这篇文章主要介绍在Java中如何使用DOM和XPath进行有效的XML处理,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
文档对象模型
DOM 规范被设计成可与任何编程语言一起使用。因此,它尝试使用在所有语言中都可用的一组通用的、核心的功能部件。DOM 规范同样尝试保持其接口定义方面的无关性。这就允许 Java 程序员在使用 Visual Basic 或 Perl 时应用他们的 DOM 知识,反之亦然。
该规范同样将文档的每个部分看成由类型和值组成的节点。这为处理文档的所有方面提供了***的概念性框架。例如,下面的 XML 片段
the Italicized portion. |
就是通过以下的 DOM 结构表示的:
图 1:XML 文档的 DOM 表示
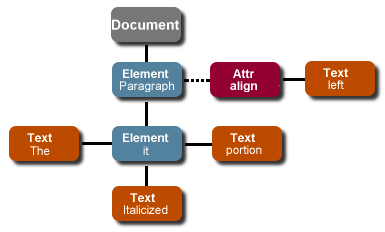
树的每个Document 、 Element 、 Text 和 Attr 部分都是 DOM Node 。
***的抽象确实付出了代价。考虑 XML 片段: Value 。您或许会认为文本的值可以通过普通的 Java String 对象来表示,并且通过简单的 getValue 调用可访问。实际上,文本被当成 tagname 节点下的一个或多个子 Node 。因此,为了获取文本值,您需要遍历 tagname 的子节点,将每个值整理成一个字符串。这样做有充分的理由: tagname 可能包含其它嵌入的 XML 元素,在这种情况下获取其文本值没有多大意义。然而,在现实世界中,我们看到由于缺乏便利的函数导致频繁的编码错误占了 80% 的情况,这样做的确有意义。
设计问题
DOM 语言无关性的缺点是通常在每个编程语言中使用的一整套工作方法和模式不能被使用。例如,不能使用熟悉的 Java new 构造创建新的 Element ,开发者必须使用工厂构造器方法。 Node 的集合被表示成 NodeList ,而不是通常的 List 或 Iterator 对象。这些微小的不便意味着不同寻常的编码实践和增多的代码行,并且它们迫使程序员学习 DOM 的行事方法而不是用直觉的方法。
DOM 使用“一切都是节点”的抽象。这就意味着几乎 XML 文档的每个部分,例如: Document 、 Element 和 Attr ,全都继承( extend ) Node 接口。这不仅是概念上***,而且还允许每个 DOM 的不同实现通过标准接口使其自身的类可见,并且没有通过中间包装类所导致的性能损失。
由于存在的节点类型数量及其访问方法缺乏一致性,“一切都是节点”的抽象丧失了一些意义。例如, insertData 方法被用来设置 CharacterData 节点的值,而通过使用 setValue 方法来设置 Attr (属性)节点的值。由于对于不同的节点存在不同的接口,模型的一致性和***性降低了,而学习曲线增加了。
JDOM
JDOM 是使 DOM API 适应 Java 的研究计划,从而提供了更自然和易用的接口。由于认识到语言无关 DOM 构造的棘手本质,JDOM 目标在于使用内嵌的 Java 表示和对象,并且为常用任务提供便利的函数。
例如,JDOM 直接处理“一切都是节点”和 DOM 特定构造的使用(如 NodeList )。JDOM 将不同的节点类型(如 Document 、 Element 和 Attribute )定义为不同的 Java 类,这意味着开发者可以使用 new 构造它们,避免频繁类型转换的需要。JDOM 将字符串表示成 Java String ,并且通过普通的 List 和 Iterator 类来表示节点的集合。(JDOM 用其本身类替代 DOM 类。)
JDOM 为提供更完善的接口做了相当有益的工作。它已经被接受成为 JSR(正式的 Java Specification Request),而且它将来很可能会被包含到核心的 Java 平台中。但是,因其还不是核心 Java API 的一部分,一些人对于使用它还心存犹豫。这儿还有关于与 Iterator 和 Java 对象频繁创建相关的性能问题的报告。(请参阅 参考资料)。
如果您对 JDOM 的接受性和可用性已经满足,并且如果您也没有将 Java 代码和程序员转移到其它语言的直接需求,JDOM 是个值得探索的好选择。JDOM 还不能满足本文探讨的项目所在的公司需要,因而他们使用了非常普遍的 DOM。本文也是这样做的。
常见编码问题
几个大型 XML 项目分析揭示了使用 DOM 中的一些常见问题。下面对其中的几个进行介绍。
代码臃肿
在我们研究中查看的所有项目,本身都出现一个突出的问题:花费许多行代码行来做简单的事情。在某个示例中,使用 16 行代码检查一个属性的值。而同样的任务,带有改进的健壮性和出错处理,可以使用 3 行代码实现。DOM API 的低级本质、方法和编程模式的不正确应用以及缺乏完整 API 的知识,都会致使代码行数增加。下面的摘要介绍了关于这些问题的特定实例。
遍历 DOM
在我们探讨的代码中,最常见的任务是遍历或搜索 DOM。 清单 1 演示了需要在文档的 config 节里查找一个称为“header”节点的浓缩版本代码:
清单 1 中,从根开始通过检索顶端元素遍历文档,获取其***个子节点( configNode ),并且最终单独检查 configNode 的子节点。不幸的是,这种方法不仅冗长,而且还伴随着脆弱性和潜在的错误。
例如,第二行代码通过使用 getFirstChild 方法获取中间的 config 节点。已经存在许多潜在的问题。根节点的***个子节点实际上可能并不是用户正在搜索的节点。由于盲目地跟随***个子节点,我忽视了标记的实际名称并且可能搜索不正确的文档部分。当源 XML 文档的根节点后包含空格或回车时,这种情况中发生一个频繁的错误;根节点的***个子节点实际是 Node.TEXT_NODE 节点,而不是所希望的元素节点。您可以自己试验一下,从 参考资料下载样本代码并且编辑 sample.xml 文件 ― 在 sample 和 config 标记之间放置一个回车。代码立即异常而终止。要正确浏览所希望的节点,需要检查每个 root 的子节点,直到找到非 Text 的节点,并且那个节点有我正在查找的名称为止。
清单 1 还忽视了文档结构可能与我们期望有所不同的可能性。例如,如果 root 没有任何子节点, configNode 将会被设置为 null ,并且示例的第三行将产生一个错误。因此,要正确浏览文档,不仅要单独检查每个子节点以及核对相应的名称,而且每步都得检查以确保每个方法调用返回的是一个有效值。编写能够处理任意输入的健壮、无错的代码,不仅需要非常关注细节,而且需要编写很多行代码。
最终,如果最初的开发者了解它的话,清单 1 中示例的所有功能应该可以通过利用对 getElementsByTagName 函数的简单调用实现。这是下面要讨论的。
检索元素中的文本值
在所分析的项目中,DOM 遍历以后,第二项最常进行的任务是检索在元素中包含的文本值。考虑 XML 片段 The Value 。如果已经导航到 sometag 节点,如何获取其文本值( The Value )呢?一个直观的实现可能是:
sometagElement.getData(); |
正如您所猜测到的,上面的代码并不会执行我们希望的动作。由于实际的文本被存储为一个或多个子节点,因此不能对 sometag 元素调用 getData 或类似的函数。更好的方法可能是:
sometag.getFirstChild().getData(); |
第二种尝试的问题在于值实际上可能并不包含在***个子节点中;在 sometag 内可能会发现处理指令或其它嵌入的节点,或是文本值包含在几个子节点而不是单单一个子节点中。考虑到空格经常作为文本节点表示,因此对 sometag.getFirstChild() 的调用可能仅让您得到标记和值之间的回车。实际上,您需要遍历所有子节点,以核对 Node.TEXT_NODE 类型的节点,并且整理它们的值直到有完整的值为止。
注意,JDOM 已经利用便利的函数 getText 为我们解决了这个问题。DOM 级别 3 也将有一个使用规划的 getTextContent 方法的解答。教训:尽可能使用较高级的 API 是不会错的。
getElementsByTagName
DOM 级别 2 接口包含一个查找给定名称的子节点的方法。例如,调用:
NodeList names = someElement.getElementsByTagName("name"); |
将返回一个包含在 someElement 节点中称为 names 的节点 NodeList 。这无疑比我所讨论的遍历方法更方便。这也是一组常见错误的原因。
问题在于 getElementsByTagName 递归地遍历文档,从而返回所有匹配的节点。假定您有一个包含客户信息、公司信息和产品信息的文档。所有这三个项中都可能含有 name 标记。如果调用 getElementsByTagName 搜索客户名称,您的程序极有可能行为失常,除了检索出客户名称,还会检索出产品和公司名称。在文档的子树上调用该函数可能会降低风险,但由于 XML 的灵活本质,使确保您所操作的子树包含您期望的结构,且没有您正在搜索的名称的虚假子节点就变得十分困难。
DOM 的有效使用
考虑到由 DOM 设计强加的限制,如何才能有效和高效的使用该规范呢?下面是使用 DOM 的几条基本原则和方针,以及使工作更方便的函数库。
基本原则
如果您遵循几条基本原则,您使用 DOM 的经验将会显著提高:
◆ 不要使用 DOM 遍历文档。
◆ 尽可能使用 XPath 来查找节点或遍历文档。
◆ 使用较高级的函数库来更方便地使用 DOM。
这些原则直接从对常见问题的研究中得到。正如上面所讨论的,DOM 遍历是出错的主要原因。但它也是最常需要的功能之一。如何通过不使用 DOM 而遍历文档呢?
Path
XPath 是寻址、搜索和匹配文档的各个部分的语言。它是 W3C 推荐标准(Recommendation),并且在大多数语言和 XML 包中实现。您的 DOM 包可能直接支持 XPath 或通过加载件(add-on)支持。本文的样本代码对于 XPath 支持使用 Xalan 包。
XPath 使用路径标记法来指定和匹配文档的各个部分,该标记法与文件系统和 URL 中使用的类似。例如,XPath: /x/y/z 搜索文档的根节点 x ,其下存在节点 y ,其下存在节点 z 。该语句返回与指定路径结构匹配的所有节点。
更为复杂的匹配可能同时在包含文档的结构方面以及在节点及其属性的值中。语句 /x/y/* 返回父节点为 x 的 y 节点下的任何节点。 /x/y[@name='a'] 匹配所有父节点为 x 的 y 节点,其属性称为 name ,属性值为 a 。请注意,XPath 处理筛选空格文本节点以获得实际的元素节点 ― 它只返回元素节点。
详细探讨 XPath 及其用法超出了本文的范围。请参阅 参考资料获得一些优秀教程的链接。花点时间学习 XPath,您将会更方便的处理 XML 文档。
函数库
当研究 DOM 项目时令我们惊奇的一个发现,是存在的拷贝和粘贴代码的数量。为什么有经验的开发者没有使用良好的编程习惯,却使用拷贝和粘贴方法而不是创建助手(helper)库呢?我们相信这是由于 DOM 的复杂性加深了学习的难度,并使开发者要理解能完成他们所需要的***段代码。开发产生构成助手库规范的函数所需的专门技术需要花费大量的时间。
要节省一些走弯路的时间,这里是一些将使您自己的库可以运转起来的基本助手函数。
findValue
使用 XML 文档时,最常执行的操作是查找给定节点的值。正如上所讨论的,在遍历文档以查找期望的值和检索节点的值中都出现难度。可以通过使用 XPath 来简化遍历,而值的检索可以一次编码然后重用。在两个较低级函数的帮助下,我们实现了 getValue 函数,这两个低级函数是:由 Xalan 包提供的 XPathAPI.selectSingleNode (用来查找和返回与给定的 XPath 表达式匹配的***个节点);以及 getTextContents ,它非递归地返回包含在节点中的连续文本值。请注意,JDOM 的 getText 函数,或将出现在 DOM 级别 3 中规划的 getTextContent 方法,都可用来代替 getTextContents 。 清单 2包含了一个简化的清单;您可以通过下载样本代码来访问所有函数(请参阅 参考资料)。
通过同时传入要开始搜索的节点和指定要搜索节点的 XPath 语句来调用 findValue 。函数查找***个与给定 XPath 匹配的节点,并且抽取其文本值。
setValue
另一项常用的操作是将节点的值设置为希望的值,如 清单 3 所示。该函数获取一个起始节点和一条 XPath 语句 ― 就象 findValue ― 以及一个用来设置匹配的节点值的字符串。它查找希望的节点,除去其所有子节点(因此除去包含在其中的任何文本和其它元素),并将其文本内容设置为传入的(passed-in)字符串。
appendNode
虽然某些程序查找和修改包含在 XML 文档中的值,而另一些则通过添加和除去节点来修改文档本身的结构。这个助手函数简化了文档节点的添加,如 清单 4所示。
该函数的参数有:要将新节点添加到其下的节点,要添加的新节点名称,以及指定要将节点添加到其下位置的 XPath 语句(也就是,新节点的父节点应当是哪个)。新节点被添加到文档的指定位置。
以上是“在Java中如何使用DOM和XPath进行有效的XML处理”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





