这篇文章主要介绍“Java TreeMap源码是什么”,在日常操作中,相信很多人在Java TreeMap源码是什么问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Java TreeMap源码是什么”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
签名(signature)
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
可以看到,相比HashMap来说,TreeMap多继承了一个接口NavigableMap,也就是这个接口,决定了TreeMap与HashMap的不同:
HashMap的key是无序的,TreeMap的key是有序的
接口NavigableMap
首先看下NavigableMap的签名
public interface NavigableMap<K,V> extends SortedMap<K,V>
发现NavigableMap继承了SortedMap,再看SortedMap的签名
SortedMap
public interface SortedMap<K,V> extends Map<K,V>
SortedMap就像其名字那样,说明这个Map是有序的。这个顺序一般是指由Comparable接口提供的keys的自然序(natural ordering),或者也可以在创建SortedMap实例时,指定一个Comparator来 决定。 当我们在用集合视角(collection views,与HashMap一样,也是由entrySet、keySet与values方法提供)来迭代(iterate)一个SortedMap实例 时会体现出key的顺序。 这里引申下关于Comparable与Comparator的区别(参考这里):
Comparable一般表示类的自然序,比如定义一个Student类,学号为默认排序
Comparator一般表示类在某种场合下的特殊分类,需要定制化排序。比如现在想按照Student类的age来排序
插入SortedMap中的key的类类都必须继承Comparable类(或指定一个comparator),这样才能确定如何比较(通过k1.compareTo(k2)或comparator.compare(k1, k2))两个key,否则,在插入时,会报ClassCastException的异常。 此为,SortedMap中key的顺序性应该与equals方法保持一致。也就是说k1.compareTo(k2)或comparator.compare(k1, k2)为true时,k1.equals(k2)也 应该为true。 介绍完了SortedMap,再来回到我们的NavigableMap上面来。 NavigableMap是JDK1.6新增的,在SortedMap的基础上,增加了一些“导航方法”(navigation methods)来返回与搜索目标最近的元素。例如下面这些方法:
lowerEntry,返回所有比给定Map.Entry小的元素
floorEntry,返回所有比给定Map.Entry小或相等的元素
ceilingEntry,返回所有比给定Map.Entry大或相等的元素
higherEntry,返回所有比给定Map.Entry大的元素
设计理念(design concept)
红黑树(Red–black tree)
TreeMap是用红黑树作为基础实现的,红黑树是一种二叉搜索树,让我们在一起回忆下二叉搜索树的一些性质
二叉搜索树
先看看二叉搜索树(binary search tree,BST)长什么样呢?
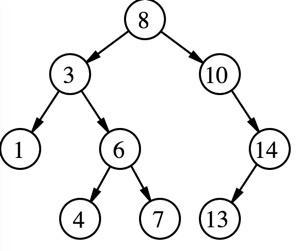
相信大家对这个图都不陌生,关键点是:
左子树的值小于根节点,右子树的值大于根节点。
二叉搜索树的优势在于每进行一次判断就是能将问题的规模减少一半,所以如果二叉搜索树是平衡的话,查找元素的时间复杂度为log(n),也就是树的高度。 我这里想到一个比较严肃的问题,如果说二叉搜索树将问题规模减少了一半,那么三叉搜索树不就将问题规模减少了三分之二,这不是更好嘛,以此类推,我们还可以有四叉搜索树,五叉搜索树……对于更一般的情况:
n个元素,K叉树搜索树的K为多少时效率是***的?K=2时吗?
K 叉搜索树
如果大家按照我上面分析,很可能也陷入一个误区,就是
三叉搜索树在将问题规模减少三分之二时,所需比较操作的次数是两次(二叉搜索树再将问题规模减少一半时,只需要一次比较操作)
我们不能把这两次给忽略了,对于更一般的情况:
n个元素,K叉树搜索树需要的平均比较次数为
k*log(n/k)。
对于极端情况k=n时,K叉树就转化为了线性表了,复杂度也就是O(n)了,如果用数学角度来解这个问题,相当于:
n为固定值时,k取何值时,
k*log(n/k)的取值最小?
k*log(n/k)根据对数的运算规则可以转化为ln(n)*k/ln(k),ln(n)为常数,所以相当于取k/ln(k)的极小值。这个问题对于大一刚学高数的人来说再简单不过了,我们这里直接看结果
当k=e时,
k/ln(k)取最小值。
自然数e的取值大约为2.718左右,可以看到二叉树基本上就是这样***解了。在Nodejs的REPL中进行下面的操作
function foo(k) {return k/Math.log(k);} > foo(2) 2.8853900817779268 > foo(3) 2.730717679880512 > foo(4) 2.8853900817779268 > foo(5) 3.1066746727980594貌似k=3时比k=2时得到的结果还要小,那也就是说三叉搜索树应该比二叉搜索树更好些呀,但是为什么二叉树更流行呢?后来在***的stackoverflow上找到了答案,主旨如下:
现在的CPU可以针对二重逻辑(binary logic)的代码做优化,三重逻辑会被分解为多个二重逻辑。
这样也就大概能理解为什么二叉树这么流行了,就是因为进行一次比较操作,我们最多可以将问题规模减少一半。 好了这里扯的有点远了,我们再回到红黑树上来。
红黑树性质
先看看红黑树的样子:
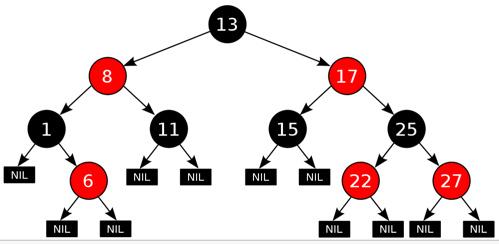
上图是从wiki截来的,需要说明的一点是:
叶子节点为上图中的NIL节点,国内一些教材中没有这个NIL节点,我们在画图时有时也会省略这些NIL节点,但是我们需要明确,当我们说叶子节点时,指的就是这些NIL节点。
红黑树通过下面5条规则,保证了树是平衡的:
树的节点只有红与黑两种颜色
根节点为黑色的
叶子节点为黑色的
红色节点的字节点必定是黑色的
从任意一节点出发,到其后继的叶子节点的路径中,黑色节点的数目相同
满足了上面5个条件后,就能够保证:根节点到叶子节点的最长路径不会大于根节点到叶子最短路径的2倍。 其实这个很好理解,主要是用了性质4与5,这里简单说下:
假设根节点到叶子节点最短的路径中,黑色节点数目为B,那么根据性质5,根节点到叶子节点的最长路径中,黑色节点数目也是B,最长的情况就是每两个黑色节点中间有个红色节点(也就是红黑相间的情况),所以红色节点最多为B-1个。这样就能证明上面的结论了。
红黑树操作
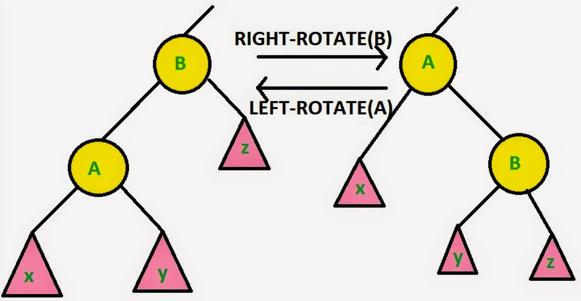
关于红黑树的插入、删除、左旋、右旋这些操作,我觉得***可以做到可视化,文字表达比较繁琐,我这里就不在献丑了,网上能找到的也比较多,像v_July_v的《教你透彻了解红黑树》。我这里推荐个swf教学视频(视频为英文,大家不要害怕,重点是看图??),7分钟左右,大家可以参考。 这里还有个交互式红黑树的可视化网页,大家可以上去自己操作操作,插入几个节点,删除几个节点玩玩,看看左旋右旋是怎么玩的。
源码剖析
由于红黑树的操作我这里不说了,所以这里基本上也就没什么源码可以讲了,因为这里面重要的算法都是From CLR,这里的CLR是指Cormen, Leiserson, Rivest,他们是算法导论的作者,也就是说TreeMap里面算法都是参照算法导论的伪代码。 因为红黑树是平衡的二叉搜索树,所以其put(包含update操作)、get、remove的时间复杂度都为log(n)。
到此,关于“Java TreeMap源码是什么”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



