Redisзҡ„з®Җд»ӢеҸҠдјҳзјәзӮ№
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңRedisзҡ„з®Җд»ӢеҸҠдјҳзјәзӮ№вҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁRedisзҡ„з®Җд»ӢеҸҠдјҳзјәзӮ№й—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқRedisзҡ„з®Җд»ӢеҸҠдјҳзјәзӮ№вҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
дёҖгҖҒRedis з®Җд»Ӣ
"Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker." —— RedisжҳҜдёҖдёӘејҖж”ҫжәҗд»Јз ҒпјҲBSDи®ёеҸҜпјүзҡ„еҶ…еӯҳдёӯж•°жҚ®з»“жһ„еӯҳеӮЁпјҢз”ЁдҪңж•°жҚ®еә“пјҢзј“еӯҳе’Ңж¶ҲжҒҜд»ЈзҗҶгҖӮ(ж‘ҳиҮӘе®ҳзҪ‘)
Redis жҳҜдёҖдёӘејҖжәҗпјҢй«ҳзә§зҡ„й”®еҖјеӯҳеӮЁе’ҢдёҖдёӘйҖӮз”Ёзҡ„и§ЈеҶіж–№жЎҲпјҢз”ЁдәҺжһ„е»әй«ҳжҖ§иғҪпјҢеҸҜжү©еұ•зҡ„ Web еә”з”ЁзЁӢеәҸгҖӮRedis д№ҹиў«дҪңиҖ…жҲҸз§°дёә ж•°жҚ®з»“жһ„жңҚеҠЎеҷЁ пјҢиҝҷж„Ҹе‘ізқҖдҪҝз”ЁиҖ…еҸҜд»ҘйҖҡиҝҮдёҖдәӣе‘Ҫд»ӨпјҢеҹәдәҺеёҰжңү TCP еҘ—жҺҘеӯ—зҡ„з®ҖеҚ• жңҚеҠЎеҷЁ-е®ўжҲ·з«Ҝ еҚҸи®®жқҘи®ҝй—®дёҖз»„ еҸҜеҸҳж•°жҚ®з»“жһ„ гҖӮ(еңЁ Redis дёӯйғҪйҮҮз”Ёй”®еҖјеҜ№зҡ„ж–№ејҸпјҢеҸӘдёҚиҝҮеҜ№еә”зҡ„ж•°жҚ®з»“жһ„дёҚдёҖж ·зҪўдәҶ)
Redis зҡ„дјҳзӮ№
д»ҘдёӢжҳҜ Redis зҡ„дёҖдәӣдјҳзӮ№пјҡ
ејӮеёёеҝ« - Redis йқһеёёеҝ«пјҢжҜҸз§’еҸҜжү§иЎҢеӨ§зәҰ 110000 ж¬Ўзҡ„и®ҫзҪ®(SET)ж“ҚдҪңпјҢжҜҸз§’еӨ§зәҰеҸҜжү§иЎҢ 81000 ж¬Ўзҡ„иҜ»еҸ–/иҺ·еҸ–(GET)ж“ҚдҪңгҖӮ
ж”ҜжҢҒдё°еҜҢзҡ„ж•°жҚ®зұ»еһӢ - Redis ж”ҜжҢҒејҖеҸ‘дәәе‘ҳеёёз”Ёзҡ„еӨ§еӨҡж•°ж•°жҚ®зұ»еһӢпјҢдҫӢеҰӮеҲ—иЎЁпјҢйӣҶеҗҲпјҢжҺ’еәҸйӣҶе’Ңж•ЈеҲ—зӯүзӯүгҖӮиҝҷдҪҝеҫ— Redis еҫҲе®№жҳ“иў«з”ЁжқҘи§ЈеҶіеҗ„з§Қй—®йўҳпјҢеӣ дёәжҲ‘们зҹҘйҒ“е“Әдәӣй—®йўҳеҸҜд»ҘжӣҙеҘҪдҪҝз”Ёең°е“Әдәӣж•°жҚ®зұ»еһӢжқҘеӨ„зҗҶи§ЈеҶігҖӮ
ж“ҚдҪңе…·жңүеҺҹеӯҗжҖ§ - жүҖжңү Redis ж“ҚдҪңйғҪжҳҜеҺҹеӯҗж“ҚдҪңпјҢиҝҷзЎ®дҝқеҰӮжһңдёӨдёӘе®ўжҲ·з«Ҝ并еҸ‘и®ҝй—®пјҢRedis жңҚеҠЎеҷЁиғҪжҺҘ收жӣҙж–°зҡ„еҖјгҖӮ
еӨҡе®һз”Ёе·Ҙе…· - Redis жҳҜдёҖдёӘеӨҡе®һз”Ёе·Ҙе…·пјҢеҸҜз”ЁдәҺеӨҡз§Қз”ЁдҫӢпјҢеҰӮпјҡзј“еӯҳпјҢж¶ҲжҒҜйҳҹеҲ—(Redis жң¬ең°ж”ҜжҢҒеҸ‘еёғ/и®ўйҳ…)пјҢеә”з”ЁзЁӢеәҸдёӯзҡ„д»»дҪ•зҹӯжңҹж•°жҚ®пјҢдҫӢеҰӮпјҢwebеә”з”ЁзЁӢеәҸдёӯзҡ„дјҡиҜқпјҢзҪ‘йЎөе‘Ҫдёӯи®Ўж•°зӯүгҖӮ
Redis зҡ„е®үиЈ…
иҝҷдёҖжӯҘжҜ”иҫғз®ҖеҚ•пјҢдҪ еҸҜд»ҘеңЁзҪ‘дёҠжҗңеҲ°и®ёеӨҡж»Ўж„Ҹзҡ„ж•ҷзЁӢпјҢиҝҷйҮҢе°ұдёҚеҶҚиөҳиҝ°гҖӮ
з»ҷдёҖдёӘиҸңйёҹж•ҷзЁӢзҡ„е®үиЈ…ж•ҷзЁӢз”ЁдҪңеҸӮиҖғпјҡhttps://www.runoob.com/redis/redis-install.html
жөӢиҜ•жң¬ең° Redis жҖ§иғҪ
еҪ“дҪ е®үиЈ…е®ҢжҲҗд№ӢеҗҺпјҢдҪ еҸҜд»Ҙе…Ҳжү§иЎҢ redis-server и®© Redis еҗҜеҠЁиө·жқҘпјҢ然еҗҺиҝҗиЎҢе‘Ҫд»Ө redis-benchmark -n 100000 -q жқҘжЈҖжөӢжң¬ең°еҗҢж—¶жү§иЎҢ 10 дёҮдёӘиҜ·жұӮж—¶зҡ„жҖ§иғҪпјҡ
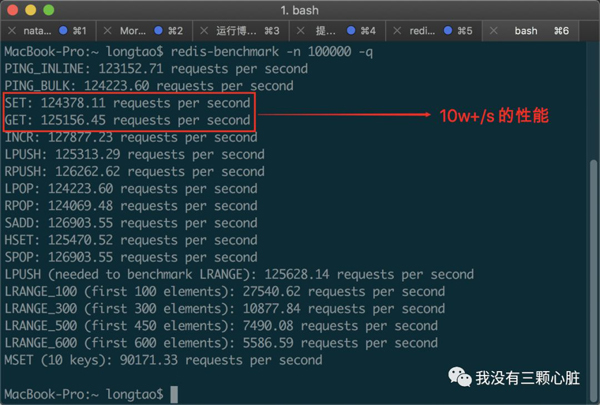
еҪ“然дёҚеҗҢз”өи„‘д№Ӣй—ҙз”ұдәҺеҗ„ж–№йқўзҡ„еҺҹеӣ дјҡеӯҳеңЁжҖ§иғҪе·®и·қпјҢиҝҷдёӘжөӢиҜ•жӮЁеҸҜд»ҘжқғеҪ“жҳҜдёҖз§Қ гҖҢд№җи¶ЈгҖҚ е°ұеҘҪгҖӮ
дәҢгҖҒRedis дә”з§Қеҹәжң¬ж•°жҚ®з»“жһ„
Redis жңү 5 з§ҚеҹәзЎҖж•°жҚ®з»“жһ„пјҢе®ғ们еҲҶеҲ«жҳҜпјҡstring(еӯ—з¬ҰдёІ)гҖҒlist(еҲ—иЎЁ)гҖҒhash(еӯ—е…ё)гҖҒset(йӣҶеҗҲ) е’Ң zset(жңүеәҸйӣҶеҗҲ)гҖӮиҝҷ 5 з§ҚжҳҜ Redis зӣёе…ізҹҘиҜҶдёӯжңҖеҹәзЎҖгҖҒжңҖйҮҚиҰҒзҡ„йғЁеҲҶпјҢдёӢйқўжҲ‘们结еҗҲжәҗз Ғд»ҘеҸҠдёҖдәӣе®һи·өжқҘз»ҷеӨ§е®¶еҲҶеҲ«и®Іи§ЈдёҖдёӢгҖӮ
1пјүеӯ—з¬ҰдёІ string
Redis дёӯзҡ„еӯ—з¬ҰдёІжҳҜдёҖз§Қ еҠЁжҖҒеӯ—з¬ҰдёІпјҢиҝҷж„Ҹе‘ізқҖдҪҝз”ЁиҖ…еҸҜд»Ҙдҝ®ж”№пјҢе®ғзҡ„еә•еұӮе®һзҺ°жңүзӮ№зұ»дјјдәҺ Java дёӯзҡ„ ArrayListпјҢжңүдёҖдёӘеӯ—з¬Ұж•°з»„пјҢд»Һжәҗз Ғзҡ„ sds.h/sdshdr ж–Ү件 дёӯеҸҜд»ҘзңӢеҲ° Redis еә•еұӮеҜ№дәҺеӯ—з¬ҰдёІзҡ„е®ҡд№ү SDSпјҢеҚі Simple Dynamic String з»“жһ„пјҡ
/* Note: sdshdr5 is never used, we just access the flags byte directly. * However is here to document the layout of type 5 SDS strings. */ struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; /* used */ uint16_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; /* used */ uint32_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; };дҪ дјҡеҸ‘зҺ°еҗҢж ·дёҖз»„з»“жһ„ Redis дҪҝз”ЁжіӣеһӢе®ҡд№үдәҶеҘҪеӨҡж¬ЎпјҢдёәд»Җд№ҲдёҚзӣҙжҺҘдҪҝз”Ё int зұ»еһӢе‘ўпјҹ
еӣ дёәеҪ“еӯ—з¬ҰдёІжҜ”иҫғзҹӯзҡ„ж—¶еҖҷпјҢlen е’Ң alloc еҸҜд»ҘдҪҝз”Ё byte е’Ң short жқҘиЎЁзӨәпјҢRedis дёәдәҶеҜ№еҶ…еӯҳеҒҡжһҒиҮҙзҡ„дјҳеҢ–пјҢдёҚеҗҢй•ҝеәҰзҡ„еӯ—з¬ҰдёІдҪҝз”ЁдёҚеҗҢзҡ„з»“жһ„дҪ“жқҘиЎЁзӨәгҖӮ
SDS дёҺ C еӯ—з¬ҰдёІзҡ„еҢәеҲ«
дёәд»Җд№ҲдёҚиҖғиҷ‘зӣҙжҺҘдҪҝз”Ё C иҜӯиЁҖзҡ„еӯ—з¬ҰдёІе‘ўпјҹеӣ дёә C иҜӯиЁҖиҝҷз§Қз®ҖеҚ•зҡ„еӯ—з¬ҰдёІиЎЁзӨәж–№ејҸ дёҚз¬ҰеҗҲ Redis еҜ№еӯ—з¬ҰдёІеңЁе®үе…ЁжҖ§гҖҒж•ҲзҺҮд»ҘеҸҠеҠҹиғҪж–№йқўзҡ„иҰҒжұӮгҖӮжҲ‘们зҹҘйҒ“пјҢC иҜӯиЁҖдҪҝз”ЁдәҶдёҖдёӘй•ҝеәҰдёә N+1 зҡ„еӯ—з¬Ұж•°з»„жқҘиЎЁзӨәй•ҝеәҰдёә N зҡ„еӯ—з¬ҰдёІпјҢ并且еӯ—з¬Ұж•°з»„жңҖеҗҺдёҖдёӘе…ғзҙ жҖ»жҳҜ '\0'гҖӮ(дёӢеӣҫе°ұеұ•зӨәдәҶ C иҜӯиЁҖдёӯеҖјдёә "Redis" зҡ„дёҖдёӘеӯ—з¬Ұж•°з»„)

иҝҷж ·з®ҖеҚ•зҡ„ж•°жҚ®з»“жһ„еҸҜиғҪдјҡйҖ жҲҗд»ҘдёӢдёҖдәӣй—®йўҳпјҡ
иҺ·еҸ–еӯ—з¬ҰдёІй•ҝеәҰдёә O(N) зә§еҲ«зҡ„ж“ҚдҪң → еӣ дёә C дёҚдҝқеӯҳж•°з»„зҡ„й•ҝеәҰпјҢжҜҸж¬ЎйғҪйңҖиҰҒйҒҚеҺҶдёҖйҒҚж•ҙдёӘж•°з»„пјӣ
дёҚиғҪеҫҲеҘҪзҡ„жқңз»қ зј“еҶІеҢәжәўеҮә/еҶ…еӯҳжі„жјҸ зҡ„й—®йўҳ → и·ҹдёҠиҝ°й—®йўҳеҺҹеӣ дёҖж ·пјҢеҰӮжһңжү§иЎҢжӢјжҺҘ or зј©зҹӯеӯ—з¬ҰдёІзҡ„ж“ҚдҪңпјҢеҰӮжһңж“ҚдҪңдёҚеҪ“е°ұеҫҲе®№жҳ“йҖ жҲҗдёҠиҝ°й—®йўҳпјӣ
C еӯ—з¬ҰдёІ еҸӘиғҪдҝқеӯҳж–Үжң¬ж•°жҚ® → еӣ дёә C иҜӯиЁҖдёӯзҡ„еӯ—з¬ҰдёІеҝ…йЎ»з¬ҰеҗҲжҹҗз§Қзј–з ҒпјҲжҜ”еҰӮ ASCIIпјүпјҢдҫӢеҰӮдёӯй—ҙеҮәзҺ°зҡ„ '\0' еҸҜиғҪдјҡиў«еҲӨе®ҡдёәжҸҗеүҚз»“жқҹзҡ„еӯ—з¬ҰдёІиҖҢиҜҶеҲ«дёҚдәҶпјӣ
жҲ‘们д»ҘиҝҪеҠ еӯ—з¬ҰдёІзҡ„ж“ҚдҪңдёҫдҫӢпјҢRedis жәҗз ҒеҰӮдёӢпјҡ
/* Append the specified binary-safe string pointed by 't' of 'len' bytes to the * end of the specified sds string 's'. * * After the call, the passed sds string is no longer valid and all the * references must be substituted with the new pointer returned by the call. */ sds sdscatlen(sds s, const void *t, size_t len) { // иҺ·еҸ–еҺҹеӯ—з¬ҰдёІзҡ„й•ҝеәҰ size_t curlen = sdslen(s); // жҢүйңҖи°ғж•ҙз©әй—ҙпјҢеҰӮжһңе®№йҮҸдёҚеӨҹе®№зәіиҝҪеҠ зҡ„еҶ…е®№пјҢе°ұдјҡйҮҚж–°еҲҶй…Қеӯ—иҠӮ数组并еӨҚеҲ¶еҺҹеӯ—з¬ҰдёІзҡ„еҶ…е®№еҲ°ж–°ж•°з»„дёӯ s = sdsMakeRoomFor(s,len); if (s == NULL) return NULL; // еҶ…еӯҳдёҚи¶і memcpy(s+curlen, t, len); // иҝҪеҠ зӣ®ж Үеӯ—з¬ҰдёІеҲ°еӯ—иҠӮж•°з»„дёӯ sdssetlen(s, curlen+len); // и®ҫзҪ®иҝҪеҠ еҗҺзҡ„й•ҝеәҰ s[curlen+len] = '\0'; // и®©еӯ—з¬ҰдёІд»Ҙ \0 з»“е°ҫпјҢдҫҝдәҺи°ғиҜ•жү“еҚ° return s; }еҜ№еӯ—з¬ҰдёІзҡ„еҹәжң¬ж“ҚдҪң
е®үиЈ…еҘҪ RedisпјҢжҲ‘们еҸҜд»ҘдҪҝз”Ё redis-cli жқҘеҜ№ Redis иҝӣиЎҢе‘Ҫд»ӨиЎҢзҡ„ж“ҚдҪңпјҢеҪ“然 Redis е®ҳж–№д№ҹжҸҗдҫӣдәҶеңЁзәҝзҡ„и°ғиҜ•еҷЁпјҢдҪ д№ҹеҸҜд»ҘеңЁйҮҢйқўж•Іе…Ҙе‘Ҫд»ӨиҝӣиЎҢж“ҚдҪңпјҡhttp://try.redis.io/#run
и®ҫзҪ®е’ҢиҺ·еҸ–й”®еҖјеҜ№
> SET key value OK > GET key "value"
жӯЈеҰӮдҪ зңӢеҲ°зҡ„пјҢжҲ‘们йҖҡеёёдҪҝз”Ё SET е’Ң GET жқҘи®ҫзҪ®е’ҢиҺ·еҸ–еӯ—з¬ҰдёІеҖјгҖӮ
еҖјеҸҜд»ҘжҳҜд»»дҪ•з§Қзұ»зҡ„еӯ—з¬ҰдёІпјҲеҢ…жӢ¬дәҢиҝӣеҲ¶ж•°жҚ®пјүпјҢдҫӢеҰӮдҪ еҸҜд»ҘеңЁдёҖдёӘй”®дёӢдҝқеӯҳдёҖеј .jpeg еӣҫзүҮпјҢеҸӘйңҖиҰҒжіЁж„ҸдёҚиҰҒи¶…иҝҮ 512 MB зҡ„жңҖеӨ§йҷҗеәҰе°ұеҘҪдәҶгҖӮ
еҪ“ key еӯҳеңЁж—¶пјҢSET е‘Ҫд»ӨдјҡиҰҶзӣ–жҺүдҪ дёҠдёҖж¬Ўи®ҫзҪ®зҡ„еҖјпјҡ
> SET key newValue OK > GET key "newValue"
еҸҰеӨ–дҪ иҝҳеҸҜд»ҘдҪҝз”Ё EXISTS е’Ң DEL е…ій”®еӯ—жқҘжҹҘиҜўжҳҜеҗҰеӯҳеңЁе’ҢеҲ йҷӨй”®еҖјеҜ№пјҡ
> EXISTS key (integer) 1 > DEL key (integer) 1 > GET key (nil)
жү№йҮҸи®ҫзҪ®й”®еҖјеҜ№
> SET key1 value1 OK > SET key2 value2 OK > MGET key1 key2 key3 # иҝ”еӣһдёҖдёӘеҲ—иЎЁ 1) "value1" 2) "value2" 3) (nil) > MSET key1 value1 key2 value2 > MGET key1 key2 1) "value1" 2) "value2"
иҝҮжңҹе’Ң SET е‘Ҫд»Өжү©еұ•
еҸҜд»ҘеҜ№ key и®ҫзҪ®иҝҮжңҹж—¶й—ҙпјҢеҲ°ж—¶й—ҙдјҡиў«иҮӘеҠЁеҲ йҷӨпјҢиҝҷдёӘеҠҹиғҪеёёз”ЁжқҘжҺ§еҲ¶зј“еӯҳзҡ„еӨұж•Ҳж—¶й—ҙгҖӮ(иҝҮжңҹеҸҜд»ҘжҳҜд»»ж„Ҹж•°жҚ®з»“жһ„)
> SET key value1 > GET key "value1" > EXPIRE name 5 # 5s еҗҺиҝҮжңҹ ... # зӯүеҫ… 5s > GET key (nil)
зӯүд»·дәҺ SET + EXPIRE зҡ„ SETNX е‘Ҫд»Өпјҡ
> SETNX key value1 ... # зӯүеҫ… 5s еҗҺиҺ·еҸ– > GET key (nil) > SETNX key value1 # еҰӮжһң key дёҚеӯҳеңЁеҲҷ SET жҲҗеҠҹ (integer) 1 > SETNX key value1 # еҰӮжһң key еӯҳеңЁеҲҷ SET еӨұиҙҘ (integer) 0 > GET key "value" # жІЎжңүж”№еҸҳ
и®Ўж•°
еҰӮжһң value жҳҜдёҖдёӘж•ҙж•°пјҢиҝҳеҸҜд»ҘеҜ№е®ғдҪҝз”Ё INCR е‘Ҫд»ӨиҝӣиЎҢ еҺҹеӯҗжҖ§ зҡ„иҮӘеўһж“ҚдҪңпјҢиҝҷж„Ҹе‘ізқҖеҸҠж—¶еӨҡдёӘе®ўжҲ·з«ҜеҜ№еҗҢдёҖдёӘ key иҝӣиЎҢж“ҚдҪңпјҢд№ҹеҶідёҚдјҡеҜјиҮҙз«һдәүзҡ„жғ…еҶөпјҡ
> SET counter 100 > INCR count (interger) 101 > INCRBY counter 50 (integer) 151
иҝ”еӣһеҺҹеҖјзҡ„ GETSET е‘Ҫд»Ө
еҜ№еӯ—з¬ҰдёІпјҢиҝҳжңүдёҖдёӘ GETSET жҜ”иҫғи®©дәәи§үеҫ—жңүж„ҸжҖқпјҢе®ғзҡ„еҠҹиғҪи·ҹе®ғеҗҚеӯ—дёҖж ·пјҡдёә key и®ҫзҪ®дёҖдёӘеҖје№¶иҝ”еӣһеҺҹеҖјпјҡ
> SET key value > GETSET key value1 "value"
иҝҷеҸҜд»ҘеҜ№дәҺжҹҗдёҖдәӣйңҖиҰҒйҡ”дёҖж®өж—¶й—ҙе°ұз»ҹи®Ўзҡ„ key еҫҲж–№дҫҝзҡ„и®ҫзҪ®е’ҢжҹҘзңӢпјҢдҫӢеҰӮпјҡзі»з»ҹжҜҸеҪ“з”ұз”ЁжҲ·иҝӣе…Ҙзҡ„ж—¶еҖҷдҪ е°ұжҳҜз”Ё INCR е‘Ҫд»Өж“ҚдҪңдёҖдёӘ keyпјҢеҪ“йңҖиҰҒз»ҹи®Ўж—¶еҖҷдҪ е°ұжҠҠиҝҷдёӘ key дҪҝз”Ё GETSET е‘Ҫд»ӨйҮҚж–°иөӢеҖјдёә 0пјҢиҝҷж ·е°ұиҫҫеҲ°дәҶз»ҹи®Ўзҡ„зӣ®зҡ„гҖӮ
2пјүеҲ—иЎЁ list
Redis зҡ„еҲ—иЎЁзӣёеҪ“дәҺ Java иҜӯиЁҖдёӯзҡ„ LinkedListпјҢжіЁж„Ҹе®ғжҳҜй“ҫиЎЁиҖҢдёҚжҳҜж•°з»„гҖӮиҝҷж„Ҹе‘ізқҖ list зҡ„жҸ’е…Ҙе’ҢеҲ йҷӨж“ҚдҪңйқһеёёеҝ«пјҢж—¶й—ҙеӨҚжқӮеәҰдёә O(1)пјҢдҪҶжҳҜзҙўеј•е®ҡдҪҚеҫҲж…ўпјҢж—¶й—ҙеӨҚжқӮеәҰдёә O(n)гҖӮ
жҲ‘们еҸҜд»Ҙд»Һжәҗз Ғзҡ„ adlist.h/listNode жқҘзңӢеҲ°еҜ№е…¶зҡ„е®ҡд№үпјҡ
/* Node, List, and Iterator are the only data structures used currently. */ typedef struct listNode { struct listNode *prev; struct listNode *next; void *value; } listNode; typedef struct listIter { listNode *next; int direction; } listIter; typedef struct list { listNode *head; listNode *tail; void *(*dup)(void *ptr); void (*free)(void *ptr); int (*match)(void *ptr, void *key); unsigned long len; } list;еҸҜд»ҘзңӢеҲ°пјҢеӨҡдёӘ listNode еҸҜд»ҘйҖҡиҝҮ prev е’Ң next жҢҮй’Ҳз»„жҲҗеҸҢеҗ‘й“ҫиЎЁпјҡ
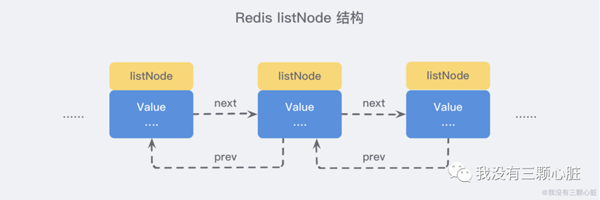
иҷҪ然仅仅дҪҝз”ЁеӨҡдёӘ listNode з»“жһ„е°ұеҸҜд»Ҙз»„жҲҗй“ҫиЎЁпјҢдҪҶжҳҜдҪҝз”Ё adlist.h/list з»“жһ„жқҘжҢҒжңүй“ҫиЎЁзҡ„иҜқпјҢж“ҚдҪңиө·жқҘдјҡжӣҙеҠ ж–№дҫҝпјҡ
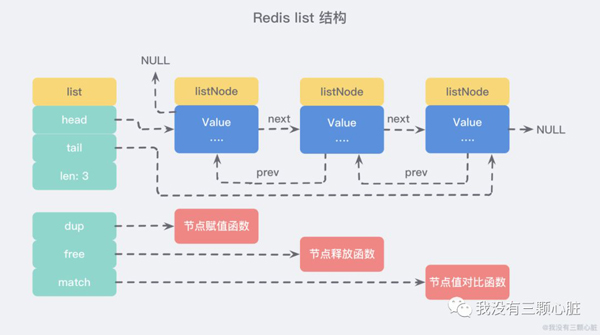
й“ҫиЎЁзҡ„еҹәжң¬ж“ҚдҪң
LPUSH е’Ң RPUSH еҲҶеҲ«еҸҜд»Ҙеҗ‘ list зҡ„е·Ұиҫ№пјҲеӨҙйғЁпјүе’ҢеҸіиҫ№пјҲе°ҫйғЁпјүж·»еҠ дёҖдёӘж–°е…ғзҙ пјӣ
LRANGE е‘Ҫд»ӨеҸҜд»Ҙд»Һ list дёӯеҸ–еҮәдёҖе®ҡиҢғеӣҙзҡ„е…ғзҙ пјӣ
LINDEX е‘Ҫд»ӨеҸҜд»Ҙд»Һ list дёӯеҸ–еҮәжҢҮе®ҡдёӢиЎЁзҡ„е…ғзҙ пјҢзӣёеҪ“дәҺ Java й“ҫиЎЁж“ҚдҪңдёӯзҡ„ get(int index) ж“ҚдҪңпјӣ
зӨәиҢғпјҡ
> rpush mylist A (integer) 1 > rpush mylist B (integer) 2 > lpush mylist first (integer) 3 > lrange mylist 0 -1 # -1 иЎЁзӨәеҖ’数第дёҖдёӘе…ғзҙ , иҝҷйҮҢиЎЁзӨәд»Һ第дёҖдёӘе…ғзҙ еҲ°жңҖеҗҺдёҖдёӘе…ғзҙ пјҢеҚіжүҖжңү 1) "first" 2) "A" 3) "B"
list е®һзҺ°йҳҹеҲ—
йҳҹеҲ—жҳҜе…Ҳиҝӣе…ҲеҮәзҡ„ж•°жҚ®з»“жһ„пјҢеёёз”ЁдәҺж¶ҲжҒҜжҺ’йҳҹе’ҢејӮжӯҘйҖ»иҫ‘еӨ„зҗҶпјҢе®ғдјҡзЎ®дҝқе…ғзҙ зҡ„и®ҝй—®йЎәеәҸпјҡ
> RPUSH books python java golang (integer) 3 > LPOP books "python" > LPOP books "java" > LPOP books "golang" > LPOP books (nil)
list е®һзҺ°ж Ҳ
ж ҲжҳҜе…ҲиҝӣеҗҺеҮәзҡ„ж•°жҚ®з»“жһ„пјҢи·ҹйҳҹеҲ—жӯЈеҘҪзӣёеҸҚпјҡ
> RPUSH books python java golang > RPOP books "golang" > RPOP books "java" > RPOP books "python" > RPOP books (nil)
3пјүеӯ—е…ё hash
Redis дёӯзҡ„еӯ—е…ёзӣёеҪ“дәҺ Java дёӯзҡ„ HashMapпјҢеҶ…йғЁе®һзҺ°д№ҹе·®дёҚеӨҡзұ»дјјпјҢйғҪжҳҜйҖҡиҝҮ "ж•°з»„ + й“ҫиЎЁ" зҡ„й“ҫең°еқҖжі•жқҘи§ЈеҶійғЁеҲҶ е“ҲеёҢеҶІзӘҒпјҢеҗҢж—¶иҝҷж ·зҡ„з»“жһ„д№ҹеҗёж”¶дәҶдёӨз§ҚдёҚеҗҢж•°жҚ®з»“жһ„зҡ„дјҳзӮ№гҖӮжәҗз Ғе®ҡд№үеҰӮ dict.h/dictht е®ҡд№үпјҡ
typedef struct dictht { // е“ҲеёҢиЎЁж•°з»„ dictEntry **table; // е“ҲеёҢиЎЁеӨ§е°Ҹ unsigned long size; // е“ҲеёҢиЎЁеӨ§е°ҸжҺ©з ҒпјҢз”ЁдәҺи®Ўз®—зҙўеј•еҖјпјҢжҖ»жҳҜзӯүдәҺ size - 1 unsigned long sizemask; // иҜҘе“ҲеёҢиЎЁе·ІжңүиҠӮзӮ№зҡ„ж•°йҮҸ unsigned long used; } dictht; typedef struct dict { dictType *type; void *privdata; // еҶ…йғЁжңүдёӨдёӘ dictht з»“жһ„ dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsigned long iterators; /* number of iterators currently running */ } dict;table еұһжҖ§жҳҜдёҖдёӘж•°з»„пјҢж•°з»„дёӯзҡ„жҜҸдёӘе…ғзҙ йғҪжҳҜдёҖдёӘжҢҮеҗ‘ dict.h/dictEntry з»“жһ„зҡ„жҢҮй’ҲпјҢиҖҢжҜҸдёӘ dictEntry з»“жһ„дҝқеӯҳзқҖдёҖдёӘй”®еҖјеҜ№пјҡ
typedef struct dictEntry { // й”® void *key; // еҖј union { void *val; uint64_t u64; int64_t s64; double d; } v; // жҢҮеҗ‘дёӢдёӘе“ҲеёҢиЎЁиҠӮзӮ№пјҢеҪўжҲҗй“ҫиЎЁ struct dictEntry *next; } dictEntry;еҸҜд»Ҙд»ҺдёҠйқўзҡ„жәҗз ҒдёӯзңӢеҲ°пјҢе®һйҷ…дёҠеӯ—е…ёз»“жһ„зҡ„еҶ…йғЁеҢ…еҗ«дёӨдёӘ hashtableпјҢйҖҡеёёжғ…еҶөдёӢеҸӘжңүдёҖдёӘ hashtable жҳҜжңүеҖјзҡ„пјҢдҪҶжҳҜеңЁеӯ—е…ёжү©е®№зј©е®№ж—¶пјҢйңҖиҰҒеҲҶй…Қж–°зҡ„ hashtableпјҢ然еҗҺиҝӣиЎҢ жёҗиҝӣејҸжҗ¬иҝҒ (дёӢйқўиҜҙеҺҹеӣ )гҖӮ
жёҗиҝӣејҸ rehash
еӨ§еӯ—е…ёзҡ„жү©е®№жҳҜжҜ”иҫғиҖ—ж—¶й—ҙзҡ„пјҢйңҖиҰҒйҮҚж–°з”іиҜ·ж–°зҡ„ж•°з»„пјҢ然еҗҺе°Ҷж—§еӯ—е…ёжүҖжңүй“ҫиЎЁдёӯзҡ„е…ғзҙ йҮҚж–°жҢӮжҺҘеҲ°ж–°зҡ„ж•°з»„дёӢйқўпјҢиҝҷжҳҜдёҖдёӘ O(n) зә§еҲ«зҡ„ж“ҚдҪңпјҢдҪңдёәеҚ•зәҝзЁӢзҡ„ Redis еҫҲйҡҫжүҝеҸ—иҝҷж ·иҖ—ж—¶зҡ„иҝҮзЁӢпјҢжүҖд»Ҙ Redis дҪҝз”Ё жёҗиҝӣејҸ rehash е°ҸжӯҘжҗ¬иҝҒпјҡ
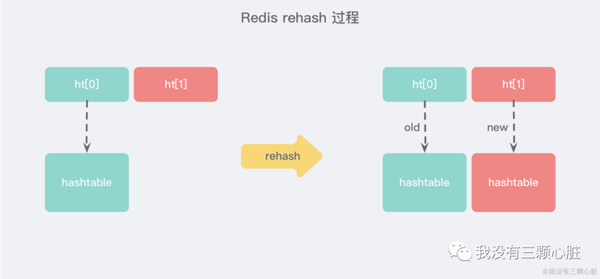
жёҗиҝӣејҸ rehash дјҡеңЁ rehash зҡ„еҗҢж—¶пјҢдҝқз•ҷж–°ж—§дёӨдёӘ hash з»“жһ„пјҢеҰӮдёҠеӣҫжүҖзӨәпјҢжҹҘиҜўж—¶дјҡеҗҢж—¶жҹҘиҜўдёӨдёӘ hash з»“жһ„пјҢ然еҗҺеңЁеҗҺз»ӯзҡ„е®ҡж—¶д»»еҠЎд»ҘеҸҠ hash ж“ҚдҪңжҢҮд»ӨдёӯпјҢеҫӘеәҸжёҗиҝӣзҡ„жҠҠж—§еӯ—е…ёзҡ„еҶ…е®№иҝҒ移еҲ°ж–°еӯ—е…ёдёӯгҖӮеҪ“жҗ¬иҝҒе®ҢжҲҗдәҶпјҢе°ұдјҡдҪҝз”Ёж–°зҡ„ hash з»“жһ„еҸ–иҖҢд»Јд№ӢгҖӮ
жү©зј©е®№зҡ„жқЎд»¶
жӯЈеёёжғ…еҶөдёӢпјҢеҪ“ hash иЎЁдёӯ е…ғзҙ зҡ„дёӘж•°зӯүдәҺ第дёҖз»ҙж•°з»„зҡ„й•ҝеәҰж—¶пјҢе°ұдјҡејҖе§Ӣжү©е®№пјҢжү©е®№зҡ„ж–°ж•°з»„жҳҜ еҺҹж•°з»„еӨ§е°Ҹзҡ„ 2 еҖҚгҖӮдёҚиҝҮеҰӮжһң Redis жӯЈеңЁеҒҡ bgsave(жҢҒд№…еҢ–е‘Ҫд»Ө)пјҢдёәдәҶеҮҸе°‘еҶ…еӯҳд№ҹеҫ—иҝҮеӨҡеҲҶзҰ»пјҢRedis е°ҪйҮҸдёҚеҺ»жү©е®№пјҢдҪҶжҳҜеҰӮжһң hash иЎЁйқһеёёж»ЎдәҶпјҢиҫҫеҲ°дәҶ第дёҖз»ҙж•°з»„й•ҝеәҰзҡ„ 5 еҖҚдәҶпјҢиҝҷдёӘж—¶еҖҷе°ұдјҡ ејәеҲ¶жү©е®№гҖӮ
еҪ“ hash иЎЁеӣ дёәе…ғзҙ йҖҗжёҗиў«еҲ йҷӨеҸҳеҫ—и¶ҠжқҘи¶ҠзЁҖз–Ҹж—¶пјҢRedis дјҡеҜ№ hash иЎЁиҝӣиЎҢзј©е®№жқҘеҮҸе°‘ hash иЎЁзҡ„第дёҖз»ҙж•°з»„з©әй—ҙеҚ з”ЁгҖӮжүҖз”Ёзҡ„жқЎд»¶жҳҜ е…ғзҙ дёӘж•°дҪҺдәҺж•°з»„й•ҝеәҰзҡ„ 10%пјҢзј©е®№дёҚдјҡиҖғиҷ‘ Redis жҳҜеҗҰеңЁеҒҡ bgsaveгҖӮ
еӯ—е…ёзҡ„еҹәжң¬ж“ҚдҪң
hash д№ҹжңүзјәзӮ№пјҢhash з»“жһ„зҡ„еӯҳеӮЁж¶ҲиҖ—иҰҒй«ҳдәҺеҚ•дёӘеӯ—з¬ҰдёІпјҢжүҖд»ҘеҲ°еә•иҜҘдҪҝз”Ё hash иҝҳжҳҜеӯ—з¬ҰдёІпјҢйңҖиҰҒж №жҚ®е®һйҷ…жғ…еҶөеҶҚдёүжқғиЎЎпјҡ
> HSET books java "think in java" # е‘Ҫд»ӨиЎҢзҡ„еӯ—з¬ҰдёІеҰӮжһңеҢ…еҗ«з©әж јеҲҷйңҖиҰҒдҪҝз”Ёеј•еҸ·еҢ…иЈ№ (integer) 1 > HSET books python "python cookbook" (integer) 1 > HGETALL books # key е’Ң value й—ҙйҡ”еҮәзҺ° 1) "java" 2) "think in java" 3) "python" 4) "python cookbook" > HGET books java "think in java" > HSET books java "head first java" (integer) 0 # еӣ дёәжҳҜжӣҙж–°ж“ҚдҪңпјҢжүҖд»Ҙиҝ”еӣһ 0 > HMSET books java "effetive java" python "learning python" # жү№йҮҸж“ҚдҪң OK
4пјүйӣҶеҗҲ set
Redis зҡ„йӣҶеҗҲзӣёеҪ“дәҺ Java иҜӯиЁҖдёӯзҡ„ HashSetпјҢе®ғеҶ…йғЁзҡ„й”®еҖјеҜ№жҳҜж— еәҸгҖҒе”ҜдёҖзҡ„гҖӮе®ғзҡ„еҶ…йғЁе®һзҺ°зӣёеҪ“дәҺдёҖдёӘзү№ж®Ҡзҡ„еӯ—е…ёпјҢеӯ—е…ёдёӯжүҖжңүзҡ„ value йғҪжҳҜдёҖдёӘеҖј NULLгҖӮ
йӣҶеҗҲ set зҡ„еҹәжң¬дҪҝз”Ё
з”ұдәҺиҜҘз»“жһ„жҜ”иҫғз®ҖеҚ•пјҢжҲ‘们зӣҙжҺҘжқҘзңӢзңӢжҳҜеҰӮдҪ•дҪҝз”Ёзҡ„пјҡ
> SADD books java (integer) 1 > SADD books java # йҮҚеӨҚ (integer) 0 > SADD books python golang (integer) 2 > SMEMBERS books # жіЁж„ҸйЎәеәҸпјҢset жҳҜж— еәҸзҡ„ 1) "java" 2) "python" 3) "golang" > SISMEMBER books java # жҹҘиҜўжҹҗдёӘ value жҳҜеҗҰеӯҳеңЁпјҢзӣёеҪ“дәҺ contains (integer) 1 > SCARD books # иҺ·еҸ–й•ҝеәҰ (integer) 3 > SPOP books # еј№еҮәдёҖдёӘ "java"
5пјүжңүеәҸеҲ—иЎЁ zset
иҝҷеҸҜиғҪдҪҝ Redis жңҖе…·зү№иүІзҡ„дёҖдёӘж•°жҚ®з»“жһ„дәҶпјҢе®ғзұ»дјјдәҺ Java дёӯ SortedSet е’Ң HashMap зҡ„з»“еҗҲдҪ“пјҢдёҖж–№йқўе®ғжҳҜдёҖдёӘ setпјҢдҝқиҜҒдәҶеҶ…йғЁ value зҡ„е”ҜдёҖжҖ§пјҢеҸҰдёҖж–№йқўе®ғеҸҜд»ҘдёәжҜҸдёӘ value иөӢдәҲдёҖдёӘ score еҖјпјҢз”ЁжқҘд»ЈиЎЁжҺ’еәҸзҡ„жқғйҮҚгҖӮ
е®ғзҡ„еҶ…йғЁе®һзҺ°з”Ёзҡ„жҳҜдёҖз§ҚеҸ«еҒҡ гҖҢи·іи·ғиЎЁгҖҚ зҡ„ж•°жҚ®з»“жһ„пјҢз”ұдәҺжҜ”иҫғеӨҚжқӮпјҢжүҖд»ҘеңЁиҝҷйҮҢз®ҖеҚ•жҸҗдёҖдёӢеҺҹзҗҶе°ұеҘҪдәҶпјҡ
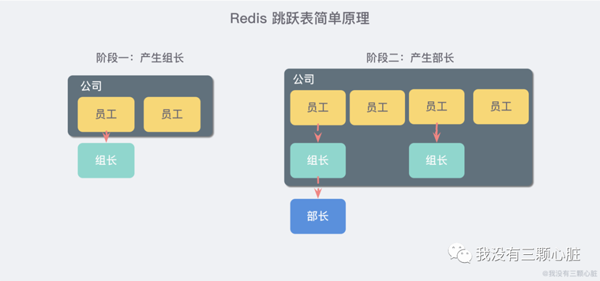
жғіиұЎдҪ жҳҜдёҖ家еҲӣдёҡе…¬еҸёзҡ„иҖҒжқҝпјҢеҲҡејҖе§ӢеҸӘжңүеҮ дёӘдәәпјҢеӨ§е®¶йғҪе№іиө·е№іеқҗгҖӮеҗҺжқҘйҡҸзқҖе…¬еҸёзҡ„еҸ‘еұ•пјҢдәәж•°и¶ҠжқҘи¶ҠеӨҡпјҢеӣўйҳҹжІҹйҖҡжҲҗжң¬йҖҗжёҗеўһеҠ пјҢжёҗжёҗең°еј•е…ҘдәҶз»„й•ҝеҲ¶пјҢеҜ№еӣўйҳҹиҝӣиЎҢеҲ’еҲҶпјҢдәҺжҳҜжңүдёҖдәӣдәәеҸҲжҳҜе‘ҳе·ҘеҸҲжңүз»„й•ҝзҡ„иә«д»ҪгҖӮ
еҶҚеҗҺжқҘпјҢе…¬еҸёи§„жЁЎиҝӣдёҖжӯҘжү©еӨ§пјҢе…¬еҸёйңҖиҰҒеҶҚиҝӣе…ҘдёҖдёӘеұӮзә§пјҡйғЁй—ЁгҖӮдәҺжҳҜжҜҸдёӘйғЁй—ЁеҸҲдјҡд»Һз»„й•ҝдёӯжҺЁдёҫдёҖдҪҚйҖүеҮәйғЁй•ҝгҖӮ
и·іи·ғиЎЁе°ұзұ»дјјдәҺиҝҷж ·зҡ„жңәеҲ¶пјҢжңҖдёӢйқўдёҖеұӮжүҖжңүзҡ„е…ғзҙ йғҪдјҡдёІиө·жқҘпјҢйғҪжҳҜе‘ҳе·ҘпјҢ然еҗҺжҜҸйҡ”еҮ дёӘе…ғзҙ е°ұдјҡжҢ‘йҖүеҮәдёҖдёӘд»ЈиЎЁпјҢеҶҚжҠҠиҝҷеҮ дёӘд»ЈиЎЁдҪҝз”ЁеҸҰеӨ–дёҖзә§жҢҮй’ҲдёІиө·жқҘгҖӮ然еҗҺеҶҚеңЁиҝҷдәӣд»ЈиЎЁйҮҢйқўжҢ‘еҮәдәҢзә§д»ЈиЎЁпјҢеҶҚдёІиө·жқҘгҖӮжңҖз»ҲеҪўжҲҗдәҶдёҖдёӘйҮ‘еӯ—еЎ”зҡ„з»“жһ„гҖӮ
жғідёҖдёӢдҪ зӣ®еүҚжүҖеңЁзҡ„ең°зҗҶдҪҚзҪ®пјҡдәҡжҙІ > дёӯеӣҪ > жҹҗзңҒ > жҹҗеёӮ > ....пјҢе°ұжҳҜиҝҷж ·дёҖдёӘз»“жһ„пјҒ
жңүеәҸеҲ—иЎЁ zset еҹәзЎҖж“ҚдҪң
> ZADD books 9.0 "think in java" > ZADD books 8.9 "java concurrency" > ZADD books 8.6 "java cookbook" > ZRANGE books 0 -1 # жҢү score жҺ’еәҸеҲ—еҮәпјҢеҸӮж•°еҢәй—ҙдёәжҺ’еҗҚиҢғеӣҙ 1) "java cookbook" 2) "java concurrency" 3) "think in java" > ZREVRANGE books 0 -1 # жҢү score йҖҶеәҸеҲ—еҮәпјҢеҸӮж•°еҢәй—ҙдёәжҺ’еҗҚиҢғеӣҙ 1) "think in java" 2) "java concurrency" 3) "java cookbook" > ZCARD books # зӣёеҪ“дәҺ count() (integer) 3 > ZSCORE books "java concurrency" # иҺ·еҸ–жҢҮе®ҡ value зҡ„ score "8.9000000000000004" # еҶ…йғЁ score дҪҝз”Ё double зұ»еһӢиҝӣиЎҢеӯҳеӮЁпјҢжүҖд»ҘеӯҳеңЁе°Ҹж•°зӮ№зІҫеәҰй—®йўҳ > ZRANK books "java concurrency" # жҺ’еҗҚ (integer) 1 > ZRANGEBYSCORE books 0 8.91 # ж №жҚ®еҲҶеҖјеҢәй—ҙйҒҚеҺҶ zset 1) "java cookbook" 2) "java concurrency" > ZRANGEBYSCORE books -inf 8.91 withscores # ж №жҚ®еҲҶеҖјеҢәй—ҙ (-∞, 8.91] йҒҚеҺҶ zsetпјҢеҗҢж—¶иҝ”еӣһеҲҶеҖјгҖӮinf д»ЈиЎЁ infiniteпјҢж— з©·еӨ§зҡ„ж„ҸжҖқгҖӮ 1) "java cookbook" 2) "8.5999999999999996" 3) "java concurrency" 4) "8.9000000000000004" > ZREM books "java concurrency" # еҲ йҷӨ value (integer) 1 > ZRANGE books 0 -1 1) "java cookbook" 2) "think in java"
еҲ°жӯӨпјҢе…ідәҺвҖңRedisзҡ„з®Җд»ӢеҸҠдјҳзјәзӮ№вҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





