еҰӮдҪ•зҗҶи§Је®№еҷЁйғЁзҪІELK7.10
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңеҰӮдҪ•зҗҶи§Је®№еҷЁйғЁзҪІELK7.10вҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁеҰӮдҪ•зҗҶи§Је®№еҷЁйғЁзҪІELK7.10й—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқеҰӮдҪ•зҗҶи§Је®№еҷЁйғЁзҪІELK7.10вҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
дёҖгҖҒelkжһ¶жһ„з®Җд»Ӣ
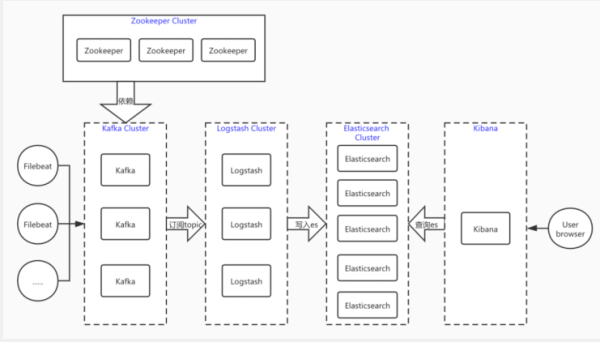
йҰ–е…Ҳ logstash е…·жңүж—Ҙеҝ—йҮҮйӣҶгҖҒиҝҮж»ӨгҖҒзӯӣйҖүзӯүеҠҹиғҪпјҢеҠҹиғҪе®Ңе–„дҪҶеҗҢж—¶дҪ“йҮҸд№ҹдјҡжҜ”иҫғеӨ§пјҢж¶ҲиҖ—зі»з»ҹиө„жәҗиҮӘ然д№ҹеӨҡгҖӮfilebeatдҪңдёәдёҖдёӘиҪ»йҮҸзә§ж—Ҙеҝ—йҮҮйӣҶе·Ҙе…·пјҢиҷҪ然没жңүиҝҮж»ӨзӯӣйҖүеҠҹиғҪпјҢдҪҶжҳҜд»…д»…йғЁзҪІеңЁеә”з”ЁжңҚеҠЎеҷЁдҪңдёәжҲ‘们йҮҮйӣҶж—Ҙеҝ—зҡ„е·Ҙе…·еҸҜд»ҘжҳҜиҜҙжңҖеҘҪзҡ„йҖүжӢ©гҖӮдҪҶжҲ‘们жңүдәӣж—¶еҖҷеҸҜиғҪеҸҲйңҖиҰҒlogstashзҡ„иҝҮж»ӨзӯӣйҖүеҠҹиғҪпјҢжүҖд»ҘжҲ‘们еңЁйҮҮйӣҶж—Ҙеҝ—ж—¶з”ЁfilebeatпјҢ然еҗҺдәӨз»ҷlogstashиҝҮж»ӨзӯӣйҖүгҖӮ
е…¶ж¬ЎпјҢlogstashзҡ„еҗһеҗҗйҮҸжҳҜжңүйҷҗзҡ„пјҢдёҖж—Ұзҹӯж—¶й—ҙеҶ…filebeatдј иҝҮжқҘзҡ„ж—Ҙеҝ—иҝҮеӨҡдјҡдә§з”ҹе Ҷз§Ҝе’Ңе өеЎһпјҢеҜ№ж—Ҙеҝ—зҡ„йҮҮйӣҶд№ҹдјҡеҸ—еҲ°еҪұе“ҚпјҢжүҖд»ҘеңЁfilebeatдёҺlogstashдёӯй—ҙеҸҲеҠ дәҶдёҖеұӮkafkaж¶ҲжҒҜйҳҹеҲ—жқҘзј“еӯҳжҲ–иҖ…иҜҙи§ЈиҖҰпјҢеҪ“然redisд№ҹжҳҜеҸҜд»Ҙзҡ„гҖӮиҝҷж ·еҪ“дј—еӨҡfilebeatиҠӮзӮ№йҮҮйӣҶеӨ§йҮҸж—Ҙеҝ—зӣҙжҺҘж”ҫеҲ°kafkaдёӯпјҢlogstashж…ўж…ўзҡ„иҝӣиЎҢж¶Ҳиҙ№пјҢдёӨиҫ№дә’дёҚе№Іжү°гҖӮ
иҮідәҺzookeeperпјҢеҲҶеёғејҸжңҚеҠЎз®ЎзҗҶзҘһеҷЁпјҢзӣ‘жҺ§з®ЎзҗҶkafkaзҡ„иҠӮзӮ№жіЁеҶҢпјҢtopicз®ЎзҗҶзӯүпјҢеҗҢж—¶ејҘиЎҘдәҶkafkaйӣҶзҫӨиҠӮзӮ№еҜ№еӨ–з•Ңж— жі•ж„ҹзҹҘзҡ„й—®йўҳпјҢkafkaе®һйҷ…е·Із»ҸиҮӘеёҰдәҶzookeeperпјҢиҝҷйҮҢе°ҶдјҡдҪҝз”ЁзӢ¬з«Ӣзҡ„zookeeperиҝӣиЎҢз®ЎзҗҶпјҢж–№дҫҝеҗҺжңҹzookeeperйӣҶзҫӨзҡ„жү©еұ•гҖӮ
дәҢгҖҒзҺҜеўғ
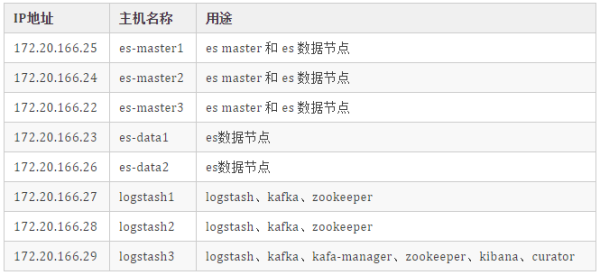
йҳҝйҮҢдә‘ECSпјҡ5еҸ°йғЁзҪІESиҠӮзӮ№пјҢ3еҸ°еҲҶеҲ«йғЁзҪІlogstashгҖҒkafkaгҖҒzookeeperе’ҢkibanaзӯүжңҚеҠЎгҖӮ
йҳҝйҮҢдә‘ECSй…ҚзҪ®пјҡ5еҸ° 4ж ё16G SSDзЈҒзӣҳгҖӮ3еҸ° 4ж ё16G SSDзЈҒзӣҳгҖӮйғҪжҳҜ Centos7.8зі»з»ҹ
е®үиЈ… docker е’Ң docker-compose
ELKзүҲжң¬7.10.1;zookeeperзүҲжң¬3.6.2;kafkaзүҲжң¬2.13-2.6.0;
дёүгҖҒзі»з»ҹеҸӮж•°дјҳеҢ–
# жңҖеӨ§з”ЁжҲ·жү“ејҖиҝӣзЁӢж•° $ vim /etc/security/limits.d/20-nproc.conf * soft nproc 65535 * hard nproc 65535 # дјҳеҢ–еҶ…ж ёпјҢз”ЁдәҺ docker ж”ҜжҢҒ $ modprobe br_netfilter $ cat <<EOF > /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF $ sysctl -p /etc/sysctl.d/k8s.conf # дјҳеҢ–еҶ…ж ёпјҢеҜ№ es ж”ҜжҢҒ $ echo 'vm.max_map_count=262144' >> /etc/sysctl.conf # з”ҹж•Ҳй…ҚзҪ® $ sysctl -p
еӣӣгҖҒйғЁзҪІ docker е’Ң docker-compose
йғЁзҪІ docker
# е®үиЈ…еҝ…иҰҒзҡ„дёҖдәӣзі»з»ҹе·Ҙе…· $ yum install -y yum-utils device-mapper-persistent-data lvm2 # ж·»еҠ иҪҜ件жәҗдҝЎжҒҜ $ yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # жӣҙ新并е®үиЈ… Docker-CE $ yum makecache fast $ yum -y install docker-ce # й…ҚзҪ®docker $ systemctl enable docker $ systemctl start docker $ vim /etc/docker/daemon.json {"data-root": "/var/lib/docker", "bip": "10.50.0.1/16", "default-address-pools": [{"base": "10.51.0.1/16", "size": 24}], "registry-mirrors": ["https://4xr1qpsp.mirror.aliyuncs.com"], "log-opts": {"max-size":"500m", "max-file":"3"}} $ sed -i '/ExecStart=/i ExecStartPost=\/sbin\/iptables -P FORWARD ACCEPT' /usr/lib/systemd/system/docker.service $ systemctl enable docker.service $ systemctl daemon-reload $ systemctl restart dockerйғЁзҪІ docker-compose
# е®үиЈ… docker-compose $ sudo curl -L "https://github.com/docker/compose/releases/download/1.27.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose $ chmod +x /usr/local/bin/docker-compose
дә”гҖҒйғЁзҪІ ES
es-master1 ж“ҚдҪң
# еҲӣе»ә es зӣ®еҪ• $ mkdir /data/ELKStack $ mkdir elasticsearch elasticsearch-data elasticsearch-plugins # е®№еҷЁesз”ЁжҲ· uid е’Ң gid йғҪжҳҜ 1000 $ chown 1000.1000 elasticsearch-data elasticsearch-plugins # дёҙж—¶еҗҜеҠЁдёҖдёӘes $ docker run --name es-test -it --rm docker.elastic.co/elasticsearch/elasticsearch:7.10.1 bash # з”ҹжҲҗиҜҒд№ҰпјҢиҜҒд№Ұжңүж•Ҳжңҹ10е№ҙпјҢиҜҒд№Ұиҫ“е…Ҙзҡ„еҜҶз ҒиҝҷйҮҢдёәз©ә $ bin/elasticsearch-certutil ca --days 3660 $ bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12 --days 3660 # жү“ејҖж–°зҡ„зӘ—еҸЈпјҢжӢ·иҙқз”ҹжҲҗзҡ„иҜҒд№Ұ $ cd /data/ELKStack/elasticsearch $ mkdir es-p12 $ docker cp es-test:/usr/share/elasticsearch/elastic-certificates.p12 ./es-p12 $ docker cp es-test:/usr/share/elasticsearch/elastic-stack-ca.p12 ./es-p12 $ chown -R 1000.1000 ./es-p12 # еҲӣе»ә docker-compose.yml $ vim docker-compose.yml version: '2.2' services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:7.10.1 container_name: es01 environment: - cluster.name=es-docker-cluster - cluster.initial_master_nodes=es01,es02,es03 - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms10000m -Xmx10000m" ulimits: memlock: soft: -1 hard: -1 nofile: soft: 65536 hard: 65536 mem_limit: 13000m cap_add: - IPC_LOCK restart: always # и®ҫзҪ® docker host зҪ‘з»ңжЁЎејҸ network_mode: "host" volumes: - /data/ELKStack/elasticsearch-data:/usr/share/elasticsearch/data - /data/ELKStack/elasticsearch-plugins:/usr/share/elasticsearch/plugins - /data/ELKStack/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml - /data/ELKStack/elasticsearch/es-p12:/usr/share/elasticsearch/config/es-p12 # еҲӣе»ә elasticsearch.yml й…ҚзҪ®ж–Ү件 $ vim elasticsearch.yml cluster.name: "es-docker-cluster" node.name: "es01" network.host: 0.0.0.0 node.master: true node.data: true discovery.zen.minimum_master_nodes: 2 http.port: 9200 transport.tcp.port: 9300 # еҰӮжһңжҳҜеӨҡиҠӮзӮ№esпјҢйҖҡиҝҮpingжқҘеҒҘеә·жЈҖжҹҘ discovery.zen.ping.unicast.hosts: ["172.20.166.25:9300", "172.20.166.24:9300", "172.20.166.22:9300", "172.20.166.23:9300", "172.20.166.26:9300"] discovery.zen.fd.ping_timeout: 120s discovery.zen.fd.ping_retries: 6 discovery.zen.fd.ping_interval: 10s cluster.info.update.interval: 1m indices.fielddata.cache.size: 20% indices.breaker.fielddata.limit: 40% indices.breaker.request.limit: 40% indices.breaker.total.limit: 70% indices.memory.index_buffer_size: 20% script.painless.regex.enabled: true # зЈҒзӣҳеҲҶзүҮеҲҶй…Қ cluster.routing.allocation.disk.watermark.low: 100gb cluster.routing.allocation.disk.watermark.high: 50gb cluster.routing.allocation.disk.watermark.flood_stage: 30gb # жң¬ең°ж•°жҚ®еҲҶзүҮжҒўеӨҚй…ҚзҪ® gateway.recover_after_nodes: 3 gateway.recover_after_time: 5m gateway.expected_nodes: 3 cluster.routing.allocation.node_initial_primaries_recoveries: 8 cluster.routing.allocation.node_concurrent_recoveries: 2 # е…Ғи®ёи·ЁеҹҹиҜ·жұӮ http.cors.enabled: true http.cors.allow-origin: "*" http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type # ејҖеҗҜxpack xpack.security.enabled: true xpack.monitoring.collection.enabled: true # ејҖеҗҜйӣҶзҫӨдёӯhttpsдј иҫ“ xpack.security.transport.ssl.enabled: true xpack.security.transport.ssl.verification_mode: certificate xpack.security.transport.ssl.keystore.path: es-p12/elastic-certificates.p12 xpack.security.transport.ssl.truststore.path: es-p12/elastic-certificates.p12 # жҠҠ es й…ҚзҪ®дҪҝз”Ё rsync еҗҢжӯҘеҲ°е…¶е®ғ es иҠӮзӮ№ $ rsync -avp -e ssh /data/ELKStack 172.20.166.24:/data/ $ rsync -avp -e ssh /data/ELKStack 172.20.166.22:/data/ $ rsync -avp -e ssh /data/ELKStack 172.20.166.23:/data/ $ rsync -avp -e ssh /data/ELKStack 172.20.166.26:/data/ # еҗҜеҠЁ es $ docker-compose up -d # жҹҘзңӢ es $ docker-compose ps
es-master2 ж“ҚдҪң
$ cd /data/ELKStack/elasticsearch # дҝ®ж”№ docker-compose.yml elasticsearch.yml дёӨдёӘй…ҚзҪ® $ sed -i 's/es01/es02/g' docker-compose.yml elasticsearch.yml # еҗҜеҠЁ es $ docker-compose up -d
es-master3 ж“ҚдҪң
$ cd /data/ELKStack/elasticsearch # дҝ®ж”№ docker-compose.yml elasticsearch.yml дёӨдёӘй…ҚзҪ® $ sed -i 's/es01/es03/g' docker-compose.yml elasticsearch.yml # еҗҜеҠЁ es $ docker-compose up -d
es-data1 ж“ҚдҪң
$ cd /data/ELKStack/elasticsearch # дҝ®ж”№ docker-compose.yml elasticsearch.yml дёӨдёӘй…ҚзҪ® $ sed -i 's/es01/es04/g' docker-compose.yml elasticsearch.yml # дёҚеҒҡдёә es master иҠӮзӮ№пјҢеҸӘеҒҡж•°жҚ®иҠӮзӮ№ $ sed -i 's/node.master: true/node.master: false/g' elasticsearch.yml # еҗҜеҠЁ es $ docker-compose up -d
es-data2 ж“ҚдҪң
$ cd /data/ELKStack/elasticsearch # дҝ®ж”№ docker-compose.yml elasticsearch.yml дёӨдёӘй…ҚзҪ® $ sed -i 's/es01/es05/g' docker-compose.yml elasticsearch.yml # дёҚеҒҡдёә es master иҠӮзӮ№пјҢеҸӘеҒҡж•°жҚ®иҠӮзӮ№ $ sed -i 's/node.master: true/node.master: false/g' elasticsearch.yml # еҗҜеҠЁ es $ docker-compose up -d
и®ҫзҪ® es и®ҝй—®иҙҰеҸ·
# es-master1 ж“ҚдҪң $ docker exec -it es01 bash # и®ҫзҪ® elasticпјҢapm_systemпјҢkibanaпјҢkibana_systemпјҢlogstash_systemпјҢbeats_systemпјҢremote_monitoring_user зӯүеҜҶз Ғ # еҜҶз ҒйғҪи®ҫзҪ®дёә elastic123пјҢиҝҷйҮҢеҸӘжҳҜдёҫдҫӢпјҢе…·дҪ“ж №жҚ®йңҖжұӮи®ҫзҪ® $ ./bin/elasticsearch-setup-passwords interactive
е…ӯгҖҒйғЁзҪІ Kibana
logstash4 ж“ҚдҪң
$ mkdir -p /data/ELKStack/kibana $ cd /data/ELKStack/kibana # еҲӣе»ә kibana зӣёе…ізӣ®еҪ•пјҢз”ЁдәҺе®№еҷЁжҢӮиҪҪ $ mkdir config data plugins $ chown 1000.1000 config data plugins # еҲӣе»ә docker-compose.yml $ vim docker-compose.yml version: '2' services: kibana: image: docker.elastic.co/kibana/kibana:7.10.1 container_name: kibana restart: always network_mode: "bridge" mem_limit: 2000m environment: SERVER_NAME: kibana.example.com ports: - "5601:5601" volumes: - /data/ELKStack/kibana/config:/usr/share/kibana/config - /data/ELKStack/kibana/data:/usr/share/kibana/data - /data/ELKStack/kibana/plugins:/usr/share/kibana/plugins # еҲӣе»ә kibana.yml $ vim config/kibana.yml server.name: kibana server.host: "0" elasticsearch.hosts: ["http://172.20.166.25:9200","http://172.20.166.24:9200","http://172.20.166.22:9200"] elasticsearch.username: "kibana" elasticsearch.password: "elastic123" monitoring.ui.container.elasticsearch.enabled: true xpack.security.enabled: true xpack.encryptedSavedObjects.encryptionKey: encryptedSavedObjects12345678909876543210 xpack.security.encryptionKey: encryptionKeysecurity12345678909876543210 xpack.reporting.encryptionKey: encryptionKeyreporting12345678909876543210 i18n.locale: "zh-CN" # еҗҜеҠЁ kibana $ docker-compose up -d
дёғгҖҒйғЁзҪІ Zookeeper
logstash2 ж“ҚдҪң
# еҲӣе»ә zookeeper зӣ®еҪ• $ mkdir /data/ELKStack/zookeeper $ cd /data/ELKStack/zookeeper $ mkdir data datalog $ chown 1000.1000 data datalog # еҲӣе»ә docker-compose.yml $ vim docker-compose.yml version: '2' services: zoo1: image: zookeeper:3.6.2 restart: always hostname: zoo1 container_name: zoo1 network_mode: "bridge" mem_limit: 2000m ports: - 2181:2181 - 3888:3888 - 2888:2888 volumes: - /data/ELKStack/zookeeper/data:/data - /data/ELKStack/zookeeper/datalog:/datalog - /data/ELKStack/zookeeper/zoo.cfg:/conf/zoo.cfg environment: ZOO_MY_ID: 1 # иЎЁзӨә ZKжңҚеҠЎзҡ„ id, е®ғжҳҜ1-255 д№Ӣй—ҙзҡ„ж•ҙж•°, еҝ…йЎ»еңЁйӣҶзҫӨдёӯе”ҜдёҖ ZOO_SERVERS: server.1=0.0.0.0:2888:3888;2181 server.2=172.20.166.28:2888:3888;2181 server.3=172.20.166.29:2888:3888;2181 # ZOOKEEPER_CLIENT_PORT: 2181 # еҲӣе»ә zoo.cfg й…ҚзҪ® $ vim zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/data dataLogDir=/datalog autopurge.snapRetainCount=3 autopurge.purgeInterval=1 maxClientCnxns=60 server.1= 0.0.0.0:2888:3888;2181 server.2= 172.20.166.28:2888:3888;2181 server.3= 172.20.166.29:2888:3888;2181 # жӢ·иҙқй…ҚзҪ®еҲ° logstash3 logstash4 жңәеҷЁдёҠ $ rsync -avp -e ssh /data/ELKStack/zookeeper 172.20.166.28:/data/ELKStack/ $ rsync -avp -e ssh /data/ELKStack/zookeeper 172.20.166.29:/data/ELKStack/ # еҗҜеҠЁ zookeeper $ docker-compose up -d
logstash3 ж“ҚдҪң
$ cd /data/ELKStack/zookeeper # дҝ®ж”№ docker-compose.yml ж–Ү件 $ vim docker-compose.yml version: '2' services: zoo2: image: zookeeper:3.6.2 restart: always hostname: zoo2 container_name: zoo2 network_mode: "bridge" mem_limit: 2000m ports: - 2181:2181 - 3888:3888 - 2888:2888 volumes: - /data/ELKStack/zookeeper/data:/data - /data/ELKStack/zookeeper/datalog:/datalog - /data/ELKStack/zookeeper/zoo.cfg:/conf/zoo.cfg environment: ZOO_MY_ID: 2 # иЎЁзӨә ZKжңҚеҠЎзҡ„ id, е®ғжҳҜ1-255 д№Ӣй—ҙзҡ„ж•ҙж•°, еҝ…йЎ»еңЁйӣҶзҫӨдёӯе”ҜдёҖ ZOO_SERVERS: server.1=172.20.166.27:2888:3888;2181 server.2=0.0.0.0:2888:3888;2181 server.3=172.20.166.29:2888:3888;2181 # ZOOKEEPER_CLIENT_PORT: 2181 # дҝ®ж”№ zoo.cfg $ vim zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/data dataLogDir=/datalog autopurge.snapRetainCount=3 autopurge.purgeInterval=1 maxClientCnxns=60 server.1= 172.20.166.27:2888:3888;2181 server.2= 0.0.0.0:2888:3888;2181 server.3= 172.20.166.29:2888:3888;2181 # еҗҜеҠЁ zookeeper $ docker-compose up -d
logstash4 ж“ҚдҪң
$ cd /data/ELKStack/zookeeper # дҝ®ж”№ docker-compose.yml ж–Ү件 $ vim docker-compose.yml version: '2' services: zoo3: image: zookeeper:3.6.2 restart: always hostname: zoo3 container_name: zoo3 network_mode: "bridge" mem_limit: 2000m ports: - 2181:2181 - 3888:3888 - 2888:2888 volumes: - /data/ELKStack/zookeeper/data:/data - /data/ELKStack/zookeeper/datalog:/datalog - /data/ELKStack/zookeeper/zoo.cfg:/conf/zoo.cfg environment: ZOO_MY_ID: 3 # иЎЁзӨә ZKжңҚеҠЎзҡ„ id, е®ғжҳҜ1-255 д№Ӣй—ҙзҡ„ж•ҙж•°, еҝ…йЎ»еңЁйӣҶзҫӨдёӯе”ҜдёҖ ZOO_SERVERS: server.1=172.20.166.27:2888:3888;2181 server.2=172.20.166.28:2888:3888;2181 server.3=0.0.0.0:2888:3888;2181 # ZOOKEEPER_CLIENT_PORT: 2181 # дҝ®ж”№ zoo.cfg $ vim zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/data dataLogDir=/datalog autopurge.snapRetainCount=3 autopurge.purgeInterval=1 maxClientCnxns=60 server.1= 172.20.166.27:2888:3888;2181 server.2= 172.20.166.28:2888:3888;2181 server.3= 0.0.0.0:2888:3888;2181 # еҗҜеҠЁ zookeeper $ docker-compose up -d # ж“ҚдҪң zookeeper $ docker run -it zoo3 bash $ zkCli.sh -server 172.20.166.27:2181,172.20.166.28:2181,172.20.166.29:2181
е…«гҖҒйғЁзҪІ Kafka
logstash2 ж“ҚдҪң
# еҲӣе»ә kafka зӣ®еҪ• $ mkdir -p /data/ELKStack/kafka $ cd /data/ELKStack/kafka # еҲӣе»әж•°жҚ®зӣ®еҪ•пјҢз”ЁдәҺеӯҳеӮЁkafkaе®№еҷЁж•°жҚ® $ mkdir data # жҠҠkafkaй…ҚзҪ®жӢ·иҙқеҲ°е®ҝдё»жңәдёҠ $ docker run --name kafka-test -it --rm wurstmeister/kafka:2.13-2.6.0 bash $ cd /opt/kafka $ tar zcvf /tmp/config.tar.gz config # жү“ејҖдёҖдёӘж–°зҡ„зӘ—еҸЈ $ docker cp kafka-test:/tmp/config.tar.gz ./ # и§ЈеҺӢй…ҚзҪ®ж–Ү件 $ tar xf config.tar.gz # еҲӣе»ә docker-compose.yml $ vim docker-compose.yml version: '2' services: kafka1: image: wurstmeister/kafka:2.13-2.6.0 restart: always hostname: kafka1 container_name: kafka1 network_mode: "bridge" mem_limit: 5120m ports: - 9092:9092 - 9966:9966 environment: KAFKA_BROKER_ID: 1 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://172.20.166.27:9092 # е®ҝдё»жңәзҡ„IPең°еқҖиҖҢйқһе®№еҷЁзҡ„IPпјҢеҸҠжҡҙйңІеҮәжқҘзҡ„з«ҜеҸЈ KAFKA_ADVERTISED_HOST_NAME: 172.20.166.27 # еӨ–зҪ‘и®ҝй—®ең°еқҖ KAFKA_ADVERTISED_PORT: 9092 # з«ҜеҸЈ KAFKA_ZOOKEEPER_CONNECT: 172.20.166.27:2181,172.20.166.28:2181,172.20.166.29:2181 # иҝһжҺҘзҡ„zookeeperжңҚеҠЎеҸҠз«ҜеҸЈ KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=172.20.166.27 -Dcom.sun.management.jmxremote.rmi.port=9966" JMX_PORT: 9966 # kafkaйңҖиҰҒзӣ‘жҺ§brokerе’Ңtopicзҡ„ж•°жҚ®зҡ„ж—¶еҖҷ,жҳҜйңҖиҰҒејҖеҗҜjmx_portзҡ„ KAFKA_HEAP_OPTS: "-Xmx4096M -Xms4096M" volumes: - /data/ELKStack/kafka/data:/kafka # kafkaж•°жҚ®ж–Ү件еӯҳеӮЁзӣ®еҪ• - /data/ELKStack/kafka/config:/opt/kafka/config # дјҳеҢ– kafka server.properties й…ҚзҪ® $ vim config/server.properties # и°ғеӨ§socketпјҢйҳІжӯўжҠҘй”ҷ socket.send.buffer.bytes=1024000 socket.receive.buffer.bytes=1024000 socket.request.max.bytes=1048576000 # topic ж•°жҚ®дҝқз•ҷеӨҡд№…пјҢй»ҳи®Ө168е°Ҹж—¶(7day) log.retention.hours=72 log.cleanup.policy=delete # жӢ·иҙқй…ҚзҪ®еҲ° logstash3 logstash4 жңәеҷЁдёҠ $ rsync -avp -e ssh /data/ELKStack/kafka 172.20.166.28:/data/ELKStack/ $ rsync -avp -e ssh /data/ELKStack/kafka 172.20.166.29:/data/ELKStack/ # еҗҜеҠЁ kafka $ docker-compose up -d
logstash3 ж“ҚдҪң
$ cd /data/ELKStack/kafka # дҝ®ж”№ docker-compose.yml ж–Ү件 $ vim docker-compose.yml version: '2' services: kafka2: image: wurstmeister/kafka:2.13-2.6.0 restart: always hostname: kafka2 container_name: kafka2 network_mode: "bridge" mem_limit: 5120m ports: - 9092:9092 - 9966:9966 environment: KAFKA_BROKER_ID: 2 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://172.20.166.28:9092 # е®ҝдё»жңәзҡ„IPең°еқҖиҖҢйқһе®№еҷЁзҡ„IPпјҢеҸҠжҡҙйңІеҮәжқҘзҡ„з«ҜеҸЈ KAFKA_ADVERTISED_HOST_NAME: 172.20.166.28 # еӨ–зҪ‘и®ҝй—®ең°еқҖ KAFKA_ADVERTISED_PORT: 9092 # з«ҜеҸЈ KAFKA_ZOOKEEPER_CONNECT: 172.20.166.27:2181,172.20.166.28:2181,172.20.166.29:2181 # иҝһжҺҘзҡ„zookeeperжңҚеҠЎеҸҠз«ҜеҸЈ KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=172.20.166.28 -Dcom.sun.management.jmxremote.rmi.port=9966" JMX_PORT: 9966 # kafkaйңҖиҰҒзӣ‘жҺ§brokerе’Ңtopicзҡ„ж•°жҚ®зҡ„ж—¶еҖҷ,жҳҜйңҖиҰҒејҖеҗҜjmx_portзҡ„ KAFKA_HEAP_OPTS: "-Xmx4096M -Xms4096M" volumes: - /data/ELKStack/kafka/data:/kafka # kafkaж•°жҚ®ж–Ү件еӯҳеӮЁзӣ®еҪ• - /data/ELKStack/kafka/config:/opt/kafka/config # еҗҜеҠЁ kafka $ docker-compose up -d
logstash4 ж“ҚдҪң
$ cd /data/ELKStack/kafka # дҝ®ж”№ docker-compose.yml ж–Ү件 $ vim docker-compose.yml version: '2' services: kafka3: image: wurstmeister/kafka:2.13-2.6.0 restart: always hostname: kafka3 container_name: kafka3 network_mode: "bridge" mem_limit: 5120m ports: - 9092:9092 - 9966:9966 environment: KAFKA_BROKER_ID: 3 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://172.20.166.29:9092 # е®ҝдё»жңәзҡ„IPең°еқҖиҖҢйқһе®№еҷЁзҡ„IPпјҢеҸҠжҡҙйңІеҮәжқҘзҡ„з«ҜеҸЈ KAFKA_ADVERTISED_HOST_NAME: 172.20.166.29 # еӨ–зҪ‘и®ҝй—®ең°еқҖ KAFKA_ADVERTISED_PORT: 9092 # з«ҜеҸЈ KAFKA_ZOOKEEPER_CONNECT: 172.20.166.27:2181,172.20.166.28:2181,172.20.166.29:2181 # иҝһжҺҘзҡ„zookeeperжңҚеҠЎеҸҠз«ҜеҸЈ KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=172.20.166.29 -Dcom.sun.management.jmxremote.rmi.port=9966" JMX_PORT: 9966 # kafkaйңҖиҰҒзӣ‘жҺ§brokerе’Ңtopicзҡ„ж•°жҚ®зҡ„ж—¶еҖҷ,жҳҜйңҖиҰҒејҖеҗҜjmx_portзҡ„ KAFKA_HEAP_OPTS: "-Xmx4096M -Xms4096M" volumes: - /data/ELKStack/kafka/data:/kafka # kafkaж•°жҚ®ж–Ү件еӯҳеӮЁзӣ®еҪ• - /data/ELKStack/kafka/config:/opt/kafka/config # еҗҜеҠЁ kafka $ docker-compose up -d # йғЁзҪІ kafka-manager з®ЎзҗҶ kafka е№іеҸ° $ mkdir /data/ELKStack/kafka-manager $ cd /data/ELKStack/kafka-manager $ vim docker-compose.yml version: '3.6' services: kafka_manager: restart: always container_name: kafa-manager hostname: kafka-manager network_mode: "bridge" mem_limit: 1024m image: hlebalbau/kafka-manager:3.0.0.5-7e7a22e ports: - "9000:9000" environment: ZK_HOSTS: "172.20.166.27:2181,172.20.166.28:2181,172.20.166.29:2181" APPLICATION_SECRET: "random-secret" KAFKA_MANAGER_AUTH_ENABLED: "true" KAFKA_MANAGER_USERNAME: admin KAFKA_MANAGER_PASSWORD: elastic123 JMX_PORT: 9966 TZ: "Asia/Shanghai" # еҗҜеҠЁ kafka-manager $ docker-compose up -d # и®ҝй—® http://172.20.166.29:9000 пјҢжҠҠдёҠйқўеҲӣе»әзҡ„дёүеҸ° kafka еҠ е…Ҙз®ЎзҗҶпјҢиҝҷйҮҢдёҚеңЁйҳҗиҝ°пјҢзҪ‘дёҠеҫҲеӨҡй…ҚзҪ®ж•ҷзЁӢ
д№қгҖҒйғЁзҪІ logstash
logstash2 ж“ҚдҪң
$ mkdir /data/ELKStack/logstash $ cd /data/ELKStack/logstash $ mkdir config data $ chown 1000.1000 config data # еҲӣе»ә docker-compose.yml $ vim docker-compose.yml version: '2' services: logstash2: image: docker.elastic.co/logstash/logstash:7.10.1 container_name: logstash2 hostname: logstash2 restart: always network_mode: "bridge" mem_limit: 4096m environment: TZ: "Asia/Shanghai" ports: - 5044:5044 volumes: - /data/ELKStack/logstash/config:/config-dir - /data/ELKStack/logstash/logstash.yml:/usr/share/logstash/config/logstash.yml - /data/ELKStack/logstash/data:/usr/share/logstash/data - /etc/localtime:/etc/localtime user: logstash command: bash -c "logstash -f /config-dir --config.reload.automatic" # еҲӣе»ә logstash.yml $ vim logstash.yml http.host: "0.0.0.0" # жҢҮеҸ‘йҖҒеҲ°Elasticsearchзҡ„жү№йҮҸиҜ·жұӮзҡ„еӨ§е°ҸпјҢеҖји¶ҠеӨ§пјҢеӨ„зҗҶеҲҷйҖҡеёёжӣҙй«ҳж•ҲпјҢдҪҶеўһеҠ дәҶеҶ…еӯҳејҖй”Җ pipeline.batch.size: 3000 # жҢҮи°ғж•ҙLogstashз®ЎйҒ“зҡ„延иҝҹпјҢиҝҮдәҶиҜҘж—¶й—ҙеҲҷlogstashејҖе§Ӣжү§иЎҢиҝҮж»ӨеҷЁе’Ңиҫ“еҮә pipeline.batch.delay: 200 # еҲӣе»ә logstash 规еҲҷй…ҚзҪ® $ vim config/01-input.conf input { # иҫ“е…Ҙ组件 kafka { # д»Һkafkaж¶Ҳиҙ№ж•°жҚ® bootstrap_servers => ["172.20.166.27:9092,172.20.166.28:9092,172.20.166.29:9092"] #topics => "%{[@metadata][topic]}" # дҪҝз”Ёkafkaдј иҝҮжқҘзҡ„topic topics_pattern => "elk-.*" # дҪҝз”ЁжӯЈеҲҷеҢ№й…Қtopic codec => "json" # ж•°жҚ®ж јејҸ consumer_threads => 3 # ж¶Ҳиҙ№зәҝзЁӢж•°йҮҸ decorate_events => true # еҸҜеҗ‘дәӢ件添еҠ Kafkaе…ғж•°жҚ®пјҢжҜ”еҰӮдё»йўҳгҖҒж¶ҲжҒҜеӨ§е°Ҹзҡ„йҖүйЎ№пјҢиҝҷе°Ҷеҗ‘logstashдәӢ件дёӯж·»еҠ дёҖдёӘеҗҚдёәkafkaзҡ„еӯ—ж®ө auto_offset_reset => "latest" # иҮӘеҠЁйҮҚзҪ®еҒҸ移йҮҸеҲ°жңҖж–°зҡ„еҒҸ移йҮҸ group_id => "logstash-node" # ж¶Ҳиҙ№з»„IDпјҢеӨҡдёӘжңүзӣёеҗҢgroup_idзҡ„logstashе®һдҫӢдёәдёҖдёӘж¶Ҳиҙ№з»„ client_id => "logstash2" # е®ўжҲ·з«ҜID fetch_max_wait_ms => "1000" # жҢҮеҪ“жІЎжңүи¶іеӨҹзҡ„ж•°жҚ®з«ӢеҚіж»Ўи¶іfetch_min_bytesж—¶пјҢжңҚеҠЎеҷЁеңЁеӣһзӯ”fetchиҜ·жұӮд№ӢеүҚе°Ҷйҳ»еЎһзҡ„жңҖй•ҝж—¶й—ҙ } } $ vim config/02-output.conf output { # иҫ“еҮә组件 elasticsearch { # Logstashиҫ“еҮәеҲ°es hosts => ["172.20.166.25:9200", "172.20.166.24:9200", "172.20.166.22:9200", "172.20.166.23:9200", "172.20.166.26:9200"] index => "%{[fields][source]}-%{+YYYY-MM-dd}" # зӣҙжҺҘеңЁж—Ҙеҝ—дёӯеҢ№й…ҚпјҢзҙўеј•дјҡеҺ»жҺүelk # index => "%{[@metadata][topic]}-%{+YYYY-MM-dd}" # д»Ҙж—Ҙжңҹе»әзҙўеј• user => "elastic" password => "elastic123" } #stdout { # codec => rubydebug #} } $ vim config/03-filter.conf filter { # еҪ“йқһдёҡеҠЎеӯ—ж®өж—¶пјҢж— traceIdеҲҷ移йҷӨ if ([message] =~ "traceId=null") { # иҝҮж»Ө组件пјҢиҝҷйҮҢеҸӘжҳҜеұ•зӨәпјҢж— е®һйҷ…ж„Ҹд№үпјҢж №жҚ®иҮӘе·ұзҡ„дёҡеҠЎйңҖжұӮиҝӣиЎҢиҝҮж»Ө drop {} } } # жӢ·иҙқй…ҚзҪ®еҲ° logstash3 logstash4 жңәеҷЁдёҠ $ rsync -avp -e ssh /data/ELKStack/logstash 172.20.166.28:/data/ELKStack/ $ rsync -avp -e ssh /data/ELKStack/logstash 172.20.166.29:/data/ELKStack/ # еҗҜеҠЁ logstash $ docker-compose up -dlogstash3 ж“ҚдҪң
$ cd /data/ELKStack/logstash $ sed -i 's/logstash2/logstash3/g' docker-compose.yml $ sed -i 's/logstash2/logstash3/g' config/01-input.conf # еҗҜеҠЁ logstash $ docker-compose up -d
logstash4 ж“ҚдҪң
$ cd /data/ELKStack/logstash $ sed -i 's/logstash2/logstash4/g' docker-compose.yml $ sed -i 's/logstash2/logstash4/g' config/01-input.conf # еҗҜеҠЁ logstash $ docker-compose up -d
еҚҒгҖҒйғЁзҪІ filebeat
# й…ҚзҪ® filebeat yumжәҗпјҢиҝҷйҮҢд»Ҙ centos7 дёәдҫӢ $ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch $ vim /etc/yum.repos.d/elastic.repo [elastic-7.x] name=Elastic repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md $ yum install -y filebeat-7.10.1 $ systemctl enable filebeat # й…ҚзҪ® $ cd /etc/filebeat/ $ cp -a filebeat.yml filebeat.yml.old $ echo > filebeat.yml # д»Ҙ收йӣҶnginxи®ҝй—®ж—Ҙеҝ—дёәдҫӢ $ vim filebeat.yml filebeat.inputs: # inputsдёәеӨҚж•°пјҢиЎЁеҗҚtypeеҸҜд»ҘжңүеӨҡдёӘ - type: log # иҫ“е…Ҙзұ»еһӢ access: enabled: true # еҗҜз”ЁиҝҷдёӘtypeй…ҚзҪ® json.keys_under_root: true # й»ҳи®ӨиҝҷдёӘеҖјжҳҜFALSEзҡ„пјҢд№ҹе°ұжҳҜжҲ‘们зҡ„jsonж—Ҙеҝ—и§ЈжһҗеҗҺдјҡиў«ж”ҫеңЁjsonй”®дёҠгҖӮи®ҫдёәTRUEпјҢжүҖжңүзҡ„keysе°ұдјҡиў«ж”ҫеҲ°ж №иҠӮзӮ№ json.overwrite_keys: true # жҳҜеҗҰиҰҒиҰҶзӣ–еҺҹжңүзҡ„keyпјҢиҝҷжҳҜе…ій”®й…ҚзҪ®пјҢе°Ҷkeys_under_rootи®ҫдёәTRUEеҗҺпјҢеҶҚе°Ҷoverwrite_keysд№ҹи®ҫдёәTRUEпјҢе°ұиғҪжҠҠfilebeatй»ҳи®Өзҡ„keyеҖјз»ҷиҰҶзӣ– max_bytes: 20480 # еҚ•жқЎж—Ҙеҝ—зҡ„еӨ§е°ҸйҷҗеҲ¶,е»әи®®йҷҗеҲ¶(й»ҳи®Өдёә10M,queue.mem.events * max_bytes е°ҶжҳҜеҚ жңүеҶ…еӯҳзҡ„дёҖйғЁеҲҶ) paths: - /var/log/nginx/access.log # зӣ‘жҺ§nginx зҡ„accessж—Ҙеҝ— fields: # йўқеӨ–зҡ„еӯ—ж®ө source: nginx-access-prod # иҮӘе®ҡд№үsourceеӯ—ж®өпјҢз”ЁдәҺesе»әи®®зҙўеј•пјҲеӯ—ж®өеҗҚе°ҸеҶҷпјҢжҲ‘и®°еҫ—еӨ§еҶҷеҘҪеғҸдёҚиЎҢпјү # иҮӘе®ҡд№үesзҡ„зҙўеј•йңҖиҰҒжҠҠilmи®ҫзҪ®дёәfalse setup.ilm.enabled: false output.kafka: # иҫ“еҮәеҲ°kafka enabled: true # иҜҘoutputй…ҚзҪ®жҳҜеҗҰеҗҜз”Ё hosts: ["172.20.166.27:9092", "172.20.166.28:9092", "172.20.166.29:9092"] # kafkaиҠӮзӮ№еҲ—иЎЁ topic: "elk-%{[fields.source]}" # kafkaдјҡеҲӣе»әиҜҘtopicпјҢ然еҗҺlogstash(еҸҜд»ҘиҝҮж»Өдҝ®ж”№)дјҡдј з»ҷesдҪңдёәзҙўеј•еҗҚз§° partition.hash: reachable_only: true # жҳҜеҗҰеҸӘеҸ‘еҫҖеҸҜиҫҫеҲҶеҢә compression: gzip # еҺӢзј© max_message_bytes: 1000000 # EventжңҖеӨ§еӯ—иҠӮж•°гҖӮй»ҳи®Ө1000000гҖӮеә”е°ҸдәҺзӯүдәҺkafka broker message.max.bytesеҖј required_acks: 1 # kafka ackзӯүзә§ worker: 1 # kafka outputзҡ„жңҖеӨ§е№¶еҸ‘ж•° bulk_max_size: 2048 # еҚ•ж¬ЎеҸ‘еҫҖkafkaзҡ„жңҖеӨ§дәӢ件数 logging.to_files: true # иҫ“еҮәжүҖжңүж—Ҙеҝ—еҲ°fileпјҢй»ҳи®ӨtrueпјҢ иҫҫеҲ°ж—Ҙеҝ—ж–Ү件еӨ§е°ҸйҷҗеҲ¶ж—¶пјҢж—Ҙеҝ—ж–Ү件дјҡиҮӘеҠЁйҷҗеҲ¶жӣҝжҚўпјҢиҜҰз»Ҷй…ҚзҪ®пјҡhttps://www.cnblogs.com/qinwengang/p/10982424.html close_older: 30m # еҰӮжһңдёҖдёӘж–Ү件еңЁжҹҗдёӘж—¶й—ҙж®өеҶ…жІЎжңүеҸ‘з”ҹиҝҮжӣҙж–°пјҢеҲҷе…ій—ӯзӣ‘жҺ§зҡ„ж–Ү件handleгҖӮй»ҳи®Ө1h force_close_files: false # иҝҷдёӘйҖүйЎ№е…ій—ӯдёҖдёӘж–Ү件,еҪ“ж–Ү件еҗҚз§°зҡ„еҸҳеҢ–гҖӮеҸӘеңЁwindowе»әи®®дёәtrue # жІЎжңүж–°ж—Ҙеҝ—йҮҮйӣҶеҗҺеӨҡй•ҝж—¶й—ҙе…ій—ӯж–Ү件еҸҘжҹ„пјҢй»ҳи®Ө5еҲҶй’ҹпјҢи®ҫзҪ®жҲҗ1еҲҶй’ҹпјҢеҠ еҝ«ж–Ү件еҸҘжҹ„е…ій—ӯ close_inactive: 1m # дј иҫ“дәҶ3hеҗҺиҚҸжІЎжңүдј иҫ“е®ҢжҲҗзҡ„иҜқе°ұејәиЎҢе…ій—ӯж–Ү件еҸҘжҹ„пјҢиҝҷдёӘй…ҚзҪ®йЎ№жҳҜи§ЈеҶід»ҘдёҠжЎҲдҫӢй—®йўҳзҡ„key point close_timeout: 3h # иҝҷдёӘй…ҚзҪ®йЎ№д№ҹеә”иҜҘй…ҚзҪ®дёҠпјҢй»ҳи®ӨеҖјжҳҜ0иЎЁзӨәдёҚжё…зҗҶпјҢдёҚжё…зҗҶзҡ„ж„ҸжҖқжҳҜйҮҮйӣҶиҝҮзҡ„ж–Ү件жҸҸиҝ°еңЁregistryж–Ү件йҮҢж°ёдёҚжё…зҗҶпјҢеңЁиҝҗиЎҢдёҖж®өж—¶й—ҙеҗҺпјҢregistryдјҡеҸҳеӨ§пјҢеҸҜиғҪдјҡеёҰжқҘй—®йўҳ clean_inactive: 72h # и®ҫзҪ®дәҶclean_inactiveеҗҺе°ұйңҖиҰҒи®ҫзҪ®ignore_olderпјҢдё”иҰҒдҝқиҜҒignore_older < clean_inactive ignore_older: 70h # йҷҗеҲ¶ CPUе’ҢеҶ…еӯҳиө„жәҗ max_procs: 1 # йҷҗеҲ¶дёҖдёӘCPUж ёеҝғ,йҒҝе…ҚиҝҮеӨҡжҠўеҚ дёҡеҠЎиө„жәҗ queue.mem.events: 256 # еӯҳеӮЁдәҺеҶ…еӯҳйҳҹеҲ—зҡ„дәӢ件数пјҢжҺ’йҳҹеҸ‘йҖҒ (й»ҳи®Ө4096) queue.mem.flush.min_events: 128 # е°ҸдәҺ queue.mem.events ,еўһеҠ жӯӨеҖјеҸҜжҸҗй«ҳеҗһеҗҗйҮҸ (й»ҳи®ӨеҖј2048) # еҗҜеҠЁ filebeat $ systemctl start filebeatеҚҒдёҖгҖҒйғЁзҪІ curatorпјҢе®ҡж—¶жё…зҗҶesзҙўеј•
logstash4 жңәеҷЁж“ҚдҪң
# еҸӮиҖғй“ҫжҺҘпјҡhttps://www.elastic.co/guide/en/elasticsearch/client/curator/current/yum-repository.html # е®үиЈ… curator жңҚеҠЎпјҢд»Ҙ centos7 дёәдҫӢ $ rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch $ vim /etc/yum.repos.d/elk-curator-5.repo [curator-5] name=CentOS/RHEL 7 repository for Elasticsearch Curator 5.x packages baseurl=https://packages.elastic.co/curator/5/centos/7 gpgcheck=1 gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch enabled=1 $ yum install elasticsearch-curator -y # еҲӣе»ә curator й…ҚзҪ®ж–Ү件зӣ®еҪ•дёҺиҫ“еҮәж—Ҙеҝ—зӣ®еҪ• $ mkdir -p /data/ELKStack/curator/logs $ cd /data/ELKStack/curator $ vim config.yml --- # Remember, leave a key empty if there is no value. None will be a string, # # not a Python "NoneType" client: hosts: ["172.20.166.25", "172.20.166.24", "172.20.166.22", "172.20.166.23", "172.20.166.26"] port: 9200 url_prefix: use_ssl: False certificate: client_cert: client_key: ssl_no_validate: False http_auth: elastic:elastic123 timeout: 150 master_only: False logging: loglevel: INFO logfile: /data/ELKStack/curator/logs/curator.log logformat: default blacklist: ['elasticsearch', 'urllib3'] $ vim action.yml --- # Remember, leave a key empty if there is no value. None will be a string, # not a Python "NoneType" # # Also remember that all examples have 'disable_action' set to True. If you # want to use this action as a template, be sure to set this to False after # copying it. actions: 1: action: delete_indices description: >- Delete indices older than 30 days. Ignore the error if the filter does not result in an actionable list of indices (ignore_empty_list) and exit cleanly. options: ignore_empty_list: True disable_action: False filters: - filtertype: pattern kind: regex value: '^((?!(kibana|json|monitoring|metadata|apm|async|transform|siem|security)).)*$' - filtertype: age source: creation_date direction: older #timestring: '%Yi-%m-%d' unit: days unit_count: 30 2: action: delete_indices description: >- Delete indices older than 15 days. Ignore the error if the filter does not result in an actionable list of indices (ignore_empty_list) and exit cleanly. options: ignore_empty_list: True disable_action: False filters: - filtertype: pattern kind: regex value: '^(nginx-).*$' - filtertype: age source: creation_date direction: older #timestring: '%Yi-%m-%d' unit: days unit_count: 15 # и®ҫзҪ®е®ҡж—¶д»»еҠЎжё…зҗҶesзҙўеј• $ crontab -e 0 0 * * * /usr/bin/curator --config /data/ELKStack/curator/config.yml /data/ELKStack/curator/action.yml
еҲ°жӯӨпјҢе…ідәҺвҖңеҰӮдҪ•зҗҶи§Је®№еҷЁйғЁзҪІELK7.10вҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





