Python中怎么创建线性回归机器学习模型,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
线性回归机器学习模型
1.要使用的数据集
由于线性回归是我们在本文中学习的第一个机器学习模型,因此在本文中,我们将使用人工创建的数据集。这能让你可以更加专注于学习理解机器学习的概念,并避免在清理或处理数据上花费不必要的时间。
更具体地说,我们将使用住房数据的数据集并尝试预测住房价格。在构建模型之前,我们首先需要导入所需的库。
2.需要用到的Python库
我们需要导入的第一个库是 pandas,它是一个“panel data”的组合体,是处理表格数据比较流行的Python库。
一般我们会用pd来命名该库,你可以使用以下语句导入Pandas:
import pandas as pd接下来,我们需要导入NumPy,这是一个很常用的数值计算库。Numpy以其Numpy数组数据结构以及非常有用的reshee、arange和append而闻名。
一般我们也会用np作为Numpy的别名,你可以使用以下语句进行导入:
import numpy as np接下来,我们需要导入matplotlib,这是Python很受欢迎的数据可视化库。
matplotlib通常以别名导入plt。你可以使用以下语句导入:
import matplotlib.pyplot as plt %matplotlib inline该%matplotlib inline语句可以将我们的matplotlib可视化直接嵌入到我们的Jupyter Notebook中,更易于访问和解释。
最后,你还要导入seaborn,这是另一个Python数据可视化库,你可以更轻松地使用matplotlib创建漂亮的可视化数据。
你可以使用以下语句导入:
import seaborn as sns总结一下,这是本文必需的库的导入:
import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns如前所述,我们将使用住房信息数据集。在下面的URL链接中,有我们的.csv文件数据集:
https://nickmccullum.com/files/Housing_Data.csv
要将数据集导入到Jupyter Notebook中,首先要做的是通过将该URL复制并粘贴到浏览器中来下载文件。然后,将文件移到Jupyter Notebook的目录下。
完成此操作后,以下Python语句可以将住房数据集导入到Jupyter Notebook中:
raw_data = pd.read_csv('Housing_Data.csv')该数据集具有许多功能,包括:
房屋面积的平均售价
该地区平均客房总数
房子卖出的价格
房子的地址
此数据是随机生成的,因此你会看到一些可能没有意义的细微差别(例如,在应该为整数的数字之后的大量小数位)。
现在已经在raw_data变量下导入了数据集,你可以使用该info方法获取有关数据集的一些高级信息。具体来说,运行raw_data.info()可以得出:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 5000 entries, 0 to 4999 Data columns (total 7 columns): Avg. Area Income 5000 non-null float64 Avg. Area House Age 5000 non-null float64 Avg. Area Number of Rooms 5000 non-null float64 Avg. Area Number of Bedrooms 5000 non-null float64 Area Population 5000 non-null float64 Price 5000 non-null float64 Address 5000 non-null object dtypes: float64(6), object(1) memory usage: 273.6+ KB另一个有用的方法是生成数据。您可以为此使用seaborn方法pairplot,并将整个DataFrame作为参数传递。通过下面的一行代码进行说明:
sns.pairplot(raw_data)该语句的输出如下:
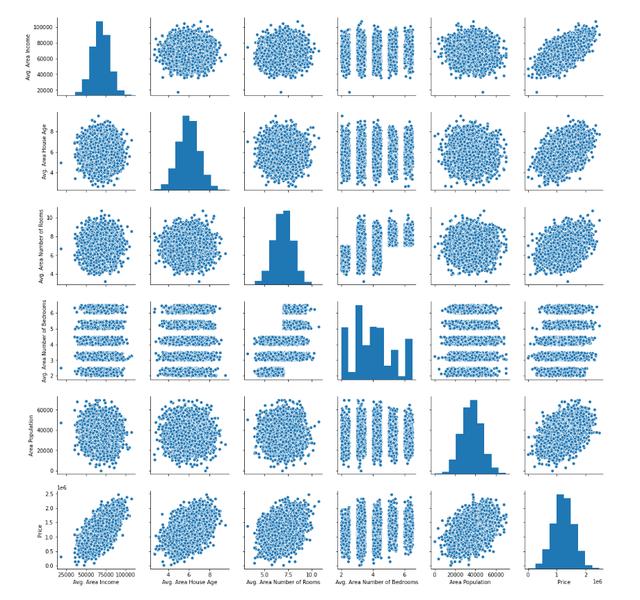
接下来,让我们开始构建线性回归模型。
我们需要做的第一件事是将我们的数据分为一个x-array(包含我们将用于进行预测y-array的数据)和一个(包含我们正在尝试进行预测的数据)。
首先,我们应该决定要包括哪些列,你可以使用生成DataFrame列的列表,该列表raw_data.columns输出:
Index(['Avg. Area Income', 'Avg. Area House Age', 'Avg. Area Number of Rooms', 'Avg. Area Number of Bedrooms', 'Area Population', 'Price', 'Address'], dtype='object')x-array除了价格(因为这是我们要预测的变量)和地址(因为它仅包含文本)之外,我们将在所有这些变量中使用。
让我们创建x-array并将其分配给名为的变量x。
x = raw_data[['Avg. Area Income', 'Avg. Area House Age', 'Avg. Area Number of Rooms', 'Avg. Area Number of Bedrooms', 'Area Population']]接下来,让我们创建我们的代码y-array并将其分配给名为的变量y。
y = raw_data['Price']我们已经成功地将数据集划分为和x-array(分别为模型的输入值)和和y-array(分别为模型的输出值)。在下一部分中,我们将学习如何将数据集进一步分为训练数据和测试数据。
scikit-learn 可以很容易地将我们的数据集分为训练数据和测试数据。为此,我们需要 train_test_split 从中的 model_selection 模块导入函数 scikit-learn。
这是执行此操作的完整代码:
from sklearn.model_selection import train_test_split该train_test_split数据接受三个参数:
x-array
y-array
测试数据的期望大小
有了这些参数,该 train_test_split 功能将为我们拆分数据!如果我们想让测试数据占整个数据集的30%,可以使用以下代码:
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3)
让我们解开这里发生的一切。
train_test_split 函数返回长度为4的Python列表,其中列表中的每个项分别是x_train、x_test、y_train和y_test。然后我们使用列表解包将正确的值赋给正确的变量名。
现在我们已经正确地划分了数据集,是时候构建和训练我们的线性回归机器学习模型了。
我们需要做的第一件事是从scikit learn导入LinearRegression估计器。下面是Python语句:
from sklearn.linear_model import LinearRegression接下来,我们需要创建一个线性回归Python对象的实例。我们将把它赋给一个名为model的变量。下面是代码:
model = LinearRegression()我们可以使用 scikit-learn 中的 fit 方法在训练数据上训练该模型。
model.fit(x_train, y_train)我们的模型现已训练完毕,可以使用以下语句检查模型的每个系数:
print(model.coef_)输出:
[2.16176350e+01 1.65221120e+05 1.21405377e+05 1.31871878e+03 1.52251955e+01]类似地,下面是如何查看回归方程的截距:
print(model.intercept_)输出:
-2641372.6673013503查看系数的更好方法是将它们放在一个数据帧中,可以通过以下语句实现:
pd.DataFrame(model.coef_, x.columns, columns = ['Coeff'])这种情况下的输出更容易理解:

让我们花点时间来理解这些系数的含义。让我们具体看看面积人口变量,它的系数约为15。
这意味着,如果你保持所有其他变量不变,那么区域人口增加一个单位将导致预测变量(在本例中为价格)增加15个单位。
换言之,某个特定变量上的大系数意味着该变量对您试图预测的变量的值有很大的影响。同样,小值的影响也很小。
现在我们已经生成了我们的第一个机器学习线性回归模型,现在是时候使用该模型从我们的测试数据集进行预测了。
scikit-learn使得从机器学习模型做出预测变得非常容易,我们只需调用前面创建的模型变量的 predict 方法。
因为 predict 变量是用来进行预测的,所以它只接受一个 x-array 参数,它将为我们生成y值!
以下是使用 predict 方法从我们的模型生成预测所需的代码:
predictions = model.predict(x_test)预测变量保存 x_test 中存储的要素的预测值。 由于我们使用 train_test_split 方法将实际值存储在y_test中,因此我们接下来要做的是将预测数组的值与 y_test 的值进行比较。
这里有一种简单的方法是使用散点图绘制两个数组。 使用 plt.scatter 方法可以轻松构建 matplotlib 散点图。 以下为代码:
plt.scatter(y_test, predictions)这是代码生成的散点图:
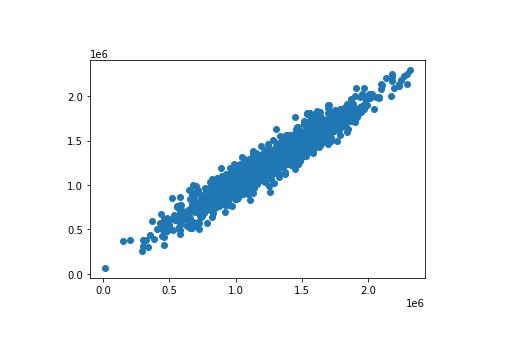
如图所见,我们的预测值非常接近数据集中观测值的实际值。在这个散点图中一条完美的直线表明我们的模型完美地预测了 y-array 的值。
另一种直观评估模型性能的方法是绘制残差,即实际y数组值与预测 y-array 值之间的差异。
使用以下代码语句可以轻松实现:
plt.hist(y_test - predictions)以下为代码生成的可视化效果:

这是我们的机器学习模型残差的直方图。
你可能会注意到,我们的机器学习模型中的残差似乎呈正态分布。这正好是一个很好的信号!
它表明我们已经选择了适当的模型类型(在这种情况下为线性回归)来根据我们的数据集进行预测。在本课程的后面,我们将详细了解如何确保使用了正确的模型。
我们在本课程开始时就了解到,回归机器学习模型使用了三个主要性能指标:
平均绝对误差
均方误差
均方根误差
现在,我们来看看如何为本文中构建的模型计算每个指标。在继续之前,记得在Jupyter Notebook中运行以下import语句:
from sklearn import metrics平均绝对误差(MAE)
可以使用以下语句计算Python中的平均绝对误差:
metrics.mean_absolute_error(y_test, predictions)均方误差(MSE)
同样,你可以使用以下语句在Python中计算均方误差:
metrics.mean_squared_error(y_test, predictions)均方根误差(RMSE)
与平均绝对误差和均方误差不同,scikit learn实际上没有计算均方根误差的内置方法。
幸运的是,它真的不需要。由于均方根误差只是均方根误差的平方根,因此可以使用NumPy的sqrt方法轻松计算:
np.sqrt(metrics.mean_squared_error(y_test, predictions))这是此Python线性回归机器学习教程的全部代码。
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline raw_data = pd.read_csv('Housing_Data.csv') x = raw_data[['Avg. Area Income', 'Avg. Area House Age', 'Avg. Area Number of Rooms', 'Avg. Area Number of Bedrooms', 'Area Population']] y = raw_data['Price'] from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3) from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(x_train, y_train) print(model.coef_) print(model.intercept_) pd.DataFrame(model.coef_, x.columns, columns = ['Coeff']) predictions = model.predict(x_test) # plt.scatter(y_test, predictions) plt.hist(y_test - predictions) from sklearn import metrics metrics.mean_absolute_error(y_test, predictions) metrics.mean_squared_error(y_test, predictions) np.sqrt(metrics.mean_squared_error(y_test, predictions))看完上述内容,你们掌握Python中怎么创建线性回归机器学习模型的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.toutiao.com/i6844105530626015752/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



