°ұжҳҜжЈҖйӘҢиҮӘеҸҳйҮҸx1гҖҒx2гҖҒ...гҖҒxpд»Һж•ҙдҪ“дёҠеҜ№yжҳҜеҗҰжңүжҳҺжҳҫзҡ„еҪұе“ҚпјҢдё»иҰҒз”ЁеҲ°пјҲ2пјүгҖҒпјҲ3пјүгҖҒпјҲ4пјүејҸпјҢе…¶дёӯпјҲ2пјүе’ҢпјҲ3пјүејҸжҳҜдёҖдёӘејҸеӯҗпјҢдёҚиҝҮжҳҜз”ЁдёҚеҗҢз¬ҰеҸ·иЎЁзӨәпјӣ第дәҢдёӘжҳҜtжЈҖйӘҢпјҢжҳҜеҜ№жҜҸдёӘиҮӘеҸҳйҮҸиҝӣиЎҢжҳҫи‘—жҖ§жЈҖйӘҢпјҢе°ұжҳҜзңӢжҜҸдёӘиҮӘеҸҳйҮҸжҳҜеҗҰеҜ№yжңүжҳҫи‘—жҖ§еҪұе“ҚпјҢиҝҷе’ҢеүҚйқўд»Һж•ҙдҪ“дёҠжЈҖйӘҢиҝҳжҳҜжңүеҢәеҲ«зҡ„пјӣ第дёүдёӘжҳҜжӢҹеҗҲдјҳеәҰпјҢд№ҹе°ұжҳҜR2пјҢе…¶еҸ–еҖјеңЁ0еҲ°1д№Ӣй—ҙпјҢи¶ҠжҺҘиҝ‘1пјҢиЎЁжҳҺеӣһеҪ’жӢҹеҗҲзҡ„ж•Ҳжһңи¶ҠеҘҪпјҢи¶ҠжҺҘиҝ‘дәҺ0пјҢеҲҷж•Ҳжһңи¶Ҡе·®пјҢдҪҶRеҸӘиғҪзӣҙи§ӮеҸҚжҳ жӢҹеҗҲзҡ„ж•ҲжһңпјҢдёҚиғҪд»ЈжӣҝFжЈҖйӘҢдҪңдёәдёҘж јзҡ„жҳҫи‘—жҖ§жЈҖйӘҢгҖӮ
дёҠйқўжҳҜеӨҡе…ғзәҝжҖ§еӣһеҪ’зҡ„дёҖдёӘз®ҖеҚ•д»Ӣз»ҚпјҢе…¶иҜҰз»ҶеҺҹзҗҶеҶ…е®№иҫғеӨҡпјҢжңүе…ҙи¶Јзҡ„иҜ»иҖ…еҸҜд»ҘеҺ»жҹҘйҳ…дёҖдёӢзӣёе…іж–ҮзҢ®пјҢиҝҷйҮҢдёҚеҶҚиөҳиҝ°пјҢеҸӘйҮҚзӮ№и®Іи§ЈеҰӮдҪ•з”ЁpythonиҝӣиЎҢеҲҶжһҗгҖӮдёӢйқўжҲ‘们иҝҳжҳҜз”Ёд»Јз ҒжқҘеұ•зӨәдёҖдёӢеӨҡе…ғзәҝжҖ§еӣһеҪ’зҡ„еҲҶжһҗиҝҮзЁӢгҖӮ
иҝҷйҮҢжҲ‘们用еҲ°зҡ„ж•°жҚ®жқҘжәҗдәҺ2013е№ҙгҖҠдёӯеӣҪз»ҹи®Ўе№ҙйүҙгҖӢпјҢж•°жҚ®д»Ҙеұ…ж°‘зҡ„ж¶Ҳиҙ№жҖ§ж”ҜеҮәдёәеӣ еҸҳйҮҸyпјҢе…¶д»–9дёӘеҸҳйҮҸдёәиҮӘеҸҳйҮҸпјҢе…¶дёӯx1жҳҜеұ…ж°‘зҡ„йЈҹе“ҒиҠұиҙ№пјҢx2жҳҜиЎЈзқҖиҠұиҙ№пјҢx3жҳҜеұ…дҪҸиҠұиҙ№пјҢx4жҳҜеҢ»з–—дҝқеҒҘиҠұиҙ№пјҢx5жҳҜж–Үж•ҷеЁұд№җиҠұиҙ№пјҢx6жҳҜиҒҢе·Ҙе№іеқҮе·Ҙиө„пјҢx7жҳҜең°еҢәзҡ„дәәеқҮGDPпјҢx8жҳҜең°еҢәзҡ„ж¶Ҳиҙ№д»·ж јжҢҮж•°пјҢx9жҳҜең°еҢәзҡ„еӨұдёҡзҺҮгҖӮеңЁиҝҷжүҖжңүеҸҳйҮҸйҮҢйқўпјҢx1иҮіx7д»ҘеҸҠyзҡ„еҚ•дҪҚжҳҜе…ғпјҢx9жҳҜзҷҫеҲҶж•°пјҢx8жІЎжңүеҚ•дҪҚпјҢеӣ дёәе…¶жҳҜж¶Ҳиҙ№д»·ж јжҢҮж•°гҖӮж•°жҚ®зҡ„жҖ»дҪ“еӨ§е°Ҹдёә31x10пјҢеҚі31иЎҢгҖҒ10еҲ—пјҢеӨ§дҪ“еҶ…е®№еҰӮеӣҫ2жүҖзӨәгҖӮ
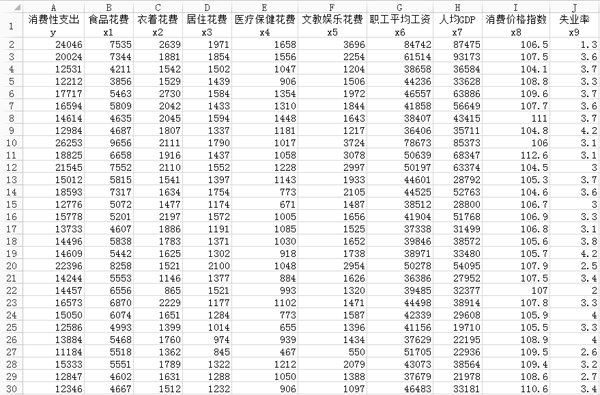
еӣҫ2. ж•°жҚ®йӣҶйғЁеҲҶеҶ…е®№
йҰ–е…ҲиҝҳжҳҜеҜје…ҘйңҖиҰҒзҡ„еә“гҖӮ
import numpy as np import pandas as pd import statsmodels.api as sm
жҺҘдёӢжқҘжҳҜж•°жҚ®йў„еӨ„зҗҶпјҢеӣ дёәеҺҹж•°жҚ®зҡ„еҲ—ж ҮеӨӘй•ҝпјҢжҲ‘们иҰҒеӨ„зҗҶдёҖдёӢпјҢеҺ»йҷӨе…¶дёӯзҡ„дёӯж–ҮпјҢеҸӘз•ҷдёӢиӢұж–ҮеҗҚз§°гҖӮ
file = r'C:\Users\data.xlsx' data = pd.read_excel(file) data.columns = ['y', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x9']
然еҗҺжҲ‘们е°ұејҖе§Ӣз”ҹжҲҗеӨҡе…ғзәҝжҖ§жЁЎеһӢпјҢд»Јз ҒеҰӮдёӢгҖӮ
x = sm.add_constant(data.iloc[:,1:]) #з”ҹжҲҗиҮӘеҸҳйҮҸ y = data['y'] #з”ҹжҲҗеӣ еҸҳйҮҸ model = sm.OLS(y, x) #з”ҹжҲҗжЁЎеһӢ result = model.fit() #жЁЎеһӢжӢҹеҗҲ result.summary() #жЁЎеһӢжҸҸиҝ°
еҫҲжҳҺжҳҫпјҢиҝҷйҮҢзҡ„иҮӘеҸҳйҮҸжҳҜжҢҮx1еҲ°x9иҝҷ9дёӘиҮӘеҸҳйҮҸпјҢд»Јз Ғdata.iloc[:,1:]е°ұжҳҜеҺ»жҺүеҺҹж•°жҚ®дёӯ第дёҖеҲ—пјҢд№ҹе°ұжҳҜyйӮЈдёҖеҲ—зҡ„ж•°жҚ®пјҢresult.summary()еҲҷжҳҜз”ҹжҲҗдёҖд»Ҫз»“жһңжҸҸиҝ°пјҢе…¶еҶ…е®№еҰӮеӣҫ3жүҖзӨәгҖӮ
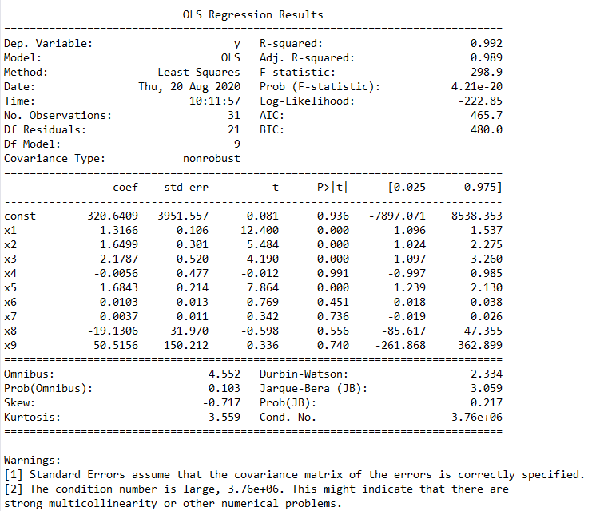
еӣҫ3. еҢ…еҗ«жүҖжңүиҮӘеҸҳйҮҸзҡ„еӣһеҪ’з»“жһң
еңЁиҝҷдёӘз»“жһңдёӯпјҢжҲ‘们主иҰҒзңӢвҖңcoefвҖқгҖҒвҖңtвҖқе’ҢвҖңP>|t|вҖқиҝҷдёүеҲ—гҖӮcoefе°ұжҳҜеүҚйқўиҜҙиҝҮзҡ„еӣһеҪ’зі»ж•°пјҢconstиҝҷдёӘеҖје°ұжҳҜеӣһеҪ’еёёж•°пјҢжүҖд»ҘжҲ‘们еҫ—еҲ°зҡ„иҝҷдёӘеӣһеҪ’жЁЎеһӢе°ұжҳҜy = 320.640948 + 1.316588 x1 + 1.649859 x2 + 2.17866 x3 - 0.005609 x4 + 1.684283 x5 + 0.01032 x6 + 0.003655 x7 -19.130576 x8 + 50.515575 x9гҖӮиҖҢвҖңtвҖқе’ҢвҖңP>|t|вҖқиҝҷдёӨеҲ—жҳҜзӯүд»·зҡ„пјҢдҪҝз”Ёж—¶йҖүжӢ©е…¶дёӯдёҖдёӘе°ұиЎҢпјҢе…¶дё»иҰҒз”ЁжқҘеҲӨж–ӯжҜҸдёӘиҮӘеҸҳйҮҸе’Ңyзҡ„зәҝжҖ§жҳҫи‘—е…ізі»пјҢеҗҺйқўжҲ‘们дјҡи®ІеҲ°гҖӮд»ҺеӣҫдёӯиҝҳеҸҜд»ҘзңӢеҮәпјҢProb (F-statistic)дёә4.21e-20пјҢиҝҷдёӘеҖје°ұжҳҜжҲ‘们常用зҡ„PеҖјпјҢе…¶жҺҘиҝ‘дәҺйӣ¶пјҢиҜҙжҳҺжҲ‘们зҡ„еӨҡе…ғзәҝжҖ§ж–№зЁӢжҳҜжҳҫи‘—зҡ„пјҢд№ҹе°ұжҳҜyдёҺx1гҖҒx2гҖҒ...гҖҒx9жңүзқҖжҳҫи‘—зҡ„зәҝжҖ§е…ізі»пјҢиҖҢR-squaredжҳҜ0.992пјҢд№ҹиҜҙжҳҺиҝҷдёӘзәҝжҖ§е…ізі»жҜ”иҫғжҳҫи‘—гҖӮзҗҶи®әдёҠпјҢиҝҷдёӘеӨҡе…ғзәҝжҖ§ж–№зЁӢе·Із»ҸжұӮеҮәжқҘдәҶпјҢиҖҢдё”ж•ҲжһңиҝҳдёҚй”ҷпјҢжҲ‘们е°ұеҸҜд»Ҙз”Ёе…¶иҝӣиЎҢйў„жөӢдәҶпјҢдҪҶиҝҷйҮҢжҲ‘们иҝҳжҳҜиҰҒиҝӣиЎҢжӣҙж·ұдёҖжӯҘзҡ„жҺўи®ЁгҖӮеүҚйқўиҜҙиҝҮпјҢyдёҺx1гҖҒx2гҖҒ...гҖҒx9жңүзқҖжҳҫи‘—зҡ„зәҝжҖ§е…ізі»пјҢиҝҷйҮҢиҰҒжіЁж„Ҹx1еҲ°x9иҝҷ9дёӘеҸҳйҮҸиў«зңӢдҪңжҳҜдёҖдёӘж•ҙдҪ“пјҢyдёҺиҝҷдёӘж•ҙдҪ“жңүжҳҫи‘—зҡ„зәҝжҖ§е…ізі»пјҢдҪҶдёҚд»ЈиЎЁyдёҺе…¶дёӯзҡ„жҜҸдёӘиҮӘеҸҳйҮҸйғҪжңүжҳҫи‘—зҡ„зәҝжҖ§е…ізі»пјҢжҲ‘们еңЁиҝҷйҮҢиҰҒжүҫеҮәйӮЈдәӣдёҺyзҡ„зәҝжҖ§е…ізі»дёҚжҳҫи‘—зҡ„иҮӘеҸҳйҮҸпјҢ然еҗҺжҠҠе®ғ们еү”йҷӨпјҢеҸӘз•ҷдёӢе…ізі»жҳҫи‘—зҡ„пјҢиҝҷе°ұжҳҜеүҚйқўиҜҙиҝҮзҡ„tжЈҖйӘҢпјҢtжЈҖйӘҢзҡ„еҺҹзҗҶеҶ…е®№жңүдәӣеӨҚжқӮпјҢжңүе…ҙи¶Јзҡ„иҜ»иҖ…еҸҜд»ҘиҮӘиЎҢжҹҘйҳ…иө„ж–ҷпјҢиҝҷйҮҢдёҚеҶҚиөҳиҝ°гҖӮжҲ‘们еҸҜд»ҘйҖҡиҝҮеӣҫ3дёӯвҖңP>|t|вҖқиҝҷдёҖеҲ—жқҘеҲӨж–ӯпјҢиҝҷдёҖеҲ—дёӯжҲ‘们еҸҜд»ҘйҖүе®ҡдёҖдёӘйҳҲеҖјпјҢжҜ”еҰӮз»ҹи®ЎеӯҰеёёз”Ёзҡ„е°ұжҳҜ0.05гҖҒ0.02жҲ–0.01пјҢиҝҷйҮҢжҲ‘们е°ұз”Ё0.05пјҢеҮЎжҳҜP>|t|иҝҷеҲ—дёӯж•°еҖјеӨ§дәҺ0.05зҡ„иҮӘеҸҳйҮҸпјҢжҲ‘们йғҪжҠҠе®ғеү”йҷӨжҺүпјҢиҝҷдәӣе°ұжҳҜе’ҢyзәҝжҖ§е…ізі»дёҚжҳҫи‘—зҡ„иҮӘеҸҳйҮҸпјҢжүҖд»ҘйғҪиҲҚеҺ»пјҢиҜ·жіЁж„ҸиҝҷйҮҢжҢҮзҡ„иҮӘеҸҳйҮҸжҳҜx1еҲ°x9пјҢдёҚеҢ…жӢ¬еӣҫ3дёӯconstиҝҷдёӘеҖјгҖӮдҪҶжҳҜиҝҷйҮҢжңүдёҖдёӘеҺҹеҲҷпјҢе°ұжҳҜдёҖж¬ЎеҸӘиғҪеү”йҷӨдёҖдёӘпјҢеү”йҷӨзҡ„иҝҷдёӘеҫҖеҫҖжҳҜPеҖјжңҖеӨ§зҡ„йӮЈдёӘпјҢжҜ”еҰӮеӣҫ3дёӯPеҖјжңҖеӨ§зҡ„жҳҜx4пјҢйӮЈд№Ҳе°ұжҠҠе®ғеү”йҷӨжҺүпјҢ然еҗҺеҶҚз”Ёеү©дёӢзҡ„x1гҖҒx2гҖҒx3гҖҒx5гҖҒx6гҖҒx7гҖҒx8гҖҒx9жқҘйҮҚеӨҚдёҠиҝ°е»әжЁЎиҝҮзЁӢпјҢеҶҚжүҫеҮәPеҖјжңҖеӨ§зҡ„йӮЈдёӘиҮӘеҸҳйҮҸпјҢжҠҠе®ғеү”йҷӨпјҢеҰӮжӯӨйҮҚеӨҚиҝҷдёӘиҝҮзЁӢпјҢзӣҙеҲ°жүҖжңүPеҖјйғҪе°ҸдәҺзӯүдәҺ0.05пјҢеү©дёӢзҡ„иҝҷдәӣиҮӘеҸҳйҮҸе°ұжҳҜжҲ‘们йңҖиҰҒзҡ„иҮӘеҸҳйҮҸпјҢиҝҷдәӣиҮӘеҸҳйҮҸе’Ңyзҡ„зәҝжҖ§е…ізі»йғҪжҜ”иҫғжҳҫи‘—пјҢжҲ‘们иҰҒз”ЁиҝҷдәӣиҮӘеҸҳйҮҸжқҘиҝӣиЎҢе»әжЁЎгҖӮ
жҲ‘们еҸҜд»Ҙе°ҶдёҠиҝ°иҝҮзЁӢеҶҷжҲҗдёҖдёӘеҮҪж•°пјҢе‘ҪеҗҚдёәlooperпјҢд»Јз ҒеҰӮдёӢгҖӮ
def looper(limit): cols = ['x1', 'x2', 'x3', 'x5', 'x6', 'x7', 'x8', 'x9'] for i in range(len(cols)): datadata1 = data[cols] x = sm.add_constant(data1) #з”ҹжҲҗиҮӘеҸҳйҮҸ y = data['y'] #з”ҹжҲҗеӣ еҸҳйҮҸ model = sm.OLS(y, x) #з”ҹжҲҗжЁЎеһӢ result = model.fit() #жЁЎеһӢжӢҹеҗҲ pvalues = result.pvalues #еҫ—еҲ°з»“жһңдёӯжүҖжңүPеҖј pvalues.drop('const',inplace=True) #жҠҠconstеҸ–еҫ— pmax = max(pvalues) #йҖүеҮәжңҖеӨ§зҡ„PеҖј if pmax>limit: ind = pvalues.idxmax() #жүҫеҮәжңҖеӨ§PеҖјзҡ„index cols.remove(ind) #жҠҠиҝҷдёӘindexд»ҺcolsдёӯеҲ йҷӨ else: return result result = looper(0.05) result.summary()е…¶з»“жһңеҰӮеӣҫ4жүҖзӨәгҖӮд»Һз»“жһңдёӯеҸҜд»ҘзңӢеҲ°жңҖеҗҺеү©дёӢзҡ„жңүж•ҲеҸҳйҮҸдёәx1гҖҒx2гҖҒx3е’Ңx5пјҢжҲ‘们еҫ—еҲ°зҡ„еӨҡе…ғзәҝжҖ§жЁЎеһӢдёәy = -1694.6269 + 1.3642 x1 + 1.7679 x2 + 2.2894 x3 + 1.7424 x5пјҢиҝҷдёӘе°ұжҳҜжҲ‘们жңҖз»ҲиҰҒз”ЁеҲ°зҡ„жңүж•Ҳзҡ„еӨҡе…ғзәҝжҖ§жЁЎеһӢгҖӮ
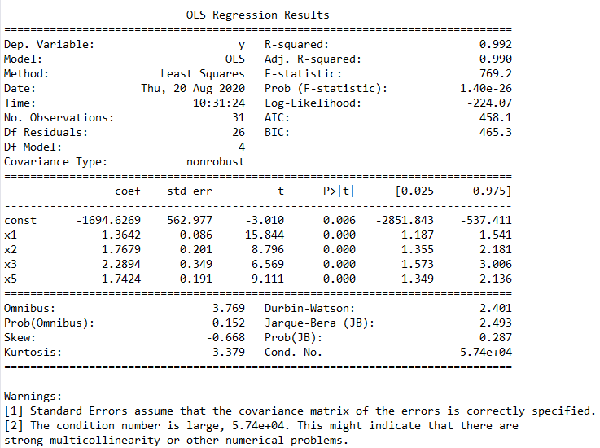
еӣҫ4. еү”йҷӨж— ж•ҲеҸҳйҮҸеҗҺзҡ„еӣһеҪ’жЁЎеһӢ
йӮЈд№Ҳй—®йўҳжқҘдәҶпјҢеүҚйқўжҲ‘们еҫ—еҲ°зҡ„еҢ…еҗ«жүҖжңүиҮӘеҸҳйҮҸзҡ„еӨҡе…ғзәҝжҖ§жЁЎеһӢе’ҢиҝҷдёӘеү”йҷӨйғЁеҲҶеҸҳйҮҸзҡ„жЁЎеһӢпјҢжҲ‘们иҰҒйҖүжӢ©е“ӘдёҖдёӘпјҢжҜ•з«ҹ第дёҖдёӘжЁЎеһӢзҡ„ж•ҙдҪ“зәҝжҖ§ж•Ҳжһңд№ҹжҢәжҳҫи‘—пјҢдҫқжҚ®з¬”иҖ…зҡ„з»ҸйӘҢпјҢиҝҷдёӘиҝҳжҳҜиҰҒзңӢе…·дҪ“зҡ„йЎ№зӣ®иҰҒжұӮгҖӮеӣ дёәжҲ‘们е®һйҷ…йЎ№зӣ®дёӯйҒҮеҲ°зҡ„й—®йўҳйғҪжҳҜзҺ°е®һз”ҹжҙ»дёӯзңҹе®һеӯҳеңЁзҡ„дҫӢеӯҗпјҢдёҚеҶҚжҳҜеҚ•зәҜзҡ„ж•°еӯҰйўҳдәҶпјҢжҜ”еҰӮжң¬дҫӢдёӯзҡ„x8ж¶Ҳиҙ№д»·ж јжҢҮж•°е’Ңx9ең°еҢәзҡ„еӨұдёҡзҺҮпјҢиҝҷдёӨдёӘиӮҜе®ҡеҜ№yжҳҜжңүдёҖе®ҡеҪұе“Қзҡ„пјҢеҰӮжһңзӣІзӣ®еү”йҷӨпјҢеҸҜиғҪдјҡеҜ№жңҖз»Ҳзҡ„з»“жһңдә§з”ҹдёҚиүҜеҪұе“ҚпјҢжүҖд»ҘжҲ‘们иҝҳжҳҜиҰҒж №жҚ®е®һйҷ…йңҖжұӮжқҘеҒҡеҶіе®ҡгҖӮ
вҖңжҖҺд№Ҳз”ЁPythonиҝӣиЎҢеӨҡе…ғзәҝжҖ§еӣһеҪ’вҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





