这篇文章主要讲解了“一行Python命令搞定前期数据探索性的方法是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“一行Python命令搞定前期数据探索性的方法是什么”吧!
对于每个从事和数据科学有关的人来说,前期的数据清洗和探索一定是个花费时间的工作。毫不夸张的说,80%的时间我们都花在了前期的数据工作中,包括清洗、处理、EDA(Exploratory Data Analysis,探索性数据分析)等。前期的工作不仅关乎数据的质量,也关乎最终模型预测效果的好坏。
每当我们手上出现一份新的数据时,我们都需要事先通过人为地观察、字段释义等方式预先对数据进行熟悉与理解。在清洗、处理完数据之后才会开始真正的 EDA 过程。
这个过程最通用的操作无非就是对现有的数据做基本性的统计、描述,包括平均值、方差、最大值与最小值、频数、分位数、分布等。实际上往往都是比较固定且机械的。
在 R 语言中 skimr 包提供了丰富的数据探索性统计信息,比 Pandas 中的 describe() 基本统计信息更为丰富一些。
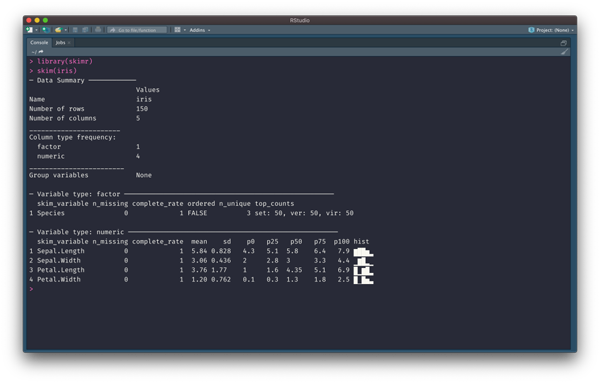
01-skmir
但在 Python 社区中,我们同样也可以实现 skmir 的功能,甚至比 skmir 有过之而无不及。那就是使用 pandas-profiling 库来帮助我们搞定前期的数据探索工作。
快速使用
通过 pip install pandas-profiling 之后我们就可以直接导入并使用了。我们只需要通过其一行核心代码 ProfileReport(df, **kwargs) 即可实现:
import pandas as pd import seaborn as sns from pandas_profiling import ProfileReport titanic = sns.load_dataset("Titanic") ProfileReport(titanic, title = "The EDA of Titanic Dataset")如果我们是在 Jupyter Notebook 中使用,则会在 Jupyter Notebook 中渲染最后直接输出到单元格中。
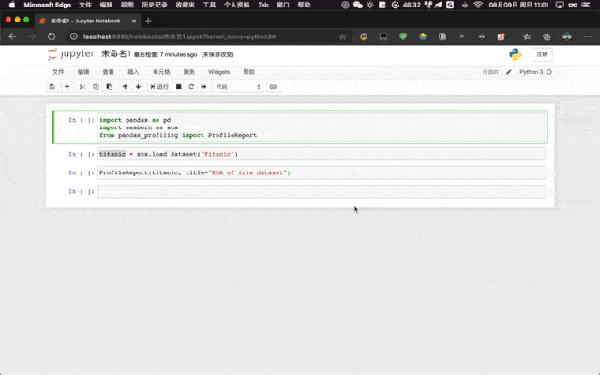
02-profile
pandas-profiling 库也扩展了 DataFrame 对象方法,这意味着我们也可以通过像调用方法一样使用 DataFrame.profile_report() 来实现和上述一样的效果。
无论使用哪种方式,最后都是生成一个 ProfileReport 对象;如果要进一步贴合 Jupyter Notebook,可以直接调用 to_widgets() 和 to_notebook_iframe() 来分别生成挂架或对应的组件,在展示效果上会更加美观,而不是在输出栏进行展示。
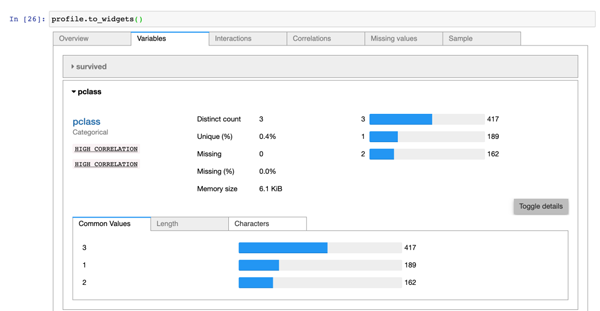
03-widgets
如果不在 Jupyter Notebook 中直接使用,而是使用其他 IDE,那么我们可以通过 to_file() 方法来直接将报告输出,需要注意的是最后保存的文件名需要加上扩展名 .html。
另外,Pandas-profiling 还和多个框架、云上平台等进行了集成,能够让我们方便的进行调用,详情见官网(https://pandas-profiling.github.io/pandas-profiling/docs/master/rtd/pages/integrations.html)。
进一步定制报告信息
虽然生成的探索性报告基本上已经能满足我们了解数据的简单需求,但是当中输出的信息也有些不足或是冗余。好在 pandas-profiling 也给我们提供了自己定制的可能。这些定制的配置最终会写入到 yaml 文件中。
在官方文档中列出了几个我们能够进一步调整的部分,分别对应了报告 Tab 栏的各部分标签:
vars:主要用于调整数据中字段或变量在报告中的呈现的统计指标
missing_diagrams:主要涉及到关于缺失值字段的可视化展示
correlations:顾名思义即调整有关各字段或变量之间相关关系的部分,包括是否计算相关系数、以及相关的阈值等
interactions:主要涉及两两字段或变量之前的相关关系图呈现
samples:分别对应了 Pandas 中 head() 和 tail() 方法,即预览前后多少条数据
这些部分还有许多可以指定的参数,感兴趣的朋友可以直接参考官方文档(https://pandas-profiling.github.io/pandas-profiling/docs/master/rtd/pages/advanced_usage.html),本文就不多加赘述了。
于是我们可以直接在代码中手动写入并进行调整,就像这样:
profile_config = { "progress_bar": False, "sort": "ascending", "vars": { "num": {"chi_squared_threshold": 0.95}, "cat": {"n_obs": 10} }, "missing_diagrams": { 'heatmap': False, 'dendrogram': False, } } profile = titanic.profile_report(**profile_config) profile.to_file("titanic-EDA-report.html")将所有配置的信息写在一个字典变量中,再通过 **variable 的形式将键值对进行解包使其能够根据键来对应到相应的参数中。
除了代码中的配置写法外,如果你稍微了解一点 yaml 配置文件的写法,那么我们也无需在代码中逐个写入,而是可以通过在 yaml 文件中修改。修改的不仅官方文档中所列出的配置选项,还能修改未列出的参数。由于配置文件过长,这里我只放出基于官方默认配置文件 config_default.yaml 自己做出修改的部分:
# profile_config.yml vars: num: quantiles: - 0.25 - 0.5 - 0.75 skewness_threshold: 10 low_categorical_threshold: 5 chi_squared_threshold: 0.95 cat: length: True unicode: True cardinality_threshold: 50 n_obs: 5 chi_squared_threshold: 0.95 coerce_str_to_date: False bool: n_obs: 3 file: active: False image: active: False exif: True hash: True sort: "desceding"
修改完 yaml 文件之后,我们只需在生成报告时通过 config_file 参数指定配置文件所在的路径即可,就像这样:
df.profile_report(config_file = "你的文件路径.yml")
通过将配置文件与核心代码相分离,以提高我们代码的简洁性与可读性。
感谢各位的阅读,以上就是“一行Python命令搞定前期数据探索性的方法是什么”的内容了,经过本文的学习后,相信大家对一行Python命令搞定前期数据探索性的方法是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





