pytorchдёҺtensorflowжңүе“ӘдәӣеҢәеҲ«
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңpytorchдёҺtensorflowжңүе“ӘдәӣеҢәеҲ«вҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁpytorchдёҺtensorflowжңүе“ӘдәӣеҢәеҲ«й—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқpytorchдёҺtensorflowжңүе“ӘдәӣеҢәеҲ«вҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ

> Source: Author
ж•°жҚ®з§‘еӯҰз•ҢжҳҜдёҖз§Қе……ж»Ўжҙ»еҠӣе’ҢеҗҲдҪңзҡ„з©әй—ҙгҖӮжҲ‘们д»ҺеҪјжӯӨзҡ„еҮәзүҲзү©дёӯеӯҰеҲ°пјҢиҫ©и®әе…ідәҺи®әеқӣе’ҢеңЁзәҝзҪ‘зӮ№зҡ„жғіжі•пјҢ并еҲҶдә«и®ёеӨҡд»Јз Ғ(е’Ңи®ёеӨҡ)д»Јз ҒгҖӮиҝҷз§ҚеҗҲдҪңзІҫзҘһзҡ„иҮӘ然еүҜдҪңз”ЁжҳҜйҒҮеҲ°еҗҢдәӢдҪҝз”Ёзҡ„дёҚзҶҹжӮүе·Ҙе…·зҡ„й«ҳеҸҜиғҪжҖ§гҖӮеӣ дёәжҲ‘们дёҚеңЁзңҹз©әдёӯе·ҘдҪңпјҢжүҖд»ҘеңЁз»ҷе®ҡзҡ„дё»йўҳйўҶеҹҹдёӯиҺ·еҫ—зҶҹжӮүеӨҡз§ҚиҜӯиЁҖе’Ңеӣҫд№ҰйҰҶзҡ„зҶҹжӮүзЁӢеәҰеҫҖеҫҖжҳҜжңүж„Ҹд№үзҡ„пјҢд»ҘдҫҝеҗҲдҪңе’ҢеӯҰд№ жңҖжңүж•ҲгҖӮ
иҝҷ并дёҚеҘҮжҖӘпјҢйӮЈд№ҲпјҢи®ёеӨҡж•°жҚ®з§‘еӯҰ家е’ҢжңәеҷЁеӯҰд№ е·ҘзЁӢеёҲеңЁе…¶е·Ҙе…·з®ұдёӯжңүдёӨдёӘжөҒиЎҢзҡ„жңәеҷЁеӯҰд№ жЎҶжһ¶пјҡTensorflowе’ҢPytorchгҖӮиҝҷдәӣжЎҶжһ¶ - еңЁPythonдёӯ - еҲҶдә«и®ёеӨҡзӣёдјјд№ӢеӨ„пјҢд№ҹд»Ҙжңүж„Ҹд№үзҡ„ж–№ејҸеҲҶжӯ§гҖӮиҝҷдәӣе·®ејӮпјҢдҫӢеҰӮе®ғ们еҰӮдҪ•еӨ„зҗҶAPIпјҢеҠ иҪҪж•°жҚ®е’Ңж”ҜжҢҒдё“дёҡеҹҹпјҢеҸҜд»ҘеңЁдёӨдёӘжЎҶжһ¶з№Ғзҗҗдё”ж•ҲзҺҮдҪҺдёӢд№Ӣй—ҙдәӨжӣҝгҖӮиҝҷжҳҜдёҖдёӘй—®йўҳпјҢз»ҷеҮәдәҶиҝҷдёӨдёӘе·Ҙе…·зҡ„еёёи§ҒгҖӮ
еӣ жӯӨпјҢжң¬ж–Үж—ЁеңЁйҖҡиҝҮдё“жіЁдәҺеҲӣе»әе’Ңи®ӯз»ғдёӨдёӘз®ҖеҚ•жЁЎеһӢзҡ„еҹәзЎҖзҹҘиҜҶжқҘиҜҙжҳҺPytorchе’ҢTensorflowд№Ӣй—ҙзҡ„е·®ејӮгҖӮзү№еҲ«жҳҜпјҢжҲ‘们е°Ҷд»Ӣз»ҚеҰӮдҪ•дҪҝз”ЁжқҘиҮӘPytorch 1.xзҡ„жЁЎеқ—APIе’ҢжқҘиҮӘTensorflow 2.xзҡ„жЁЎеқ—APIдҪҝз”ЁеҠЁжҖҒеӯҗзұ»жЁЎеһӢгҖӮжҲ‘们е°ҶжҹҘзңӢиҝҷдәӣжЎҶжһ¶зҡ„иҮӘеҠЁе·®ејӮеҰӮдҪ•пјҢд»ҘжҸҗдҫӣйқһеёёжңҙзҙ зҡ„жўҜеәҰдёӢйҷҚзҡ„е®һзҺ°гҖӮ
дҪҶйҰ–е…ҲпјҢж•°жҚ®
еӣ дёәжҲ‘们专注дәҺиҮӘеҠЁе·®еҲҶ/иҮӘеҠЁжұӮеҜјеҠҹиғҪзҡ„ж ёеҝғ(дҪңдёәдёҖз§Қиҝӣдҝ®пјҢжҳҜеҸҜд»ҘиҮӘеҠЁжҸҗеҸ–еҮҪж•°зҡ„еҜјж•°зҡ„е®№йҮҸ并еңЁдёҖдәӣеҸӮж•°дёҠеә”з”ЁжўҜеәҰпјҢд»ҘдҫҝдҪҝз”ЁиҝҷдәӣеҸӮж•°жўҜеәҰдёӢйҷҚ)жҲ‘们еҸҜд»Ҙд»ҺжңҖз®ҖеҚ•зҡ„жЁЎеһӢејҖе§ӢпјҢжҳҜзәҝжҖ§еӣһеҪ’гҖӮжҲ‘们еҸҜд»ҘдҪҝз”ЁNumpyеә“дҪҝз”ЁдёҖзӮ№йҡҸжңәеҷӘеЈ°з”ҹжҲҗдёҖдәӣзәҝжҖ§ж•°жҚ®пјҢ然еҗҺеңЁиҜҘиҷҡжӢҹж•°жҚ®йӣҶдёҠиҝҗиЎҢжҲ‘们зҡ„жЁЎеһӢгҖӮ
def generate_data(m=0.1, b=0.3, n=200): x = np.random.uniform(-10, 10, n) noise = np.random.normal(0, 0.15, n) y = (m * x + b ) + noise return x.astype(np.float32), y.astype(np.float32) x, y = generate_data() plt.figure(figsize = (12,5)) ax = plt.subplot(111) ax.scatter(x,y, c = "b", label="samples")
жЁЎеһӢ
дёҖж—ҰжҲ‘们жӢҘжңүж•°жҚ®пјҢжҲ‘们е°ұеҸҜд»Ҙд»ҺTensorflowе’ҢPytorchдёӯзҡ„еҺҹе§Ӣд»Јз Ғе®һзҺ°еӣһеҪ’жЁЎеһӢгҖӮдёәз®ҖеҚ•иө·и§ҒпјҢжҲ‘们дёҚдјҡжңҖеҲқдҪҝз”Ёд»»дҪ•еұӮжҲ–жҝҖжҙ»еҷЁпјҢд»…е®ҡд№үдёӨдёӘеј йҮҸпјҢWе’ҢBпјҢиЎЁзӨәзәҝжҖ§жЁЎеһӢY = Wx + Bзҡ„жқғйҮҚе’ҢеҒҸзҪ®гҖӮ
жӯЈеҰӮжӮЁжүҖзңӢеҲ°зҡ„пјҢйҷӨдәҶAPIеҗҚз§°зҡ„еҮ дёӘе·®ејӮд№ӢеӨ–пјҢдёӨдёӘжЁЎеһӢзҡ„зұ»е®ҡд№үеҮ д№ҺзӣёеҗҢгҖӮжңҖйҮҚиҰҒзҡ„еҢәеҲ«еңЁдәҺпјҢPytorchйңҖиҰҒдёҖдёӘжҳҺзЎ®зҡ„еҸӮж•°еҜ№иұЎжқҘе®ҡд№үз”ұеӣҫжҚ•иҺ·зҡ„жқғйҮҚе’ҢеҒҸзҪ®еј йҮҸпјҢиҖҢTensoRFlowиғҪеӨҹиҮӘеҠЁжҚ•иҺ·зӣёеҗҢзҡ„еҸӮж•°гҖӮе®һйҷ…дёҠпјҢPytorchеҸӮж•°жҳҜдёҺжЁЎеқ—APIдёҖиө·дҪҝз”Ёж—¶е…·жңүзү№ж®ҠеұһжҖ§зҡ„Tensorеӯҗзұ»пјҡе®ғ们дјҡиҮӘеҠЁеҗ‘жЁЎеқ—еҸӮж•°еҲ—иЎЁж·»еҠ SELFпјҢеӣ жӯӨSECRESеңЁеҸӮж•°()иҝӯд»ЈеҷЁдёӯеҮәзҺ°гҖӮ
иҝҷдёӨдёӘжЎҶжһ¶йғҪжҸҗеҸ–дәҶд»ҺжӯӨзұ»е®ҡд№үе’Ңжү§иЎҢж–№жі•з”ҹжҲҗеӣҫжүҖйңҖзҡ„дёҖеҲҮ(__call__жҲ–иҪ¬еҸ‘)пјҢ并且еҰӮдёӢпјҢеҰӮдёӢжүҖзӨәпјҢи®Ўз®—е®һзҺ°bospropagationжүҖйңҖзҡ„жёҗеҸҳгҖӮ
TensorflowеҠЁжҖҒжЁЎеһӢ
class LinearRegressionKeras(tf.keras.Model): def __init__(self): super().__init__() self.w = tf.Variable(tf.random.uniform(shape=[1], -0.1, 0.1)) self.b = tf.Variable(tf.random.uniform(shape=[1], -0.1, 0.1)) def __call__(self,x): return x * self.w + self.b
PytorchеҠЁжҖҒжЁЎеһӢ
class LinearRegressionPyTorch(torch.nn.Module): def __init__(self): super().__init__() self.w = torch.nn.Parameter(torch.Tensor(1, 1).uniform_(-0.1, 0.1)) self.b = torch.nn.Parameter(torch.Tensor(1).uniform_(-0.1, 0.1)) def forward(self, x): return x @ self.w + self.b
жһ„е»әи®ӯз»ғеҫӘзҺҜпјҢbackpropagationе’ҢдјҳеҢ–еҷЁ
дҪҝз”Ёиҝҷдәӣз®ҖеҚ•зҡ„Tensorflowе’ҢBytorchжЁЎеһӢе»әз«ӢпјҢдёӢдёҖжӯҘжҳҜе®һзҺ°жҚҹеӨұеҮҪж•°пјҢеңЁиҝҷз§Қжғ…еҶөдёӢеҸӘжҳҜж„Ҹе‘ізқҖе№іж–№й”ҷиҜҜгҖӮ然еҗҺпјҢжҲ‘们еҸҜд»Ҙе®һдҫӢеҢ–жЁЎеһӢзұ»е№¶иҝҗиЎҢи®ӯз»ғеҫӘзҺҜд»Ҙе®һзҺ°еҮ дёӘе‘ЁжңҹгҖӮ
еҗҢж ·пјҢз”ұдәҺжҲ‘们专注дәҺж ёеҝғиҮӘеҠЁе·®еҲҶ/иҮӘеҠЁжұӮеҜјеҠҹиғҪпјҢиҝҷйҮҢзҡ„зӣ®зҡ„жҳҜдҪҝз”ЁTensorFlowе’Ңзү№е®ҡдәҺPytorchзү№е®ҡзҡ„иҮӘеҠЁDiffе®һзҺ°жһ„е»әиҮӘе®ҡд№үи®ӯз»ғеҫӘзҺҜгҖӮиҝҷдәӣе®һж–Ҫж–№ејҸи®Ўз®—з®ҖеҚ•зҡ„зәҝжҖ§еҮҪж•°зҡ„жўҜеәҰпјҢ并用еӨ©зңҹжўҜеәҰдёӢйҷҚдјҳеҢ–еҷЁжүӢеҠЁдјҳеҢ–жқғйҮҚе’ҢеҒҸзҪ®еҸӮж•°пјҢеҹәжң¬дёҠжңҖе°ҸеҢ–дәҶеңЁжҜҸдёӘзӮ№еӨ„дҪҝз”ЁеҸҜеҫ®е·®еҮҪж•°д№Ӣй—ҙи®Ўз®—зҡ„е®һйҷ…зӮ№е’Ңйў„жөӢд№Ӣй—ҙи®Ўз®—зҡ„жҚҹеӨұгҖӮ
еҜ№дәҺTensorFlowи®ӯз»ғеҫӘзҺҜпјҢжҲ‘жҳҺзЎ®ең°дҪҝз”ЁGradientTape APIжқҘи·ҹиёӘжЁЎеһӢзҡ„еүҚеҗ‘жү§иЎҢе’ҢйҖҗжӯҘжҚҹиҖ—и®Ўз®—гҖӮжҲ‘дҪҝз”ЁGradientTapeзҡ„жёҗеҸҳжқҘдјҳеҢ–жқғйҮҚе’ҢеҒҸзҪ®еҸӮж•°гҖӮPytorchжҸҗдҫӣдәҶдёҖз§ҚжӣҙвҖңзҘһеҘҮзҡ„вҖқиҮӘеҠЁжұӮеҜјж–№жі•пјҢйҡҗејҸең°жҚ•иҺ·еҸӮж•°еј йҮҸзҡ„д»»дҪ•ж“ҚдҪңпјҢ并жҸҗдҫӣз”ЁдәҺдјҳеҢ–жқғйҮҚе’ҢеҒҸзҪ®еҸӮж•°зҡ„жўҜеәҰпјҢиҖҢж— йңҖи°ғз”ЁеҸҰдёҖAPIгҖӮдёҖж—ҰжҲ‘е…·жңүжқғйҮҚе’ҢеҒҸзҪ®жўҜеәҰпјҢеңЁPytorchе’ҢTensorflowдёҠе®һзҺ°иҮӘе®ҡд№үжўҜеәҰдёӢйҷҚж–№жі•е°ұеғҸд»ҺиҝҷдәӣжўҜеәҰдёӯеҮҸеҺ»жқғйҮҚе’ҢеҒҸзҪ®еҸӮж•°дёҖж ·з®ҖеҚ•пјҢд№ҳд»ҘжҒ’е®ҡзҡ„еӯҰд№ йҖҹзҺҮгҖӮ
иҜ·жіЁж„ҸпјҢз”ұдәҺPytorchиҮӘеҠЁе®һзҺ°иҮӘеҠЁе·®еҲҶ/иҮӘеҠЁжұӮеҜјпјҢеӣ жӯӨеңЁи®Ўз®—еҗҺеҗ‘дј ж’ӯд№ӢеҗҺпјҢжңүеҝ…иҰҒжҳҺзЎ®и°ғз”Ёno_grad apiгҖӮиҝҷжҢҮзӨәPytorchдёҚи®Ўз®—жқғйҮҚе’ҢеҒҸзҪ®еҸӮж•°зҡ„жӣҙж–°ж“ҚдҪңзҡ„жўҜеәҰгҖӮжҲ‘们иҝҳйңҖиҰҒжҳҺзЎ®йҮҠж”ҫеңЁеүҚеҗ‘ж“ҚдҪңдёӯи®Ўз®—зҡ„е…ҲеүҚиҮӘеҠЁи®Ўз®—зҡ„жёҗеҸҳпјҢд»Ҙйҳ»жӯўPytorchиҮӘеҠЁзҙҜз§Ҝиҫғжү№ж¬Ўе’ҢеҫӘзҺҜиҝӯд»Јдёӯзҡ„жёҗеҸҳгҖӮ
Tensorflowи®ӯз»ғеҫӘзҺҜ
def squared_error(y_pred, y_true): return tf.reduce_mean(tf.square(y_pred - y_true)) tf_model = LinearRegressionKeras() [w, b] = tf_model.trainable_variables for epoch in range(epochs): with tf.GradientTape() as tape: predictions = tf_model(x) loss = squared_error(predictions, y) w_grad, b_grad = tape.gradient(loss, tf_model.trainable_variables) w.assign(w - w_grad * learning_rate) b.assign(b - b_grad * learning_rate) if epoch % 20 == 0: print(f"Epoch {epoch} : Loss {loss.numpy()}")Pytorchи®ӯз»ғеҫӘзҺҜ
def squared_error(y_pred, y_true): return torch.mean(torch.square(y_pred - y_true)) torch_model = LinearRegressionPyTorch() [w, b] = torch_model.parameters() for epoch in range(epochs): y_pred = torch_model(inputs) loss = squared_error(y_pred, labels) loss.backward() with torch.no_grad(): w -= w.grad * learning_rate b -= b.grad * learning_rate w.grad.zero_() b.grad.zero_() if epoch % 20 == 0: print(f"Epoch {epoch} : Loss {loss.data}")Pytorchе’ҢTensorflowжЁЎеһӢйҮҚз”ЁеҸҜз”ЁеұӮ
既然жҲ‘еұ•зӨәдәҶеҰӮдҪ•д»ҺPytorchе’ҢTensorflowдёӯзҡ„еҺҹе§Ӣд»Јз Ғе®һзҺ°зәҝжҖ§еӣһеҪ’жЁЎеһӢпјҢжҲ‘们еҸҜд»ҘжҹҘзңӢеҰӮдҪ•дҪҝз”ЁеҜҶйӣҶе’ҢзәҝжҖ§еұӮпјҢд»ҺTensorFlowе’ҢPytorchеә“дёӯйҮҚж–°е®һзҺ°зӣёеҗҢзҡ„еһӢеҸ·гҖӮ
еёҰзҺ°жңүеӣҫеұӮзҡ„TensoRFlowе’ҢPytorchеҠЁжҖҒжЁЎеһӢ
жӮЁе°ҶеңЁжЁЎеһӢеҲқе§ӢеҢ–ж–№жі•дёӯжіЁж„ҸеҲ°пјҢжҲ‘们жӯЈеңЁз”ЁTensorFlowдёӯзҡ„еҜҶйӣҶеұӮжӣҝжҚўWе’ҢBеҸӮж•°зҡ„жҳҫејҸеЈ°жҳҺе’ҢPytorchдёӯзҡ„зәҝжҖ§еұӮгҖӮиҝҷдёӨдёӘеұӮйғҪе®һзҺ°дәҶзәҝжҖ§еӣһеҪ’пјҢ并且жҲ‘们е°ҶжҢҮзӨәе®ғ们дҪҝз”ЁеҚ•дёӘжқғйҮҚе’ҢеҒҸзҪ®еҸӮж•°жқҘд»Јжӣҝд»ҘеүҚдҪҝз”Ёзҡ„жҳҫејҸWе’ҢBеҸӮж•°гҖӮеҜҶйӣҶе’ҢзәҝжҖ§е®һзҺ°е°ҶеңЁеҶ…йғЁдҪҝз”ЁжҲ‘们д№ӢеүҚдҪҝз”Ёзҡ„зӣёеҗҢзҡ„еј и§ЈеЈ°жҳҺ(еҲҶеҲ«дёәtf.variableе’Ңnn.parameter)жқҘеҲҶй…Қиҝҷдәӣеј йҮҸ并е°Ҷе®ғ们дёҺжЁЎеһӢеҸӮж•°еҲ—иЎЁзӣёе…іиҒ”гҖӮ
жҲ‘们иҝҳе°Ҷжӣҙж–°иҝҷдәӣж–°жЁЎеһӢзұ»зҡ„е‘јеҸ«/еүҚиҝӣж–№жі•пјҢд»ҘжӣҝжҚўе…·жңүеҜҶеәҰ/зәҝжҖ§еұӮзҡ„жүӢеҠЁзәҝжҖ§еӣһеҪ’и®Ўз®—гҖӮ
class LinearRegressionKeras(tf.keras.Model): def __init__(self): super().__init__() self.linear = tf.keras.layers.Dense(1, activation=None) # , input_shape=[1] def call(self, x): return self.linear(x)
class LinearRegressionPyTorch(torch.nn.Module): def __init__(self): super(LinearRegressionPyTorch, self).__init__() self.linear = torch.nn.Linear(1, 1) def forward(self, x): return self.linear(x)
е…·жңүеҸҜз”ЁдјҳеҢ–еҷЁе’ҢжҚҹиҖ—еҮҪж•°зҡ„и®ӯз»ғ
既然жҲ‘们已з»ҸдҪҝз”ЁзҺ°жңүеӣҫеұӮйҮҚж–°е®һзҺ°дәҶжҲ‘们зҡ„Tensorflowе’ҢPytorchеһӢеҸ·пјҢжҲ‘们еҸҜд»Ҙдё“жіЁдәҺеҰӮдҪ•жһ„е»әжӣҙдјҳеҢ–зҡ„и®ӯз»ғеҫӘзҺҜгҖӮжҲ‘们дёҚжҳҜдҪҝз”ЁжҲ‘们д»ҘеүҚзҡ„Naïveе®һзҺ°пјҢжҲ‘们е°ҶдҪҝз”Ёиҝҷдәӣеә“еҸҜз”Ёзҡ„жң¬жңәдјҳеҢ–еҷЁе’ҢжҚҹеӨұеҮҪж•°гҖӮ
жҲ‘们е°Ҷ继з»ӯдҪҝз”Ёд№ӢеүҚи§ӮеҜҹеҲ°зҡ„иҮӘеҠЁе·®еҲҶ/иҮӘеҠЁжұӮеҜјеҠҹиғҪпјҢдҪҶжӯӨж—¶е…·жңүж ҮеҮҶжёҗеҸҳдёӢйҷҚ(SGD)дјҳеҢ–е®һзҺ°д»ҘеҸҠж ҮеҮҶжҚҹиҖ—еҠҹиғҪгҖӮ
Tensorflowи®ӯз»ғеҫӘзҺҜпјҢжҳ“дәҺжӢҹеҗҲж–№жі•
еңЁTensorflowдёӯпјҢFIT()жҳҜдёҖз§ҚйқһеёёејәеӨ§пјҢй«ҳзә§еҲ«зҡ„и®ӯз»ғжЁЎеһӢж–№жі•гҖӮе®ғе…Ғи®ёжҲ‘们用еҚ•дёӘж–№жі•жӣҝжҚўжүӢеҠЁи®ӯз»ғеҫӘзҺҜпјҢиҜҘж–№жі•жҢҮе®ҡи¶…зә§и°ғж•ҙеҸӮж•°гҖӮеңЁи°ғз”Ёfit()д№ӢеүҚпјҢжҲ‘们е°ҶдҪҝз”ЁCompile()ж–№жі•зј–иҜ‘жЁЎеһӢзұ»пјҢ然еҗҺйҖҡиҝҮжўҜеәҰеҗҺд»ЈдјҳеҢ–еҷЁе’Ңз”ЁдәҺи®ӯз»ғзҡ„жҚҹеӨұеҮҪж•°гҖӮ
жӮЁдјҡжіЁж„ҸеҲ°еңЁиҝҷз§Қжғ…еҶөдёӢпјҢжҲ‘们е°Ҷе°ҪеҸҜиғҪеӨҡең°йҮҚз”ЁжқҘиҮӘTensorFlowеә“зҡ„ж–№жі•гҖӮзү№еҲ«жҳҜпјҢжҲ‘们е°ҶйҖҡиҝҮж ҮеҮҶйҡҸжңәжўҜеәҰдёӢйҷҚ(SGD)дјҳеҢ–еҷЁе’Ңж ҮеҮҶзҡ„е№іеқҮз»қеҜ№иҜҜе·®еҮҪж•°е®һзҺ°(MEAL_ABSOLUTE_ERROR)еҲ°зј–иҜ‘ж–№жі•гҖӮдёҖж—ҰжЁЎеһӢиҝӣиЎҢзј–иҜ‘пјҢжҲ‘们жңҖз»ҲеҸҜд»ҘжӢЁжү“жӢҹеҗҲж–№жі•жқҘе®Ңе…Ёи®ӯз»ғжҲ‘们зҡ„жЁЎеһӢгҖӮжҲ‘们е°ҶйҖҡиҝҮж•°жҚ®(xе’Ңy)пјҢepochsзҡ„ж•°йҮҸд»ҘеҸҠжҜҸдёӘж—¶д»ЈдҪҝз”Ёзҡ„жү№йҮҸеӨ§е°ҸгҖӮ
еёҰжңүиҮӘе®ҡд№үеҫӘзҺҜе’ҢSGDдјҳеҢ–еҷЁзҡ„TensoRFLOFи®ӯз»ғеҫӘзҺҜ
еңЁд»ҘдёӢд»Јз Ғж®өдёӯпјҢжҲ‘们е°ҶдёәжҲ‘们зҡ„жЁЎеһӢе®һж–ҪеҸҰдёҖдёӘиҮӘе®ҡд№үи®ӯз»ғеҫӘзҺҜпјҢиҝҷж¬Ўе°ҪеҸҜиғҪеӨҡең°йҮҚз”Ёз”ұTensorflowеә“жҸҗдҫӣзҡ„жҚҹеӨұеҮҪж•°е’ҢдјҳеҢ–еҷЁгҖӮжӮЁдјҡжіЁж„ҸеҲ°жҲ‘们зҡ„еүҚиҮӘе®ҡд№үPythonжҚҹеӨұеҮҪж•°жӣҝжҚўдёәtf.losses.mse()ж–№жі•гҖӮжҲ‘们еҲқе§ӢеҢ–дәҶTF.keras.optimizers.sgd()дјҳеҢ–зЁӢеәҸиҖҢдёҚжҳҜз”ЁжёҗеҸҳжүӢеҠЁжӣҙж–°жЁЎеһӢеҸӮж•°гҖӮи°ғз”ЁOptimizer.apply_gradient()е№¶дј йҖ’жқғйҮҚе’ҢеҒҸзҪ®е…ғз»„еҲ—иЎЁе°ҶдҪҝз”ЁжёҗеҸҳжӣҙж–°жЁЎеһӢеҸӮж•°гҖӮ
tf_model_train_loop = LinearRegressionKeras() optimizer = tf.keras.optimizers.SGD(learning_ratelearning_rate=learning_rate) for epoch in range(epochs * 3): x_batch = tf.reshape(x, [200, 1]) with tf.GradientTape() as tape: y_pred = tf_model_train_loop(x_batch) y_pred = tf.reshape(y_pred, [200]) loss = tf.losses.mse(y_pred, y) grads = tape.gradient(loss, tf_model_train_loop.variables) optimizer.apply_gradients(grads_and_vars=zip(grads, tf_model_train_loop.variables)) if epoch % 20 == 0: print(f"Epoch {epoch} : Loss {loss.numpy()}")е…·жңүиҮӘе®ҡд№үеҫӘзҺҜе’ҢSGDдјҳеҢ–еҷЁзҡ„Pytorchи®ӯз»ғеҫӘзҺҜ
дёҺдёҠйқўзҡ„дёҠдёҖдёӘTensorflowд»Јз Ғж®өдёҖж ·пјҢд»ҘдёӢд»Јз ҒзүҮж®өйҖҡиҝҮйҮҚз”ЁPytorchеә“жҸҗдҫӣзҡ„дёўеӨұеҠҹиғҪе’ҢдјҳеҢ–еҷЁжқҘе®һзҺ°ж–°жЁЎеһӢзҡ„Pytorchи®ӯз»ғеҫӘзҺҜгҖӮжӮЁдјҡжіЁж„ҸеҲ°жҲ‘们е°ҶдҪҝз”ЁNN.Mseloss()ж–№жі•жӣҝжҚўжҲ‘们д»ҘеүҚзҡ„иҮӘе®ҡд№үPythonдёўеӨұеҮҪж•°пјҢ并еҲқе§ӢеҢ–ж ҮеҮҶOptim.sgd()дјҳеҢ–зЁӢеәҸпјҢе…¶дёӯеҢ…еҗ«жЁЎеһӢзҡ„еӯҰд№ еҸӮж•°еҲ—иЎЁгҖӮеҰӮеүҚжүҖиҝ°пјҢжҲ‘们е°ҶжҢҮзӨәPytorchд»ҺдёўеӨұеҗ‘еҗҺдј ж’ӯдёӯиҺ·еҸ–жҜҸдёӘеҸӮж•°еј йҮҸзҡ„е…іиҒ”жўҜеәҰ(load.backward())пјҢжңҖеҗҺпјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮи°ғз”ЁжқҘе®№жҳ“ең°жӣҙж–°ж–°ж ҮеҮҶдјҳеҢ–еҷЁдёҺдёҺжўҜеәҰзӣёе…іиҒ”зҡ„жүҖжңүеҸӮж•°жӣҙж–°ж–°зҡ„ж ҮеҮҶдјҳеҢ–еҷЁдјҳеҢ–еҷЁ.step()ж–№жі•гҖӮPytorchдҪҝеј йҮҸе’ҢжўҜеәҰд№Ӣй—ҙиҮӘеҠЁе…іиҒ”зҡ„ж–№ејҸе…Ғи®ёдјҳеҢ–еҷЁжЈҖзҙўеј йҮҸе’ҢжўҜеәҰд»ҘйҖҡиҝҮй…ҚзҪ®зҡ„еӯҰд№ йҖҹзҺҮжӣҙж–°е®ғ们гҖӮ
torch_model = LinearRegressionPyTorch() criterion = torch.nn.MSELoss(reduction='mean') optimizer = torch.optim.SGD(torch_model.parameters(), lr=learning_rate) for epoch in range(epochs * 3): y_pred = torch_model(inputs) loss = criterion(y_pred, labels) optimizer.zero_grad() loss.backward() optimizer.step() if epoch % 20 == 0: print(f"Epoch {epoch} : Loss {loss.data}")з»“жһң
жӯЈеҰӮжҲ‘们жүҖзңӢеҲ°зҡ„йӮЈж ·пјҢTensoRFlowе’ҢPytorchиҮӘеҠЁе·®еҲҶе’ҢеҠЁжҖҒеӯҗзұ»APIйқһеёёзӣёдјјпјҢеҚідҪҝе®ғ们дҪҝз”Ёж ҮеҮҶSGDе’ҢMSEе®һзҺ°ж–№ејҸд№ҹжҳҜеҰӮжӯӨгҖӮеҪ“然пјҢиҝҷдёӨдёӘжЁЎеһӢд№ҹз»ҷдәҶжҲ‘们йқһеёёзӣёдјјзҡ„з»“жһңгҖӮ
еңЁдёӢйқўзҡ„д»Јз ҒзүҮж®өдёӯпјҢжҲ‘们дҪҝз”ЁTensorflowзҡ„Training_variablesе’ҢPytorchзҡ„еҸӮж•°ж–№жі•жқҘиҺ·еҫ—еҜ№жЁЎеһӢзҡ„еҸӮж•°зҡ„и®ҝй—®пјҢ并з»ҳеҲ¶жҲ‘们еӯҰд№ зҡ„зәҝжҖ§еҮҪж•°зҡ„еӣҫиЎЁгҖӮ
[w_tf, b_tf] = tf_model_fit.trainable_variables [w2_tf, b2_tf] = tf_model_train_loop.trainable_variables [w_torch, b_torch] = torch_model.parameters() w_tf = tf.reshape(w_tf, [1]) w2_tf = tf.reshape(w2_tf, [1]) with torch.no_grad(): plt.figure(figsize = (12,5)) ax = plt.subplot(111) ax.scatter(x, y, c = "b", label="samples") ax.plot(x, w_tf * x + b_tf, "r", linewidth = 5.0, label = "tensorflow fit") ax.plot(x, w2_tf * x + b2_tf, "y", linewidth = 5.0, label = "tensorflow train loop") ax.plot(x, w_torch * inputs + b_torch, "c", linewidth = 5.0, label = "pytorch") ax.legend() plt.xlabel("x1") plt.ylabel("y",rotation = 0)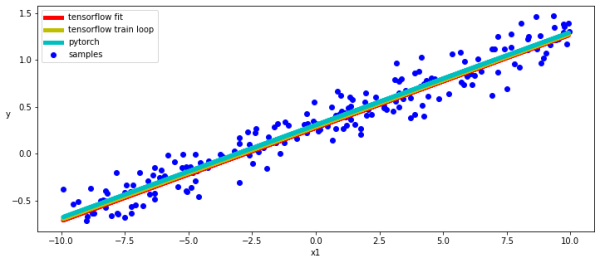
з»“и®ә
Pytorchе’Ңж–°Tensorflow 2.xйғҪж”ҜжҢҒеҠЁжҖҒеӣҫеҪўе’ҢиҮӘеҠЁе·®еҲҶж ёеҝғеҠҹиғҪпјҢд»ҘжҸҗеҸ–еӣҫиЎЁдёӯдҪҝз”Ёзҡ„жүҖжңүеҸӮж•°зҡ„жёҗеҸҳгҖӮжӮЁеҸҜд»ҘиҪ»жқҫең°еңЁPythonдёӯе®һзҺ°и®ӯз»ғеҫӘзҺҜпјҢе…¶дёӯеҢ…еҗ«д»»дҪ•жҚҹеӨұеҮҪж•°е’ҢжёҗеҸҳеҗҺд»ЈдјҳеҢ–еҷЁгҖӮдёәдәҶдё“жіЁдәҺдёӨдёӘжЎҶжһ¶д№Ӣй—ҙзҡ„зңҹе®һж ёеҝғе·®ејӮпјҢжҲ‘们йҖҡиҝҮе®һж–ҪиҮӘе·ұзҡ„з®ҖеҚ•MSEе’ҢNaïveSGDжқҘз®ҖеҢ–дёҠйқўзҡ„зӨәдҫӢгҖӮ
дҪҶжҳҜпјҢжҲ‘ејәзғҲе»әи®®жӮЁеңЁе®һзҺ°д»»дҪ•Naïveд»Јз Ғд№ӢеүҚйҮҚз”Ёиҝҷдәӣеә“дёҠеҸҜз”Ёзҡ„дјҳеҢ–е’Ңдё“з”Ёд»Јз ҒгҖӮ
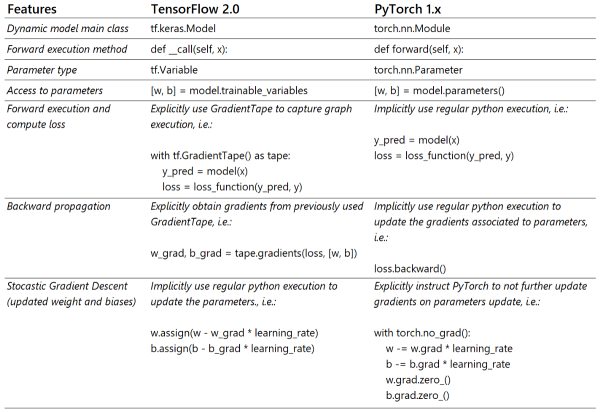
дёӢиЎЁжҖ»з»“дәҶдёҠйқўзӨәдҫӢд»Јз ҒдёӯжүҖжіЁжҳҺзҡ„жүҖжңүе·®ејӮгҖӮжҲ‘еёҢжңӣе®ғеҸҜд»ҘдҪңдёәеңЁиҝҷдёӨдёӘжЎҶжһ¶д№Ӣй—ҙеҲҮжҚўж—¶зҡ„жңүз”ЁеҸӮиҖғгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңpytorchдёҺtensorflowжңүе“ӘдәӣеҢәеҲ«вҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





