本篇内容主要讲解“如何理解分布式调度框架Elastic-job”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“如何理解分布式调度框架Elastic-job”吧!
一、介绍
之所以产生这样的结果,是因为 Quartz 在分布式集群环境下是通过数据库锁方式来实现有且只有一个有效的服务节点来运行服务,从而保证服务在集群环境下定时任务不会被重复调用!
如果需要运行的定时任务很少的话,使用 Quartz 不会有太大的问题,但是如果 现在有这么一个需求,例如理财产品,每天6点系统需要计算每个账户昨天的收益,假如这个理财产品,有几个亿的用户,如果都在一个服务实例上跑,可能第二天都无法处理完这项任务!
类似这样场景还有很多很多,很显然 Quartz 很难满足我们这种大批量、任务执行周期长的任务调度!
因此短板,当当网基于 Quartz 开发了一套适合在分布式环境下能高效率的使用服务器资源的 Elastic-Job 定时任务框架!
Elastic-Job-Lite最大的亮点就是支持弹性扩容缩容,怎么实现的呢?
比如现在有个任务要执行,如果将任务进行分片成10个,那么可以同时在10个服务实例上并行执行,互相不影响,从而大大的提升了任务执行效率,并且充分的利用服务器资源!
对于上面的理财产品,如果这个任务需要处理1个亿用户,那么我们可以通过水平扩展,比如对任务进行分片为500,让500个服务实例同时运行,每个服务实例处理20万条数据,不出意外的话,1 - 2个小时可以全部跑完,如果时间还是很长,还可以继续水平扩张,添加服务实例来运行!
2015 年,当当网将其开源,瞬间吸引了一大批程序员的关注,同时登顶开源中国第一名!
下面我们就一起来了解一下这款使用非常广泛的分布式调度框架。
二、项目架构介绍
Elastic-Job 最开始只有一个 elastic-job-core 的项目,定位轻量级、无中心化,最核心的服务就是支持弹性扩容和数据分片!
从 2.X 版本以后,主要分为 Elastic-Job-Lite 和 Elastic-Job-Cloud 两个子项目。
其中,Elastic-Job-Lite 定位为轻量级 无 中 心 化 解 决 方 案 , 使 用jar 包 的 形 式 提 供 分 布 式 任 务 的 协 调 服 务 。
而 Elastic-Job-Cloud 使用 Mesos + Docker 的解决方案,额外提供资源治理、应用分发以及进程隔离等服务(跟 Lite 的区别只是部署方式不同,他们使用相同的 API,只要开发一次)。
今天我们主要介绍的是Elastic-Job-Lite,最主要的功能特性如下:
分布式调度协调:采用 zookeeper 实现注册中心,进行统一调度。
支持任务分片:将需要执行的任务进行分片,实现并行调度。
支持弹性扩容缩容:将任务拆分为 n 个任务项后,各个服务器分别执行各自分配到的任务项。一旦有新的服务器加入集群,或现有服务器下线,elastic-job 将在保留本次任务执行不变的情况下,下次任务开始前触发任务重分片。
当然,还有失效转移、错过执行作业重触发等等功能,大家可以访问官网文档,以获取更多详细资料。
应用在各自的节点执行任务,通过 zookeeper 注册中心协调。节点注册、节点选举、任务分片、监听都在 E-Job 的代码中完成。下图是官网提供得架构图。
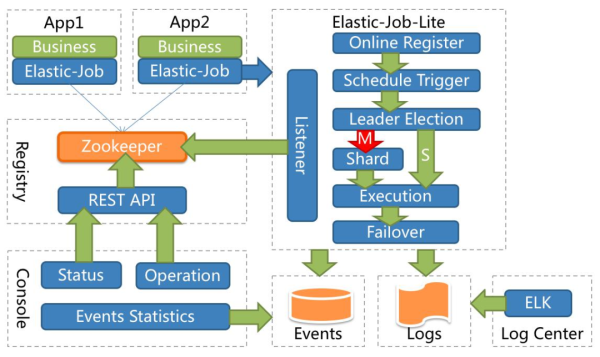
啥也不用多说了,下面我们直接通过实践介绍,更容易了解里面是怎么玩的!
三、应用实践
3.1、zookeeper 安装
elastic-job-lite,是直接依赖 zookeeper 的,因此在开发之前我们需要先准备好对应的 zookeeper 环境,关于 zookeeper 的安装过程,就不多说了,非常简单,网上都有教程!
3.2、elastic-job-lite-console 安装
elastic-job-lite-console,主要是一个任务作业可视化界面管理系统。
可以单独部署,与平台不关,主要是通过配置注册中心和数据源来抓取数据。
获取的方式也很简单,直接访问https://github.com/apache/shardingsphere-elasticjob地址,然后切换到2.1.5的版本号,然后执行mvn clean install进行打包,获取对应的安装包将其解压,进行bin文件夹启动服务即可!
如果你的网速像蜗牛一样的慢,还有一个办法就是从这个地址https://gitee.com/elasticjob/elastic-job获取对应的源码!
启动服务后,在浏览器访问http://127.0.0.1:8899,输入账户、密码(都是root)即可进入控制台页面,类似如下界面!
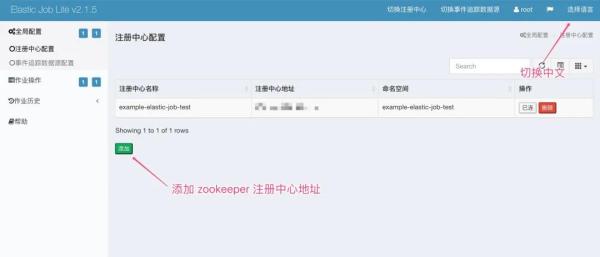
进入之后,将上文所在的 zookeeper 注册中心进行配置,包括数据库 mysql 的数据源也可以配置一下!
3.3、创建工程
本文采用springboot来搭建工程为例,创建工程并添加elastic-job-lite依赖!
<!-- 引入elastic-job-lite核心模块 --> <dependency> <groupId>com.dangdang</groupId> <artifactId>elastic-job-lite-core</artifactId> <version>2.1.5</version> </dependency> <!-- 使用springframework自定义命名空间时引入 --> <dependency> <groupId>com.dangdang</groupId> <artifactId>elastic-job-lite-spring</artifactId> <version>2.1.5</version> </dependency>在配置文件application.properties中提前配置好 zookeeper 注册中心相关信息!
#zookeeper config zookeeper.serverList=127.0.0.1:2181 zookeeper.namespace=example-elastic-job-test3.4、新建 ZookeeperConfig 配置类
@Configuration @ConditionalOnExpression("'${zookeeper.serverList}'.length() > 0") public class ZookeeperConfig { /** * zookeeper 配置 * @return */ @Bean(initMethod = "init") public ZookeeperRegistryCenter zookeeperRegistryCenter(@Value("${zookeeper.serverList}") String serverList, @Value("${zookeeper.namespace}") String namespace){ return new ZookeeperRegistryCenter(new ZookeeperConfiguration(serverList,namespace)); } }3.5、新建任务处理类
elastic-job支持三种类型的作业任务处理!
Simple 类型作业:Simple 类型用于一般任务的处理,只需实现SimpleJob接口。该接口仅提供单一方法用于覆盖,此方法将定时执行,与Quartz原生接口相似。
Dataflow 类型作业:Dataflow 类型用于处理数据流,需实现DataflowJob接口。该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据。
Script类型作业:Script 类型作业意为脚本类型作业,支持 shell,python,perl等所有类型脚本。只需通过控制台或代码配置 scriptCommandLine 即可,无需编码。执行脚本路径可包含参数,参数传递完毕后,作业框架会自动追加最后一个参数为作业运行时信息。
3.6、新建 Simple 类型作业
编写一个SimpleJob接口的实现类MySimpleJob,当前工作主要是打印一条日志。
@Slf4j public class MySimpleJob implements SimpleJob { @Override public void execute(ShardingContext shardingContext) { log.info(String.format("Thread ID: %s, 作业分片总数: %s, " + "当前分片项: %s.当前参数: %s," + "作业名称: %s.作业自定义参数: %s" , Thread.currentThread().getId(), shardingContext.getShardingTotalCount(), shardingContext.getShardingItem(), shardingContext.getShardingParameter(), shardingContext.getJobName(), shardingContext.getJobParameter() )); } }创建一个MyElasticJobListener任务监听器,用于监听MySimpleJob的任务执行情况。
@Slf4j public class MyElasticJobListener implements ElasticJobListener { private long beginTime = 0; @Override public void beforeJobExecuted(ShardingContexts shardingContexts) { beginTime = System.currentTimeMillis(); log.info("===>{} MyElasticJobListener BEGIN TIME: {} <===",shardingContexts.getJobName(), DateFormatUtils.format(new Date(), "yyyy-MM-dd HH:mm:ss")); } @Override public void afterJobExecuted(ShardingContexts shardingContexts) { long endTime = System.currentTimeMillis(); log.info("===>{} MyElasticJobListener END TIME: {},TOTAL CAST: {} <===",shardingContexts.getJobName(), DateFormatUtils.format(new Date(), "yyyy-MM-dd HH:mm:ss"), endTime - beginTime); } }创建一个MySimpleJobConfig类,将MySimpleJob其注入到zookeeper。
@Configuration public class MySimpleJobConfig { /** * 任务名称 */ @Value("${simpleJob.mySimpleJob.name}") private String mySimpleJobName; /** * cron表达式 */ @Value("${simpleJob.mySimpleJob.cron}") private String mySimpleJobCron; /** * 作业分片总数 */ @Value("${simpleJob.mySimpleJob.shardingTotalCount}") private int mySimpleJobShardingTotalCount; /** * 作业分片参数 */ @Value("${simpleJob.mySimpleJob.shardingItemParameters}") private String mySimpleJobShardingItemParameters; /** * 自定义参数 */ @Value("${simpleJob.mySimpleJob.jobParameters}") private String mySimpleJobParameters; @Autowired private ZookeeperRegistryCenter registryCenter; @Bean public MySimpleJob mySimpleJob() { return new MySimpleJob(); } @Bean(initMethod = "init") public JobScheduler simpleJobScheduler(final MySimpleJob mySimpleJob) { //配置任务监听器 MyElasticJobListener elasticJobListener = new MyElasticJobListener(); return new SpringJobScheduler(mySimpleJob, registryCenter, getLiteJobConfiguration(), elasticJobListener); } private LiteJobConfiguration getLiteJobConfiguration() { // 定义作业核心配置 JobCoreConfiguration simpleCoreConfig = JobCoreConfiguration.newBuilder(mySimpleJobName, mySimpleJobCron, mySimpleJobShardingTotalCount). shardingItemParameters(mySimpleJobShardingItemParameters).jobParameter(mySimpleJobParameters).build(); // 定义SIMPLE类型配置 SimpleJobConfiguration simpleJobConfig = new SimpleJobConfiguration(simpleCoreConfig, MySimpleJob.class.getCanonicalName()); // 定义Lite作业根配置 LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).overwrite(true).build(); return simpleJobRootConfig; } }在配置文件application.properties中配置好对应的mySimpleJob参数!
#elastic job #simpleJob类型的job simpleJob.mySimpleJob.name=mySimpleJob simpleJob.mySimpleJob.cron=0/15 * * * * ? simpleJob.mySimpleJob.shardingTotalCount=3 simpleJob.mySimpleJob.shardingItemParameters=0=a,1=b,2=c simpleJob.mySimpleJob.jobParameters=helloWorld运行程序,看看效果如何?
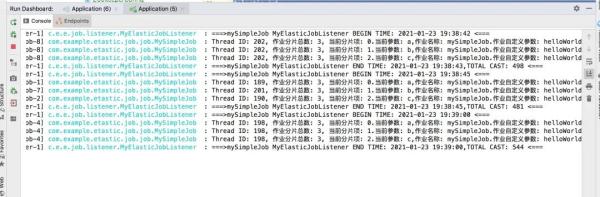
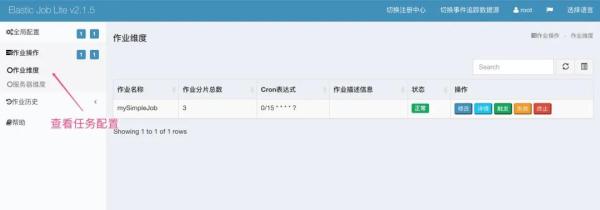
在上图demo中,配置的分片数为3,这个时候会有3个线程进行同时执行任务,因为都是在一台机器上执行的,这个任务被执行来3次,下面修改一下端口配置,创建三个相同的服务实例,在看看效果如下:

很清晰的看到任务被执行一次!
3.7、新建 DataFlowJob 类型作业
DataFlowJob 类型的任务配置和SimpleJob类似,操作也很简单!
创建一个DataflowJob类型的实现类MyDataFlowJob。
@Slf4j public class MyDataFlowJob implements DataflowJob<String> { private boolean flag = false; @Override public List<String> fetchData(ShardingContext shardingContext) { log.info("开始获取数据"); if (flag) { return null; } return Arrays.asList("qingshan", "jack", "seven"); } @Override public void processData(ShardingContext shardingContext, List<String> data) { for (String val : data) { // 处理完数据要移除掉,不然就会一直跑,处理可以在上面的方法里执行。这里采用 flag log.info("开始处理数据:" + val); } flag = true; } }接着创建MyDataFlowJob的配置类,将其注入到zookeeper注册中心。
Configuration public class MyDataFlowJobConfig { /** * 任务名称 */ @Value("${dataflowJob.myDataflowJob.name}") private String jobName; /** * cron表达式 */ @Value("${dataflowJob.myDataflowJob.cron}") private String jobCron; /** * 作业分片总数 */ @Value("${dataflowJob.myDataflowJob.shardingTotalCount}") private int jobShardingTotalCount; /** * 作业分片参数 */ @Value("${dataflowJob.myDataflowJob.shardingItemParameters}") private String jobShardingItemParameters; /** * 自定义参数 */ @Value("${dataflowJob.myDataflowJob.jobParameters}") private String jobParameters; @Autowired private ZookeeperRegistryCenter registryCenter; @Bean public MyDataFlowJob myDataFlowJob() { return new MyDataFlowJob(); } @Bean(initMethod = "init") public JobScheduler dataFlowJobScheduler(final MyDataFlowJob myDataFlowJob) { MyElasticJobListener elasticJobListener = new MyElasticJobListener(); return new SpringJobScheduler(myDataFlowJob, registryCenter, getLiteJobConfiguration(), elasticJobListener); } private LiteJobConfiguration getLiteJobConfiguration() { // 定义作业核心配置 JobCoreConfiguration dataflowCoreConfig = JobCoreConfiguration.newBuilder(jobName, jobCron, jobShardingTotalCount). shardingItemParameters(jobShardingItemParameters).jobParameter(jobParameters).build(); // 定义DATAFLOW类型配置 DataflowJobConfiguration dataflowJobConfig = new DataflowJobConfiguration(dataflowCoreConfig, MyDataFlowJob.class.getCanonicalName(), false); // 定义Lite作业根配置 LiteJobConfiguration dataflowJobRootConfig = LiteJobConfiguration.newBuilder(dataflowJobConfig).overwrite(true).build(); return dataflowJobRootConfig; } }最后,在配置文件application.properties中配置好对应的myDataflowJob参数!
#dataflow类型的job dataflowJob.myDataflowJob.name=myDataflowJob dataflowJob.myDataflowJob.cron=0/15 * * * * ? dataflowJob.myDataflowJob.shardingTotalCount=1 dataflowJob.myDataflowJob.shardingItemParameters=0=a,1=b,2=c dataflowJob.myDataflowJob.jobParameters=myDataflowJobParamter运行程序,看看效果如何?
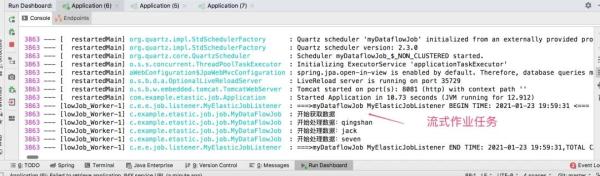
需要注意的地方是,如果配置的是流式处理类型,它会不停的拉取数据、处理数据,在拉取的时候,如果返回为空,就不会处理数据!
如果配置的是非流式处理类型,和上面介绍的simpleJob类型,处理一样!
3.8、新建 ScriptJob 类型作业
ScriptJob 类型的任务配置和上面类似,主要是用于定时执行某个脚本,一般用的比较少!
因为目标是脚本,没有执行的任务,所以无需编写任务作业类型!
只需要编写一个ScriptJob类型的配置类即可,命令是echo 'Hello World !内容!
@Configuration public class MyScriptJobConfig { /** * 任务名称 */ @Value("${scriptJob.myScriptJob.name}") private String jobName; /** * cron表达式 */ @Value("${scriptJob.myScriptJob.cron}") private String jobCron; /** * 作业分片总数 */ @Value("${scriptJob.myScriptJob.shardingTotalCount}") private int jobShardingTotalCount; /** * 作业分片参数 */ @Value("${scriptJob.myScriptJob.shardingItemParameters}") private String jobShardingItemParameters; /** * 自定义参数 */ @Value("${scriptJob.myScriptJob.jobParameters}") private String jobParameters; @Autowired private ZookeeperRegistryCenter registryCenter; @Bean(initMethod = "init") public JobScheduler scriptJobScheduler() { MyElasticJobListener elasticJobListener = new MyElasticJobListener(); return new JobScheduler(registryCenter, getLiteJobConfiguration(), elasticJobListener); } private LiteJobConfiguration getLiteJobConfiguration() { // 定义作业核心配置 JobCoreConfiguration scriptCoreConfig = JobCoreConfiguration.newBuilder(jobName, jobCron, jobShardingTotalCount). shardingItemParameters(jobShardingItemParameters).jobParameter(jobParameters).build(); // 定义SCRIPT类型配置 ScriptJobConfiguration scriptJobConfig = new ScriptJobConfiguration(scriptCoreConfig, "echo 'Hello World !'"); // 定义Lite作业根配置 LiteJobConfiguration scriptJobRootConfig = LiteJobConfiguration.newBuilder(scriptJobConfig).overwrite(true).build(); return scriptJobRootConfig; } }在配置文件application.properties中配置好对应的myScriptJob参数!
#script类型的job scriptJob.myScriptJob.name=myScriptJob scriptJob.myScriptJob.cron=0/15 * * * * ? scriptJob.myScriptJob.shardingTotalCount=3 scriptJob.myScriptJob.shardingItemParameters=0=a,1=b,2=c scriptJob.myScriptJob.jobParameters=myScriptJobParamter运行程序,看看效果如何?
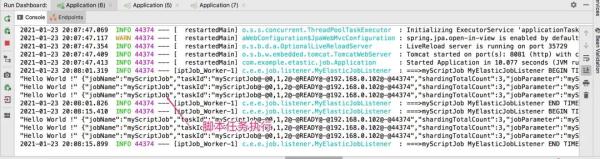
3.9、将任务状态持久化到数据库
可能有的人会发出疑问,elastic-job是如何存储数据的,用ZooInspector客户端链接zookeeper注册中心,你发现对应的任务配置被存储到相应的树根上!

而具体作业任务执行轨迹和状态结果是不会存储到zookeeper,需要我们在项目中通过数据源方式进行持久化!
将任务状态持久化到数据库配置过程也很简单,只需要在对应的配置类上注入数据源即可,以MySimpleJobConfig为例,代码如下:
@Configuration public class MySimpleJobConfig { /** * 任务名称 */ @Value("${simpleJob.mySimpleJob.name}") private String mySimpleJobName; /** * cron表达式 */ @Value("${simpleJob.mySimpleJob.cron}") private String mySimpleJobCron; /** * 作业分片总数 */ @Value("${simpleJob.mySimpleJob.shardingTotalCount}") private int mySimpleJobShardingTotalCount; /** * 作业分片参数 */ @Value("${simpleJob.mySimpleJob.shardingItemParameters}") private String mySimpleJobShardingItemParameters; /** * 自定义参数 */ @Value("${simpleJob.mySimpleJob.jobParameters}") private String mySimpleJobParameters; @Autowired private ZookeeperRegistryCenter registryCenter; @Autowired private DataSource dataSource;; @Bean public MySimpleJob stockJob() { return new MySimpleJob(); } @Bean(initMethod = "init") public JobScheduler simpleJobScheduler(final MySimpleJob mySimpleJob) { //添加事件数据源配置 JobEventConfiguration jobEventConfig = new JobEventRdbConfiguration(dataSource); MyElasticJobListener elasticJobListener = new MyElasticJobListener(); return new SpringJobScheduler(mySimpleJob, registryCenter, getLiteJobConfiguration(), jobEventConfig, elasticJobListener); } private LiteJobConfiguration getLiteJobConfiguration() { // 定义作业核心配置 JobCoreConfiguration simpleCoreConfig = JobCoreConfiguration.newBuilder(mySimpleJobName, mySimpleJobCron, mySimpleJobShardingTotalCount). shardingItemParameters(mySimpleJobShardingItemParameters).jobParameter(mySimpleJobParameters).build(); // 定义SIMPLE类型配置 SimpleJobConfiguration simpleJobConfig = new SimpleJobConfiguration(simpleCoreConfig, MySimpleJob.class.getCanonicalName()); // 定义Lite作业根配置 LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).overwrite(true).build(); return simpleJobRootConfig; } }同时,需要在配置文件application.properties中配置好对应的datasource参数!
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/example-elastic-job-test spring.datasource.username=root spring.datasource.password=root spring.datasource.driver-class-name=com.mysql.jdbc.Driver运行程序,然后在elastic-job-lite-console控制台配置对应的数据源!

最后,点击【作业轨迹】即可查看对应作业执行情况!
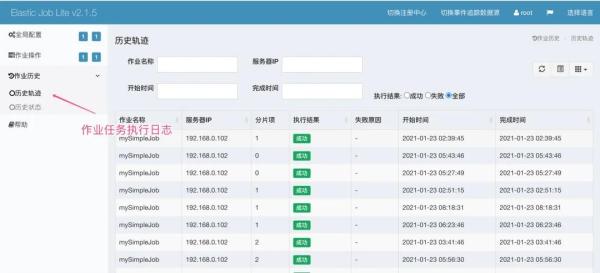
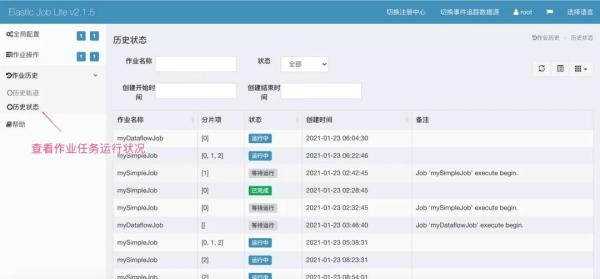
到此,相信大家对“如何理解分布式调度框架Elastic-job”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/8mbNIBDQw2gMHPkmHfj1JQ



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



