本篇文章为大家展示了Python中怎么实现一个透视表,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
1. 数据
为帮助大家更好地理解,在讲解如何使用pivot_table( )实现透视表前,我们先导入示例数据,在接下来的讲解中都使用此数据作为例子。
# 导入示例数据 <<< datadata =pd.read_csv("data.csv") <<< data.head() 月份 项目 部门 金额 剩余金额 0 1月 水费 市场部 1962.37 8210.58 1 2月 水费 市场部 690.69 9510.60 2 2月 电费 市场部 2310.12 5384.92 3 2月 电费 运营部 -1962.37 7973.10 4 2月 电费 开发部 1322.33 6572.16下面我将带大家使用pivot_table( )一步一步实现数据透视表的操作。
2. 操作
首先,原数据有5个字段,我们在做数据透视表之前必须理解每个字段的意思,明确清楚自己需要得到什么信息。
假设我们想看看不同月份所花费的水电费金额是多少,这时我们需要把字段“月份”设置为索引,将字段“金额”设置为我们需要看的值,具体代码如下:
<<< data.pivot_table(index=['月份'],values=['金额']) 金额 月份 10月 3723.940000 11月 2900.151667 12月 10768.262857 1月 1962.370000 2月 1432.280000 3月 3212.106667 4月 4019.175000 5月 4051.480000 6月 6682.632500 7月 11336.463333 8月 17523.485000 9月 10431.960000
参数index为设置的索引列表,即分组依据,需要用中括号[ ]将索引字段括起来;参数values为分组后进行计算的字段列表,也需要用中括号[ ]括起来。这两个参数的值可以是一个或多个字段,即按照多个字段进行分组和对多个字段进行计算汇总。例如,设置index=['项目','部门']代表求不同项目不同部门下的金额。
<<< data.pivot_table(index=['项目','部门'],values=['金额']) 金额 项目 部门 水费 市场部 3614.318125 开发部 2358.205000 运营部 5896.213333 电费 市场部 6094.748235 开发部 1322.330000 运营部 7288.615000 采暖费 市场部 5068.380000 运营部 55978.000000
若设置values=['金额','剩余金额'],即求不同项目不同部门下金额和剩余金额的值。
<<< data.pivot_table(index=['项目','部门'],values=['金额','剩余金额']) 剩余金额 金额 项目 部门 水费 市场部 7478.423125 3614.318125 开发部 6866.490000 2358.205000 运营部 7224.033333 5896.213333 电费 市场部 7645.535882 6094.748235 开发部 6572.160000 1322.330000 运营部 8821.895000 7288.615000 采暖费 市场部 6572.030000 5068.380000 运营部 7908.560000 55978.000000
同时,如果我们想以交叉表的形式查看不同项目和不同部门下的消费金额,这时就要将字段‘部门’设置为列名,进行交叉查看,具体代码如下:
<<< data.pivot_table(index=['项目'],columns=['部门'],values=['金额']) 金额 部门 市场部 开发部 运营部 项目 水费 3614.318125 2358.205 5896.213333 电费 6094.748235 1322.330 7288.615000 采暖费 5068.380000 NaN 55978.000000
通过上面的示例,我们可以看到某个分组下不存在记录会被标记为NAN,例如上述中采暖部和开发部不存在金额这一字段的记录,则会标记为NAN。如果不希望被标记为NAN,我们可以通过设置参数fill_value=0来用数值0替代这部分的缺失值。
<<< data.pivot_table(index=['项目'],columns=['部门'],values=['金额'],fill_value=0) 金额 部门 市场部 开发部 运营部 项目 水费 3614.318125 2358.205 5896.213333 电费 6094.748235 1322.330 7288.615000 采暖费 5068.380000 0.000 55978.000000
在上面的示例中,我们都是默认分组后对值进行求平均值计算,假如我们想查看不同项目不同部门下金额的总和该怎么实现呢?
通过设置参数aggfunc=np.sum即可对分组后的值进行求和操作,参数aggfunc代表分组后值的汇总方式,可传入numpy库中的聚合方法。
<<< data.pivot_table(index=['项目'],columns=['部门'],values=['金额'],fill_value=0,aggfunc=np.sum) 金额 部门 市场部 开发部 运营部 项目 水费 57829.09 4716.41 17688.64 电费 103610.72 1322.33 29154.46 采暖费 5068.38 0.00 55978.00
除了常见的求和、求平均值这两种聚合方法,我们还可能接触到以下这几种:
描述方法标准差np.std()方差np.var()所有元素相乘np.prod()中数np.median()幂运算np.power()开方np.sqrt()最小值np.min()最大值np.max()以e为底的指数np.exp(10)对数np.log(10)
与前面介绍的参数index,columns,value一样,参数aggfunc传入的值也是一个列表,表示可传入一个或多个值。当传入多个值时,表示对该值进行多种汇总方式,例如同时求不同项目不同部门下金额的求和值和平均值:
<<< data.pivot_table(index=['项目'],columns=['部门'],values=['金额'],fill_value=0,aggfunc=[np.sum,np.max]) sum amax 金额 金额 部门 市场部 开发部 运营部 市场部 开发部 运营部 项目 水费 57829.09 4716.41 17688.64 16807.58 2941.28 6273.56 电费 103610.72 1322.33 29154.46 18239.39 1322.33 26266.60 采暖费 5068.38 0.00 55978.00 5068.38 0.00 55978.00
同时,如果我们想对不同字段进行不同的汇总方式,可通过对参数aggfunc传入字典来实现,例如我们可以同时对不同项目不同部门下,对字段金额求总和值,对字段剩余金额求平均值:
<<< data.pivot_table(index=['项目'],columns=['部门'],values=['金额','剩余金额'],fill_value=0,aggfunc={'金额':np.sum,'剩余金额':np.max}) 剩余金额 金额 部门 市场部 开发部 运营部 市场部 开发部 运营部 项目 水费 9510.60 8719.34 7810.38 57829.09 4716.41 17688.64 电费 9625.27 6572.16 9938.82 103610.72 1322.33 29154.46 采暖费 6572.03 0.00 7908.56 5068.38 0.00 55978.00另外,在进行以上功能的同时,pivot_table还为我们提供了一个求所有行及所有列对应合计值的参数margins,当设置参数margins=True时,会在输出结果的最后添加一行'All',表示根据columns进行分组后每一项的列总计值;以及在输出结果的最后添加一列'All',表示根据index进行分组后每一项的行总计值。
<<< pd.set_option('precision',0) <<< data.pivot_table(index=['项目'],columns=['部门'],values=['金额','剩余金额'],fill_value=0,aggfunc={'金额':np.sum,'剩余金额':np.max},margins=True) 剩余金额 金额 部门 市场部 开发部 运营部 All 市场部 开发部 运营部 All 项目 水费 9511 8719 7810 9511 57829 4716 17689 80234 电费 9625 6572 9939 9939 103611 1322 29154 134088 采暖费 6572 0 7909 7909 5068 0 55978 61046 All 9625 8719 9939 9939 166508 6039 102821 2753683. 番外
上面详细介绍了如何在python中通过pivot_table( )方法实现数据透视表的功能,那么,与数据透视表原理相同,显示方式不同的‘数据透视图’又该怎么实现呢?
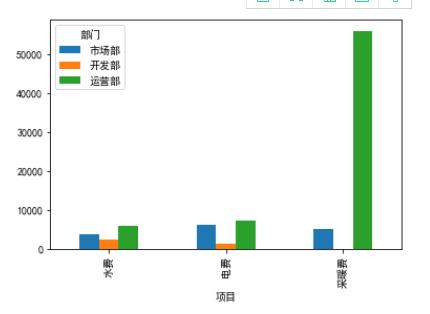
实现方法非常简单,将上述进行pivot_table操作后的对象进行实例化,再对实例化后的对象进行plot绘图操作即可,具体代码如下:
<<< dfdf=data.pivot_table(index=['项目'],columns=['部门'],values='金额',fill_value=0) <<< df.plot(kind='bar')
上述内容就是Python中怎么实现一个透视表,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





