本篇内容介绍了“C++11中的双重检查锁定是什么意思”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
什么是双重检查锁定?
如果你想在多线程编程中安全使用单件模式(Singleton),最简单的做法是在访问时对其加锁,使用这种方式,假定两个线程同时调用Singleton::getInstance方法,其中之一负责创建单件:
Singleton* Singleton::getInstance() { Lock lock; // scope-based lock, released automatically when the function returns if (m_instance == NULL) { m_instance = new Singleton; } return m_instance; }使用这种方式是可行的,但是当单件被创建之后,实际上你已经不需要再对其进行加锁,加锁虽然不一定导致性能低下,但是在重负载情况下,这也可能导致响应缓慢。
使用双重检查锁定模式避免了在单件对象已经创建好之后进行不必要的锁定,然而实现却有点复杂,在Meyers-Alexandrescu的论文中也 有过阐述,文中提出了几种存在缺陷的实现方式,并逐一解释了为什么这样实现存在问题。在论文的结尾的第12页,给出了一种可靠的实现方式,实现依赖一种标 准中未规范的内存栅栏技术。
Singleton* Singleton::getInstance() { Singleton* tmp = m_instance; ... // insert memory barrier if (tmp == NULL) { Lock lock; tmp = m_instance; if (tmp == NULL) { tmp = new Singleton; ... // insert memory barrier m_instance = tmp; } } return tmp; }这里,我们可以看到:如模式名称一样,代码中实现了双重校验,在m_instance指针为NULL时,我们做了一次锁定,这一过程在***创建该对象的线程可见。在创建线程内部构造块中,m_instance被再一次检查,以确保该线程仅创建了一份对象副本。
这是双重检查锁定的实现,只不过在被高亮的代码行中还缺乏了内存栅栏技术做保证,在此文写就之际,C/C++各编译器未对该实现进行统一,而在C++11标准中,对这种情况下的实现进行了完善和统一。
在C++11中获取和释放内存栅栏
在C++11中,你可以获取和释放内存栅栏来实现上述功能(如何获取和释放内存栅栏在我上一篇博文中有讲述)。为了使你的代码在C++各种实现中具 备更好的可移植性,你应该使用C++11中新增的atomic类型来包装你的m_instance指针,这使得对m_instance的操作是一个原子操作。下面的代码演示了如何使用内存栅栏,请注意代码高亮部分:
std::atomic<Singleton*> Singleton::m_instance; std::mutex Singleton::m_mutex; Singleton* Singleton::getInstance() { Singleton* tmp = m_instance.load(std::memory_order_relaxed); std::atomic_thread_fence(std::memory_order_acquire); // 编注:原作者提示注意的 if (tmp == nullptr) { std::lock_guard<std::mutex> lock(m_mutex); tmp = m_instance.load(std::memory_order_relaxed); if (tmp == nullptr) { tmp = new Singleton; std::atomic_thread_fence(std::memory_order_release); // 编注:作者提示注意的 m_instance.store(tmp, std::memory_order_relaxed); } } return tmp; }上述代码在多核系统中仍然工作正常,这是因为内存栅栏技术在创建对象线程和使用对象线程之间建立了一种“同步-与”的关系(synchronizes-with)。Singleton::m_instance扮演了守卫变量的角色,而单件本身则作为负载内容。
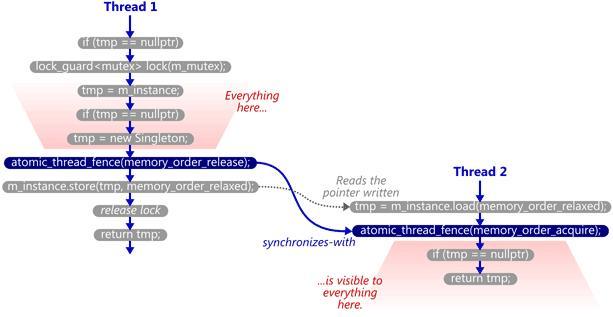
而其他存在缺陷的双重检查锁定实现都缺乏该机制的保障:在没有“同步-与”关系保证的情况下,***个创建线程的写操作,确切地说是在其构造函数中, 可以被其他线程感知,即m_instance指针能被其他线程访问!创建单件线程中的锁也不起作用,由于该锁对其他线程不可见,从而导致在某些情况下,创 建对象被执行多次。
如果你想了解关于内存栅栏技术是如何可靠实现双重检查锁定的内部原理,在我的前一篇文章中有一些背景信息(previous post),之前的博客也有一些相关内容。
使用Mintomic 内存栅栏
Mintomic是一个很小的c库,提供了C++11 atomic库中的一些功能函数子集,包含获取和释放内存栅栏,同时它能工作在早期的编译器之上。Mintomic依赖于与C++11相似的内存模型—— 确切地说是不使用Out-of-thin-air存储——这一技术在早期编译器中未进行实现,而这是在没有C++11标准情况下我们能做的***实现。以我 多年C++多线程开发的经验看来,Out-of-thin-air存储并不流行,而且大多数编译器会避免实现它。
下面的代码演示了如何使用Mintomic的获取和释放内存栅栏机制实现双重检查锁定,基本上与上面的例子类似:
mint_atomicPtr_t Singleton::m_instance = { 0 }; mint_mutex_t Singleton::m_mutex; Singleton* Singleton::getInstance() { Singleton* tmp = (Singleton*) mint_load_ptr_relaxed(&m_instance); mint_thread_fence_acquire(); if (tmp == NULL) { mint_mutex_lock(&m_mutex); tmp = (Singleton*) mint_load_ptr_relaxed(&m_instance); if (tmp == NULL) { tmp = new Singleton; mint_thread_fence_release(); mint_store_ptr_relaxed(&m_instance, tmp); } mint_mutex_unlock(&m_mutex); } return tmp; }为了实现获取和释放内存栅栏,Mintomic会试图在其支持的编译器平台产生***效的机器码。例如,下面的汇编代码来自Xbox 360,使用的是PowerPC处理器。在该平台上,内联的lwsync关键字是针对获取和释放内存栅栏的优化指令。
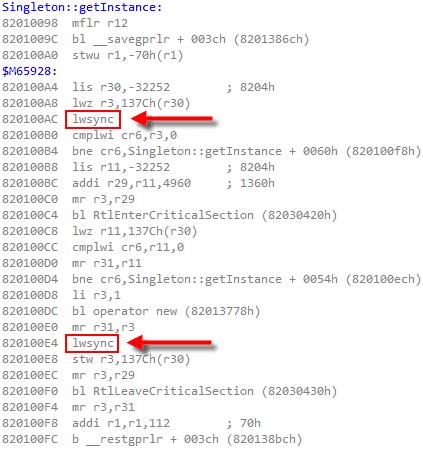
上述采用C++11标准库编译的例子在PowerPC处理器编译应该会产生一样的汇编代码(理想情况下)。不过,我没有能够在PowerPC下编译C++11来验证这一点。
使用C++11低阶指令顺序约束
在C++11中使用内存栅栏锁定技术可以很方便地实现双重检查锁定。同时也保证在现今流行的多核系统中产生优化的机器码(Mintomic也能做到 这一点)。不过使用这种方式并不是常用,在C++11中更好的实现方式是使用保证低阶指令执行顺序约束的原子操作。之前的图片中可以看到,一个写-释放操 作可以与一个获取-读操作同步:
std::atomic<Singleton*> Singleton::m_instance; std::mutex Singleton::m_mutex; Singleton* Singleton::getInstance() { Singleton* tmp = m_instance.load(std::memory_order_acquire); if (tmp == nullptr) { std::lock_guard<std::mutex> lock(m_mutex); tmp = m_instance.load(std::memory_order_relaxed); if (tmp == nullptr) { tmp = new Singleton; m_instance.store(tmp, std::memory_order_release); } } return tmp; }从技术上讲,使用这种形式的无锁同步比独立内存栅栏技术限制更低。上述操作只是为了防止自身操作的内存排序,而内存栅栏技术则阻止了临近操作的内存 排序。尽管如此,现今的x86/64,ARMv6 / v7,和PowerPC处理器架构,针对这两种形式产生的机器码应该是一致的。在我之前的博文中,我展示了C++11低阶指令顺序约束在ARM7中使用了 dmb指令,这和使用内存栅栏技术产生的汇编代码相一致。
上述两种方式在Itanium平台可能产生不一样的机器码,在Itanium平台上,C++11标准中的 load(memory_order_acquire)可以用单CPU指令:ld.acq,而store(tmp, memory_order_release)使用st.rel就可以实现。
在ARMv8处理器架构中,也提供了和Itanium指令等价的ldar 和 stlr 指令,而不同的地方是:这些指令还会导致stlr和后续ldar之间进一级的存储装载指令进行排序。实际上,ARMv8的新指令试图实现C++11标准中 的顺序约束原子操作,这会在后面进一步讲述。
使用C++顺序一致的原子操作
C++11标准提供了一个不同的方式来编写无锁程序(可以把双重检查锁定归类为无锁编程的一种,因为不是所有线程都会获取锁)。在所有原子操作库方 法中使用可选参数std::memory_order可以使得所有原子变量变为顺序的原子操作(sequentially consistent),方法的默认参数为std::memory_order_seq_cst。使用顺序约束(SC)原子操作库,整个函数执行都将保证 顺序执行,并且不会出现数据竞态(data races)。顺序约束(SC)原子操作和JAVA5版本之后出现的volatile变量很相似。
使用SC原子操作实现双重检查锁定的代码如下:和前面的例子一样,高亮的第二行会与***次创建单件的线程进行同步与操作。
std::atomic<Singleton*> Singleton::m_instance; std::mutex Singleton::m_mutex; Singleton* Singleton::getInstance() { Singleton* tmp = m_instance.load(); if (tmp == nullptr) { std::lock_guard<std::mutex> lock(m_mutex); tmp = m_instance.load(); if (tmp == nullptr) { tmp = new Singleton; m_instance.store(tmp); } } return tmp; }顺序约束(SC)原子操作使得开发者更容易预测代码执行结果,不足之处在于使用顺序约束(SC)原子操作类库的代码效率要比之前的例子低一些。例如,在x64位机器上,上述代码使用Clang3.3优化后产生如下汇编代码:
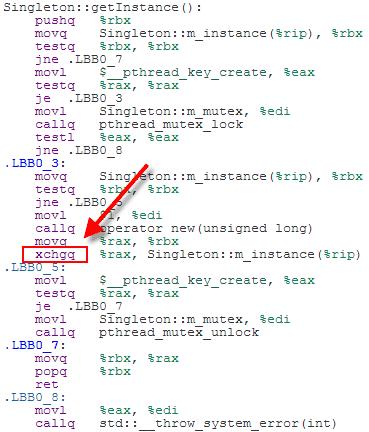
由于使用了顺序约束(SC)原子操作类库,变量m_instance的存储操作使用了xchg指令,在x64处理器上相当于一个内存栅栏操作。该指 令在x64位处理器是一个长周期指令,使用轻量级的mov指令也可以完成操作。不过,这影响不大,因为xchg指令只被单件创建过程调用一次。
不过,在PowerPC or ARMv6/v7处理器上编译上述代码,产生的汇编操作要糟糕得多,具体情形可以参见Herb Sutter的演讲(atomic Weapons talk, part 2.00:44:25 – 00:49:16)。
使用C++11数据顺序依赖原理
上面的例子都是使用了创建单件线程和使用单件其他线程之间的同步与关系。守卫的是数据指针单个元素,开销也是创建单件内容本身。这里,我将演示一种使用数据依赖来保护防卫的指针。
在使用数据依赖时候,上述例子中都使用了一个读-获取操作,这也会产生性能消耗,我们可以使用消费指令来进一步优化。消费指令(consume instruction)非常酷,在PowerPc处理器上它使用了lwsync指令,在ARMv7处理器上则编译为dmd指令。今后我会写一些文章来讲 述消费指令和数据依赖机制。
使用C++11静态初始化
一些读者可能已经知道C++11中,你可以跳过之前的检查过程而直接得到线程安全的单件。你只需要使用一个静态初始化:
C++11标准在6.7.4节中规定:
如果指令逻辑进入一个未被初始化的声明变量,所有并发执行应当等待完成该变量完成初始化。
上述操作在编译时由编译器保证。双重检查锁定则可以利用这一点。编译器并不保证会使用双重检查锁定,但是大部分编译器会这样做。gcc4.6使用-std=c++0x编译选项在ARM处理器产生的汇编代码如下:
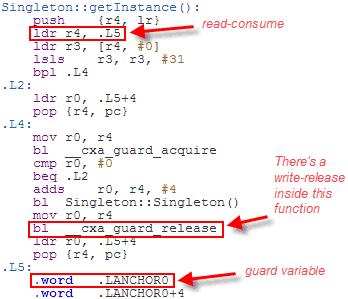
由于单件使用的是一个固定地址,编译器会使用一个特殊的防卫变量来完成同步。请注意这里,在初始化变量读操作时没有使用dmb指令来获取一个内存栅 栏。守卫变量指向了单件,因此编译器可以使用数据依赖原则来避免使用dmb指令的开销。__cxa_guard_release指令扮演了一个写-释放来 解除变量守卫。一旦守卫栅栏被设置,这里存在一个指令顺序强制在读-消费操作之前。这里和前面的例子一样,对内存排序的进行适应性的变更。
“C++11中的双重检查锁定是什么意思”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





