PythonжҖ§иғҪдјҳеҢ–еҲҶжһҗ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңPythonжҖ§иғҪдјҳеҢ–еҲҶжһҗвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
pythonдёәд»Җд№ҲжҖ§иғҪе·®пјҡ
еҪ“жҲ‘们жҸҗеҲ°дёҖй—Ёзј–зЁӢиҜӯиЁҖзҡ„ж•ҲзҺҮж—¶пјҡйҖҡеёёжңүдёӨеұӮж„ҸжҖқпјҢ***жҳҜејҖеҸ‘ж•ҲзҺҮпјҢиҝҷжҳҜеҜ№зЁӢеәҸе‘ҳиҖҢиЁҖпјҢе®ҢжҲҗзј–з ҒжүҖйңҖиҰҒзҡ„ж—¶й—ҙ;еҸҰдёҖдёӘжҳҜиҝҗиЎҢж•ҲзҺҮпјҢиҝҷжҳҜеҜ№и®Ўз®—жңәиҖҢиЁҖпјҢе®ҢжҲҗи®Ўз®—д»»еҠЎжүҖйңҖиҰҒзҡ„ж—¶й—ҙгҖӮзј–з Ғж•ҲзҺҮе’ҢиҝҗиЎҢж•ҲзҺҮеҫҖеҫҖжҳҜйұјдёҺзҶҠжҺҢзҡ„е…ізі»пјҢжҳҜеҫҲйҡҫеҗҢж—¶е…јйЎҫзҡ„гҖӮдёҚеҗҢзҡ„иҜӯиЁҖдјҡжңүдёҚеҗҢзҡ„дҫ§йҮҚпјҢpythonиҜӯиЁҖжҜ«ж— з–‘й—®жӣҙеңЁд№Һзј–з Ғж•ҲзҺҮпјҢlife is shortпјҢwe use pythonгҖӮ
иҷҪ然дҪҝз”Ёpythonзҡ„зј–зЁӢдәәе‘ҳйғҪеә”иҜҘжҺҘеҸ—е…¶иҝҗиЎҢж•ҲзҺҮдҪҺзҡ„дәӢе®һпјҢдҪҶpythonеңЁи¶ҠеӨҡи¶ҠжқҘзҡ„йўҶеҹҹйғҪжңүе№ҝжіӣеә”з”ЁпјҢжҜ”еҰӮ科еӯҰи®Ўз®— гҖҒwebжңҚеҠЎеҷЁзӯүгҖӮзЁӢеәҸе‘ҳеҪ“然д№ҹеёҢжңӣpythonиғҪеӨҹиҝҗз®—еҫ—жӣҙеҝ«пјҢеёҢжңӣpythonеҸҜд»ҘжӣҙејәеӨ§гҖӮ
йҰ–е…ҲпјҢpythonзӣёжҜ”е…¶д»–иҜӯиЁҖе…·дҪ“жңүеӨҡж…ўпјҢиҝҷдёӘдёҚеҗҢеңәжҷҜе’ҢжөӢиҜ•з”ЁдҫӢпјҢз»“жһңиӮҜе®ҡжҳҜдёҚдёҖж ·зҡ„гҖӮиҝҷдёӘзҪ‘еқҖз»ҷеҮәдәҶдёҚеҗҢиҜӯиЁҖеңЁеҗ„з§ҚcaseдёӢзҡ„жҖ§иғҪеҜ№жҜ”пјҢиҝҷдёҖйЎөжҳҜpython3е’ҢC++зҡ„еҜ№жҜ”пјҢдёӢйқўжҳҜдёӨдёӘcaseпјҡ
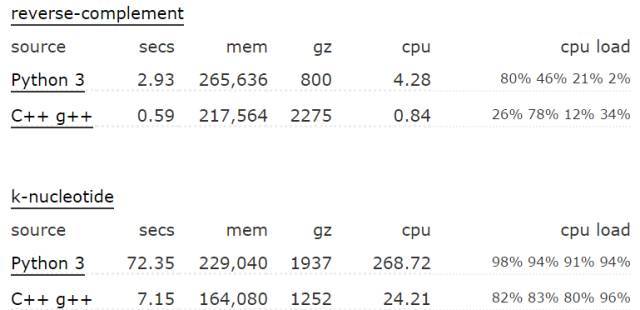
pythonиҝҗз®—ж•ҲзҺҮдҪҺпјҢе…·дҪ“жҳҜд»Җд№ҲеҺҹеӣ е‘ўпјҢдёӢеҲ—зҪ—еҲ—дёҖдәӣ
***пјҡpythonжҳҜеҠЁжҖҒиҜӯиЁҖ
дёҖдёӘеҸҳйҮҸжүҖжҢҮеҗ‘еҜ№иұЎзҡ„зұ»еһӢеңЁиҝҗиЎҢж—¶жүҚзЎ®е®ҡпјҢзј–иҜ‘еҷЁеҒҡдёҚдәҶд»»дҪ•йў„жөӢпјҢд№ҹе°ұж— д»ҺдјҳеҢ–гҖӮдёҫдёҖдёӘз®ҖеҚ•зҡ„дҫӢеӯҗпјҡгҖҖr = a + bгҖӮгҖҖaе’ҢbзӣёеҠ пјҢдҪҶaе’Ңbзҡ„зұ»еһӢеңЁиҝҗиЎҢж—¶жүҚзҹҘйҒ“пјҢеҜ№дәҺеҠ жі•ж“ҚдҪңпјҢдёҚеҗҢзҡ„зұ»еһӢжңүдёҚеҗҢзҡ„еӨ„зҗҶпјҢжүҖд»ҘжҜҸж¬ЎиҝҗиЎҢзҡ„ж—¶еҖҷйғҪдјҡеҺ»еҲӨж–ӯaе’Ңbзҡ„зұ»еһӢпјҢ然еҗҺжү§иЎҢеҜ№еә”зҡ„ж“ҚдҪңгҖӮиҖҢеңЁйқҷжҖҒиҜӯиЁҖеҰӮC++дёӯпјҢзј–иҜ‘зҡ„ж—¶еҖҷе°ұзЎ®е®ҡдәҶиҝҗиЎҢж—¶зҡ„д»Јз ҒгҖӮ
第дәҢпјҡpythonжҳҜи§ЈйҮҠжү§иЎҢпјҢдҪҶжҳҜдёҚж”ҜжҢҒJIT(just in time compiler)гҖӮиҷҪ然еӨ§еҗҚйјҺйјҺзҡ„googleжӣҫз»Ҹе°қиҜ•Unladen Swallow иҝҷдёӘйЎ№зӣ®пјҢдҪҶжңҖз»Ҳд№ҹжҠҳдәҶгҖӮ
第дёүпјҡpythonдёӯдёҖеҲҮйғҪжҳҜеҜ№иұЎпјҢжҜҸдёӘеҜ№иұЎйғҪйңҖиҰҒз»ҙжҠӨеј•з”Ёи®Ўж•°пјҢеўһеҠ дәҶйўқеӨ–зҡ„е·ҘдҪңгҖӮ
第еӣӣпјҡpython GIL
GILжҳҜPythonжңҖдёәиҜҹз—…зҡ„дёҖзӮ№пјҢеӣ дёәGILпјҢpythonдёӯзҡ„еӨҡзәҝзЁӢ并дёҚиғҪзңҹжӯЈзҡ„并еҸ‘гҖӮеҰӮжһңжҳҜеңЁIO boundзҡ„дёҡеҠЎеңәжҷҜпјҢиҝҷдёӘй—®йўҳ并дёҚеӨ§пјҢдҪҶжҳҜеңЁCPU BOUNDзҡ„еңәжҷҜпјҢиҝҷе°ұеҫҲиҮҙе‘ҪдәҶгҖӮжүҖд»Ҙ笔иҖ…еңЁе·ҘдҪңдёӯдҪҝз”ЁpythonеӨҡзәҝзЁӢзҡ„жғ…еҶө并дёҚеӨҡпјҢдёҖиҲ¬йғҪжҳҜдҪҝз”ЁеӨҡиҝӣзЁӢ(pre fork)пјҢжҲ–иҖ…еңЁеҠ дёҠеҚҸзЁӢгҖӮеҚідҪҝеңЁеҚ•зәҝзЁӢпјҢGILд№ҹдјҡеёҰжқҘеҫҲеӨ§зҡ„жҖ§иғҪеҪұе“ҚпјҢеӣ дёәpythonжҜҸжү§иЎҢ100дёӘopcode(й»ҳи®ӨпјҢеҸҜд»ҘйҖҡиҝҮsys.setcheckinterval()и®ҫзҪ®)е°ұдјҡе°қиҜ•зәҝзЁӢзҡ„еҲҮжҚўпјҢе…·дҪ“зҡ„жәҗд»Јз ҒеңЁceval.c::PyEval_EvalFrameExгҖӮ
第дә”пјҡеһғеңҫеӣһ收пјҢиҝҷдёӘеҸҜиғҪжҳҜжүҖжңүе…·жңүеһғеңҫеӣһ收зҡ„зј–зЁӢиҜӯиЁҖзҡ„йҖҡз—…гҖӮpythonйҮҮз”Ёж Үи®°е’ҢеҲҶд»Јзҡ„еһғеңҫеӣһ收зӯ–з•ҘпјҢжҜҸж¬Ўеһғеңҫеӣһ收зҡ„ж—¶еҖҷйғҪдјҡдёӯж–ӯжӯЈеңЁжү§иЎҢзҡ„зЁӢеәҸпјҢйҖ жҲҗжүҖи°“зҡ„йЎҝеҚЎгҖӮinfoqдёҠжңүдёҖзҜҮж–Үз« пјҢжҸҗеҲ°зҰҒз”ЁPythonзҡ„GCжңәеҲ¶еҗҺпјҢInstagramжҖ§иғҪжҸҗеҚҮдәҶ10%гҖӮж„ҹе…ҙи¶Јзҡ„иҜ»иҖ…еҸҜд»ҘеҺ»з»ҶиҜ»гҖӮ
Be pythonic
жҲ‘们йғҪзҹҘйҒ“ иҝҮж—©зҡ„дјҳеҢ–жҳҜзҪӘжҒ¶д№ӢжәҗпјҢдёҖеҲҮдјҳеҢ–йғҪйңҖиҰҒеҹәдәҺprofileгҖӮдҪҶжҳҜпјҢдҪңдёәдёҖдёӘpythonејҖеҸ‘иҖ…еә”иҜҘиҰҒpythonicпјҢиҖҢдё”pythonicзҡ„д»Јз ҒеҫҖеҫҖжҜ”non-pythonicзҡ„д»Јз Ғж•ҲзҺҮй«ҳдёҖдәӣпјҢжҜ”еҰӮпјҡ
dictзҡ„iteritems иҖҢдёҚжҳҜitems(еҗҢitervaluesпјҢiterkeys)
дҪҝз”ЁgeneratorпјҢзү№еҲ«жҳҜеңЁеҫӘзҺҜдёӯеҸҜиғҪжҸҗеүҚbreakзҡ„жғ…еҶө
еҲӨж–ӯжҳҜеҗҰжҳҜеҗҢдёҖдёӘеҜ№иұЎдҪҝз”Ё is иҖҢдёҚжҳҜ ==
еҲӨж–ӯдёҖдёӘеҜ№иұЎжҳҜеҗҰеңЁдёҖдёӘйӣҶеҗҲдёӯпјҢдҪҝз”ЁsetиҖҢдёҚжҳҜlist
еҲ©з”Ёзҹӯи·ҜжұӮеҖјзү№жҖ§пјҢжҠҠвҖңзҹӯи·ҜвҖқжҰӮзҺҮиҝҮзҡ„йҖ»иҫ‘иЎЁиҫҫејҸеҶҷеңЁеүҚйқўгҖӮе…¶д»–зҡ„lazy ideasд№ҹжҳҜеҸҜд»Ҙзҡ„
еҜ№дәҺеӨ§йҮҸеӯ—з¬ҰдёІзҡ„зҙҜеҠ пјҢдҪҝз”Ёjoinж“ҚдҪң
дҪҝз”Ёfor else(while else)иҜӯжі•
дәӨжҚўдёӨдёӘеҸҳйҮҸзҡ„еҖјдҪҝз”Ёпјҡ a, b = b, a
еҹәдәҺprofileзҡ„дјҳеҢ–
еҚідҪҝжҲ‘们зҡ„д»Јз Ғе·Із»ҸйқһеёёpythonicдәҶпјҢдҪҶеҸҜиғҪиҝҗиЎҢж•ҲзҺҮиҝҳжҳҜдёҚиғҪж»Ўи¶ійў„жңҹгҖӮжҲ‘们д№ҹзҹҘйҒ“80/20е®ҡеҫӢпјҢз»қеӨ§еӨҡж•°зҡ„ж—¶й—ҙйғҪиҖ—иҙ№еңЁе°‘йҮҸзҡ„д»Јз ҒзүҮж®өйҮҢйқўдәҶпјҢдјҳеҢ–зҡ„е…ій”®еңЁдәҺжүҫеҮәиҝҷдәӣ瓶йўҲд»Јз ҒгҖӮж–№ејҸеҫҲеӨҡпјҡеҲ°еӨ„еҠ logжү“еҚ°ж—¶й—ҙжҲігҖҒжҲ–иҖ…е°ҶжҖҖз–‘зҡ„еҮҪж•°дҪҝз”ЁtimeitиҝӣиЎҢеҚ•зӢ¬жөӢиҜ•пјҢдҪҶжңҖжңүж•Ҳзҡ„жҳҜдҪҝз”Ёprofileе·Ҙе…·гҖӮ
python profilers
еҜ№дәҺpythonзЁӢеәҸпјҢжҜ”иҫғеҮәеҗҚзҡ„profileе·Ҙе…·жңүдёүдёӘпјҡprofileгҖҒcprofileе’ҢhotshotгҖӮе…¶дёӯprofileжҳҜзәҜpythonиҜӯиЁҖе®һзҺ°зҡ„пјҢCprofileе°Ҷprofileзҡ„йғЁеҲҶе®һзҺ°nativeеҢ–пјҢhotshotд№ҹжҳҜCиҜӯиЁҖе®һзҺ°пјҢhotshotдёҺCprofileзҡ„еҢәеҲ«еңЁдәҺпјҡhotshotеҜ№зӣ®ж Үд»Јз Ғзҡ„иҝҗиЎҢеҪұе“Қиҫғе°ҸпјҢд»Јд»·жҳҜжӣҙеӨҡзҡ„еҗҺеӨ„зҗҶж—¶й—ҙпјҢиҖҢдё”hotshotе·Із»ҸеҒңжӯўз»ҙжҠӨдәҶгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢprofile(Cprofile hotshot)еҸӘйҖӮеҗҲеҚ•зәҝзЁӢзҡ„pythonзЁӢеәҸгҖӮ
еҜ№дәҺеӨҡзәҝзЁӢпјҢеҸҜд»ҘдҪҝз”ЁyappiпјҢyappiдёҚд»…ж”ҜжҢҒеӨҡзәҝзЁӢпјҢиҝҳеҸҜд»ҘзІҫзЎ®еҲ°CPUж—¶й—ҙ
еҜ№дәҺеҚҸзЁӢ(greenlet)пјҢеҸҜд»ҘдҪҝз”ЁgreenletprofilerпјҢеҹәдәҺyappiдҝ®ж”№пјҢз”Ёgreenlet context hookдҪҸthread context
дёӢйқўз»ҷеҮәдёҖж®өзј–йҖ зҡ„вҖқж•ҲзҺҮдҪҺдёӢвҖңзҡ„д»Јз ҒпјҢ并дҪҝз”ЁCprofileжқҘиҜҙжҳҺprofileзҡ„е…·дҪ“ж–№жі•д»ҘеҸҠжҲ‘们еҸҜиғҪйҒҮеҲ°зҡ„жҖ§иғҪ瓶йўҲгҖӮ
# -*- coding: UTF-8 -*- from cProfile import Profile import math def foo(): return foo1() def foo1(): return foo2() def foo2(): return foo3() def foo3(): return foo4() def foo4(): return "this call tree seems ugly, but it always happen" def bar(): ret = 0 for i in xrange(10000): ret += i * i + math.sqrt(i) return ret def main(): for i in range(100000): if i % 10000 == 0: bar() else: foo() if __name__ == '__main__': prof = Profile() prof.runcall(main) prof.print_stats() #prof.dump_stats('test.prof') # dump profile result to test.prof code for profileиҝҗиЎҢз»“жһңеҰӮдёӢпјҡ
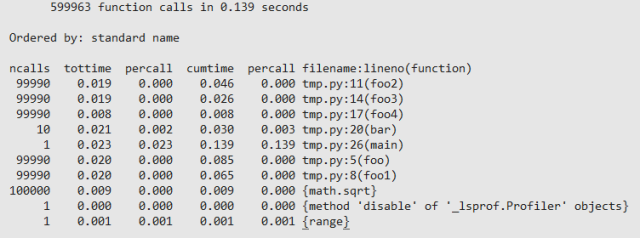
еҜ№дәҺдёҠйқўзҡ„зҡ„иҫ“еҮәпјҢжҜҸдёҖдёӘеӯ—ж®өж„Ҹд№үеҰӮдёӢпјҡ
ncalls еҮҪж•°жҖ»зҡ„и°ғз”Ёж¬Ўж•°
tottime еҮҪж•°еҶ…йғЁ(дёҚеҢ…жӢ¬еӯҗеҮҪж•°)зҡ„еҚ з”Ёж—¶й—ҙ
percall(***дёӘ) tottime/ncalls
cumtime еҮҪж•°еҢ…жӢ¬еӯҗеҮҪж•°жүҖеҚ з”Ёзҡ„ж—¶й—ҙ
percall(第дәҢдёӘ)cumtime/ncalls
filename:lineno(function) ж–Ү件пјҡиЎҢеҸ·(еҮҪж•°)
д»Јз Ғдёӯзҡ„иҫ“еҮәйқһеёёз®ҖеҚ•пјҢдәӢе®һдёҠеҸҜд»ҘеҲ©з”ЁpstatпјҢи®©profileз»“жһңзҡ„иҫ“еҮәеӨҡж ·еҢ–пјҢе…·дҪ“еҸҜд»ҘеҸӮи§Ғе®ҳж–№ж–ҮжЎЈpython profilerгҖӮ
profile GUI tools
иҷҪ然Cprofileзҡ„иҫ“еҮәе·Із»ҸжҜ”иҫғзӣҙи§ӮпјҢдҪҶжҲ‘们иҝҳжҳҜеҖҫеҗ‘дәҺдҝқеӯҳprofileзҡ„з»“жһңпјҢ然еҗҺз”ЁеӣҫеҪўеҢ–зҡ„е·Ҙе…·жқҘд»ҺдёҚеҗҢзҡ„з»ҙеәҰжқҘеҲҶжһҗпјҢжҲ–иҖ…жҜ”иҫғдјҳеҢ–еүҚеҗҺзҡ„д»Јз ҒгҖӮжҹҘзңӢprofileз»“жһңзҡ„е·Ҙе…·д№ҹжҜ”иҫғеӨҡпјҢжҜ”еҰӮпјҢvisualpytuneгҖҒqcachegrindгҖҒrunsnakerunпјҢжң¬ж–Үз”ЁvisualpytuneеҒҡеҲҶжһҗгҖӮеҜ№дәҺдёҠйқўзҡ„д»Јз ҒпјҢжҢүз…§жіЁйҮҠз”ҹжҲҗдҝ®ж”№еҗҺйҮҚж–°иҝҗиЎҢз”ҹжҲҗtest.profж–Ү件пјҢз”ЁvisualpytuneзӣҙжҺҘжү“ејҖе°ұеҸҜд»ҘдәҶпјҢеҰӮдёӢпјҡ
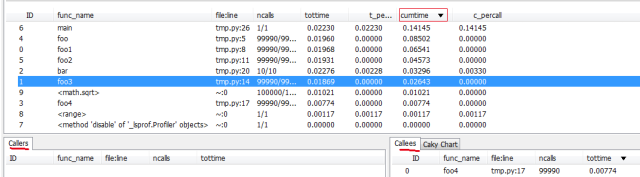
еӯ—ж®өзҡ„ж„Ҹд№үдёҺж–Үжң¬иҫ“еҮәеҹәжң¬дёҖиҮҙпјҢдёҚиҝҮдҫҝжҚ·жҖ§еҸҜд»ҘзӮ№еҮ»еӯ—ж®өеҗҚжҺ’еәҸгҖӮе·ҰдёӢж–№еҲ—еҮәдәҶеҪ“еүҚеҮҪж•°зҡ„calller(и°ғз”ЁиҖ…)пјҢеҸідёӢж–№жҳҜеҪ“еүҚеҮҪж•°еҶ…йғЁдёҺеӯҗеҮҪж•°зҡ„ж—¶й—ҙеҚ з”Ёжғ…еҶөгҖӮдёҠеҰӮжҳҜжҢүз…§cumtime(еҚіиҜҘеҮҪж•°еҶ…йғЁеҸҠе…¶еӯҗеҮҪж•°жүҖеҚ зҡ„ж—¶й—ҙе’Ң)жҺ’еәҸзҡ„з»“жһңгҖӮ
йҖ жҲҗжҖ§иғҪ瓶йўҲзҡ„еҺҹеӣ йҖҡеёёжҳҜй«ҳйў‘и°ғз”Ёзҡ„еҮҪж•°гҖҒеҚ•ж¬Ўж¶ҲиҖ—йқһеёёй«ҳзҡ„еҮҪж•°гҖҒжҲ–иҖ…дәҢиҖ…зҡ„з»“еҗҲгҖӮеңЁжҲ‘们еүҚйқўзҡ„дҫӢеӯҗдёӯпјҢfooе°ұеұһдәҺй«ҳйў‘и°ғз”Ёзҡ„жғ…еҶөпјҢbarеұһдәҺеҚ•ж¬Ўж¶ҲиҖ—йқһеёёй«ҳзҡ„жғ…еҶөпјҢиҝҷйғҪжҳҜжҲ‘们йңҖиҰҒдјҳеҢ–зҡ„йҮҚзӮ№гҖӮ
python-profiling-toolsдёӯд»Ӣз»ҚдәҶqcachegrindе’Ңrunsnakerunзҡ„дҪҝз”Ёж–№жі•пјҢиҝҷдёӨдёӘcolorfulзҡ„е·Ҙе…·жҜ”visualpytuneејәеӨ§еҫ—еӨҡгҖӮе…·дҪ“зҡ„дҪҝз”Ёж–№жі•иҜ·еҸӮиҖғеҺҹж–ҮпјҢдёӢеӣҫз»ҷеҮәtest.profз”Ёqcachegrindжү“ејҖзҡ„з»“жһңгҖӮ
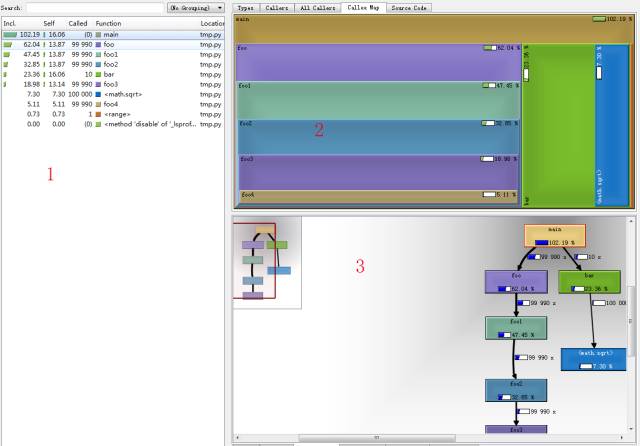
qcachegrindзЎ®е®һиҰҒжҜ”visualpytuneејәеӨ§гҖӮд»ҺдёҠеӣҫеҸҜд»ҘзңӢеҲ°пјҢеӨ§иҮҙеҲҶдёәдёүйғЁпјҡгҖӮ***йғЁеҲҶеҗҢvisualpytuneзұ»дјјпјҢжҳҜжҜҸдёӘеҮҪж•°еҚ з”Ёзҡ„ж—¶й—ҙпјҢе…¶дёӯInclзӯүеҗҢдәҺcumtimeпјҢ SelfзӯүеҗҢдәҺtottimeгҖӮ第дәҢйғЁеҲҶе’Ң第дёүйғЁеҲҶйғҪжңүеҫҲеӨҡж ҮзӯҫпјҢдёҚеҗҢзҡ„ж Үзӯҫж ҮзӨәд»ҺдёҚеҗҢзҡ„и§’еәҰжқҘзңӢз»“жһңпјҢеҰӮеӣҫдёҠжүҖд»ҘпјҢ第дёүйғЁеҲҶзҡ„вҖңcall graphвҖқеұ•зӨәдәҶиҜҘеҮҪж•°зҡ„call tree并еҢ…еҗ«жҜҸдёӘеӯҗеҮҪж•°зҡ„ж—¶й—ҙзҷҫеҲҶжҜ”пјҢдёҖзӣ®дәҶ然гҖӮ
profileй’ҲеҜ№дјҳеҢ–
зҹҘйҒ“дәҶзғӯзӮ№пјҢе°ұеҸҜд»ҘиҝӣиЎҢй’ҲеҜ№жҖ§зҡ„дјҳеҢ–пјҢиҖҢиҝҷдёӘдјҳеҢ–еҫҖеҫҖж №е…·дҪ“зҡ„дёҡеҠЎеҜҶеҲҮзӣёе…іпјҢжІЎз”Ё***й’ҘеҢҷпјҢе…·дҪ“й—®йўҳпјҢе…·дҪ“еҲҶжһҗгҖӮдёӘдәәз»ҸйӘҢиҖҢиЁҖпјҢжңҖжңүж•Ҳзҡ„дјҳеҢ–жҳҜжүҫдә§е“Ғз»ҸзҗҶи®Ёи®әйңҖжұӮпјҢеҸҜиғҪжҚўдёҖз§Қж–№ејҸд№ҹиғҪж»Ўи¶ійңҖжұӮпјҢе°‘иҖ…зЁҚеҫ®жҠҳиЎ·дёҖдёӢдә§е“Ғз»ҸзҗҶд№ҹиғҪжҺҘеҸ—гҖӮж¬Ўд№ӢжҳҜдҝ®ж”№д»Јз Ғзҡ„е®һзҺ°пјҢжҜ”еҰӮд№ӢеүҚдҪҝз”ЁдәҶдёҖдёӘжҜ”иҫғйҖҡдҝ—жҳ“жҮӮдҪҶж•ҲзҺҮиҫғдҪҺзҡ„з®—жі•пјҢеҰӮжһңиҝҷдёӘз®—жі•жҲҗдёәдәҶжҖ§иғҪ瓶йўҲпјҢйӮЈе°ұиҖғиҷ‘жҚўдёҖз§Қж•ҲзҺҮжӣҙй«ҳдҪҶжҳҜеҸҜиғҪйҡҫзҗҶи§Јзҡ„з®—жі•гҖҒжҲ–иҖ…дҪҝз”Ёdirty FlagжЁЎејҸгҖӮеҜ№дәҺиҝҷдәӣеҗҢж ·зҡ„ж–№жі•пјҢйңҖиҰҒз»“еҗҲе…·дҪ“зҡ„жЎҲдҫӢпјҢжң¬ж–ҮдёҚеҒҡиөҳиҝ°гҖӮ
жҺҘдёӢжқҘз»“еҗҲpythonиҜӯиЁҖзү№жҖ§пјҢд»Ӣз»ҚдёҖдәӣи®©pythonд»Јз ҒдёҚйӮЈд№ҲpythonicпјҢдҪҶеҸҜд»ҘжҸҗеҚҮжҖ§иғҪзҡ„дёҖдәӣеҒҡжі•
***пјҡеҮҸе°‘еҮҪж•°зҡ„и°ғз”ЁеұӮж¬Ў
жҜҸдёҖеұӮеҮҪж•°и°ғз”ЁйғҪдјҡеёҰжқҘдёҚе°Ҹзҡ„ејҖй”ҖпјҢзү№еҲ«еҜ№дәҺи°ғз”Ёйў‘зҺҮй«ҳпјҢдҪҶеҚ•ж¬Ўж¶ҲиҖ—иҫғе°Ҹзҡ„calltreeпјҢеӨҡеұӮзҡ„еҮҪж•°и°ғз”ЁејҖй”Җе°ұеҫҲеӨ§пјҢиҝҷдёӘж—¶еҖҷеҸҜд»ҘиҖғиҷ‘е°Ҷе…¶еұ•ејҖгҖӮ
еҜ№дәҺд№ӢеүҚи°ғеҲ°зҡ„profileзҡ„д»Јз ҒпјҢfooиҝҷдёӘcall treeйқһеёёз®ҖеҚ•пјҢдҪҶйў‘зҺҮй«ҳгҖӮдҝ®ж”№д»Јз ҒпјҢеўһеҠ дёҖдёӘplain_foo()еҮҪж•°, зӣҙжҺҘиҝ”еӣһжңҖз»Ҳз»“жһңпјҢе…ій”®иҫ“еҮәеҰӮдёӢпјҡ

и·ҹд№ӢеүҚзҡ„з»“жһңеҜ№жҜ”пјҡ
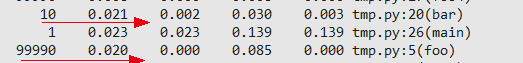
еҸҜд»ҘзңӢеҲ°пјҢдјҳеҢ–дәҶе·®дёҚеӨҡ3еҖҚгҖӮ
第дәҢпјҡдјҳеҢ–еұһжҖ§жҹҘжүҫ
дёҠйқўжҸҗеҲ°пјҢpython зҡ„еұһжҖ§жҹҘжүҫж•ҲзҺҮеҫҲдҪҺпјҢеҰӮжһңеңЁдёҖж®өд»Јз Ғдёӯйў‘з№Ғи®ҝй—®дёҖдёӘеұһжҖ§(жҜ”еҰӮforеҫӘзҺҜ)пјҢйӮЈд№ҲеҸҜд»ҘиҖғиҷ‘з”ЁеұҖйғЁеҸҳйҮҸд»ЈжӣҝеҜ№иұЎзҡ„еұһжҖ§гҖӮ
第дёүпјҡе…ій—ӯGC
еңЁжң¬ж–Үзҡ„***з« иҠӮе·Із»ҸжҸҗеҲ°пјҢе…ій—ӯGCеҸҜд»ҘжҸҗеҚҮpythonзҡ„жҖ§иғҪпјҢGCеёҰжқҘзҡ„йЎҝеҚЎеңЁе®һж—¶жҖ§иҰҒжұӮжҜ”иҫғй«ҳзҡ„еә”з”ЁеңәжҷҜд№ҹжҳҜйҡҫд»ҘжҺҘеҸ—зҡ„гҖӮдҪҶе…ій—ӯGC并дёҚжҳҜдёҖ件容жҳ“зҡ„дәӢжғ…гҖӮжҲ‘们зҹҘйҒ“pythonзҡ„еј•з”Ёи®Ўж•°еҸӘиғҪеә”д»ҳжІЎжңүеҫӘзҺҜеј•з”Ёзҡ„жғ…еҶөпјҢжңүдәҶеҫӘзҺҜеј•з”Ёе°ұйңҖиҰҒйқ GCжқҘеӨ„зҗҶгҖӮеңЁpythonиҜӯиЁҖдёӯ, еҶҷеҮәеҫӘзҺҜеј•з”Ёйқһеёёе®№жҳ“гҖӮжҜ”еҰӮпјҡ
case 1пјҡ a, b = SomeClass(), SomeClass() a.b, b.a = b, a гҖҖ case 2пјҡ lst = [] lst.append(lst) case 3пјҡ self.handler = self.some_func
еҪ“然пјҢеӨ§е®¶еҸҜиғҪиҜҙпјҢи°Ғдјҡиҝҷд№ҲеӮ»пјҢеҶҷеҮәиҝҷж ·зҡ„д»Јз ҒпјҢжҳҜзҡ„пјҢдёҠйқўзҡ„д»Јз ҒеӨӘжҳҺжҳҫпјҢеҪ“дёӯй—ҙеӨҡеҮ дёӘеұӮзә§д№ӢеҗҺпјҢе°ұдјҡеҮәзҺ°вҖңй—ҙжҺҘвҖқзҡ„еҫӘзҺҜеә”з”ЁгҖӮеңЁpythonзҡ„ж ҮеҮҶеә“ collectionsйҮҢйқўзҡ„OrderedDictе°ұжҳҜcase2пјҡ
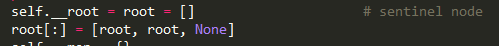
иҰҒи§ЈеҶіеҫӘзҺҜеј•з”ЁпјҢ***дёӘеҠһжі•жҳҜдҪҝз”Ёејұеј•з”Ё(weakref)пјҢ第дәҢдёӘжҳҜжүӢеҠЁи§ЈеҫӘзҺҜеј•з”ЁгҖӮ
第еӣӣпјҡsetcheckinterval
еҰӮжһңзЁӢеәҸзЎ®е®ҡжҳҜеҚ•зәҝзЁӢпјҢйӮЈд№Ҳдҝ®ж”№checkintervalдёәдёҖдёӘжӣҙеӨ§зҡ„еҖјпјҢиҝҷйҮҢжңүд»Ӣз»ҚгҖӮ
第дә”пјҡдҪҝз”Ё__slots__
slotsжңҖдё»иҰҒзҡ„зӣ®зҡ„жҳҜз”ЁжқҘиҠӮзңҒеҶ…еӯҳпјҢдҪҶжҳҜд№ҹиғҪдёҖе®ҡзЁӢеәҰдёҠжҸҗй«ҳжҖ§иғҪгҖӮжҲ‘们зҹҘйҒ“е®ҡд№үдәҶ__slots__зҡ„зұ»пјҢеҜ№жҹҗдёҖдёӘе®һдҫӢйғҪдјҡйў„з•ҷи¶іеӨҹзҡ„з©әй—ҙпјҢд№ҹе°ұдёҚдјҡеҶҚиҮӘеҠЁеҲӣе»ә__dict__гҖӮеҪ“然пјҢдҪҝз”Ё__slots__д№ҹжңүи®ёеӨҡжіЁж„ҸдәӢйЎ№пјҢжңҖйҮҚиҰҒзҡ„дёҖзӮ№пјҢ继жүҝй“ҫдёҠзҡ„жүҖжңүзұ»йғҪеҝ…йЎ»е®ҡд№ү__slots__пјҢpython docжңүиҜҰз»Ҷзҡ„жҸҸиҝ°гҖӮдёӢйқўзңӢдёҖдёӘз®ҖеҚ•зҡ„жөӢиҜ•дҫӢеӯҗпјҡ
class BaseSlots(object): __slots__ = ['e', 'f', 'g'] class Slots(BaseSlots): __slots__ = ['a', 'b', 'c', 'd'] def __init__(self): self.a = self.b = self.c = self.d = self.e = self.f = self.g = 0 class BaseNoSlots(object): pass class NoSlots(BaseNoSlots): def __init__(self): super(NoSlots,self).__init__() self.a = self.b = self.c = self.d = self.e = self.f = self.g = 0 def log_time(s): begin = time.time() for i in xrange(10000000): s.a,s.b,s.c,s.d, s.e, s.f, s.g return time.time() - begin if __name__ == '__main__': print 'Slots cost', log_time(Slots()) print 'NoSlots cost', log_time(NoSlots())
иҫ“еҮәз»“жһңпјҡ
Slots cost 3.12999987602 NoSlots cost 3.48100018501
python Cжү©еұ•
д№ҹи®ёйҖҡиҝҮprofileпјҢжҲ‘们已з»ҸжүҫеҲ°дәҶжҖ§иғҪзғӯзӮ№пјҢдҪҶиҝҷдёӘзғӯзӮ№е°ұжҳҜиҰҒиҝҗиЎҢеӨ§йҮҸзҡ„и®Ўз®—пјҢиҖҢдё”жІЎжі•cacheпјҢжІЎжі•зңҒз•ҘгҖӮгҖӮгҖӮиҝҷдёӘж—¶еҖҷе°ұиҜҘpythonзҡ„Cжү©еұ•еҮә马дәҶпјҢCжү©еұ•е°ұжҳҜжҠҠйғЁеҲҶpythonд»Јз Ғз”ЁCжҲ–иҖ…C++йҮҚж–°е®һзҺ°пјҢ然еҗҺзј–иҜ‘жҲҗеҠЁжҖҒй“ҫжҺҘеә“пјҢжҸҗдҫӣжҺҘеҸЈз»ҷе…¶е®ғpythonд»Јз Ғи°ғз”ЁгҖӮз”ұдәҺCиҜӯиЁҖзҡ„ж•ҲзҺҮиҝңиҝңй«ҳдәҺpythonд»Јз ҒпјҢжүҖд»ҘдҪҝз”ЁCжү©еұ•жҳҜйқһеёёжҷ®йҒҚзҡ„еҒҡжі•пјҢжҜ”еҰӮжҲ‘们еүҚйқўжҸҗеҲ°зҡ„cProfileе°ұжҳҜеҹәдәҺ_lsprof.soзҡ„дёҖеұӮе°ҒиЈ…гҖӮpythonзҡ„еӨ§жүҖеұһеҜ№жҖ§иғҪжңүиҰҒжұӮзҡ„еә“йғҪдҪҝз”ЁжҲ–иҖ…жҸҗдҫӣдәҶCжү©еұ•пјҢеҰӮgeventгҖҒprotobuffгҖҒbsonгҖӮ
笔иҖ…жӣҫз»ҸжөӢиҜ•иҝҮзәҜpythonзүҲжң¬зҡ„bsonе’Ңcbsonзҡ„ж•ҲзҺҮпјҢеңЁз»јеҗҲзҡ„жғ…еҶөдёӢпјҢcbsonеҝ«дәҶе·®дёҚеӨҡ10еҖҚ!
pythonзҡ„Cжү©еұ•д№ҹжҳҜдёҖдёӘйқһеёёеӨҚжқӮзҡ„й—®йўҳпјҢжң¬ж–Үд»…з»ҷеҮәдёҖдәӣжіЁж„ҸдәӢйЎ№пјҡ
***пјҡжіЁж„Ҹеј•з”Ёи®Ўж•°зҡ„жӯЈзЎ®з®ЎзҗҶ
иҝҷжҳҜжңҖйҡҫжңҖеӨҚжқӮзҡ„дёҖзӮ№гҖӮжҲ‘们йғҪзҹҘйҒ“pythonеҹәдәҺжҢҮй’ҲжҠҖжңҜжқҘз®ЎзҗҶеҜ№иұЎзҡ„з”ҹе‘Ҫе‘ЁжңҹпјҢеҰӮжһңеңЁжү©еұ•дёӯеј•з”Ёи®Ўж•°еҮәдәҶй—®йўҳпјҢйӮЈд№ҲиҰҒд№ҲжҳҜзЁӢеәҸеҙ©жәғпјҢиҰҒд№ҲжҳҜеҶ…еӯҳжі„жјҸгҖӮжӣҙиҰҒе‘Ҫзҡ„жҳҜпјҢеј•з”Ёи®Ўж•°еҜјиҮҙзҡ„й—®йўҳеҫҲйҡҫdebugгҖӮгҖӮгҖӮ
Cжү©еұ•дёӯе…ідәҺеј•з”Ёи®Ўж•°жңҖе…ій”®зҡ„дёүдёӘиҜҚжҳҜпјҡsteal referenceпјҢborrowed referenceпјҢnew referenceгҖӮе»әи®®зј–еҶҷжү©еұ•д»Јз Ғд№ӢеүҚз»ҶиҜ»pythonзҡ„е®ҳж–№ж–ҮжЎЈгҖӮ
第дәҢпјҡCжү©еұ•дёҺеӨҡзәҝзЁӢ
иҝҷйҮҢзҡ„еӨҡзәҝзЁӢжҳҜжҢҮеңЁжү©еұ•дёӯnewеҮәжқҘзҡ„CиҜӯиЁҖзәҝзЁӢпјҢиҖҢдёҚжҳҜpythonзҡ„еӨҡзәҝзЁӢпјҢеҮәдәҶpython docйҮҢйқўзҡ„д»Ӣз»ҚпјҢд№ҹеҸҜд»ҘзңӢзңӢгҖҠpython cookbookгҖӢзҡ„зӣёе…із« иҠӮгҖӮ
第дёүпјҡCжү©еұ•еә”з”ЁеңәжҷҜ
д»…йҖӮеҗҲдёҺдёҡеҠЎд»Јз Ғзҡ„е…ізі»дёҚйӮЈд№Ҳзҙ§еҜҶзҡ„йҖ»иҫ‘пјҢеҰӮжһңдёҖж®өд»Јз ҒеӨ§йҮҸдёҡеҠЎзӣёе…ізҡ„еҜ№иұЎ еұһжҖ§зҡ„иҜқпјҢжҳҜеҫҲйҡҫCжү©еұ•зҡ„
е°ҶCжү©еұ•е°ҒиЈ…жҲҗpythonд»Јз ҒеҸҜи°ғз”Ёзҡ„жҺҘеҸЈзҡ„иҝҮзЁӢз§°д№ӢдёәbindingпјҢCpythonжң¬иә«е°ұжҸҗдҫӣдәҶдёҖеҘ—еҺҹз”ҹзҡ„APIпјҢиҷҪ然дҪҝз”ЁжңҖдёәе№ҝжіӣпјҢдҪҶиҜҘ规иҢғжҜ”иҫғеӨҚжқӮгҖӮеҫҲеӨҡ第дёүж–№еә“еҒҡдәҶдёҚеҗҢзЁӢеәҰзҡ„е°ҒиЈ…пјҢд»ҘдҫҝејҖеҸ‘иҖ…дҪҝз”ЁпјҢжҜ”еҰӮboost.pythonгҖҒcythonгҖҒctypesгҖҒcffi(еҗҢж—¶ж”ҜжҢҒpypy cpython)пјҢе…·дҪ“жҖҺд№ҲдҪҝз”ЁеҸҜд»ҘgoogleгҖӮ
beyond CPython
е°Ҫз®Ўpythonзҡ„жҖ§иғҪе·®ејәдәәж„ҸпјҢдҪҶжҳҜе…¶жҳ“еӯҰжҳ“з”Ёзҡ„зү№жҖ§иҝҳжҳҜиөўеҫ—и¶ҠжқҘи¶ҠеӨҡзҡ„дҪҝз”ЁиҖ…пјҢдёҡз•ҢеӨ§зүӣд№ҹд»ҺжқҘжІЎжңүж”ҫејғеҜ№pythonзҡ„дјҳеҢ–гҖӮиҝҷйҮҢзҡ„дјҳеҢ–жҳҜеҜ№pythonиҜӯиЁҖи®ҫи®ЎдёҠгҖҒжҲ–иҖ…е®һзҺ°дёҠзҡ„дёҖдәӣеҸҚжҖқжҲ–иҖ…еўһејәгҖӮиҝҷдәӣдјҳеҢ–йЎ№зӣ®дёҖдәӣе·Із»ҸеӨӯжҠҳпјҢдёҖдәӣиҝҳеңЁиҝӣдёҖжӯҘж”№е–„дёӯпјҢеңЁиҝҷдёӘз« иҠӮд»Ӣз»Қзӣ®еүҚиҝҳдёҚй”ҷзҡ„дёҖдәӣйЎ№зӣ®гҖӮ
cython
еүҚйқўжҸҗеҲ°cythonеҸҜд»Ҙз”ЁеҲ°binding cжү©еұ•пјҢдҪҶжҳҜе…¶дҪңз”ЁиҝңиҝңдёҚжӯўиҝҷдёҖзӮ№гҖӮ
Cythonзҡ„дё»иҰҒзӣ®зҡ„жҳҜеҠ йҖҹpythonзҡ„иҝҗиЎҢж•ҲзҺҮпјҢдҪҶжҳҜеҸҲдёҚеғҸдёҠдёҖз« иҠӮжҸҗеҲ°зҡ„Cжү©еұ•йӮЈд№ҲеӨҚжқӮгҖӮеңЁCythonдёӯпјҢеҶҷCжү©еұ•е’ҢеҶҷpythonд»Јз Ғзҡ„еӨҚжқӮеәҰе·®дёҚеӨҡ(еӨҡдәҸдәҶPyrex)гҖӮCythonжҳҜpythonиҜӯиЁҖзҡ„и¶…йӣҶпјҢеўһеҠ дәҶеҜ№CиҜӯиЁҖеҮҪж•°и°ғз”Ёе’Ңзұ»еһӢеЈ°жҳҺзҡ„ж”ҜжҢҒгҖӮд»ҺиҝҷдёӘи§’еәҰжқҘзңӢпјҢcythonе°ҶеҠЁжҖҒзҡ„pythonд»Јз ҒиҪ¬жҚўжҲҗйқҷжҖҒзј–иҜ‘зҡ„Cд»Јз ҒпјҢиҝҷд№ҹжҳҜcythonй«ҳж•Ҳзҡ„еҺҹеӣ гҖӮдҪҝз”ЁcythonеҗҢCжү©еұ•дёҖж ·пјҢйңҖиҰҒзј–иҜ‘жҲҗеҠЁжҖҒй“ҫжҺҘеә“пјҢеңЁlinuxзҺҜеўғдёӢж—ўеҸҜд»Ҙз”Ёе‘Ҫд»ӨиЎҢпјҢд№ҹеҸҜд»Ҙз”ЁdistutilsгҖӮ
еҰӮжһңжғіиҰҒзі»з»ҹеӯҰд№ cythonпјҢе»әи®®д»Һcython documentе…ҘжүӢпјҢж–ҮжЎЈеҶҷеҫ—еҫҲеҘҪгҖӮдёӢйқўйҖҡиҝҮдёҖдёӘз®ҖеҚ•зҡ„зӨәдҫӢжқҘеұ•зӨәcythonзҡ„дҪҝз”Ёж–№жі•е’ҢжҖ§иғҪ(linuxзҺҜеўғ)гҖӮ
йҰ–е…ҲпјҢе®үиЈ…cythonпјҡ
pip install Cython
дёӢйқўжҳҜжөӢиҜ•з”Ёзҡ„pythonд»Јз ҒпјҢеҸҜд»ҘзңӢеҲ°иҝҷдёӨдёӘcaseйғҪжҳҜиҝҗз®—еӨҚжқӮеәҰжҜ”иҫғй«ҳзҡ„дҫӢеӯҗпјҡ
def f(): return x**2-x def integrate_f(a, b, N): s = 0 dx = (b-a)/N for i in range(N): s += f(a+i*dx) return s * dx def main(): import time begin = time.time() for i in xrange(10000): for i in xrange(100):f(10) print 'call f cost:', time.time() - begin begin = time.time() for i in xrange(10000): integrate_f(1.0, 100.0, 1000) print 'call integrate_f cost:', time.time() - begin if __name__ == '__main__': main()
иҝҗиЎҢз»“жһңпјҡ
call f cost: 0.215116024017 call integrate_f cost: 4.33698010445
дёҚж”№еҠЁд»»дҪ•pythonд»Јз Ғд№ҹеҸҜд»Ҙдә«еҸ—еҲ°cythonеёҰжқҘзҡ„жҖ§иғҪжҸҗеҚҮпјҢе…·дҪ“еҒҡжі•еҰӮдёӢпјҡ
from distutils.core import setup from Cython.Build import cythonize setup( name = 'cython_example', ext_modules = cythonize("cython_example.pyx"), )
еҸҜд»ҘзңӢеҲ° еўһеҠ дәҶдёӨдёӘж–Ү件пјҢеҜ№еә”дёӯй—ҙз»“жһңе’Ң***зҡ„еҠЁжҖҒй“ҫжҺҘеә“
иҝҗиЎҢз»“жһңпјҡ
call f cost: 0.0874309539795 call integrate_f cost: 2.92381191254
жҖ§иғҪжҸҗеҚҮдәҶеӨ§жҰӮдёӨеҖҚпјҢжҲ‘们еҶҚжқҘиҜ•иҜ•cythonжҸҗдҫӣзҡ„йқҷжҖҒзұ»еһӢ(static typing)пјҢдҝ®ж”№cython_example.pyxзҡ„ж ёеҝғд»Јз ҒпјҢжӣҝжҚўf()е’Ңintegrate_f()зҡ„е®һзҺ°еҰӮдёӢпјҡ
def f(double x): # еҸӮж•°йқҷжҖҒзұ»еһӢ return x**2-x def integrate_f(double a, double b, int N): cdef int i cdef double s, dx s = 0 dx = (b-a)/N for i in range(N): s += f(a+i*dx) return s * dx
然еҗҺйҮҚж–°иҝҗиЎҢдёҠйқўзҡ„第дёү еӣӣжӯҘпјҡз»“жһңеҰӮдёӢ
call f cost: 0.042387008667 call integrate_f cost: 0.958620071411
дёҠйқўзҡ„д»Јз ҒпјҢеҸӘжҳҜеҜ№еҸӮж•°еј•е…ҘдәҶйқҷжҖҒзұ»еһӢеҲӨж–ӯпјҢдёӢйқўеҜ№иҝ”еӣһеҖјд№ҹеј•е…ҘйқҷжҖҒзұ»еһӢеҲӨж–ӯгҖӮ
жӣҝжҚўf()е’Ңintegrate_f()зҡ„е®һзҺ°еҰӮдёӢпјҡ
cdef double f(double x): # иҝ”еӣһеҖјд№ҹжңүзұ»еһӢеҲӨж–ӯ return x**2-x cdef double integrate_f(double a, double b, int N): cdef int i cdef double s, dx s = 0 dx = (b-a)/N for i in range(N): s += f(a+i*dx) return s * dx
然еҗҺйҮҚж–°иҝҗиЎҢдёҠйқўзҡ„第дёү еӣӣжӯҘпјҡз»“жһңеҰӮдёӢ
call f cost: 1.19209289551e-06 call integrate_f cost: 0.187038183212
Amazing!
pypy
pypyжҳҜCPythonзҡ„дёҖдёӘжӣҝд»Је®һзҺ°пјҢе…¶жңҖдё»иҰҒзҡ„дјҳеҠҝе°ұжҳҜpypyзҡ„йҖҹеәҰпјҢдёӢйқўжҳҜе®ҳзҪ‘зҡ„жөӢиҜ•з»“жһңпјҡ
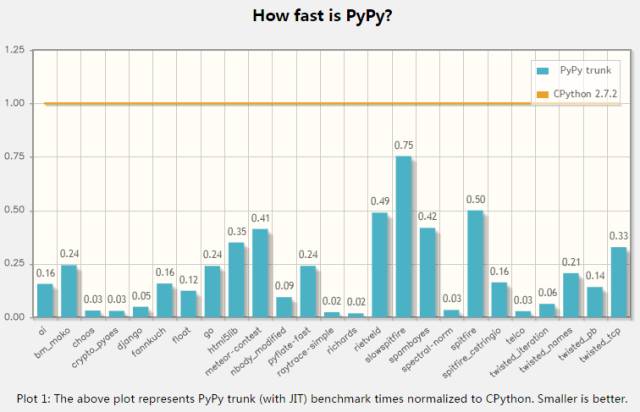
еңЁе®һйҷ…йЎ№зӣ®дёӯжөӢиҜ•пјҢpypyеӨ§жҰӮжҜ”cpythonиҰҒеҝ«3еҲ°5еҖҚ!pypyзҡ„жҖ§иғҪжҸҗеҚҮжқҘиҮӘJIT CompilerгҖӮеңЁеүҚж–ҮжҸҗеҲ°googleзҡ„Unladen Swallow йЎ№зӣ®д№ҹжҳҜжғіеңЁCPythonдёӯеј•е…ҘJITпјҢеңЁиҝҷдёӘйЎ№зӣ®еӨұиҙҘеҗҺпјҢеҫҲеӨҡејҖеҸ‘дәәе‘ҳйғҪејҖе§ӢеҠ е…Ҙpypyзҡ„ејҖеҸ‘е’ҢдјҳеҢ–гҖӮеҸҰеӨ–pypyеҚ з”Ёзҡ„еҶ…еӯҳжӣҙе°‘пјҢиҖҢдё”ж”ҜжҢҒstacklessпјҢеҹәжң¬зӯүеҗҢдәҺеҚҸзЁӢгҖӮ
pypyзҡ„зјәзӮ№еңЁдәҺеҜ№Cжү©еұ•ж–№йқўж”ҜжҢҒзҡ„дёҚеӨӘеҘҪпјҢйңҖиҰҒдҪҝз”ЁCFFiжқҘеҒҡbindingгҖӮеҜ№дәҺдҪҝз”Ёе№ҝжіӣзҡ„libraryжқҘиҜҙпјҢдёҖиҲ¬йғҪдјҡж”ҜжҢҒpypyпјҢдҪҶжҳҜе°Ҹдј—зҡ„гҖҒжҲ–иҖ…иҮӘиЎҢејҖеҸ‘зҡ„Cжү©еұ•е°ұйңҖиҰҒйҮҚж–°е°ҒиЈ…дәҶгҖӮ
вҖңPythonжҖ§иғҪдјҳеҢ–еҲҶжһҗвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





