иҪҜ件жһ¶жһ„д№ӢеҰӮдҪ•зҗҶи§ЈеүҚеҗҺз«ҜеҲҶзҰ»дёҺеүҚз«ҜжЁЎеқ—еҢ–
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңиҪҜ件жһ¶жһ„д№ӢеҰӮдҪ•зҗҶи§ЈеүҚеҗҺз«ҜеҲҶзҰ»дёҺеүҚз«ҜжЁЎеқ—еҢ–вҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңиҪҜ件жһ¶жһ„д№ӢеҰӮдҪ•зҗҶи§ЈеүҚеҗҺз«ҜеҲҶзҰ»дёҺеүҚз«ҜжЁЎеқ—еҢ–вҖқеҗ§пјҒ
еүҚеҗҺз«ҜеҲҶзҰ»жһ¶жһ„
еңЁжӯЈејҸиҜҙжҳҺеүҚеҗҺеҸ°жһ¶жһ„еҲҶзҰ»д№ӢеүҚпјҢжҲ‘们жқҘзңӢдёҖдёӢеӨҡе№ҙд№ӢеүҚпјҢдј з»ҹиҪҜ件ејҖеҸ‘зҡ„жһ¶жһ„жЁЎејҸгҖӮ
дёәд»Җд№ҲиҰҒеүҚеҗҺз«ҜеҲҶзҰ»
иҝҳи®°еҫ—йӣ¶еҮ е№ҙжҲ‘дёҠеӨ§еӯҰзҡ„ж—¶еҖҷпјҢеңЁеҲқеӯҰ Java Web ејҖеҸ‘ж—¶пјҢиҜҫжң¬дёҠд»Ӣз»Қзҡ„иҝҳжҳҜ JSP + Servlet иҝҷз§ҚеҫҲдј з»ҹзҡ„жһ¶жһ„жЁЎејҸпјҢиҝҷж—¶еҖҷеүҚз«Ҝе’ҢеҗҺз«ҜдёҡеҠЎйҖ»иҫ‘д»Јз ҒйғҪеңЁдёҖдёӘе·ҘзЁӢйҮҢйқўпјҢиҝҳжІЎжңүеҲҶзҰ»ејҖжқҘпјҢиҝҷз§ҚејҖеҸ‘жЁЎејҸеұһдәҺ Model1 жЁЎејҸпјҢиҷҪ然е®һзҺ°дәҶйҖ»иҫ‘еҠҹиғҪе’ҢжҳҫзӨәеҠҹиғҪзҡ„еҲҶзҰ»пјҢдҪҶжҳҜз”ұдәҺи§ҶеӣҫеұӮе’ҢжҺ§еҲ¶еұӮйғҪжҳҜз”ұ JSP йЎөйқўе®һзҺ°зҡ„пјҢеҚіи§ҶеӣҫеұӮе’ҢжҺ§еҲ¶еұӮ并没жңүе®һзҺ°еҲҶзҰ»гҖӮ
йҡҸзқҖеӯҰд№ зҡ„ж·ұе…Ҙд»ҘеҸҠжёҗжёҗжөҒиЎҢзҡ„дјҒдёҡеә”з”ЁејҖеҸ‘пјҢжҲ‘们жёҗжёҗзҡ„ж‘Ҳејғиҝҷз§ҚжҠҖжңҜйҖүеһӢпјҢ并ејҖе§ӢеңЁйЎ№зӣ®дёӯдҪҝз”ЁдәҶиӢҘе№ІејҖжәҗжЎҶжһ¶пјҢеёёз”Ёзҡ„жЎҶжһ¶з»„еҗҲжңү Spring +Struts/Spring MVC + Hibernate/Mybatis зӯүзӯүпјҢз”ұдәҺжЎҶжһ¶зҡ„дјҳи¶ҠжҖ§д»ҘеҸҠиүҜеҘҪзҡ„е°ҒиЈ…жҖ§дҪҝеҫ—иҝҷеҘ—ејҖеҸ‘жЎҶжһ¶з»„еҗҲиҝ…йҖҹжҲҗдёәеҗ„дёӘдјҒдёҡејҖеҸ‘дёӯзҡ„дёҚдәҢд№ӢйҖүпјҢиҝҷдәӣжЎҶжһ¶зҡ„еҮәзҺ°д№ҹеҮҸе°‘дәҶејҖеҸ‘иҖ…зҡ„йҮҚеӨҚзј–з Ғе·ҘдҪңпјҢз®ҖеҢ–ејҖеҸ‘пјҢеҠ еҝ«ејҖеҸ‘иҝӣеәҰпјҢйҷҚдҪҺз»ҙжҠӨйҡҫеәҰпјҢйҡҸд№ӢиҖҢзҒ«зғӯзҡ„жҳҜиҝҷеҘ—жҠҖжңҜжЎҶжһ¶иғҢеҗҺзҡ„ејҖеҸ‘жЁЎејҸпјҢеҚі MVC ејҖеҸ‘жЁЎејҸпјҢе®ғжҳҜдёәдәҶе…ӢжңҚ Model1 еӯҳеңЁзҡ„дёҚи¶іиҖҢи®ҫи®Ўзҡ„гҖӮ
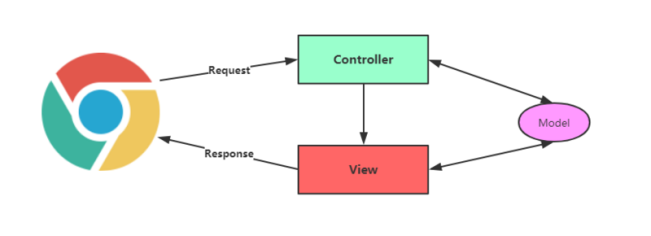
MVC зҡ„е…·дҪ“еҗ«д№үжҳҜпјҡModel + View + ControllerпјҢеҚіжЁЎеһӢ+и§Ҷеӣҫ+жҺ§еҲ¶еҷЁпјҢ
Model жЁЎеһӢеұӮпјҡ е®ғеёёеёёдҪҝз”Ё JavaBean жқҘзј–еҶҷпјҢе®ғжҺҘеҸ—и§ҶеӣҫеұӮиҜ·жұӮзҡ„ж•°жҚ®пјҢ然еҗҺиҝӣиЎҢзӣёеә”зҡ„дёҡеҠЎеӨ„зҗҶ并иҝ”еӣһжңҖз»Ҳзҡ„еӨ„зҗҶз»“жһңпјҢе®ғиҙҹжӢ…зҡ„иҙЈд»»жңҖдёәж ёеҝғпјҢ并еҲ©з”Ё JavaBean е…·жңүзҡ„зү№жҖ§е®һзҺ°дәҶд»Јз Ғзҡ„йҮҚз”Ёе’Ңжү©еұ•д»ҘеҸҠз»ҷз»ҙжҠӨеёҰжқҘдәҶж–№дҫҝгҖӮ
View и§ҶеӣҫеұӮпјҡ д»ЈиЎЁе’Ңз”ЁжҲ·дәӨдә’зҡ„з•ҢйқўпјҢиҙҹиҙЈж•°жҚ®зҡ„йҮҮйӣҶе’Ңеұ•зӨәпјҢйҖҡеёёз”ұ JSP е®һзҺ°гҖӮ
Controller жҺ§еҲ¶еұӮпјҡ жҺ§еҲ¶еұӮжҳҜд»Һз”ЁжҲ·з«ҜжҺҘ收иҜ·жұӮпјҢ然еҗҺе°ҶиҜ·жұӮдј йҖ’з»ҷжЁЎеһӢеұӮ并е‘ҠиҜүжЁЎеһӢеұӮеә”иҜҘи°ғз”Ёд»Җд№ҲеҠҹиғҪжЁЎеқ—жқҘеӨ„зҗҶиҜҘиҜ·жұӮпјҢе®ғе°ҶеҚҸи°ғи§ҶеӣҫеұӮе’ҢжЁЎеһӢеұӮд№Ӣй—ҙзҡ„е·ҘдҪңпјҢиө·еҲ°дёӯй—ҙжһўзәҪзҡ„дҪңз”ЁпјҢе®ғдёҖиҲ¬дәӨз”ұ Servlet жқҘе®һзҺ°гҖӮ
MVCзҡ„е·ҘдҪңжөҒзЁӢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
еҗҢж—¶пјҢйЎ№зӣ®ејҖеҸ‘еңЁиҝӣиЎҢжЁЎеқ—еҲҶеұӮж—¶д№ҹдјҡеҲ’еҲҶдёәдёүеұӮпјҡжҺ§еҲ¶еұӮпјҢдёҡеҠЎеұӮпјҢжҢҒд№…еұӮгҖӮжҺ§еҲ¶еұӮиҙҹиҙЈжҺҘ收еҸӮж•°пјҢи°ғз”Ёзӣёе…ідёҡеҠЎеұӮпјҢе°ҒиЈ…ж•°жҚ®пјҢд»ҘеҸҠи·Ҝз”ұ并е°Ҷж•°жҚ®жёІжҹ“еҲ° JSP йЎөйқўпјҢ然еҗҺеңЁ JSP йЎөйқўдёӯе°ҶеҗҺеҸ°зҡ„ж•°жҚ®еұ•зҺ°еҮәжқҘпјҢзӣёдҝЎеӨ§е®¶еҜ№иҝҷз§ҚејҖеҸ‘жЁЎејҸйғҪеҚҒеҲҶзҶҹжӮүпјҢдёҚз®ЎжҳҜдјҒдёҡејҖеҸ‘жҲ–иҖ…жҳҜдёӘдәәйЎ№зӣ®зҡ„жҗӯе»әпјҢиҝҷз§ҚејҖеҸ‘жЁЎејҸйғҪжҳҜеӨ§е®¶зҡ„йҰ–йҖүпјҢдёҚиҝҮпјҢйҡҸзқҖејҖеҸ‘еӣўйҳҹзҡ„жү©еӨ§е’ҢйЎ№зӣ®жһ¶жһ„зҡ„дёҚж–ӯжј”иҝӣпјҢиҝҷеҘ—ејҖеҸ‘жЁЎејҸжёҗжёҗжңүдәӣеҠӣдёҚд»ҺеҝғгҖӮ
жҺҘдёӢжқҘпјҢжҲ‘们жқҘеҲҶжһҗдёӢиҝҷеҘ—ејҖеҸ‘жЁЎејҸзҡ„з—ӣзӮ№гҖӮ
з—ӣзӮ№дёҖпјҡJSP ж•ҲзҺҮй—®йўҳ
йҰ–е…ҲпјҢJSP еҝ…йЎ»иҰҒеңЁ Servlet е®№еҷЁдёӯиҝҗиЎҢ(дҫӢеҰӮ TomcatпјҢjetty зӯү)пјҢеңЁиҜ·жұӮ JSP ж—¶д№ҹйңҖиҰҒиҝӣиЎҢдёҖж¬Ўзј–иҜ‘иҝҮзЁӢпјҢжңҖеҗҺиў«иҜ‘жҲҗ Java зұ»е’Ң class ж–Ү件пјҢиҝҷдәӣйғҪдјҡеҚ з”Ё PermGen з©әй—ҙпјҢеҗҢж—¶д№ҹйңҖиҰҒдёҖдёӘж–°зҡ„зұ»еҠ иҪҪеҷЁеҠ иҪҪпјҢJSP жҠҖжңҜдёҺ Java иҜӯиЁҖе’Ң Servlet жңүејәе…іиҒ”пјҢеңЁи§ЈиҖҰдёҠж— жі•дёҺжЁЎжқҝеј•ж“ҺжҲ–иҖ…зәҜ html йЎөйқўзӣёеӘІзҫҺгҖӮе…¶ж¬ЎжҜҸж¬ЎиҜ·жұӮ JSP еҗҺеҫ—еҲ°зҡ„е“Қеә”йғҪжҳҜ Servlet йҖҡиҝҮиҫ“еҮәжөҒиҫ“еҮәзҡ„ html йЎөйқўпјҢж•ҲзҺҮдёҠд№ҹжІЎжңүзӣҙжҺҘдҪҝз”Ё html й«ҳгҖӮз”ұдәҺ JSP дёҺ Servlet е®№еҷЁзҡ„ејәе…іиҒ”пјҢеңЁйЎ№зӣ®дјҳеҢ–ж—¶д№ҹж— жі•зӣҙжҺҘдҪҝз”Ё Nginx дҪңдёә JSP зҡ„ web жңҚеҠЎеҷЁпјҢжҖ§иғҪжҸҗеҚҮдёҚй«ҳгҖӮ
з—ӣзӮ№дәҢпјҡдәәе‘ҳеҲҶе·ҘдёҚжҳҺ
еңЁиҝҷз§ҚејҖеҸ‘жЁЎејҸдёӢзҡ„е·ҘдҪңжөҒзЁӢйҖҡеёёжҳҜпјҡи®ҫи®Ўдәәе‘ҳз»ҷеҮәйЎөйқўеҺҹеһӢи®ҫи®ЎеҗҺпјҢеүҚз«Ҝе·ҘзЁӢеёҲеҸӘиҙҹиҙЈе°Ҷи®ҫи®ЎеӣҫеҲҮжҲҗ html йЎөйқўпјҢд№ӢеҗҺеҲҷйңҖиҰҒз”ұеҗҺз«ҜејҖеҸ‘е·ҘзЁӢеёҲжқҘе°Ҷ html иҪ¬дёә JSP йЎөйқўиҝӣиЎҢйҖ»иҫ‘еӨ„зҗҶе’Ңж•°жҚ®еұ•зӨәгҖӮеңЁиҝҷз§Қе·ҘдҪңжЁЎејҸдёӢпјҢдәәдёәеҮәй”ҷзҺҮиҫғй«ҳпјҢеҗҺз«ҜејҖеҸ‘дәәе‘ҳд»»еҠЎжӣҙйҮҚпјҢдҝ®ж”№й—®йўҳж—¶йңҖиҰҒеҸҢж–№еҚҸеҗҢејҖеҸ‘пјҢж•ҲзҺҮдҪҺдёӢпјҢдёҖж—ҰеҮәзҺ°й—®йўҳеҗҺпјҢеүҚз«ҜејҖеҸ‘дәәе‘ҳйқўеҜ№зҡ„жҳҜе……ж»Ўж Үзӯҫе’ҢиЎЁиҫҫејҸзҡ„ JSP йЎөйқўпјҢеҗҺз«Ҝдәәе‘ҳеңЁйқўеҜ№ж ·ејҸжҲ–иҖ…дәӨдә’зҡ„й—®йўҳж—¶жң¬е°ұйҖ иҜЈдёҚй«ҳзҡ„еүҚз«ҜжҠҖжңҜд№ҹдјҡжҚүиҘҹи§ҒиӮҳгҖӮ
еңЁжҹҗдәӣзҙ§жҖҘжғ…еҶөдёӢд№ҹдјҡеҮәзҺ°еүҚз«Ҝдәәе‘ҳи°ғиҜ•еҗҺз«Ҝд»Јз ҒпјҢеҗҺз«ҜејҖеҸ‘дәәе‘ҳи°ғиҜ•еүҚз«Ҝд»Јз Ғиҝҷдәӣи®©дәәжҚ§и…№зҡ„зҺ°иұЎпјҢеҲҶе·ҘдёҚжҳҺзЎ®пјҢдё”жІҹйҖҡжҲҗжң¬еӨ§пјҢдёҖж—ҰжҹҗдәӣеҠҹиғҪйңҖиҰҒиҝ”е·ҘеҲҷйңҖиҰҒеүҚеҗҺз«ҜејҖеҸ‘дәәе‘ҳпјҢиҝҷз§Қжғ…еҶөдёӢпјҢеҜ№дәҺеүҚеҗҺз«Ҝдәәе‘ҳзҡ„еҗҺжңҹжҠҖжңҜжҲҗй•ҝд№ҹдёҚеҲ©пјҢеҗҺз«ҜиҝҪжұӮзҡ„жҳҜй«ҳ并еҸ‘гҖҒй«ҳеҸҜз”ЁгҖҒй«ҳжҖ§иғҪгҖҒе®үе…ЁгҖҒжһ¶жһ„дјҳеҢ–зӯүпјҢеүҚз«ҜиҝҪжұӮзҡ„жҳҜжЁЎеқ—еҢ–гҖҒ组件ж•ҙеҗҲгҖҒйҖҹеәҰжөҒз•…гҖҒе…је®№жҖ§гҖҒз”ЁжҲ·дҪ“йӘҢзӯүзӯүпјҢдҪҶжҳҜеңЁ MVC иҝҷз§ҚејҖеҸ‘жЁЎејҸдёӢжҳҫ然дјҡеҜ№иҝҷдәӣжҠҖжңҜдәәе‘ҳйғҪжңүдёҖе®ҡзҡ„жҺЈиӮҳгҖӮ
з—ӣзӮ№дёүпјҡдёҚеҲ©дәҺйЎ№зӣ®иҝӯд»Ј
йЎ№зӣ®еҲқжңҹпјҢдёәдәҶеҝ«йҖҹдёҠзәҝеә”з”ЁпјҢйҖүжӢ©дҪҝз”Ёиҝҷз§ҚејҖеҸ‘жЁЎејҸжқҘиҝӣиЎҢ Java Web йЎ№зӣ®зҡ„ејҖеҸ‘жҳҜйқһеёёжӯЈзЎ®зҡ„йҖүжӢ©пјҢжӯӨж—¶жөҒйҮҸдёҚеӨ§пјҢз”ЁжҲ·йҮҸд№ҹдёҚй«ҳпјҢ并дёҚдјҡжңүйқһеёёиӢӣеҲ»зҡ„жҖ§иғҪиҰҒжұӮпјҢдҪҶжҳҜйҡҸзқҖйЎ№зӣ®зҡ„дёҚж–ӯжҲҗй•ҝпјҢз”ЁжҲ·йҮҸе’ҢиҜ·жұӮеҺӢеҠӣд№ҹдјҡдёҚж–ӯжү©еӨ§пјҢеҜ№дәҺдә’иҒ”зҪ‘йЎ№зӣ®зҡ„жҖ§иғҪиҰҒжұӮжҳҜи¶ҠжқҘи¶Ҡй«ҳпјҢеҰӮжһңжӯӨж—¶зҡ„еүҚеҗҺз«ҜжЁЎеқ—дҫқж—§иҖҰеҗҲеңЁдёҖиө·жҳҜйқһеёёдёҚеҲ©дәҺеҗҺз»ӯжү©еұ•зҡ„гҖӮдёҫдҫӢиҜҙжҳҺдёҖдёӢпјҢдёәдәҶжҸҗй«ҳиҙҹиҪҪиғҪеҠӣпјҢжҲ‘们дјҡйҖүжӢ©еҒҡйӣҶзҫӨжқҘеҲҶжӢ…еҚ•дёӘеә”з”Ёзҡ„еҺӢеҠӣпјҢдҪҶжҳҜжЁЎеқ—зҡ„иҖҰеҗҲдјҡдҪҝеҫ—жҖ§иғҪзҡ„дјҳеҢ–з©әй—ҙи¶ҠжқҘи¶ҠдҪҺпјҢеӣ дёәеҚ•дёӘйЎ№зӣ®дјҡи¶ҠжқҘи¶ҠеӨ§пјҢдёҚиҝӣиЎҢеҗҲзҗҶзҡ„жӢҶеҲҶж— жі•еҒҡеҲ°жңҖеҘҪзҡ„дјҳеҢ–пјҢеҸҲжҲ–иҖ…еңЁеҸ‘зүҲйғЁзҪІдёҠзәҝзҡ„ж—¶еҖҷпјҢжҳҺжҳҺеҸӘж”№дәҶеҗҺз«Ҝзҡ„д»Јз ҒпјҢеүҚз«Ҝд№ҹйңҖиҰҒйҮҚж–°еҸ‘еёғпјҢжҲ–иҖ…жҳҺжҳҺеҸӘж”№дәҶйғЁеҲҶйЎөйқўжҲ–иҖ…йғЁеҲҶж ·ејҸпјҢеҗҺз«Ҝд»Јз Ғд№ҹйңҖиҰҒдёҖиө·еҸ‘еёғдёҠзәҝпјҢиҝҷдәӣйғҪжҳҜиҖҰеҗҲиҫғдёҘйҮҚж—¶еёёи§Ғзҡ„дёҚиүҜзҺ°иұЎпјҢеӣ жӯӨеҺҹе§Ӣзҡ„еүҚеҗҺз«ҜиҖҰеҗҲеңЁдёҖиө·зҡ„жһ¶жһ„жЁЎејҸе·Із»ҸйҖҗжёҗдёҚиғҪж»Ўи¶ійЎ№зӣ®зҡ„жј”иҝӣж–№еҗ‘пјҢйңҖиҰҒйңҖжүҫдёҖз§Қи§ЈиҖҰзҡ„ж–№ејҸжӣҝд»ЈеҪ“еүҚзҡ„ејҖеҸ‘жЁЎејҸгҖӮ
з—ӣзӮ№еӣӣпјҡдёҚж»Ўи¶ідёҡеҠЎйңҖжұӮ
йҡҸзқҖе…¬еҸёдёҡеҠЎзҡ„дёҚж–ӯеҸ‘еұ•пјҢд»…д»…еҸӘжңүжөҸи§ҲеҷЁз«Ҝзҡ„ Web еә”з”Ёе·Із»ҸйҖҗжёҗжҳҫеҫ—жңүдәӣдёҚеӨҹз”ЁдәҶпјҢзӣ®еүҚеҸҲжҳҜ移еҠЁдә’иҒ”зҪ‘жҖҘеү§еўһй•ҝзҡ„ж—¶д»ЈпјҢжүӢжңәз«Ҝзҡ„еҺҹз”ҹ App еә”з”Ёе·Із»ҸйқһеёёжҲҗзҶҹпјҢйҡҸзқҖ App иҪҜ件зҡ„еӨ§йҮҸжҷ®еҸҠи¶ҠжқҘи¶ҠеӨҡзҡ„дјҒдёҡд№ҹеҠ е…ҘеҲ° App иҪҜ件ејҖеҸ‘еҪ“дёӯжқҘпјҢдёәдәҶе°ҪеҸҜиғҪзҡ„жҠўеҚ е•Ҷжңәе’ҢжҸҗеҚҮз”ЁжҲ·дҪ“йӘҢпјҢдҪ жүҖеңЁзҡ„е…¬еҸёеҸҜиғҪд№ҹдёҚдјҡжҠҠжүҖжңүзҡ„ејҖеҸ‘иө„жәҗйғҪж”ҫеңЁ web еә”з”ЁдёҠпјҢиҖҢжҳҜеӨҡз«Ҝеә”з”ЁеҗҢж—¶ејҖеҸ‘пјҢжӯӨж—¶е…¬еҸёзҡ„дёҡеҠЎзәҝеҸҜиғҪе°ұжҳҜеҰӮдёӢзҡ„еҮ з§ҚжҲ–иҖ…е…¶дёӯдёҖйғЁеҲҶпјҡ
жөҸи§ҲеҷЁз«Ҝзҡ„ Web еә”з”ЁгҖҒiOS еҺҹз”ҹ AppгҖҒе®үеҚ“з«ҜеҺҹз”ҹ AppгҖҒеҫ®дҝЎе°ҸзЁӢеәҸзӯүзӯүпјҢеҸҜиғҪеҸӘжҳҜејҖеҸ‘е…¶дёӯзҡ„дёҖйғЁеҲҶдә§е“ҒпјҢдҪҶжҳҜйҷӨдәҶ web еә”з”ЁиғҪеӨҹдҪҝз”Ёдј з»ҹзҡ„ MVC жЁЎејҸејҖеҸ‘еӨ–пјҢе…¶д»–зҡ„йғҪж— жі•дҪҝз”ЁиҜҘжЁЎејҸиҝӣиЎҢејҖеҸ‘пјҢеғҸеҺҹз”ҹ App жҲ–иҖ…еҫ®дҝЎе°ҸзЁӢеәҸйғҪжҳҜйҖҡиҝҮи°ғз”Ё RESTful api зҡ„ж–№ејҸдёҺеҗҺз«ҜиҝӣиЎҢж•°жҚ®дәӨдә’гҖӮ
йҡҸзқҖдә’иҒ”зҪ‘жҠҖжңҜзҡ„еҸ‘еұ•пјҢжӣҙеӨҡзҡ„жҠҖжңҜжЎҶжһ¶иў«жҸҗдәҶеҮәжқҘпјҢе…¶дёӯжңҖйқ©е‘ҪжҖ§зҡ„е°ұжҳҜеүҚеҗҺз«ҜеҲҶзҰ»жҰӮеҝөзҡ„жҸҗеҮәгҖӮ
д»Җд№ҲжҳҜеүҚеҗҺз«ҜеҲҶзҰ»
дҪ•дёәеүҚеҗҺз«ҜеҲҶзҰ»пјҢжҲ‘и®Өдёәеә”иҜҘд»Һд»ҘдёӢеҮ дёӘж–№йқўжқҘзҗҶи§ЈгҖӮ
еүҚеҗҺз«ҜеҲҶзҰ»жҳҜдёҖз§ҚйЎ№зӣ®ејҖеҸ‘жЁЎејҸ
еҪ“дёҡеҠЎеҸҳеҫ—и¶ҠжқҘи¶ҠеӨҚжқӮжҲ–иҖ…дә§е“Ғзәҝи¶ҠжқҘи¶ҠеӨҡпјҢеҺҹжңүзҡ„ејҖеҸ‘жЁЎејҸе·Із»Ҹж— жі•ж»Ўи¶ідёҡеҠЎйңҖжұӮпјҢеҪ“з«ҜдёҠзҡ„дә§е“Ғи¶ҠжқҘи¶ҠеӨҡпјҢеұ•зҺ°еұӮзҡ„еҸҳеҢ–и¶ҠжқҘи¶Ҡеҝ«гҖҒи¶ҠжқҘи¶ҠеӨҡпјҢжӯӨж—¶е°ұеә”иҜҘиҝӣиЎҢеүҚеҗҺз«ҜеҲҶзҰ»еҲҶеұӮжҠҪиұЎпјҢз®ҖеҢ–ж•°жҚ®иҺ·еҸ–иҝҮзЁӢпјҢжҜ”еҰӮзӣ®еүҚжҜ”иҫғеёёз”Ёзҡ„е°ұжҳҜеүҚз«Ҝдәәе‘ҳиҮӘиЎҢе®һзҺ°и·іиҪ¬йҖ»иҫ‘е’ҢйЎөйқўдәӨдә’пјҢеҗҺз«ҜеҸӘиҙҹиҙЈжҸҗдҫӣжҺҘеҸЈж•°жҚ®пјҢдәҢиҖ…д№Ӣй—ҙйҖҡиҝҮи°ғз”Ё RESTful api зҡ„ж–№ејҸжқҘиҝӣиЎҢж•°жҚ®дәӨдә’пјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
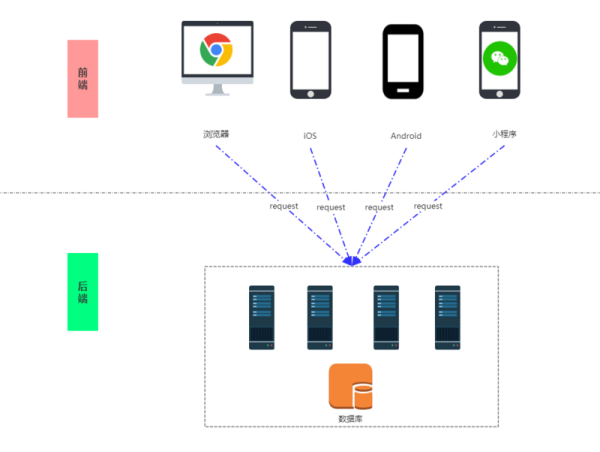
жӯӨж—¶е°ұдёҚдјҡеҮәзҺ° HTML д»Јз ҒйңҖиҰҒиҪ¬жҲҗ JSP иҝӣиЎҢејҖеҸ‘зҡ„жғ…еҶөпјҢеүҚз«ҜйЎ№зӣ®еҸӘиҙҹиҙЈеүҚз«ҜйғЁеҲҶпјҢ并дёҚдјҡжҺәжқӮд»»дҪ•еҗҺз«Ҝд»Јз ҒпјҢиҝҷж ·зҡ„иҜқд»Јз ҒдёҚеҶҚиҖҰеҗҲгҖӮеҗҢж—¶пјҢеүҚз«ҜйЎ№зӣ®дёҺеҗҺз«ҜйЎ№зӣ®д№ҹдёҚдјҡеҶҚеҮәзҺ°иҖҰеҗҲдёҘйҮҚзҡ„зҺ°иұЎпјҢеҸӘиҰҒеүҚеҗҺз«ҜеҚҸе•Ҷе’Ңе®ҡд№үеҘҪжҺҘеҸЈи§„иҢғеҸҠж•°жҚ®дәӨдә’规иҢғпјҢеҸҢж–№е°ұеҸҜд»Ҙ并иЎҢејҖеҸ‘пјҢдә’дёҚе№Іжү°пјҢдёҡеҠЎд№ҹдёҚдјҡиҖҰеҗҲпјҢдёӨз«ҜеҸӘйҖҡиҝҮжҺҘеҸЈжқҘиҝӣиЎҢдәӨдә’гҖӮ
еңЁ MVC жЁЎејҸејҖеҸ‘йЎ№зӣ®ж—¶пјҢеҫҖеҫҖеҗҺз«ҜиҝҮйҮҚпјҢвҖңжҺ§еҲ¶жқғвҖқд№ҹжҜ”иҫғеӨ§пјҢж—ўиҰҒиҙҹиҙЈеӨ„зҗҶдёҡеҠЎйҖ»иҫ‘гҖҒжқғйҷҗз®ЎзҗҶзӯүеҗҺз«Ҝж“ҚдҪңпјҢд№ҹйңҖиҰҒеӨ„зҗҶйЎөйқўи·іиҪ¬зӯүйҖ»иҫ‘пјҢеңЁеүҚеҗҺз«ҜеҲҶзҰ»зҡ„жЁЎејҸдёӯпјҢеҗҺз«Ҝз”ұеҺҹжқҘзҡ„еӨ§еҢ…еӨ§жҸҪдјјзҡ„зӢ¬иЈҒиҖ…еҸҳжҲҗдәҶжҺҘеҸЈжҸҗдҫӣиҖ…пјҢиҖҢеүҚз«Ҝд№ҹдёҚд»…д»…жҳҜеҺҹжқҘйӮЈж ·д»…еӨ„зҗҶе°ҸйғЁеҲҶдёҡеҠЎпјҢйЎөйқўи·іиҪ¬д№ҹдёҚеҶҚз”ұеҗҺз«ҜжқҘеӨ„зҗҶе’ҢеҶіе®ҡпјҢж•ҙдёӘйЎ№зӣ®зҡ„жҺ§еҲ¶жқғе·Із»Ҹз”ұеҗҺз«ҜиҝҮжёЎиҮіеүҚз«ҜжқҘжҺҢжҺ§пјҢеүҚз«ҜйңҖиҰҒеӨ„зҗҶзҡ„жӣҙеӨҡгҖӮ
еүҚз«ҜйЎ№зӣ®е’ҢеҗҺз«ҜйЎ№зӣ®йҡ”зҰ»ејҖжқҘгҖҒдә’дёҚе№Іж¶үпјҢйҖҡиҝҮжҺҘеҸЈе’Ңж•°жҚ®и§„иҢғжқҘе®ҢжҲҗйЎ№зӣ®еҠҹиғҪйңҖжұӮпјҢиҝҷд№ҹжҳҜзӣ®еүҚжҜ”иҫғжөҒиЎҢзҡ„дёҖз§ҚејҖеҸ‘ж–№ејҸгҖӮ
еүҚеҗҺз«ҜеҲҶзҰ»жҳҜдёҖз§Қдәәе‘ҳеҲҶе·Ҙ
еңЁеүҚеҗҺз«ҜеҲҶзҰ»зҡ„жһ¶жһ„жЁЎејҸдёӢпјҢеҗҺеҸ°иҙҹиҙЈж•°жҚ®жҸҗдҫӣпјҢеүҚз«ҜиҙҹиҙЈжҳҫзӨәдәӨдә’пјҢеңЁиҝҷз§ҚејҖеҸ‘жЁЎејҸдёӢпјҢеүҚз«ҜејҖеҸ‘дәәе‘ҳе’ҢеҗҺз«ҜејҖеҸ‘дәәе‘ҳеҲҶе·ҘжҳҺзЎ®пјҢиҒҢиҙЈеҲ’еҲҶеҚҒеҲҶжё…жҷ°пјҢеҸҢж–№еҗ„еҸёе…¶иҒҢпјҢдёҚдјҡеӯҳеңЁиҫ№з•ҢдёҚжё…жҷ°зҡ„ең°ж–№пјҢ并且д»Һдёҡдәәе‘ҳд№ҹеҗ„еҸёе…¶иҒҢгҖӮ
еүҚз«ҜејҖеҸ‘дәәе‘ҳеҢ…жӢ¬ Web ејҖеҸ‘дәәе‘ҳгҖҒеҺҹз”ҹ App ејҖеҸ‘дәәе‘ҳпјҢеҗҺз«ҜејҖеҸ‘еҲҷжҳҜжҢҮ Java ејҖеҸ‘дәәе‘ҳ(д»Ҙ Java иҜӯиЁҖдёәдҫӢ)пјҢдёҚеҗҢзҡ„ејҖеҸ‘дәәе‘ҳеҸӘйңҖиҰҒжіЁйҮҚиҮӘе·ұжүҖиҙҹиҙЈзҡ„йЎ№зӣ®еҚіеҸҜгҖӮеҗҺз«Ҝдё“жіЁдәҺжҺ§еҲ¶еұӮ(RESTful API)гҖҒжңҚеҠЎеұӮ гҖҒж•°жҚ®и®ҝй—®еұӮпјҢеүҚз«Ҝдё“жіЁдәҺеүҚз«ҜжҺ§еҲ¶еұӮгҖҒ и§ҶеӣҫеұӮпјҢдёҚдјҡеҶҚеҮәзҺ°еүҚз«Ҝдәәе‘ҳйңҖиҰҒз»ҙжҠӨйғЁеҲҶеҗҺз«Ҝд»Јз ҒпјҢжҲ–иҖ…еҗҺз«ҜејҖеҸ‘дәәе‘ҳйңҖиҰҒеҺ»и°ғиҜ•ж ·ејҸзӯүзӯүиҒҢиҙЈдёҚжё…е’ҢеүҚеҗҺз«ҜиҖҰеҗҲзҡ„жғ…еҶөпјҢжҲ‘们йҖҡиҝҮдёӨеј йЎ№зӣ®ејҖеҸ‘жөҒзЁӢз®ҖеӣҫжқҘеҜ№жҜ”пјҡ
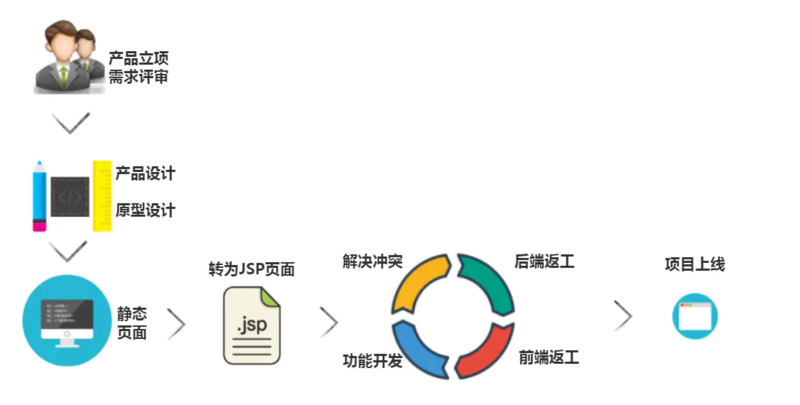
жӯӨж—¶пјҢејҖеҸ‘иҝҮзЁӢдёӯдјҡеӯҳеңЁеүҚеҗҺз«ҜиҖҰеҗҲзҡ„жғ…еҶөпјҢеҰӮжһңеҮәзҺ°й—®йўҳеүҚз«ҜйңҖиҰҒиҝ”е·ҘгҖҒеҗҺз«Ҝд№ҹйңҖиҰҒиҝ”е·ҘпјҢејҖеҸ‘ж•ҲзҺҮдјҡжңүжүҖеҪұе“ҚгҖӮзҺ°еңЁпјҢеүҚеҗҺз«ҜеҲҶзҰ»еҗҺжөҒзЁӢз®ҖеӣҫеҰӮдёӢпјҡ
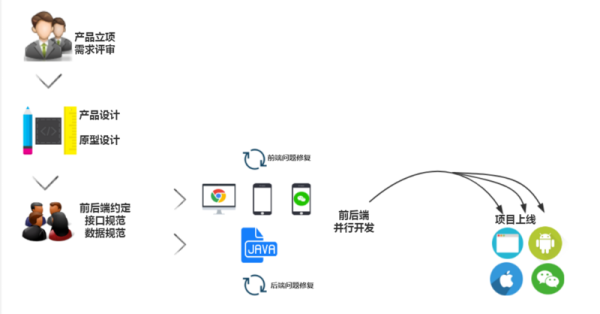
еүҚеҗҺз«ҜеҲҶзҰ»еҗҺпјҢжңҚеҠЎеҷЁз«ҜејҖеҸ‘дәәе‘ҳе’ҢеүҚз«ҜејҖеҸ‘дәәе‘ҳеҗ„е№Іеҗ„зҡ„пјҢеӨ§е®¶дә’дёҚе№Іжү°пјҢгҖӮеңЁи®ҫи®Ўе®ҢжҲҗеҗҺпјҢWeb з«ҜејҖеҸ‘дәәе‘ҳгҖҒApp з«ҜејҖеҸ‘дәәе‘ҳгҖҒеҗҺз«ҜејҖеҸ‘дәәе‘ҳйғҪеҸҜд»ҘжҠ•е…ҘеҲ°ејҖеҸ‘е·ҘдҪңеҪ“дёӯпјҢиғҪеӨҹеҒҡеҲ°е№¶иЎҢејҖеҸ‘пјҢеүҚз«ҜејҖеҸ‘дәәе‘ҳдёҺеҗҺз«ҜејҖеҸ‘дәәе‘ҳиҒҢиҙЈеҲҶзҰ»пјҢеҚідҪҝеҮәзҺ°й—®йўҳпјҢд№ҹжҳҜдҝ®еӨҚеҗ„иҮӘзҡ„й—®йўҳдёҚдјҡдә’зӣёеҪұе“Қе’ҢиҖҰеҗҲпјҢејҖеҸ‘ж•ҲзҺҮй«ҳдё”ж»Ўи¶ідјҒдёҡеҜ№дәҺеӨҡдә§е“Ғзәҝзҡ„ејҖеҸ‘йңҖжұӮгҖӮ
еүҚеҗҺз«ҜеҲҶзҰ»жҳҜдёҖз§Қжһ¶жһ„жЁЎејҸ
еүҚеҗҺз«ҜеҲҶзҰ»еҗҺпјҢеҗ„з«Ҝеә”з”ЁеҸҜд»ҘзӢ¬з«Ӣжү“еҢ…йғЁзҪІпјҢ并й’ҲеҜ№жҖ§зҡ„еҜ№йғЁзҪІж–№ејҸиҝӣиЎҢдјҳеҢ–пјҢдёҚеҶҚжҳҜеүҚеҗҺз«ҜдёҖдёӘз»ҹдёҖзҡ„е·ҘзЁӢжңҖз»Ҳжү“жҲҗдёҖдёӘйғЁзҪІеҢ…иҝӣиЎҢйғЁзҪІгҖӮд»Ҙ Web еә”з”ЁдёәдҫӢпјҢеүҚз«ҜйЎ№зӣ®йғЁзҪІеҗҺпјҢдёҚеҶҚдҫқиө–дәҺ Servlet е®№еҷЁпјҢеҸҜд»ҘдҪҝз”ЁеҗһеҗҗйҮҸжӣҙеӨ§зҡ„ Nginx жңҚеҠЎеҷЁпјҢйҮҮз”ЁеҠЁйқҷеҲҶзҰ»зҡ„йғЁзҪІж–№ејҸпјҢж—ўжҸҗеҚҮдәҶеүҚз«Ҝзҡ„и®ҝй—®дҪ“йӘҢпјҢд№ҹеҮҸиҪ»дәҶеҗҺз«ҜжңҚеҠЎеҷЁзҡ„еҺӢеҠӣпјҢеҶҚиҝӣдёҖжӯҘдјҳеҢ–зҡ„иҜқпјҢеҸҜд»ҘдҪҝз”ЁйЎөйқўзј“еӯҳгҖҒжөҸи§ҲеҷЁзј“еӯҳзӯүи®ҫзҪ®пјҢд№ҹеҸҜд»ҘдҪҝз”Ё CDN зӯүдә§е“ҒжҸҗеҚҮйқҷжҖҒиө„жәҗзҡ„и®ҝй—®ж•ҲзҺҮгҖӮеҜ№дәҺеҗҺз«ҜжңҚеҠЎиҖҢиЁҖпјҢеҸҜд»ҘиҝӣиЎҢйӣҶзҫӨйғЁзҪІжҸҗеҚҮжңҚеҠЎзҡ„е“Қеә”ж•ҲзҺҮпјҢд№ҹеҸҜд»ҘиҝӣдёҖжӯҘзҡ„иҝӣиЎҢжңҚеҠЎеҢ–зҡ„жӢҶеҲҶзӯүзӯүгҖӮеүҚеҗҺз«ҜеҲҶзҰ»еҗҺзҡ„зӢ¬з«ӢйғЁзҪІз»ҙжҠӨд»ҘеҸҠй’ҲеҜ№жҖ§зҡ„дјҳеҢ–пјҢеҸҜд»ҘеҠ еҝ«ж•ҙдҪ“е“Қеә”йҖҹеәҰе’ҢеҗһеҗҗйҮҸгҖӮ
еүҚз«ҜеҸ‘еұ•еҺҶзЁӢ
еҪ“жҲ‘们еҺ»дәҶи§ЈжҹҗдёӘдәӢзү©зҡ„ж—¶еҖҷпјҢйҰ–е…ҲжҲ‘们йңҖиҰҒеҺ»дәҶи§Је®ғзҡ„еҺҶеҸІпјҢжүҚиғҪжӣҙеҘҪзҡ„жҠҠжҸЎе®ғзҡ„жңӘжқҘгҖӮ
еҺҹе§Ӣж—¶д»Ј
дё–з•ҢдёҠ第дёҖж¬ҫжөҸи§ҲеҷЁ NCSAMosaic пјҢжҳҜзҪ‘жҷҜе…¬еҸё(Netscape)еңЁ1994е№ҙејҖеҸ‘еҮәжқҘзҡ„пјҢе®ғзҡ„еҲқиЎ·жҳҜдёәдәҶж–№дҫҝз§‘з ”дәәе‘ҳжҹҘйҳ…иө„ж–ҷгҖҒж–ҮжЎЈ(иҝҷдёӘж—¶еҖҷзҡ„ж–ҮжЎЈеӨ§еӨҡжҳҜеӣҫзүҮеҪўејҸзҡ„)гҖӮйӮЈдёӘж—¶д»Јзҡ„жҜҸдёҖдёӘдәӨдә’пјҢжҢүй’®зӮ№еҮ»гҖҒиЎЁеҚ•жҸҗдәӨпјҢйғҪйңҖиҰҒзӯүеҫ…жөҸи§ҲеҷЁе“Қеә”еҫҲй•ҝж—¶й—ҙпјҢ然еҗҺйҮҚж–°дёӢиҪҪдёҖдёӘж–°йЎөйқўгҖӮ
еҗҢе№ҙ PHP(и¶…ж–Үжң¬йў„еӨ„зҗҶеҷЁ) и„ҡжң¬иҜӯиЁҖиў«ејҖеҸ‘еҮәжқҘпјҢејҖеҗҜдәҶж•°жҚ®еөҢе…ҘжЁЎжқҝзҡ„ MVC жЁЎејҸпјҢеҗҢж—¶жңҹжҜ”иҫғзұ»дјјзҡ„еҒҡжі•жңүд»ҘдёӢеҮ з§Қпјҡ
PHP зӣҙжҺҘе°Ҷж•°жҚ®еҶ…еөҢеҲ° HTML дёӯгҖӮ
ASP зҡ„ ASPXпјҢеңЁ HTML дёӯеөҢе…Ҙ C# д»Јз ҒгҖӮ
Java зҡ„ JSP зӣҙжҺҘе°Ҷж•°жҚ®еөҢе…ҘеҲ°зҪ‘йЎөдёӯгҖӮ
иҝҷдёӘж—¶жңҹпјҢжөҸи§ҲеҷЁзҡ„ејҖеҸ‘иҖ…пјҢд»ҘеҗҺеҸ°ејҖеҸ‘дәәе‘ҳеұ…еӨҡпјҢеӨ§йғЁеҲҶеүҚеҗҺз«ҜејҖеҸ‘жҳҜдёҖдҪ“зҡ„пјҢеӨ§иҮҙејҖеҸ‘жөҒзЁӢжҳҜпјҡеҗҺз«Ҝ收еҲ°жөҸи§ҲеҷЁзҡ„иҜ·жұӮ ---> еҸ‘йҖҒйқҷжҖҒйЎөйқў ---> еҸ‘йҖҒеҲ°жөҸи§ҲеҷЁгҖӮеҚідҪҝжҳҜжңүдё“й—Ёзҡ„еүҚз«ҜејҖеҸ‘пјҢд№ҹеҸӘжҳҜз”Ё HTML еҶҷеҶҷйЎөйқўжЁЎжқҝгҖҒCSS з»ҷйЎөйқўжҺ’дёӘеҘҪзңӢзӮ№зҡ„зүҲејҸгҖӮеңЁиҝҷдёҖж—¶жңҹпјҢеүҚз«Ҝзҡ„дҪңз”ЁжңүйҷҗпјҢеҫҖеҫҖеҸӘжҳҜеҲҮеӣҫд»”зҡ„и§’иүІгҖӮ
й“ҒеҷЁж—¶д»Ј
1995е№ҙпјҢзҪ‘жҷҜе…¬еҸёзҡ„дёҖдҪҚеҸ«еёғе…°зҷ»·иүҫеҘҮзҡ„еӨ§дҪ¬пјҢеёҢжңӣејҖеҸ‘еҮәдёҖдёӘзұ»дјј Java зҡ„и„ҡжң¬иҜӯиЁҖпјҢз”ЁжқҘжҸҗеҚҮжөҸи§ҲеҷЁзҡ„еұ•зӨәж•ҲжһңпјҢеўһејәеҠЁжҖҒдәӨдә’иғҪеҠӣгҖӮз»“жһңеӨ§дҪ¬е–қзқҖе•Өй…’жҠҪзқҖзғҹпјҢеҚҒжқҘеӨ©е°ұжҠҠиҝҷдёӘи„ҡжң¬иҜӯиЁҖеҶҷеҮәжқҘдәҶпјҢеҠҹиғҪеҫҲејәеӨ§пјҢе°ұжҳҜиҜӯжі•дёҖзӮ№йғҪдёҚеғҸ JavaгҖӮиҝҷж ·е°ұжёҗжёҗеҪўжҲҗдәҶеүҚз«Ҝзҡ„йӣҸеҪўпјҡHTML дёәйӘЁжһ¶пјҢCSS дёәеӨ–иІҢпјҢJavaScript дёәдәӨдә’гҖӮ
еҗҢж—¶жңҹеҫ®иҪҜзӯүдёҖдәӣе…¬еҸёд№ҹй’ҲеҜ№иҮӘ家жөҸи§ҲеҷЁејҖеҸ‘еҮәдәҶиҮӘе·ұзҡ„и„ҡжң¬иҜӯиЁҖгҖӮжөҸи§ҲеҷЁдә”иҠұе…«й—ЁпјҢиҷҪ然жңүдәҶжҜ”иҫғз»ҹдёҖзҡ„ ECMA ж ҮеҮҶпјҢдҪҶжҳҜжөҸи§ҲеҷЁе…ҲдәҺж ҮеҮҶеңЁеёӮеңәдёҠжөҒиЎҢејҖжқҘпјҢжҲҗдёәдәҶдәӢе®һж ҮеҮҶгҖӮеҜјиҮҙпјҢзҺ°еңЁеүҚз«Ҝе·ҘзЁӢеёҲиҝҳиҰҒеңЁеҒҡдёҖдәӣж”ҝеәңеҸӨиҖҒйЎ№зӣ®зҡ„ж—¶еҖҷпјҢиҝҳиҰҒеҺ»еӨ„зҗҶжөҸи§ҲеҷЁе…је®№(дёҮжҒ¶зҡ„ IE зі»еҲ—)гҖӮ
дёҚз®ЎжҖҺд№ҲиҜҙпјҢеүҚз«ҜејҖеҸ‘д№ҹз®—жҳҜиғҪеҶҷзӮ№йҖ»иҫ‘д»Јз ҒдәҶпјҢдёҚеҶҚжҳҜеҸӘиғҪз”»з”»йЎөйқўзҡ„дҪҺз«ҜејҖеҸ‘дәҶгҖӮйҡҸзқҖ1998е№ҙ AJax зҡ„еҮәзҺ°пјҢеүҚз«ҜејҖеҸ‘д»Һ Web1.0иҝҲеҗ‘дәҶWeb2.0пјҢеүҚз«Ҝд»ҺзәҜеҶ…е®№зҡ„йқҷжҖҒеұ•зӨәпјҢеҸ‘еұ•еҲ°дәҶеҠЁжҖҒзҪ‘йЎөпјҢеҜҢдәӨдә’пјҢеүҚз«Ҝж•°жҚ®еӨ„зҗҶзҡ„ж–°ж—¶жңҹгҖӮиҝҷдёҖж—¶жңҹпјҢжҜ”иҫғзҹҘеҗҚзҡ„дёӨдёӘеҜҢдәӨдә’еҠЁжҖҒзҡ„жөҸи§ҲеҷЁдә§е“ҒжҳҜгҖӮ
Gmail(2004е№ҙ)
Google ең°еӣҫ(2005е№ҙ)
з”ұдәҺеҠЁжҖҒдәӨдә’гҖҒж•°жҚ®дәӨдә’зҡ„йңҖжұӮеўһеӨҡпјҢиҝҳиЎҚз”ҹеҮәдәҶjQuery(2006) иҝҷж ·дјҳз§Җзҡ„и·ЁжөҸи§ҲеҷЁзҡ„ js е·Ҙе…·еә“пјҢдё»иҰҒз”ЁдәҺ DOM ж“ҚдҪңпјҢж•°жҚ®дәӨдә’гҖӮжңүдәӣеҸӨиҖҒзҡ„йЎ№зӣ®пјҢз”ҡиҮіиҝ‘еҮ е№ҙејҖеҸ‘зҡ„еӨ§еһӢйЎ№зӣ®зҺ°еңЁиҝҳеңЁдҪҝз”Ё jQueryпјҢд»ҘиҮідәҺ jQuery еә“зҺ°еңЁиҝҳеңЁжӣҙж–°пјҢиҷҪ然дҪ“йҮҸдёҠе·Із»ҸиҝңиҝңдёҚеҸҠ ReactгҖҒVue иҝҷдәӣдјҳз§Җзҡ„еүҚз«Ҝеә“гҖӮ
дҝЎжҒҜж—¶д»Ј
иҮӘ 2003 д»ҘеҗҺпјҢеүҚз«ҜеҸ‘еұ•жёЎиҝҮдәҶдёҖж®өжҜ”иҫғе№ізЁізҡ„ж—¶жңҹпјҢеҗ„еӨ§жөҸи§ҲеҷЁеҺӮе•ҶйҷӨдәҶжҢүйғЁе°ұзҸӯзҡ„жӣҙж–°иҮӘе·ұзҡ„жөҸи§ҲеҷЁдә§е“Ғд№ӢеӨ–пјҢжІЎжңүеҶҚдҪңеҰ–жҗһзӮ№е…¶д»–дәӢжғ…гҖӮдҪҶжҳҜжҲ‘们зЁӢеәҸе‘ҳ们иҖҗдёҚдҪҸеҜӮеҜһе•ҠпјҢе·ҘдёҡеҢ–жҺЁеҠЁдәҶдҝЎжҒҜеҢ–зҡ„еҝ«йҖҹеҲ°жқҘпјҢжөҸи§ҲеҷЁе‘ҲзҺ°зҡ„ж•°жҚ®йҮҸи¶ҠжқҘи¶ҠеӨ§пјҢзҪ‘йЎөеҠЁжҖҒдәӨдә’зҡ„йңҖжұӮи¶ҠжқҘи¶ҠеӨҡпјҢJavaScript йҖҡиҝҮж“ҚдҪң DOM зҡ„ејҠз«Ҝе’Ң瓶йўҲи¶ҠжқҘи¶ҠжҳҺжҳҫ(йў‘з№Ғзҡ„дәӨдә’ж“ҚдҪңпјҢеҜјиҮҙйЎөйқўдјҡеҫҲеҚЎйЎҝ)пјҢд»…д»…д»Һд»Јз ҒеұӮйқўеҺ»жҸҗеҚҮйЎөйқўжҖ§иғҪпјҢеҸҳеҫ—и¶ҠжқҘи¶ҠйҡҫгҖӮдәҺжҳҜдјҳз§Җзҡ„еӨ§дҪ¬д»¬еҸҲе№ІдәҶзӮ№жғҠеӨ©еҠЁең°зҡ„е°ҸдәӢе„ҝпјҡ
2008 е№ҙпјҢи°·жӯҢ V8 еј•ж“ҺеҸ‘еёғпјҢз»Ҳз»“еҫ®иҪҜ IE ж—¶д»ЈгҖӮ
2009 е№ҙ AngularJS иҜһз”ҹгҖҒNodeиҜһз”ҹгҖӮ
2011 е№ҙ ReactJS иҜһз”ҹгҖӮ
2014 е№ҙ VueJS иҜһз”ҹгҖӮ
е…¶дёӯпјҢV8 е’Ң Node.JS зҡ„еҮәзҺ°пјҢдҪҝеүҚз«ҜејҖеҸ‘дәәе‘ҳеҸҜд»Ҙз”ЁзҶҹжӮүзҡ„иҜӯжі•зі–зј–еҶҷеҗҺеҸ°зі»з»ҹпјҢдёәеүҚз«ҜжҸҗдҫӣдәҶдҪҝз”ЁеҗҢдёҖиҜӯиЁҖзҡ„е®һзҺ°е…Ёж ҲејҖеҸ‘зҡ„жңәдјҡ(JavaScriptдёҚеҶҚжҳҜдёҖдёӘиў«еҳІз¬‘еҸӘиғҪеҶҷеҶҷйЎөйқўдәӨдә’зҡ„и„ҡжң¬иҜӯиЁҖ)гҖӮReactгҖҒAngularгҖҒVue зӯү MVVM еүҚз«ҜжЎҶжһ¶зҡ„еҮәзҺ°пјҢдҪҝеүҚз«Ҝе®һзҺ°дәҶйЎ№зӣ®зңҹжӯЈзҡ„еә”з”ЁеҢ–(SPAеҚ•йЎөйқўеә”з”Ё)пјҢдёҚеҶҚдҫқиө–еҗҺеҸ°ејҖеҸ‘дәәе‘ҳеӨ„зҗҶйЎөйқўи·Ҝз”ұ ControllerпјҢе®һзҺ°йЎөйқўи·іиҪ¬зҡ„иҮӘжҲ‘з®ЎзҗҶгҖӮеҗҢж—¶д№ҹжҺЁеҠЁдәҶеүҚеҗҺз«Ҝзҡ„еҪ»еә•еҲҶзҰ»(еүҚз«ҜйЎ№зӣ®зӢ¬з«ӢйғЁзҪІпјҢдёҚеҶҚдҫқиө–зұ»дјјзҡ„ template ж–Ү件зӣ®еҪ•)гҖӮ
иҮідәҺдёәе•Ҙ MVVM жЎҶжһ¶иғҪжҸҗеҚҮеүҚз«Ҝзҡ„жёІжҹ“жҖ§иғҪпјҢиҝҷйҮҢз®ҖеҚ•зҡ„иҜҙдёҖдёӢеҺҹзҗҶпјҢеӣ дёәеӨ§йҮҸзҡ„ DOM ж“ҚдҪңжҳҜжҖ§иғҪ瓶йўҲзҡ„зҪӘйӯҒзҘёйҰ–пјҢйӮЈйҖҡиҝҮдёҖе®ҡзҡ„еҲҶжһҗжҜ”иҫғз®—жі•пјҢе®һзҺ°еҗҢзӯүж•ҲжһңдёӢзҡ„жңҖе°Ҹ DOM ејҖй”ҖжҳҜеҸҜиЎҢзҡ„гҖӮReactгҖҒVue иҝҷзұ»жЎҶжһ¶еӨ§йғҪжҳҜйҖҡиҝҮиҝҷзұ»жҖқжғіе®һзҺ°зҡ„пјҢе…·дҪ“е®һзҺ°еҸҜд»ҘеҺ»зңӢдёҖдёӢзӣёе…іиө„ж–ҷгҖӮеүҚеҗҺз«ҜеҲҶзҰ»д№ҹеҜјиҮҙеүҚз«Ҝзҡ„еҲҶе·ҘеҸ‘з”ҹдәҶдёҖдәӣеҸҳеҢ–гҖӮ
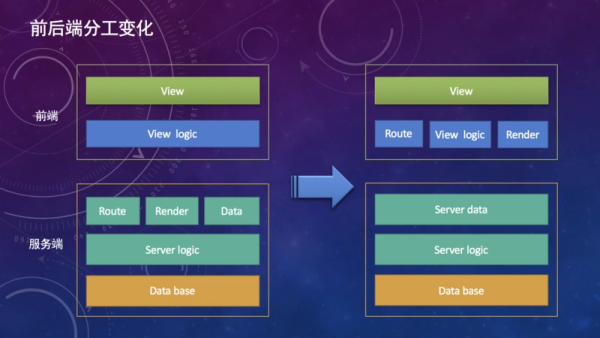
иҖҢеҗҺз«ҜејҖеҸ‘жӣҙеҠ е…іжіЁж•°жҚ®жңҚеҠЎпјҢеүҚз«ҜеҲҷиҙҹиҙЈеұ•зӨәе’ҢдәӨдә’гҖӮеҪ“然зӣёеә”зҡ„еӯҰд№ жҲҗжң¬д№ҹи¶ҠжқҘи¶ҠеӨ§пјҢNode.JSзҡ„еҮәзҺ°д№ҹдҪҝеҫ—еүҚз«ҜеүҚеҗҺз«ҜдёҖиө·ејҖеҸ‘жҲҗдёәеҸҜиғҪпјҢеҘҪеӨҡеӨ§е…¬еҸёеңЁ 2015 е№ҙеүҚеҗҺе°ұиҝӣиЎҢдәҶе°қиҜ•пјҢз”Ё Node.JS дҪңдёәдёӯй—ҙж•°жҚ®иҪ¬жҺҘеұӮпјҢи®©еҗҺз«ҜжӣҙеҠ дё“жіЁдәҺж•°жҚ®жңҚеҠЎе’ҢжІ»зҗҶгҖӮ
еүҚз«ҜжЁЎеқ—еҢ–еҸ‘еұ•еҺҶзЁӢ
иҮӘ 2009 е№ҙ 5 жңҲ Node.js еҸ‘еёғд»ҘжқҘпјҢеүҚз«ҜиғҪе№Ізҡ„дәӢжғ…и¶ҠжқҘи¶ҠеӨҡгҖӮзҹӯзҹӯ 10 жқҘе№ҙзҡ„ж—¶й—ҙпјҢеүҚз«Ҝдҫҝд»ҺеҲҖиҖ•зҒ«з§Қзҡ„е№ҙд»Јиө°еҗ‘дәҶжЁЎеқ—еҢ–гҖҒе·ҘзЁӢеҢ–зҡ„ж—¶д»ЈгҖӮеҗ„з§ҚеүҚз«ҜжЎҶжһ¶зҷҫ家дәүйёЈпјҢеүҚз«ҜиөўжқҘдәҶзңҹжӯЈеұһдәҺиҮӘе·ұзҡ„ж—¶д»ЈгҖӮ
еҺҹе§Ӣж—¶д»Ј
ж—¶й—ҙеӣһеҲ° 2009е№ҙпјҢи®°еҫ—йӮЈж—¶еҖҷиҝҳжІЎжңүжөҒиЎҢеүҚеҗҺз«ҜеҲҶзҰ»пјҢеҫҲеӨҡйЎ№зӣ®иҝҳжҳҜж··еңЁдёҖиө·пјҢиҖҢйӮЈж—¶еҖҷзҡ„еүҚз«ҜејҖеҸ‘дәәе‘ҳеӨ§еӨҡж•°д№ҹйғҪжҳҜвҖңеҲҮеӣҫд»”вҖқгҖӮеүҚз«Ҝе®ҢжҲҗйқҷжҖҒйЎөйқўпјҢз”ұжңҚеҠЎз«ҜеҗҢдәӢе®ҢжҲҗж•°жҚ®зҡ„еөҢе…ҘпјҢд№ҹе°ұжҳҜжүҖи°“зҡ„еҘ—йЎөйқўж“ҚдҪңпјҢжҜҸеҪ“жңүзұ»дјјзҡ„еҠҹиғҪпјҢйғҪдјҡеӣһеҲ°д№ӢеүҚзҡ„йЎөйқўеҺ»еӨҚеҲ¶зІҳиҙҙпјҢз”ұдәҺеӨ„дәҺдёҚеҗҢзҡ„йЎөйқўпјҢзұ»еҗҚйңҖиҰҒжӣҙжҚўпјҢдҪҶжҳҜжҚўжұӨдёҚжҚўиҚҜгҖӮ
д№…иҖҢд№…д№ӢпјҢйҮҚеӨҚд»Јз Ғи¶ҠжқҘи¶ҠеӨҡпјҢдҪҶеҮЎж”№еҠЁдёҖдёӘе°Ҹзҡ„ең°ж–№пјҢйғҪйңҖиҰҒж”№еҠЁеҫҲеӨҡд»Јз ҒпјҢжҳҫеҫ—жһҒдёҚж–№дҫҝпјҢд№ҹдёҚеҲ©дәҺеӨ§и§„жЁЎзҡ„иҝӣиЎҢе·ҘзЁӢеҢ–ејҖеҸ‘гҖӮиҷҪ然еёӮйқўдёҠд№ҹж…ўж…ўеҮәзҺ°дәҶ AngularгҖҒ Avalon зӯүдјҳз§Җзҡ„еүҚз«ҜжЎҶжһ¶пјҢдҪҶжҳҜиҖғиҷ‘еҲ° SEO е’Ңз»ҙжҠӨдәәе‘ҳ并дёҚеҘҪжӢӣпјҢеҫҲеӨҡе…¬еҸёиҝҳжҳҜйҖүжӢ©жұӮзЁіпјҢз”ЁеҘ—йЎөйқўзҡ„еҪўејҸеҲ¶дҪңзҪ‘йЎөпјҢиҝҷеҜ№еүҚз«Ҝзҡ„е·ҘзЁӢеҢ–гҖҒжЁЎеқ—еҢ–жҳҜдёҖдёӘдёҚе°Ҹзҡ„йҳ»зўҚгҖӮ
жһ„е»әе·Ҙе…·зҡ„еҮәзҺ°
дёҚиҝҮпјҢйҡҸзқҖ Node иў«еӨ§еҠӣжҺЁеҙҮпјҢеёӮйқўдёҠж¶ҢзҺ°еҮәеӨ§йҮҸзҡ„жһ„е»әе·Ҙе…·пјҢеҰӮ Npm ScriptsгҖҒGruntгҖҒGulpгҖҒFISгҖҒWebpackгҖҒRollupгҖҒParcelзӯүзӯүгҖӮжһ„е»әе·Ҙе…·и§Јж”ҫдәҶжҲ‘们зҡ„еҸҢжүӢпјҢеё®жҲ‘们еӨ„зҗҶдёҖдәӣйҮҚеӨҚзҡ„жңәжў°еҠіеҠЁгҖӮ
дёҫдёӘз®ҖеҚ•зҡ„дҫӢеӯҗпјҡжҲ‘们用 ES6 еҶҷдәҶдёҖж®өд»Јз ҒпјҢйңҖиҰҒеңЁжөҸи§ҲеҷЁжү§иЎҢгҖӮдҪҶжҳҜз”ұдәҺжөҸи§ҲеҷЁеҺӮе•ҶеҜ№жөҸи§ҲеҷЁзҡ„жӣҙж–°йқһеёёдҝқе®ҲпјҢдҪҝеҫ—еҫҲеӨҡ ES6 зҡ„д»Јз Ғ并дёҚиғҪзӣҙжҺҘеңЁжөҸи§ҲеҷЁдёҠиҝҗиЎҢгҖӮиҝҷдёӘж—¶еҖҷжҲ‘们жҖ»дёҚиғҪжүӢеҠЁе°Ҷ ES6 д»Јз Ғж”№жҲҗ ES5 зҡ„д»Јз ҒгҖӮдәҺжҳҜд№Һе°ұжңүдәҶдёӢйқўзҡ„иҪ¬жҚўгҖӮ
//зј–иҜ‘еүҚ [1,2,3].map(item => console.log(item)) //зј–иҜ‘еҗҺ [1, 2, 3].map(function (item) { return console.log(item); }); //д»Јз ҒеҺӢзј©еҗҺ [1,2,3].map(function(a){return console.log(a)});е°ұжҳҜеҒҡдәҶдёҠиҝ°зҡ„ж“ҚдҪңпјҢжүҚиғҪдҪҝеҫ—жҲ‘们еңЁеҶҷеүҚз«Ҝд»Јз Ғзҡ„ж—¶еҖҷпјҢдҪҝз”ЁжңҖж–°зҡ„ ECMAScript иҜӯжі•пјҢ并且е°ҪеҸҜиғҪзҡ„еҺӢзј©д»Јз Ғзҡ„дҪ“з§ҜпјҢдҪҝеҫ—жөҸи§ҲеҷЁеҠ иҪҪйқҷжҖҒи„ҡжң¬ж—¶иғҪжӣҙеҠ еҝ«йҖҹгҖӮ
дј з»ҹзҡ„жЁЎеқ—еҢ–
йҡҸзқҖ Ajax зҡ„жөҒиЎҢпјҢеүҚз«Ҝе·ҘзЁӢеёҲиғҪеҒҡзҡ„дәӢжғ…е°ұдёҚеҸӘжҳҜвҖңеҲҮеӣҫвҖқ иҝҷд№Ҳз®ҖеҚ•пјҢзҺ°еңЁеүҚз«Ҝе·ҘзЁӢеёҲиғҪеҒҡзҡ„и¶ҠжқҘи¶ҠеӨҡпјҢејҖе§ӢеҮәзҺ°дәҶжҳҺзЎ®зҡ„еҲҶе·ҘпјҢ并且иғҪеӨҹдёҺжңҚеҠЎз«Ҝе·ҘзЁӢеёҲиҝӣиЎҢж•°жҚ®иҒ”и°ғгҖӮиҝҷйҮҢиҜҙзҡ„дј з»ҹжЁЎеқ—еҢ–иҝҳдёҚжҳҜеҗҺзҺ°д»Јзҡ„жЁЎеқ—еҢ–пјҢж—©жңҹзҡ„жЁЎеқ—еҢ–жҳҜдёҚеҖҹеҠ©д»»дҪ•е·Ҙе…·зҡ„пјҢзәҜеұһз”ұ JavaScript е®ҢжҲҗд»Јз Ғзҡ„з»“жһ„еҢ–гҖӮеңЁдј з»ҹзҡ„жЁЎеқ—еҢ–дёӯжҲ‘们主иҰҒжҳҜе°ҶдёҖдәӣиғҪеӨҹеӨҚз”Ёзҡ„д»Јз ҒжҠҪжҲҗе…¬е…ұж–№жі•пјҢд»Ҙдҫҝз»ҹдёҖз»ҙжҠӨе’Ңз®ЎзҗҶпјҢжҜ”еҰӮдёӢйқўд»Јз ҒгҖӮ
function show(id) { document.getElementById(id).setAttribute('style', "display: block") } function hide(id) { document.getElementById(id).setAttribute('style', "display: none") }然еҗҺпјҢжҲ‘们е°Ҷиҝҷдәӣе·Ҙе…·еҮҪж•°е°ҒиЈ…еҲ°дёҖдёӘ JS и„ҡжң¬ж–Ү件йҮҢпјҢеңЁйңҖиҰҒдҪҝз”Ёе®ғ们зҡ„ең°ж–№иҝӣиЎҢеј•е…ҘгҖӮ
дҪҶжҳҜпјҢиҝҷз§ҚеҒҡжі•дјҡиЎҚз”ҹеҮәдёӨдёӘеҫҲеӨ§зҡ„й—®йўҳпјҢдёҖдёӘжҳҜе…ЁеұҖеҸҳйҮҸзҡ„жұЎжҹ“пјҢеҸҰдёҖдёӘжҳҜдәәе·Ҙз»ҙжҠӨжЁЎеқ—д№Ӣй—ҙзҡ„дҫқиө–е…ізі»дјҡйҖ жҲҗд»Јз Ғзҡ„ж··д№ұгҖӮ
<script scr="./utils.js"></script>
дҫӢеҰӮпјҢеҪ“жҲ‘们зҡ„йЎ№зӣ®жңүеҚҒеҮ дёӘз”ҡиҮіеҮ еҚҒдёӘдәәз»ҙжҠӨзҡ„ж—¶еҖҷпјҢйҡҫе…ҚдјҡжңүдәәеңЁе…¬з”Ёз»„件дёӯж·»еҠ ж–°зҡ„ж–№жі•пјҢжҜ”еҰӮ show иҝҷдёӘж–№жі•дёҖж—Ұиў«иҰҶзӣ–дәҶпјҢдҪҝз”Ёе®ғзҡ„дәәдјҡеҫ—еҲ°е’Ңйў„жңҹдёҚеҗҢзҡ„з»“жһңпјҢиҝҷж ·е°ұйҖ жҲҗзҡ„е…ЁеұҖеҸҳйҮҸзҡ„жұЎжҹ“гҖӮеҸҰдёҖдёӘй—®йўҳпјҢеӣ дёәзңҹе®һйЎ№зӣ®дёӯзҡ„е…¬з”Ёи„ҡжң¬д№Ӣй—ҙзҡ„дҫқиө–е…ізі»жҳҜжҜ”иҫғеӨҚжқӮзҡ„пјҢжҜ”еҰӮ c и„ҡжң¬дҫқиө– b и„ҡжң¬пјҢa и„ҡжң¬дҫқиө– b и„ҡжң¬пјҢйӮЈд№ҲжҲ‘们еңЁеј•е…Ҙзҡ„ж—¶еҖҷе°ұиҰҒжіЁж„Ҹеҝ…йЎ»иҰҒиҝҷж ·еј•е…ҘгҖӮ
<script scr="c.js"></script> <script scr="b.js"></script> <script scr="a.js"></script>
иҰҒиҝҷж ·еј•е…ҘжүҚиғҪдҝқиҜҒ a и„ҡжң¬зҡ„жӯЈеёёиҝҗиЎҢпјҢеҗҰеҲҷе°ұдјҡжҠҘй”ҷгҖӮеҜ№дәҺиҝҷзұ»й—®йўҳпјҢжҲ‘们иҜҘеҰӮдҪ•и§ЈеҶіиҝҷж ·зҡ„й—®йўҳе‘ў?
е…ЁеұҖеҸҳйҮҸзҡ„жұЎжҹ“
и§ЈеҶіиҝҷдёӘй—®йўҳжңүдёӨз§ҚпјҢе…ҲиҜҙиҜҙжІ»ж ҮдёҚжІ»жң¬зҡ„ж–№жі•пјҢжҲ‘们йҖҡиҝҮеӣўйҳҹ规иҢғејҖеҸ‘ж–ҮжЎЈпјҢжҜ”еҰӮиҜҙжҲ‘жңүдёӘж–№жі•пјҢжҳҜеңЁиҙӯзү©иҪҰжЁЎеқ—дёӯдҪҝз”Ёзҡ„пјҢеҸҜд»ҘеҰӮдёӢд№ҰеҶҷгҖӮ
var shop.cart.utils = { show: function(id) { document.getElementById(id).setAttribute('style', "display: block") }, hide: function(id) { document.getElementById(id).setAttribute('style', "display: none") } }иҝҷж ·е°ұиғҪжҜ”иҫғжңүж•Ҳзҡ„йҒҝејҖе…ЁеұҖеҸҳйҮҸзҡ„жұЎжҹ“пјҢжҠҠж–№жі•еҶҷеҲ°еҜ№иұЎйҮҢпјҢеҶҚйҖҡиҝҮеҜ№иұЎеҺ»и°ғз”ЁгҖӮдё“дёҡжңҜиҜӯдёҠиҝҷеҸ«е‘ҪеҗҚз©әй—ҙзҡ„规иҢғпјҢдҪҶжҳҜиҝҷж ·жЁЎеқ—еӨҡдәҶеҸҳйҮҸеҗҚдјҡжҜ”иҫғзҙҜиөҳпјҢдёҖеҶҷе°ұжҳҜдёҖй•ҝдёІпјҢжүҖд»ҘжҲ‘еҸ«е®ғжІ»ж ҮдёҚжІ»жң¬гҖӮ
иҝҳжңүдёҖз§ҚжҜ”иҫғдё“дёҡзҡ„ж–№жі•жҠҖжңҜйҖҡиҝҮз«ӢеҚіжү§иЎҢеҮҪж•°е®ҢжҲҗй—ӯеҢ…е°ҒиЈ…пјҢдёәдәҶи§ЈеҶіе°ҒиЈ…еҶ…еҸҳйҮҸзҡ„й—®йўҳпјҢз«ӢеҚіжү§иЎҢеҮҪж•°жҳҜдёӘеҫҲеҘҪзҡ„еҠһжі•пјҢиҝҷд№ҹжҳҜж—©жңҹеҫҲеӨҡејҖеҸ‘жӯЈеңЁдҪҝз”Ёзҡ„ж–№ејҸпјҢеҰӮдёӢжүҖзӨәгҖӮ
(function() { var Cart = Cart || {}; function show (id) { document.getElementById(id).setAttribute('style', "display: block") } function hide (id) { document.getElementById(id).setAttribute('style', "display: none") } Cart.Util = { show: show, hide: hide } })();дёҠиҝ°д»Јз ҒпјҢйҖҡиҝҮдёҖдёӘз«ӢеҚіжү§иЎҢеҮҪж•°пјҢз»ҷдәҲдәҶжЁЎеқ—зҡ„зӢ¬з«ӢдҪңз”ЁеҹҹпјҢеҗҢж—¶йҖҡиҝҮе…ЁеұҖеҸҳйҮҸй…ҚзҪ®дәҶжҲ‘们зҡ„жЁЎеқ—пјҢиҫҫеҲ°дәҶжЁЎеқ—еҢ–зҡ„зӣ®зҡ„гҖӮ
еҪ“еүҚзҡ„жЁЎеқ—еҢ–ж–№жЎҲ
е…ҲжқҘиҜҙиҜҙ CommonJS 规иҢғпјҢеңЁ Node.JS еҸ‘еёғд№ӢеҗҺпјҢCommonJS жЁЎеқ—еҢ–规иҢғе°ұиў«з”ЁеңЁдәҶйЎ№зӣ®ејҖеҸ‘дёӯпјҢе®ғжңүеҮ дёӘжҰӮеҝөз»ҷеӨ§е®¶и§ЈйҮҠдёҖдёӢгҖӮ
жҜҸдёӘж–Ү件йғҪжҳҜдёҖдёӘжЁЎеқ—пјҢе®ғйғҪжңүеұһдәҺиҮӘе·ұзҡ„дҪңз”ЁеҹҹпјҢеҶ…йғЁе®ҡд№үзҡ„еҸҳйҮҸгҖҒеҮҪж•°йғҪжҳҜз§Ғжңүзҡ„пјҢеҜ№еӨ–жҳҜдёҚеҸҜи§Ғзҡ„;
жҜҸдёӘжЁЎеқ—еҶ…йғЁзҡ„ module еҸҳйҮҸд»ЈиЎЁеҪ“еүҚжЁЎеқ—пјҢиҝҷдёӘеҸҳйҮҸжҳҜдёҖдёӘеҜ№иұЎ;
module зҡ„ exports еұһжҖ§жҳҜеҜ№еӨ–зҡ„жҺҘеҸЈпјҢеҠ иҪҪжҹҗдёӘжЁЎеқ—е…¶е®һе°ұжҳҜеңЁеҠ иҪҪжЁЎеқ—зҡ„ module.exports еұһжҖ§;
дҪҝз”Ё require е…ій”®еӯ—еҠ иҪҪеҜ№еә”зҡ„жЁЎеқ—пјҢrequire зҡ„еҹәжң¬еҠҹиғҪе°ұжҳҜиҜ»е…Ҙ并жү§иЎҢдёҖдёӘ JavaScript ж–Ү件пјҢ然еҗҺиҝ”еӣһж”№жЁЎеқ—зҡ„ exports еҜ№иұЎпјҢеҰӮжһңжІЎжңүзҡ„иҜқдјҡжҠҘй”ҷзҡ„;
дёӢйқўжқҘзңӢдёҖдёӢзӨәдҫӢпјҢжҲ‘们е°ұе°ҶдёҠйқўжҸҗеҲ°иҝҮзҡ„д»Јз ҒйҖҡиҝҮ CommonJS жЁЎеқ—еҢ–гҖӮ
module.exports = { show: function (id) { document.getElementById(id).setAttribute('style', "display: block") }, hide: function (id) { document.getElementById(id).setAttribute('style', "display: none") } } // д№ҹеҸҜд»Ҙиҫ“еҮәеҚ•дёӘж–№жі• module.exports.show = function (id) { document.getElementById(id).setAttribute('style', "display: block") } // еј•е…Ҙзҡ„ж–№ејҸ var utils = require('./utils') // дҪҝз”Ёе®ғ utils.show("body")йҷӨдәҶ CommonJS 规иҢғеӨ–пјҢиҝҳжңүеҮ дёӘзҺ°еңЁеҸӘиғҪеңЁиҖҒйЎ№зӣ®йҮҢжүҚиғҪзңӢеҲ°зҡ„жЁЎеқ—еҢ–жЁЎејҸпјҢжҜ”еҰӮд»Ҙ require.js дёәд»ЈиЎЁзҡ„ AMD(Asynchronous Module Definition) 规иҢғ е’Ң зҺүдјҜеӣўйҳҹеҶҷзҡ„ sea.js дёәд»ЈиЎЁзҡ„ CMD(Common Module Definition) 规иҢғгҖӮ
AMD зҡ„зү№зӮ№пјҡжҳҜдёҖжӯҘеҠ иҪҪжЁЎеқ—пјҢдҪҶжҳҜеүҚжҸҗжҳҜдёҖејҖе§Ӣе°ұиҰҒе°ҶжүҖжңүзҡ„дҫқиө–йЎ№еҠ иҪҪе®Ңе…ЁгҖӮCMD зҡ„зү№зӮ№жҳҜпјҡдҫқиө–延иҝҹпјҢеңЁйңҖиҰҒзҡ„ж—¶еҖҷжүҚеҺ»еҠ иҪҪгҖӮ
AMD
йҰ–е…ҲпјҢжҲ‘们жқҘзңӢдёҖдёӢеҰӮдҪ•йҖҡиҝҮ AMD 规иҢғзҡ„ require.js д№ҰеҶҷдёҠиҝ°жЁЎеқ—еҢ–д»Јз ҒгҖӮ
define(['home'], function(){ function show(id) { document.getElementById(id).setAttribute('style', "display: block") } function hide(id) { document.getElementById(id).setAttribute('style', "display: none") } return { show: show, hide: hide }; }); // еҠ иҪҪжЁЎеқ— require(['utils'], function (cart){ гҖҖ cart.show('body'); });require.js е®ҡд№үдәҶдёҖдёӘеҮҪж•° defineпјҢе®ғжҳҜе…ЁеұҖеҸҳйҮҸпјҢз”ЁжқҘе®ҡд№үжЁЎеқ—пјҢе®ғзҡ„иҜӯ法规иҢғеҰӮдёӢпјҡ
define(id, dependencies, factory)
idпјҡе®ғжҳҜеҸҜйҖүеҸӮж•°пјҢз”ЁдәҺж ҮиҜҶжЁЎеқ—;
dependenciesпјҡеҪ“еүҚжЁЎеқ—жүҖдҫқиө–зҡ„жЁЎеқ—еҗҚз§°ж•°з»„пјҢеҰӮдёҠиҝ°жЁЎеқ—дҫқиө– home жЁЎеқ—пјҢиҝҷе°ұи§ЈеҶідәҶд№ӢеүҚиҜҙзҡ„жЁЎеқ—д№Ӣй—ҙдҫқиө–е…ізі»жҚўд№ұзҡ„й—®йўҳпјҢйҖҡиҝҮиҝҷдёӘеҸӮж•°еҸҜд»Ҙе°ҶеүҚзҪ®дҫқиө–жЁЎеқ—еҠ иҪҪиҝӣжқҘ;
factoryпјҡжЁЎеқ—еҲқе§ӢеҢ–иҰҒжү§иЎҢзҡ„еҮҪж•°жҲ–еҜ№иұЎгҖӮ
require([dependencies], function(){})
然еҗҺпјҢеңЁе…¶д»–ж–Ү件дёӯдҪҝз”Ё require иҝӣиЎҢеј•е…ҘпјҢ第дёҖдёӘеҸӮж•°дёәйңҖиҰҒдҫқиө–зҡ„жЁЎеқ—ж•°з»„пјҢ第дәҢдёӘеҸӮж•°дёәдёҖдёӘеӣһи°ғеҮҪж•°пјҢеҪ“еүҚйқўзҡ„дҫқиө–жЁЎеқ—иў«еҠ иҪҪжҲҗеҠҹд№ӢеҗҺпјҢеӣһи°ғеҮҪж•°дјҡиў«жү§иЎҢпјҢеҠ иҪҪиҝӣжқҘзҡ„жЁЎеқ—е°Ҷдјҡд»ҘеҸӮж•°зҡ„еҪўејҸдј е…ҘеҮҪж•°еҶ…пјҢд»ҘдҫҝиҝӣиЎҢе…¶д»–ж“ҚдҪңгҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңиҪҜ件жһ¶жһ„д№ӢеҰӮдҪ•зҗҶи§ЈеүҚеҗҺз«ҜеҲҶзҰ»дёҺеүҚз«ҜжЁЎеқ—еҢ–вҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№иҪҜ件жһ¶жһ„д№ӢеҰӮдҪ•зҗҶи§ЈеүҚеҗҺз«ҜеҲҶзҰ»дёҺеүҚз«ҜжЁЎеқ—еҢ–иҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ





