这篇文章给大家分享的是有关shell中sed怎么用的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
1.首先先来了解一下什么是sed?
sed叫做流编辑器,在shell脚本和Makefile中作为过滤器使用非常普遍,也就是把前一个程序的输出引入sed的输入,经过一系列编辑命令转换成为另一种格式输出。下面我们通过一张原理图来了解一下它的工作模式:
编辑命令的格式为,sed /pattern/action
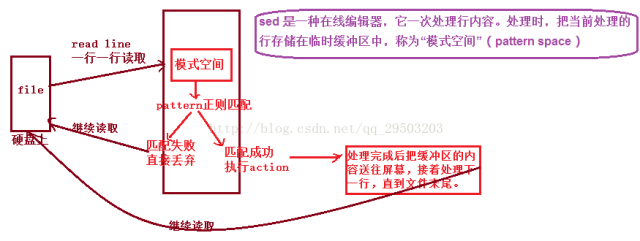
经过sed处理后文件内容并没有改变,除⾮使用重定向存储输出。sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;sed默认按照Basic 规范基本匹配!也就是说类似于( ) { } | 等特殊字符需转义,否则就不识别,或者是用扩展模式也可以。
2. 下面重点介绍一下有关sed的参数及action的操作方法
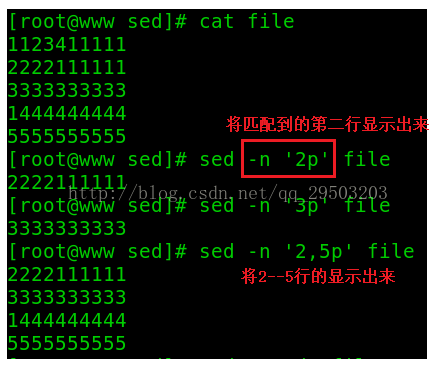
(1)-n参数,p命令的action

(2) d命令的action

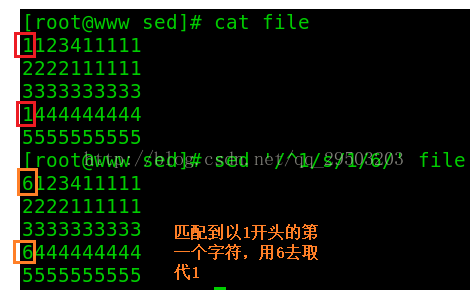
(3)/pattern/s/pattern1/pattern2/:查找符合pattern的行,将该行***个匹配pattern1的字符串替换为pattern2
/pattern/s/pattern1/pattern2/g:查找符合pattern的行,将该行所有匹配pattern1的字符串替换为pattern2
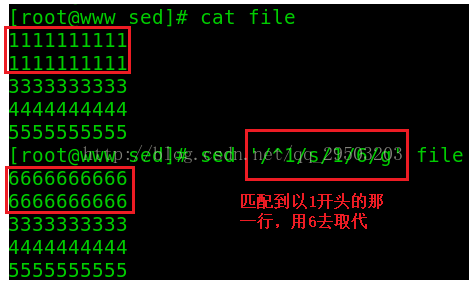
这个操作不知道大家会不会联想到vim编辑器中的底行模式搜索,它们是类似的。
下面总结一下sed中参数的选择及执行操作:
[plain] view plain copy
<strong>参数选择:
-n:一般sed命令会把所有数据都输出到屏幕,如果加入-n选项的话,则只会把经过sed命令处理的行输出到屏幕。
-e:允许对输入数据应用多条sed命令编辑。
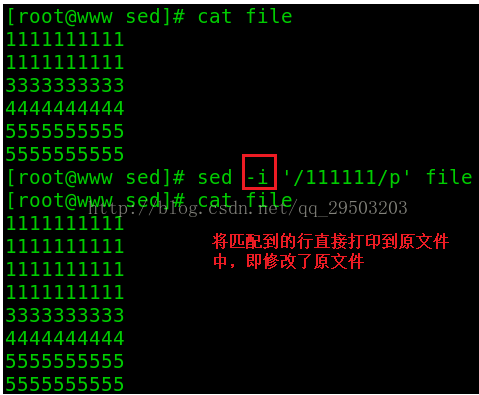
-i:将修改结果直接写入到读取数据的文件,而不是由屏幕输出。(1.修改了文件; 2.由cat可查看)
-f: 指定sed脚本的文件名。
action:
a:追加,在当前行后添加一行或多行。
c:行替换,用c后面的字符串替换原数据行。
i:插入,在当前行前插入一行或多行。
p:打印,输出指定的行。
s:字符串替换,用一个字符串替换另外一个字符串。格式为”行范围s/旧字符串/新字符串/g”(如果不加g的话,则表示只替换每行***个匹配的串)。
</strong>
以上没有练习到的,有兴趣的可以去尝试尝试!
3.再来介绍一下sed中的定址
定址用于决定对文件中哪些行进行行编辑,地址的形式可以是数字、正则表达式、或二者的结合。如果没有指定地址,sed将处理输入文件的所有行。下面举一些例子:

sed '/start/ ,/end/d' file #删除包含’start’行和’end’行之间的行
sed '/start/, 10d' file #删除包含’start’ 的行到第十行的内容
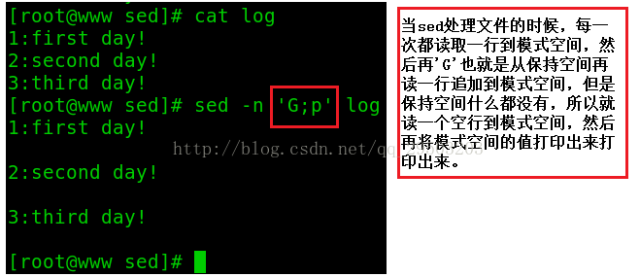
4.模式空间和保持空间
(1)保持空间:用来存储数据,相当于一个仓库,它不能对数据进行处理 ;
(2)模式空间:专门以行为单位对数据进行处理。
一般情况下,如果不显示的使用一些选项的话,是不会用到保持空间的。
[plain] view plain copy
<span style="color:#000000;"><strong>命令:
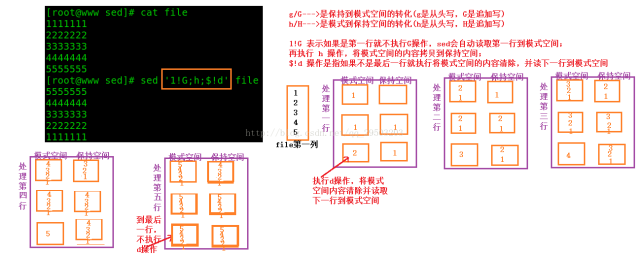
g:将保持空间的内容拷贝到模式空间中,会将模式空间原来的值覆盖掉。
G:将保持空间的内容追加到模式空间中。
h:将模式空间的值拷贝到保持空间,会将保持空间原来的值覆盖掉。
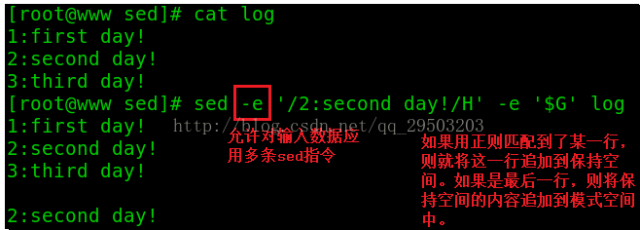
H:将模式空间的值追加到保持空间中。
d:删除模式空间的所有行,并读下一行到模式空间。
D:删除模式空间的***行,不读下一行到模式空间。
n:输出模式空间的行,读取下一行替换当前模式空间的行,接着执行下一条处理命令而不是***条命令。
N:读入下一行,追加到模式空间行后面,此时模式空间中有两行。
x:交换模式空间和保持空间的内容。
</strong></span>
例1:给每行后面添加一行空行
例2:用sed模拟倒序(tac)打印的过程
例3.追加匹配行到文件末尾
例4:将一列内容变为一行
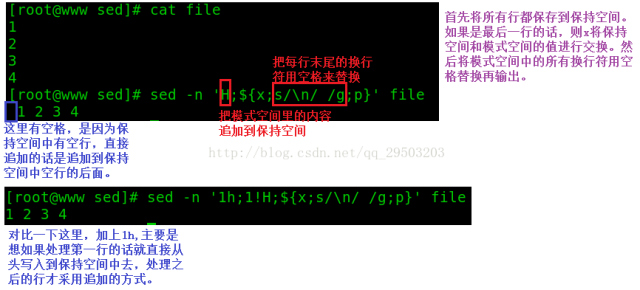
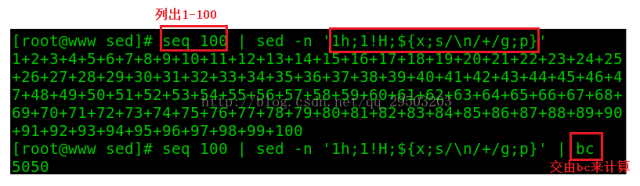
例5:求出1-100的求和
例6:打印输出奇数行和偶数行

5.使用标签
[plain] view plain copy
:a表示标签a;
ba表示跳转到a标签;
$表示***一行;
!表示不做后续操作
所以,$!ba表示***一行不用跳转到a标签,结束此次操作。
下面举一个例子:
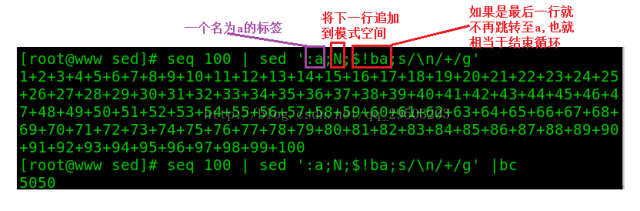
***补充一点:
[plain] view plain copy
与grep一样,sed也支持特殊元字符来进行模式查找、替换。不同的是,sed使用的正则表达式是括在斜杠线"/"之间的模式。
如果要把正则表达式分隔符"/"改为另一个字符,比如o,只要在这个字符前加一个反斜线,在字符后跟上正则表达式,再跟上这个字符即可。例如:sed -n '\o^56op' datafile
^:行首定位符 /^my/ 匹配所有以my开头的行;
$:行尾定位符 /my$/ 匹配所有以my结尾的行;
.:匹配除换行符以外的单个字符 /m..y/ 匹配包含字母m,后跟两个任意字符,再跟字母y的行;
*:匹配零个或多个前导字符 /test*/ 匹配包含字符串 tes,后跟零个或多个 t 字母的行;
[]:匹配指定字符组内的任一字符 /t[eE]st/ 匹配包含test 或 tEst 的行;
[^]:匹配不在指定字符组内的任一字符 /t[^eE]st/ 匹配string 以t开头,但st之前的那个字符不是e或E的行;
&:保存查找串以便在替换串中引用 s/test/*&*/g 符号&代表查找串。test将被替换为*test*
\<:词⾸首定位符 /\<my/ 匹配包含以my开头的单词的行;
\>:词尾定位符 /my\>/ 匹配包含以my结尾的单词的行;
x\{m\}:连续m个x 如:/9\{5\}/ 匹配包含连续5个9的行;
x\{m,\}:至少m个x 如:/9\{5,\}/ 匹配包含至少连续5个9的行;
x\{m,n\}:至少m个,但不超过n个x 如:/9\{5,7\}/ 匹配包含连续5到7个9的行。 还有一个单元匹配--替换的问题:
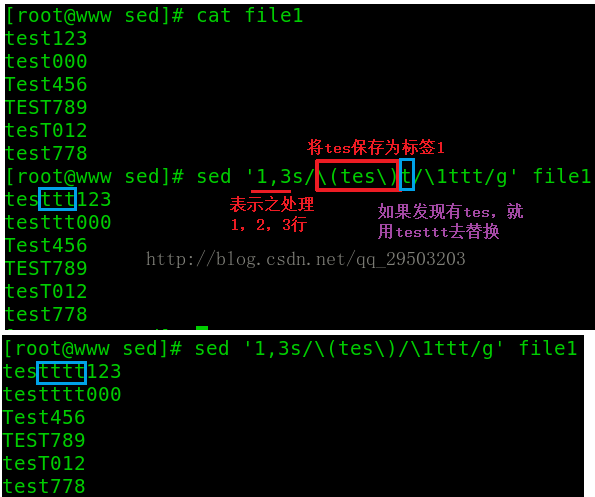
感谢各位的阅读!关于“shell中sed怎么用”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





