本篇文章将从实战角度来介绍如何构建一个稳健的分布式微博爬虫。这里我没敢谈高效,抓过微博数据的同学应该都知道微博的反爬虫能力,也知道微博数据抓取的瓶颈在哪里。我在知乎上看过一些同学的说法,把微博的数据抓取难度简单化了,我只能说,那是你太naive,没深入了解和长期抓取而已。
本文将会以PC端微博进行讲解,因为移动端微博数据不如PC短全面,而且抓取和解析难度都会小一些。文章比较长,由于篇幅所限,文章并没有列出所有代码,只是讲了大致流程和思路。
要抓微博数据,第一步便是模拟登陆,因为很多信息(比如用户信息,用户主页微博数据翻页等各种翻页)都需要在登录状态下才能查看
这里我简单说一下,做爬虫的同学不要老想着用什么机器学习的方法去识别复杂验证码,真的难度非常大,这应该也不是一个爬虫工程师的工作重点,当然这只是我的个人建议。工程化的项目,我还是建议大家通过打码平台来解决验证码的问题。
说完模拟登陆(具体请参见我写的那两篇文章,篇幅所限,我就不copy过来了),我们现在正式进入微博的数据抓取。这里我会以微博用户信息抓取为例来进行分析和讲解。
关于用户信息抓取,可能我们有两个目的。一个是我们只想抓一些指定用户,另外一个是我们想尽可能多的抓取更多数量的用户的信息。我的目的假定是第二种。那么我们该以什么样的策略来抓取,才能获得尽可能多的用户信息呢?如果我们初始用户选择有误,选了一些不活跃的用户,很可能会形成一个环,这样就抓不了太多的数据。这里有一个很简单的思路:我们把一些大V拿来做为种子用户,我们先抓他们的个人信息,然后再抓大V所关注的用户和粉丝,大V关注的用户肯定也是类似大V的用户,这样的话,就不容易形成环了。
策略我们都清楚了。就该是分析和编码了。
我们先来分析如何构造用户信息的URL。这里我以微博名为一起神吐槽的博主为例进行分析。做爬虫的话,一个很重要的意识就是爬虫能抓的数据都是人能看到的数据,反过来,人能在浏览器上看到的数据,爬虫几乎都能抓。这里用的是几乎,因为有的数据抓取难度特别。我们首先需要以正常人的流程看看怎么获取到用户的信息。我们先进入该博主的主页,如下图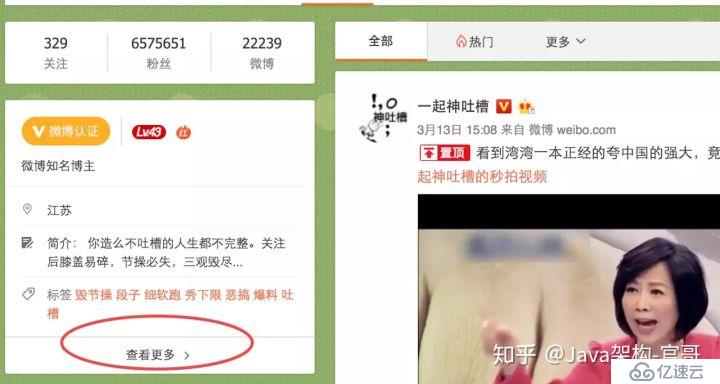
种子用户主页
点击查看更多,可以查看到该博主的具体信息
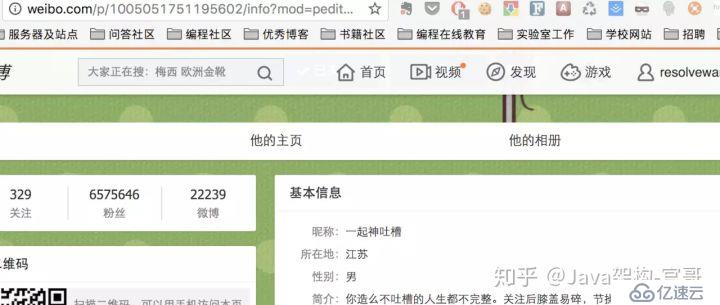
种子博主具体信息
这里我们就看到了他的具体信息了。然后,我们看该页面的url构造
weibo.com/p/100505175…
我直接copy的地址栏的url。这样做有啥不好的呢?对于老鸟来说,一下就看出来了,这样做的话,可能会导致信息不全,因为可能有些信息是动态加载的。所以,我们需要通过抓包来判断到底微博会通过该url返回所有信息,还是需要请求一些ajax 链接才会返回一些关键信息。这里我就重复一下我的观点:抓包很重要,抓包很重要,抓包很重要!重要的事情说三遍。
我们抓完包,发现并没有ajax请求。那么可以肯定请求前面的url,会返回所有信息。我们通过点击鼠标右键,查看网页源代码,然后ctrl+a、ctrl+c将所有的页面源码保存到本地,这里我命名为personinfo.html。我们用浏览器打开该文件,发现我们需要的所有信息都在这段源码中,这个工作和抓包判断数据是否全面有些重复,但是在我看来是必不可少的,因为我们解析页面数据的时候还可以用到这个html文件,如果我们每次都通过网络请求去解析内容的话,那么可能账号没一会儿就会被封了(因为频繁访问微博信息),所以我们需要把要解析的文件保存到本地。
从上面分析中我们可以得知
weibo.com/p/100505175…
这个url就是获取用户数据的url。那么我们在只知道用户id的时候怎么构造它呢?我们可以多拿几个用户id来做测试,看构造是否有规律,比如我这里以用户名为网易云音乐的用户做分析,发现它的用户信息页面构造如下
weibo.com/1721030997/…
这个就和上面那个不同了。但是我们仔细观察,可以发现上面那个是个人用户,下面是企业微博用户。我们尝试一下把它们url格式都统一为第一种或者第二种的格式
weibo.com/1751195602/…
这样会出现404,那么统一成上面那种呢?
weibo.com/p/100505172…
这样子的话,它会被重定向到用户主页,而不是用户详细资料页。所以也就不对了。那么该以什么依据判断何时用第一种url格式,何时用第二种url格式呢?我们多翻几个用户,会发现除了100505之外,还有100305、100206等前缀,那么我猜想这个应该可以区分不同用户。这个前缀在哪里可以得到呢?我们打开我们刚保存的页面源码,搜索100505,可以发现
domain
微博应该是根据这个来区分不同用户类型的。这里大家可以自己也可以试试,看不同用户的domain是否不同。为了数据能全面,我也是做了大量测试,发现个人用户的domain是1005051,作家是100305,其他基本都是认证的企业号。前两个个人信息的url构造就是
weibo.com/p/domain+ui…
后者的是
weibo.com/uid/about
弄清楚了个人信息url的构造方式,但是还有一个问题。我们已知只有uid啊,没有domain啊。如果是企业号,我们通过domain=100505会被重定向到主页,如果是作家等(domain=100305或者100306),也会被重定向主页。我们在主页把domain提取出来,再请求一次,不就能拿到用户详细信息了吗?
关于如何构造获取用户信息的url的相关分析就到这里了。因为我们是在登录的情况下进行数据抓取的,可能在抓取的时候,某个账号突然就被封了,或者由于网络原因,某次请求失败了,该如何处理?对于前者,我们需要判断每次请求返回的内容是否符合预期,也就是看response url是否正常,看response content是否是404或者让你验证手机号等,对于后者,我们可以做一个简单的重试策略,大概代码如下
@timeout_decorator
def get_page(url, user_verify=True, need_login=True):
"""
:param url: 待抓取url
:param user_verify: 是否为可能出现验证码的页面(ajax连接不会出现验证码,如果是请求微博或者用户信息可能出现验证码),否为抓取转发的ajax连接
:param need_login: 抓取页面是否需要登录,这样做可以减小一些账号的压力
:return: 返回请求的数据,如果出现404或者403,或者是别的异常,都返回空字符串
"""
crawler.info('本次抓取的url为{url}'.format(url=url))
count = 0
while count < max_retries:
if need_login:
# 每次重试的时候都换cookies,并且和上次不同,如果只有一个账号,那么就允许相同
name_cookies = Cookies.fetch_cookies()
if name_cookies is None:
crawler.warning('cookie池中不存在cookie,正在检查是否有可用账号')
rs = get_login_info()
# 选择状态正常的账号进行登录,账号都不可用就停掉celery worker
if len(rs) == 0:
crawler.error('账号均不可用,请检查账号健康状况')
# 杀死所有关于celery的进程
if 'win32' in sys.platform:
os.popen('taskkill /F /IM "celery*"')
else:
os.popen('pkill -f "celery"')
else:
crawler.info('重新获取cookie中...')
login.excute_login_task()
time.sleep(10)
try:
if need_login:
resp = requests.get(url, headers=headers, cookies=name_cookies[1], timeout=time_out, verify=False)
if "$CONFIG['islogin'] = '0'" in resp.text:
crawler.warning('账号{}出现异常'.format(name_cookies[0]))
freeze_account(name_cookies[0], 0)
Cookies.delete_cookies(name_cookies[0])
continue
else:
resp = requests.get(url, headers=headers, timeout=time_out, verify=False)
page = resp.text
if page:
page = page.encode('utf-8', 'ignore').decode('utf-8')
else:
continue
# 每次抓取过后程序sleep的时间,降低封号危险
time.sleep(interal)
if user_verify:
if 'unfreeze' in resp.url or 'accessdeny' in resp.url or 'userblock' in resp.url or is_403(page):
crawler.warning('账号{}已经被冻结'.format(name_cookies[0]))
freeze_account(name_cookies[0], 0)
Cookies.delete_cookies(name_cookies[0])
count += 1
continue
if 'verifybmobile' in resp.url:
crawler.warning('账号{}功能被锁定,需要手机解锁'.format(name_cookies[0]))
freeze_account(name_cookies[0], -1)
Cookies.delete_cookies(name_cookies[0])
continue
if not is_complete(page):
count += 1
continue
if is_404(page):
crawler.warning('url为{url}的连接不存在'.format(url=url))
return ''
except (requests.exceptions.ReadTimeout, requests.exceptions.ConnectionError, AttributeError) as e:
crawler.warning('抓取{}出现异常,具体信息是{}'.format(url, e))
count += 1
time.sleep(excp_interal)
else:
Urls.store_crawl_url(url, 1)
return page
crawler.warning('抓取{}已达到最大重试次数,请在redis的失败队列中查看该url并检查原因'.format(url))
Urls.store_crawl_url(url, 0)
return ''这里大家把上述代码当一段伪代码读就行了,主要看看如何处理抓取时候的异常。因为如果贴整个用户抓取的代码,不是很现实,代码量有点大。
下面讲页面解析的分析。有一些做PC端微博信息抓取的同学,可能曾经遇到过这么个问题:保存到本地的html文件打开都能看到所有信息啊,为啥在页面源码中找不到呢?因为PC端微博页面的关键信息都是像下图这样,被FM.view()包裹起来的,里面的数据可能被json encode过。

标签
那么这么多的FM.view(),我们怎么知道该提取哪个呢?这里有一个小技巧,由于只有中文会被编码,英文还是原来的样子,所以我们可以看哪段script中包含了渲染后的页面中的字符,那么那段应该就可能包含所有页面信息。我们这里以顶部的头像为例,如图
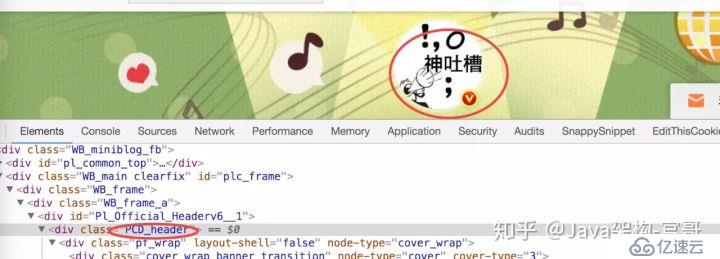
根据唯一性判断
我们在页面源码中搜索,只发现一个script中有该字符串,那么就是那段script是页面相关信息。我们可以通过正则表达式把该script提取出来,然后把其中的html也提取出来,再保存到本地,看看信息是否全面。这里我就不截图了。感觉还有很多要写的,不然篇幅太长了。
另外,对于具体页面的解析,我也不做太多的介绍了。太细的东西还是建议读读源码。我只讲一下,我觉得的一种处理异常的比较优雅的方式。微博爬虫的话,主要是页面样式太多,如果你打算包含所有不同的用户的模版,那么我觉得几乎不可能,不同用户模版,用到的解析规则就不一样。那么出现解析异常如何处理?尤其是你没有catch到的异常。很可能因为这个问题,程序就崩掉。其实对于Python这门语言来说,我们可以通过 装饰器 来捕捉我们没有考虑到的异常,比如我这个装饰器
def parse_decorator(return_type):
"""
:param return_type: 用于捕捉页面解析的异常, 0表示返回数字0, 1表示返回空字符串, 2表示返回[],3表示返回False, 4表示返回{}, 5返回None
:return: 0,'',[],False,{},None
"""
def page_parse(func):@wraps(func)
br/>@wraps(func)
keys):
try:
return func(keys)
except Exception as e:
parser.error(e)
if return_type == 5:
return None
elif return_type == 4:
return {}
elif return_type == 3:
return False
elif return_type == 2:
return []
elif return_type == 1:
return ''
else:
return 0
return handle_error
return page_parse上面的代码就是处理解析页面发生异常的情况,我们只能在数据的准确性、全面性和程序的健壮性之间做一些取舍。用装饰器的话,程序中不用写太多的 try语句,代码重复率也会减少很多。
页面的解析由于篇幅所限,我就讲到这里了。没有涉及太具体的解析,其中一个还有一个比较难的点,就是数据的全面性,读者可以去多观察几个微博用户的个人信息,就会发现有的个人信息,有的用户有填写,有的并没有。解析的时候要考虑完的话,建议从自己的微博的个人信息入手,看到底有哪些可以填。这样可以保证几乎不会漏掉一些重要的信息。
最后,我再切合本文的标题,讲如何搭建一个分布式的微博爬虫。开发过程中,我们可以先就做单机单线程的爬虫,然后再改成使用celery的方式。这里这样做是为了方便开发和测试,因为你单机搭起来并且跑得通了,那么分布式的话,就很容易改了,因为celery的API使用本来就很简洁。
我们抓取的是用户信息和他的关注和粉丝uid。用户信息的话,我们一个请求大概能抓取一个用户的信息,而粉丝和关注我们一个请求可以抓取18个左右(因为这个抓的是列表),显然可以发现用户信息应该多占一些请求的资源。这时候就该介绍理论篇没有介绍的关于celery的一个高级特性了,它叫做任务路由。直白点说,它可以规定哪个分布式节点能做哪些任务,不能做哪些任务。它的存在可以让资源分配更加合理, 分布式微博爬虫项目初期,就没有使用任务路由,然后抓了十多万条关注和分析,结果发现用户信息抓几万条,这就是资源分配得不合理。那么如何进行任务路由呢?
import os
from datetime import timedelta
from celery import Celery
from kombu import Exchange, Queue
from config.conf import get_broker_or_backend
from celery import platforms
platforms.C_FORCE_ROOT = True
worker_log_path = os.path.join(os.path.dirname(os.path.dirname(file))+'/logs', 'celery.log')
beat_log_path = os.path.join(os.path.dirname(os.path.dirname(file))+'/logs', 'beat.log')
tasks = ['tasks.login', 'tasks.user']
app = Celery('weibo_task', include=tasks, broker=get_broker_or_backend(1), backend=get_broker_or_backend(2))
app.conf.update(
CELERY_TIMEZONE='Asia/Shanghai',
CELERY_ENABLE_UTC=True,
CELERYD_LOG_FILE=worker_log_path,
CELERYBEAT_LOG_FILE=beat_log_path,
CELERY_ACCEPT_CONTENT=['json'],
CELERY_TASK_SERIALIZER='json',
CELERY_RESULT_SERIALIZER='json',
CELERY_QUEUES=(
Queue('login_queue', exchange=Exchange('login', type='direct'), routing_key='for_login'),
Queue('user_crawler', exchange=Exchange('user_info', type='direct'), routing_key='for_user_info'),
Queue('fans_followers', exchange=Exchange('fans_followers', type='direct'), routing_key='for_fans_followers'),
)
上述代码我指定了有login_queue、user_crawler、fans_followers三个任务队列。它们分别的作用是登录、用户信息抓取、粉丝和关注抓取。现在假设我有三台爬虫服务器A、B和C。我想让我所有的账号登录任务分散到三台服务器、让用户抓取在A和B上执行,让粉丝和关注抓取在C上执行,那么启动A、B、C三个服务器的celery worker的命令就分别是
celery -A tasks.workers -Q login_queue,user_crawler worker -l info -c 1 # A服务器和B服务器启动worker的命令,它们只会执行登录和用户信息抓取任务
celery -A tasks.workers -Q login_queue,fans_followers worker -l info -c 1 # C服务器启动worker的命令,它只会执行登录、粉丝和关注抓取任务
然后我们通过命令行或者代码(如下)就能发送所有任务给各个节点执行了
from tasks.workers import app
from page_get import user as user_get
from db.seed_ids import get_seed_ids, get_seed_by_id, insert_seeds, set_seed_other_crawled
@app.task(ignore_result=True)
def crawl_follower_fans(uid):
seed = get_seed_by_id(uid)
if seed.other_crawled == 0:
rs = user_get.get_fans_or_followers_ids(uid, 1)
rs.extend(user_get.get_fans_or_followers_ids(uid, 2))
datas = set(rs)
if datas:
insert_seeds(datas)
set_seed_other_crawled(uid)@app.task(ignore_result=True)
def crawl_person_infos(uid):
"""
根据用户id来爬取用户相关资料和用户的关注数和粉丝数(由于微博服务端限制,默认爬取前五页,企业号的关注和粉丝也不能查看)
:param uid: 用户id
:return:
"""
if not uid:
return
# 由于与别的任务共享数据表,所以需要先判断数据库是否有该用户信息,再进行抓取
user = user_get.get_profile(uid)
# 不抓取企业号
if user.verify_type == 2:
set_seed_other_crawled(uid)
return
app.send_task('tasks.user.crawl_follower_fans', args=(uid,), queue='fans_followers',
routing_key='for_fans_followers')@app.task(ignore_result=True)
def excute_user_task():
seeds = get_seed_ids()
if seeds:
for seed in seeds:
app.send_task('tasks.user.crawl_person_infos', args=(seed.uid,), queue='user_crawler',
routing_key='for_user_info')这里我们是通过 queue='user_crawler',routing_key='for_user_info'来将任务和worker进行关联的。
关于celery任务路由的更详细的资料请阅读官方文档。
到这里,基本把微博信息抓取的过程和分布式进行抓取的过程都讲完了,具体实现分布式的方法,可以读读基础篇。由于代码量比较大,我并没有贴上完整的代码,只讲了要点。分析过程是讲的抓取过程的分析和页面解析的分析,并在最后,结合分布式,讲了一下使用任务队列来让分布式爬虫更加灵活和可扩展。
如果有同学想跟着做一遍,可能需要参考分布式微博爬虫的源码,自己动手实现一下,或者跑一下,印象可能会更加深刻。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





