本篇内容主要讲解“如何使用python正则表达式模块中的re.findall()函数”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“如何使用python正则表达式模块中的re.findall()函数”吧!
首先,导入python正则表达式模块“re”:
import re
假设有以下字符串:
test_string1= 'Python is Amazing!'
可将表达式r“^\w+”与字符串一并传递至“re.findall”,这将返回输入字符串的开头:
reregex_1 =re.findall(r"^\w+",test_string1) print(regex_1)

在表达式r“^\w+”中,字符“^”对应字符串开头,而“\w+”查找字符串中的字母数字字符。
如果去掉“^”,会得到:
reregex_1 =re.findall(r"\w+",test_string1) print(regex_1)
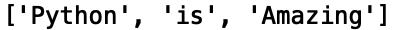
试提取另一个字符串示例的开头:
test_string2= 'Java is Amazing!'
现在,应用“re.findall()”查找该字符串的第一个单词:
reregex_2 =re.findall(r"^\w+",test_string2) print(regex_2)

接下来,考虑一个更实际的场景。假设有一个YouTube视频标题列表和相应的YouTube观看次数。我们可能对分析视频标题的第一个单词和相应视频观看次数之间的关系感兴趣。考虑以下标题/观看次数元组列表:
youtube_titles= [("How to Tell if We're Beating COVID-19", 2200000), ("ExtremeCloset Clean Out",326000), ("This is $1,000,000 inFood",8800000), ("How To Tell If Someone Truly Loves You ",2800000), ("How to Tell Real Gold from Fake", 2300000),("Extreme living room transformation ", 25000)]可以通过以下方式找到每个标题的第一个单词:
for titlein youtube_titles: print(re.findall(r"^\w+",title[0])[0])

可以将这些值添加到列表中:
first_words= [] for title in youtube_titles: first_words.append(re.findall(r"^\w+",title[0])[0]) print(first_words)
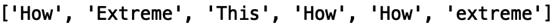
还可以将观看次数附加到列表中:
first_words= [] views = [] for title in youtube_titles: first_words.append(re.findall(r"^\w+",title[0])[0]) views.append(title[1])
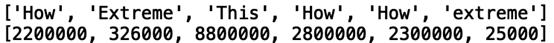
然后,可以创建视频首字值和视频观看次数的数据框:
importpandas as pd df = pd.DataFrame({'first_words': first_words, 'views':views}) print(df)
之后可以对每个标题首词进行分组,并计算每个标题首词的平均观看次数:
dfdf =df.groupby('first_words')['views'].mean() print(df)
按降序方式对这些值进行排序:
dfdf =df.groupby('first_words')['views'].mean().sort_values(ascending = False) print(df)
假设这些结果来自一个足够大的数据集(比如有数千个标题和观看次数),这种类型的分析可以帮助我们选择最佳的YouTube视频标题。
到此,相信大家对“如何使用python正则表达式模块中的re.findall()函数”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





