本篇内容介绍了“为什么Java不清内存排查”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
GC日志配置
但并不是每次出现故障,你都在机器的身边。靠人工也不能保证实时性。所以,强烈建议你把GC日志输出的详细一些,那么出现问题的时候就舒坦一些。
实际上,这个要求在我看来是强制的。
很多同学上来就说,我的内存溢出了。但你和它要一些日志信息,要堆栈,要现场保存的快照。都没有。这就是纯粹来搞笑的。
下面是JDK8或者以下的GC日志参数,可以看到还是很长的。
#!/bin/sh LOG_DIR="/tmp/logs" JAVA_OPT_LOG=" -verbose:gc" JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintGCDetails" JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintGCDateStamps" JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintGCApplicationStoppedTime" JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintTenuringDistribution" JAVA_OPT_LOG="${JAVA_OPT_LOG} -Xloggc:${LOG_DIR}/gc_%p.log" JAVA_OPT_OOM=" -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${LOG_DIR} -XX:ErrorFile=${LOG_DIR}/hs_error_pid%p.log " JAVA_OPT="${JAVA_OPT_LOG} ${JAVA_OPT_OOM}" JAVA_OPT="${JAVA_OPT} -XX:-OmitStackTraceInFastThrow"下面是JDK9及其以上的日志配置。可以看到它的配置方式全变了,而且不向下兼容。Java搞的这个变化还是挺蛋疼的。
#!/bin/sh LOG_DIR="/tmp/logs" JAVA_OPT_LOG=" -verbose:gc" JAVA_OPT_LOG="${JAVA_OPT_LOG} -Xlog:gc,gc+ref=debug,gc+heap=debug,gc+age=trace:file=${LOG_DIR}/gc_%p.log:tags,uptime,time,level" JAVA_OPT_LOG="${JAVA_OPT_LOG} -Xlog:safepoint:file=${LOG_DIR}/safepoint_%p.log:tags,uptime,time,level" JAVA_OPT_OOM=" -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${LOG_DIR} -XX:ErrorFile=${LOG_DIR}/hs_error_pid%p.log " JAVA_OPT="${JAVA_OPT_LOG} ${JAVA_OPT_OOM}" JAVA_OPT="${JAVA_OPT} -XX:-OmitStackTraceInFastThrow" echo $JAVA_OPT一旦发现了问题,就可以拿GC日志来快速定位堆内问题。但是并不是让你一行行去看,那太低效了。因为日志可能会很长很长,而且也不一定看得懂。这个时候,就可以使用一些在线工具辅助解决。我经常使用的是gceasy,下面是它的一张截图。
http://gceasy.io
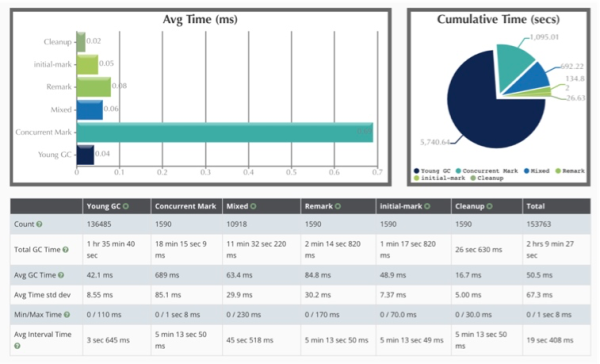
有了GC日志还不行,因为它仅仅是记录了堆空间的一些变化,至于操作系统的一些资源变动,它是无从知晓的。所以,如果你有一个监控系统的话,在寻找问题的时候也能帮到忙。从下图可以看到系统资源的一些变动。
溢出示例
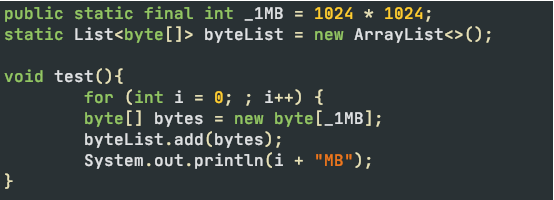
堆溢出
代码。
日志。
java -Xmx20m -Xmn4m -XX:+HeapDumpOnOutOfMemoryError - OOMTest [18.386s][info][gc] GC(10) Concurrent Mark 5.435ms [18.395s][info][gc] GC(12) Pause Full (Allocation Failure) 18M->18M(19M) 10.572ms [18.400s][info][gc] GC(13) Pause Full (Allocation Failure) 18M->18M(19M) 5.348ms Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at OldOOM.main(OldOOM.java:20)
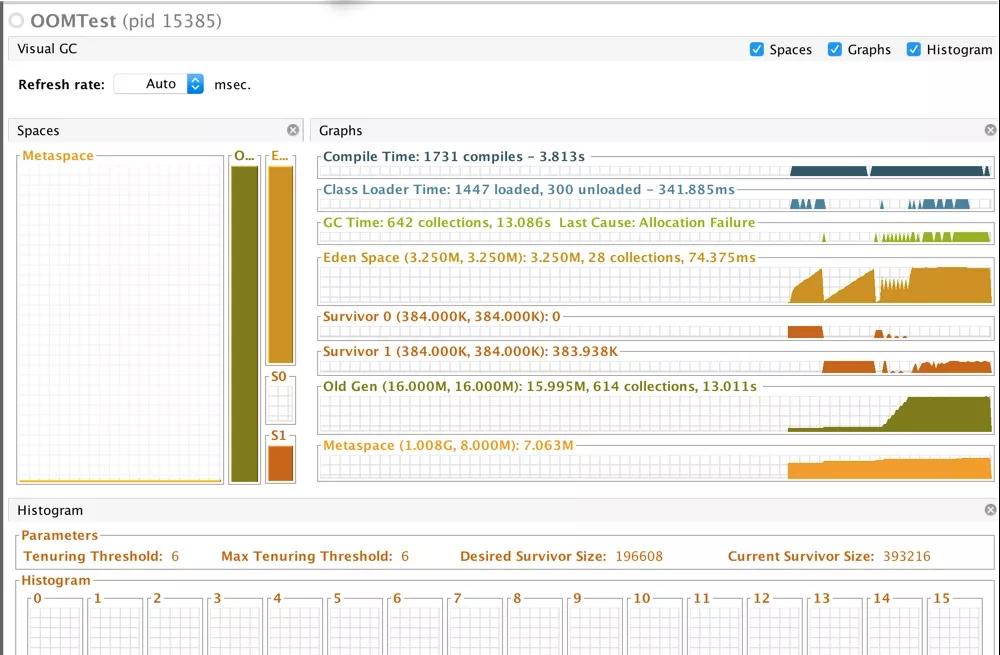
jvisualvm的反应。
元空间溢出
代码。
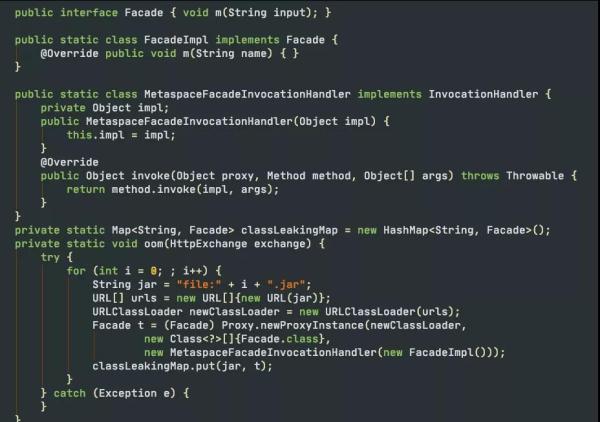
日志。
java -Xmx20m -Xmn4m -XX:+HeapDumpOnOutOfMemoryError -XX:MetaspaceSize=16M -XX:MaxMetaspaceSize=16M MetaspaceOOMTest 6.556s][info][gc] GC(30) Concurrent Cycle 46.668ms java.lang.OutOfMemoryError: Metaspace Dumping heap to /tmp/logs/java_pid36723.hprof ..
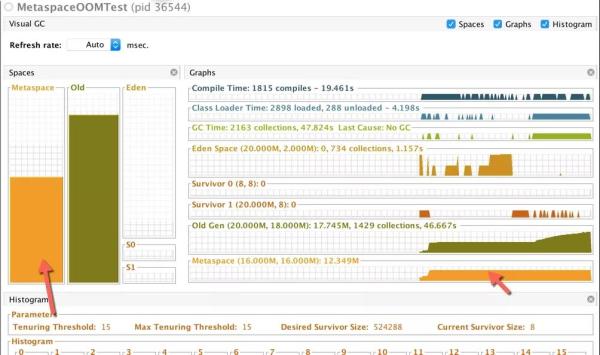
jvisualvm的反应。
直接内存溢出
代码。
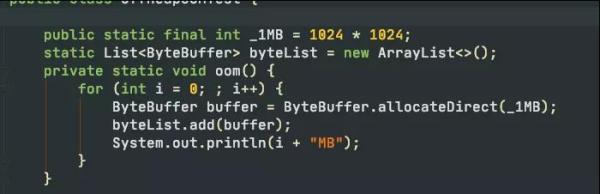
日志。
java -XX:MaxDirectMemorySize=10M -Xmx10M OffHeapOOMTest Exception in thread "Thread-2" java.lang.OutOfMemoryError: Direct buffer memory at java.nio.Bits.reserveMemory(Bits.java:694) at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123) at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311) at OffHeapOOMTest.oom(OffHeapOOMTest.java:27)...
栈溢出
代码。
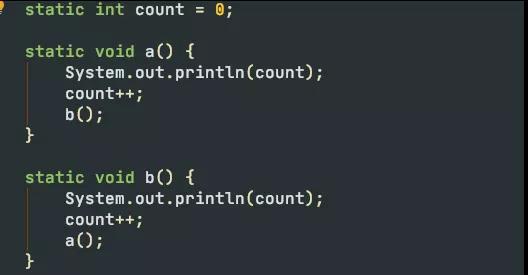
日志。
java -Xss128K StackOverflowTest Exception in thread "main" java.lang.StackOverflowError at java.io.PrintStream.write(PrintStream.java:526) at java.io.PrintStream.print(PrintStream.java:597) at java.io.PrintStream.println(PrintStream.java:736) at StackOverflowTest.a(StackOverflowTest.java:5)
哪些代码容易出现问题
忘记重写hashCode和equals
看下面的代码。由于没有重写Key类的hashCode和equals方法。造成了放入HashMap的所有对象,都无法被取出来。它们和外界失联了。
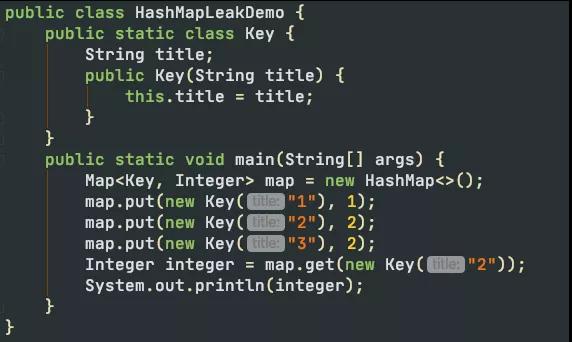
下面这篇文章详细的描述了它的原理。
结果集失控
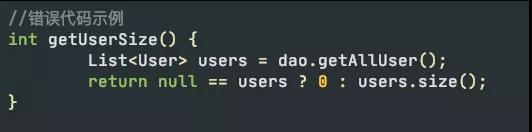
不要觉得这段代码可笑。在实际工作中的review中,xjjdog不止一次发现这种蛋疼的代码。这有可能是赶工期,也有可能是刚学会写Java。这行代码有很大的可能性踩坑。
条件失控
代码。与之类似的就是条件失控,当某个条件不满足的时候,将会造成结果集的失控。大家可以看下面的代码,fullname 和 other为空的时候,会出现什么后果?
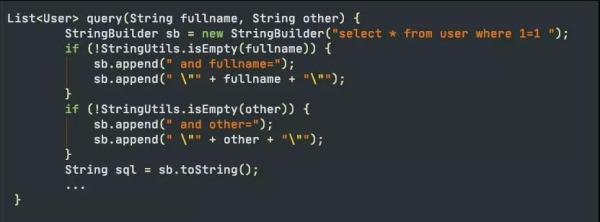
万能参数
还有的同学使用各种Object和HashMap来进行信息交换。这种代码正常运行的时候没什么问题,但一旦出错,几乎无法排查。排查参数、排查堆栈、排查调用链,全部失效。

一些预防的措施
减少创建大对象的频率:比如byte数组的传递
不要缓存太多的堆内数据:使用guava的weak引用模式
查询的范围一定要可控:如分库分表中间件;ES等有同样问题
用完的资源一定要close掉:可以使用新的 try-with-resources语法
少用intern:字符串太长,且无法复用,就会造成内存泄漏
合理的Session超时时间
少用第三方本地代码,使用Java方案替代
合理的池大小
XML(SAX/DOM)、JSON解析要注意对象大小
案例分析一
这是最常见的一种情况。了解了这种方式,能够应对大多数内存溢出和内存泄漏问题。
现象
环境:CentOS7,JDK1.8,SpringBoot
G1垃圾回收器
刚启动没什么问题,慢慢放量后,发生了OOM
系统自动生成了heapdump文件
临时解决方式:重启,但问题依然发现
信息收集
日志:GC的日志信息:内存突增突降,变动迅速
堆栈:Thread Dump文件:大部分阻塞在某个方法上
压测:使用wrk进行压测,发现20个用户并发,内存溢出
wrk -t20 -c20 -d300s http://127.0.0.1:8084/api/test
MAT分析
堆栈文件获取:
jmap -dump:format=b,file=heap.bin 37340 jhsdb jmap --binaryheap --pid 37340
MAT工具是基于eclipse平台开发的,本身是一个Java程序。分析Heap Dump文件:发现内存创建了大量的报表对象。
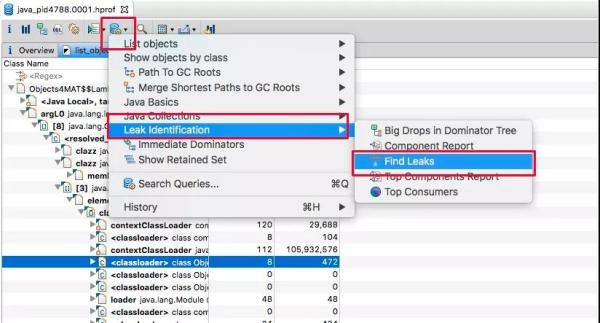
通过菜单Find Leaks,一键找出黑李逵。
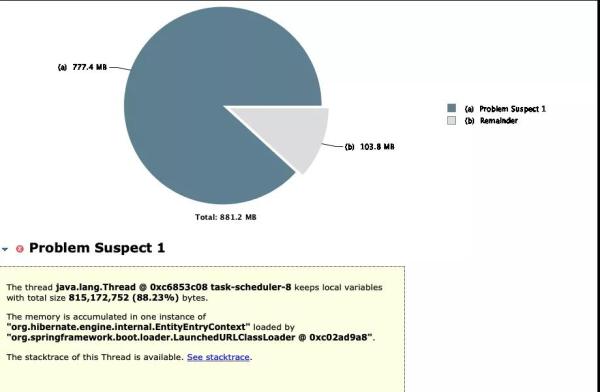
根据提示向下挖就可以。
解决
分析结果:
系统存在大数据量查询服务,并在内存做合并
当并发量达到一定程度,会有大量数据堆积到内存进行运算
解决方式:
重构查询服务,减少查询的字段
使用SQL查询代替内存拼接,避免对结果集的操作
举例:查找两个列表的交集
案例分析二
现象
环境:CentOS7,JDK1.8,JBoss
CMS垃圾回收器
操作系统CPU资源耗尽
访问任何接口,响应都非常的慢
分析
发现每次GC的效果都特别好,但是非常频繁
了解到使用了堆内缓存,而且设置的容量比较大
缓存填充的速度特别快!
结论:
开了非常大的缓存,GC之后迅速占满,造成GC频繁
案例分析三
现象java进程异常退出
java进程直接消失
没有留下dump文件
GC日志正常
监控发现死亡时,堆内内存占用很少,堆内仍有大量剩余空间
分析
XX:+HeapDumpOnOutOfMemoryError不起作用
监控发现操作系统内存持续增加
下面这些情况都会造成程序退出而没什么响应。
被操作系统杀死 dmesg oom-killer
System.exit()
java com.cn.AA & 后终端关闭
kill -9
解决
发现:
在dmesg命令中发现确实被oom-kill
解决:
给JVM少分配一些内存,腾出空间给其他进程
“为什么Java不清内存排查”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





