这篇文章主要讲解了“LRU缓存算法的实现方法是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“LRU缓存算法的实现方法是什么”吧!
LRU就是Least Recently Used,即最近最少使用,是一种常用的页面置换算法,将最近长时间未使用的页面淘汰,其实也很简单,就是要将不受欢迎的页面及时淘汰,不让它占着茅坑不拉shit,浪费资源。
LRU是一种常见的页面置换算法,在计算中,所有的文件操作都要放在内存中进行,然而计算机内存大小是固定的,所以我们不可能把所有的文件都加载到内存,因此我们需要制定一种策略对加入到内存中的文件进项选择。
常见的页面置换算法有如下几种:
LRU 最近最久未使用
FIFO 先进先出置换算法 类似队列
OPT 最佳置换算法 (理想中存在的)
NRU Clock置换算法
LFU 最少使用置换算法
PBA 页面缓冲算法
LRU原理
LRU的设计原理就是,当数据在最近一段时间经常被访问,那么它在以后也会经常被访问。这就意味着,如果经常访问的数据,我们需要然其能够快速命中,而不常访问的数据,我们在容量超出限制内,要将其淘汰。
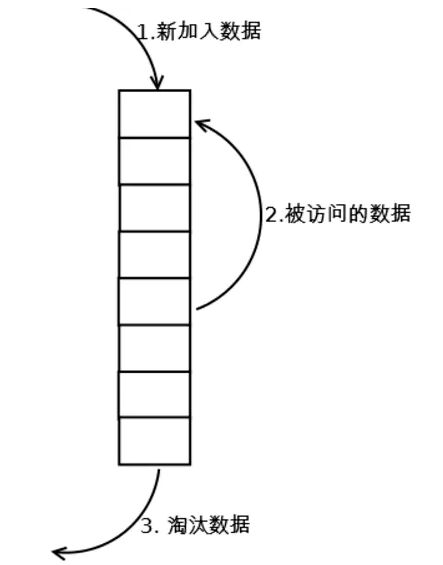
其核心就是利用栈,进行操作,其中主要有两项操作,get和put
get
get时,若栈中有值则将该值的key提到栈顶,没有时则返回null
put
栈未满时,若栈中有要put的key,则更新此key对应的value,并将该键值提到栈顶,若无要put的key,直接入栈
栈满时,若栈中有要put的key,则更新此key对应的value,并将该键值提到栈顶;若栈中没有put的key 时,去掉栈底元素,将put的值入到栈顶
解法:维护一个数组,提供 get 和 put 方法,并且限定 max 数量。
使用时,get 可以标记某个元素是最新使用的,提升它去第一项。put 可以加入某个key-value,但需要判断是否已经到最大限制 max
若未到能直接往数组第一项里插入 若到了最大限制 max,则需要淘汰数据尾端一个元素。
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ ); cache.put(1, 1); cache.put(2, 2); cache.get(1); // 返回 1 cache.put(3, 3); // 该操作会使得密钥 2 作废 cache.get(2); // 返回 -1 (未找到) cache.put(4, 4); // 该操作会使得密钥 1 作废 cache.get(1); // 返回 -1 (未找到) cache.get(3); // 返回 3 cache.get(4); // 返回 4LRU 算法设计
分析上面的操作过程,要让 put 和 get 方法的时间复杂度为 O(1),我们可以总结出 cache 这个数据结构必要的条件:查找快,插入快,删除快,有顺序之分。
因为显然 cache 必须有顺序之分,以区分最近使用的和久未使用的数据;而且我们要在 cache 中查找键是否已存在;如果容量满了要删除最后一个数据;每次访问还要把数据插入到队头。
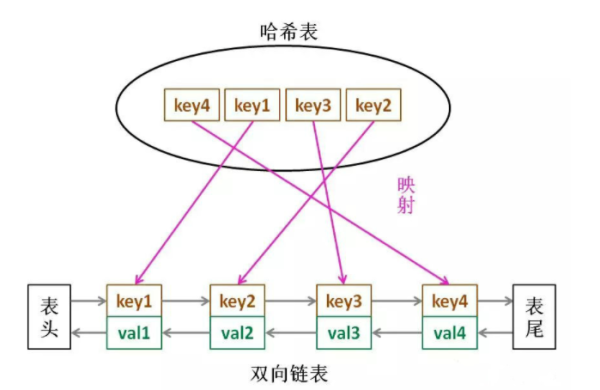
那么,什么数据结构同时符合上述条件呢?哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢。所以结合一下,形成一种新的数据结构:哈希链表。
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。这个数据结构长这样:
js 实现
具体代码 一般的解法,通过维护一个数组,数组项存放了 key-value 键值对对象,每次需要遍历去寻找 key 值所在的数组下标操作。
已经通过 leetCode 146 的检测。执行用时 : 720 ms。内存消耗 : 58.5 MB。
function LRUCache(capacity) { this.capacity = capacity; // 最大限制 this.cache = []; }; /** * @param {number} key * @return {number} */ LRUCache.prototype.get = function (key) { let index = this.cache.findIndex((item) => item.key === key); if (index === -1) { return -1; } // 删除此元素后插入到数组第一项 let value = this.cache[index].value; this.cache.splice(index, 1); this.cache.unshift({ key, value, }); return value; }; /** * @param {number} key * @param {number} value * @return {void} */ LRUCache.prototype.put = function (key, value) { let index = this.cache.findIndex((item) => item.key === key); // 想要插入的数据已经存在了,那么直接提升它就可以 if (index > -1) { this.cache.splice(index, 1); } else if (this.cache.length >= this.capacity) { // 若已经到达最大限制,先淘汰一个最久没有使用的 this.cache.pop(); } this.cache.unshift({ key, value }); };上面的做法其实有变种,可以通过一个对象来存键值对,一个数组来存放键的顺序。
进阶要求O(1)
时间复杂度 O(1),那就不能数组遍历去查找 key 值。可以用 ES6 的 Map 来解了,因为 Map 既能保持键值对,还能记住插入顺序。
function LRUCache(capacity) { this.cache = new Map(); this.capacity = capacity; // 最大限制 }; LRUCache.prototype.get = function (key) { if (this.cache.has(key)) { // 存在即更新 let temp = this.cache.get(key); this.cache.delete(key); this.cache.set(key, temp); return temp; } return -1; }; LRUCache.prototype.put = function (key, value) { if (this.cache.has(key)) { // 存在即更新(删除后加入) this.cache.delete(key); } else if (this.cache.size >= this.capacity) { // 不存在即加入 // 缓存超过最大值,则移除最近没有使用的 this.cache.delete(this.cache.keys().next().value); } this.cache.set(key, value); };感谢各位的阅读,以上就是“LRU缓存算法的实现方法是什么”的内容了,经过本文的学习后,相信大家对LRU缓存算法的实现方法是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/nT3p9-ryiqsMEXAf3zr5Gg



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



