Unix/LinuxжҺҘеҸЈе®һдҫӢеҲҶжһҗ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңUnix/LinuxжҺҘеҸЈе®һдҫӢеҲҶжһҗвҖқзҡ„зӣёе…ізҹҘиҜҶпјҢе°Ҹзј–йҖҡиҝҮе®һйҷ…жЎҲдҫӢеҗ‘еӨ§е®¶еұ•зӨәж“ҚдҪңиҝҮзЁӢпјҢж“ҚдҪңж–№жі•з®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәпјҢеёҢжңӣиҝҷзҜҮвҖңUnix/LinuxжҺҘеҸЈе®һдҫӢеҲҶжһҗвҖқж–Үз« иғҪеё®еҠ©еӨ§е®¶и§ЈеҶій—®йўҳгҖӮ
йҳ»еЎһеһӢзҡ„зҪ‘з»ңзј–зЁӢжҺҘеҸЈ
еҮ д№ҺжүҖжңүзҡ„зЁӢеәҸе‘ҳ***ж¬ЎжҺҘи§ҰеҲ°зҡ„зҪ‘з»ңзј–зЁӢйғҪжҳҜд»Һ listen()гҖҒsend()гҖҒrecv()зӯүжҺҘеҸЈејҖе§Ӣзҡ„гҖӮдҪҝз”ЁиҝҷдәӣжҺҘеҸЈеҸҜд»ҘеҫҲж–№дҫҝзҡ„жһ„е»әжңҚеҠЎеҷЁ /е®ўжҲ·жңәзҡ„жЁЎеһӢгҖӮ
жҲ‘们еҒҮи®ҫеёҢжңӣе»әз«ӢдёҖдёӘз®ҖеҚ•зҡ„жңҚеҠЎеҷЁзЁӢеәҸпјҢе®һзҺ°еҗ‘еҚ•дёӘе®ўжҲ·жңәжҸҗдҫӣзұ»дјјдәҺвҖңдёҖй—®дёҖзӯ”вҖқзҡ„еҶ…е®№жңҚеҠЎгҖӮ
еӣҫ 1. з®ҖеҚ•зҡ„дёҖй—®дёҖзӯ”зҡ„жңҚеҠЎеҷЁ /е®ўжҲ·жңәжЁЎеһӢ
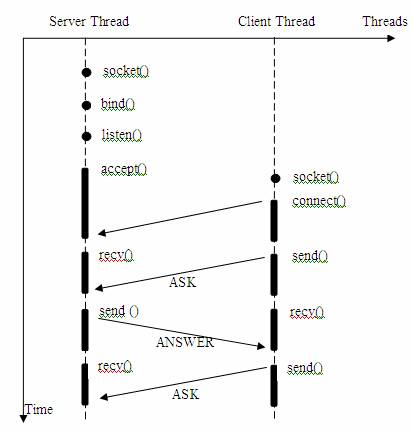
жҲ‘们注ж„ҸеҲ°пјҢеӨ§йғЁеҲҶзҡ„ socketжҺҘеҸЈйғҪжҳҜйҳ»еЎһеһӢзҡ„гҖӮжүҖи°“йҳ»еЎһеһӢжҺҘеҸЈжҳҜжҢҮзі»з»ҹи°ғз”ЁпјҲдёҖиҲ¬жҳҜ IOжҺҘеҸЈпјүдёҚиҝ”еӣһи°ғз”Ёз»“жһң并让еҪ“еүҚзәҝзЁӢдёҖзӣҙйҳ»еЎһпјҢеҸӘжңүеҪ“иҜҘзі»з»ҹи°ғз”ЁиҺ·еҫ—з»“жһңжҲ–иҖ…и¶…ж—¶еҮәй”ҷж—¶жүҚиҝ”еӣһгҖӮ
е®һйҷ…дёҠпјҢйҷӨйқһзү№еҲ«жҢҮе®ҡпјҢеҮ д№ҺжүҖжңүзҡ„ IOжҺҘеҸЈ (еҢ…жӢ¬ socket жҺҘеҸЈ )йғҪжҳҜйҳ»еЎһеһӢзҡ„гҖӮиҝҷз»ҷзҪ‘з»ңзј–зЁӢеёҰжқҘдәҶдёҖдёӘеҫҲеӨ§зҡ„й—®йўҳпјҢеҰӮеңЁи°ғз”Ё send()зҡ„еҗҢж—¶пјҢзәҝзЁӢе°Ҷиў«йҳ»еЎһпјҢеңЁжӯӨжңҹй—ҙпјҢзәҝзЁӢе°Ҷж— жі•жү§иЎҢд»»дҪ•иҝҗз®—жҲ–е“Қеә”д»»дҪ•зҡ„зҪ‘з»ңиҜ·жұӮгҖӮиҝҷз»ҷеӨҡе®ўжҲ·жңәгҖҒеӨҡдёҡеҠЎйҖ»иҫ‘зҡ„зҪ‘з»ңзј–зЁӢеёҰжқҘдәҶжҢ‘жҲҳгҖӮиҝҷж—¶пјҢеҫҲеӨҡзЁӢеәҸе‘ҳеҸҜиғҪдјҡйҖүжӢ©еӨҡзәҝзЁӢзҡ„ж–№ејҸжқҘи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
еӨҡзәҝзЁӢжңҚеҠЎеҷЁзЁӢеәҸ
еә”еҜ№еӨҡе®ўжҲ·жңәзҡ„зҪ‘з»ңеә”з”ЁпјҢжңҖз®ҖеҚ•зҡ„и§ЈеҶіж–№ејҸжҳҜеңЁжңҚеҠЎеҷЁз«ҜдҪҝз”ЁеӨҡзәҝзЁӢпјҲжҲ–еӨҡиҝӣзЁӢпјүгҖӮеӨҡзәҝзЁӢпјҲжҲ–еӨҡиҝӣзЁӢпјүзҡ„зӣ®зҡ„жҳҜи®©жҜҸдёӘиҝһжҺҘйғҪжӢҘжңүзӢ¬з«Ӣзҡ„зәҝзЁӢпјҲжҲ–иҝӣзЁӢпјүпјҢиҝҷж ·д»»дҪ•дёҖдёӘиҝһжҺҘзҡ„йҳ»еЎһйғҪдёҚдјҡеҪұе“Қе…¶д»–зҡ„иҝһжҺҘгҖӮ
е…·дҪ“дҪҝз”ЁеӨҡиҝӣзЁӢиҝҳжҳҜеӨҡзәҝзЁӢпјҢ并没жңүдёҖдёӘзү№е®ҡзҡ„жЁЎејҸгҖӮдј з»ҹж„Ҹд№үдёҠпјҢиҝӣзЁӢзҡ„ејҖй”ҖиҰҒиҝңиҝңеӨ§дәҺзәҝзЁӢпјҢжүҖд»ҘпјҢеҰӮжһңйңҖиҰҒеҗҢж—¶дёәиҫғеӨҡзҡ„е®ўжҲ·жңәжҸҗдҫӣжңҚеҠЎпјҢеҲҷдёҚжҺЁиҚҗдҪҝз”ЁеӨҡиҝӣзЁӢпјӣеҰӮжһңеҚ•дёӘжңҚеҠЎжү§иЎҢдҪ“йңҖиҰҒж¶ҲиҖ—иҫғеӨҡзҡ„ CPU иө„жәҗпјҢиӯ¬еҰӮйңҖиҰҒиҝӣиЎҢеӨ§и§„жЁЎжҲ–й•ҝж—¶й—ҙзҡ„ж•°жҚ®иҝҗз®—жҲ–ж–Ү件и®ҝй—®пјҢеҲҷиҝӣзЁӢиҫғдёәе®үе…ЁгҖӮйҖҡеёёпјҢдҪҝз”Ё pthread_create () еҲӣе»әж–°зәҝзЁӢпјҢfork() еҲӣе»әж–°иҝӣзЁӢгҖӮ
жҲ‘们еҒҮи®ҫеҜ№дёҠиҝ°зҡ„жңҚеҠЎеҷЁ / е®ўжҲ·жңәжЁЎеһӢпјҢжҸҗеҮәжӣҙй«ҳзҡ„иҰҒжұӮпјҢеҚіи®©жңҚеҠЎеҷЁеҗҢж—¶дёәеӨҡдёӘе®ўжҲ·жңәжҸҗдҫӣдёҖй—®дёҖзӯ”зҡ„жңҚеҠЎгҖӮдәҺжҳҜжңүдәҶеҰӮдёӢзҡ„жЁЎеһӢгҖӮ
еӣҫ 2. еӨҡзәҝзЁӢжңҚеҠЎеҷЁжЁЎеһӢ
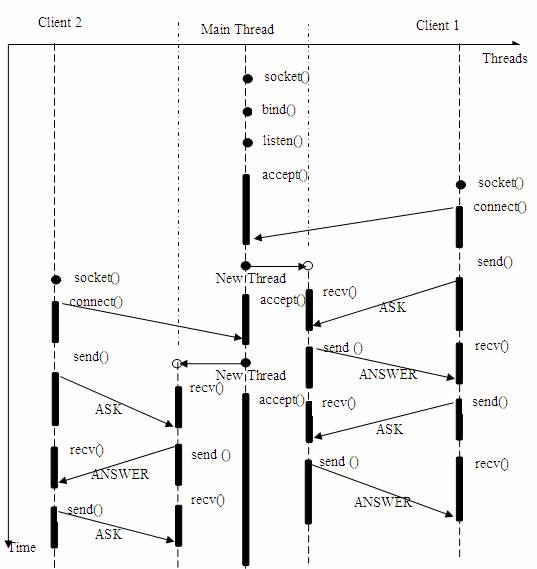
еңЁдёҠиҝ°зҡ„зәҝзЁӢ / ж—¶й—ҙеӣҫдҫӢдёӯпјҢдё»зәҝзЁӢжҢҒз»ӯзӯүеҫ…е®ўжҲ·з«Ҝзҡ„иҝһжҺҘиҜ·жұӮпјҢеҰӮжһңжңүиҝһжҺҘпјҢеҲҷеҲӣе»әж–°зәҝзЁӢпјҢ并еңЁж–°зәҝзЁӢдёӯжҸҗдҫӣдёәеүҚдҫӢеҗҢж ·зҡ„й—®зӯ”жңҚеҠЎгҖӮ
еҫҲеӨҡеҲқеӯҰиҖ…еҸҜиғҪдёҚжҳҺзҷҪдёәдҪ•дёҖдёӘ socket еҸҜд»Ҙ accept еӨҡж¬ЎгҖӮе®һйҷ…дёҠпјҢsocket зҡ„и®ҫи®ЎиҖ…еҸҜиғҪзү№ж„ҸдёәеӨҡе®ўжҲ·жңәзҡ„жғ…еҶөз•ҷдёӢдәҶдјҸ笔пјҢи®© accept() иғҪеӨҹиҝ”еӣһдёҖдёӘж–°зҡ„ socketгҖӮдёӢйқўжҳҜ accept жҺҘеҸЈзҡ„еҺҹеһӢпјҡ
int accept(int s, struct sockaddr *addr, socklen_t *addrlen);
иҫ“е…ҘеҸӮж•° s жҳҜд»Һ socket()пјҢbind() е’Ң listen() дёӯжІҝз”ЁдёӢжқҘзҡ„ socket еҸҘжҹ„еҖјгҖӮжү§иЎҢе®Ң bind() е’Ң listen() еҗҺпјҢж“ҚдҪңзі»з»ҹе·Із»ҸејҖе§ӢеңЁжҢҮе®ҡзҡ„з«ҜеҸЈеӨ„зӣ‘еҗ¬жүҖжңүзҡ„иҝһжҺҘиҜ·жұӮпјҢеҰӮжһңжңүиҜ·жұӮпјҢеҲҷе°ҶиҜҘиҝһжҺҘиҜ·жұӮеҠ е…ҘиҜ·жұӮйҳҹеҲ—гҖӮи°ғз”Ё accept() жҺҘеҸЈжӯЈжҳҜд»Һ socket s зҡ„иҜ·жұӮйҳҹеҲ—жҠҪеҸ–***дёӘиҝһжҺҘдҝЎжҒҜпјҢеҲӣе»әдёҖдёӘдёҺ s еҗҢзұ»зҡ„ж–°зҡ„ socket иҝ”еӣһеҸҘжҹ„гҖӮж–°зҡ„ socket еҸҘжҹ„еҚіжҳҜеҗҺз»ӯ read() е’Ң recv() зҡ„иҫ“е…ҘеҸӮж•°гҖӮеҰӮжһңиҜ·жұӮйҳҹеҲ—еҪ“еүҚжІЎжңүиҜ·жұӮпјҢеҲҷ accept() е°Ҷиҝӣе…Ҙйҳ»еЎһзҠ¶жҖҒзӣҙеҲ°жңүиҜ·жұӮиҝӣе…ҘйҳҹеҲ—гҖӮ
дёҠиҝ°еӨҡзәҝзЁӢзҡ„жңҚеҠЎеҷЁжЁЎеһӢдјјд№Һ***зҡ„и§ЈеҶідәҶдёәеӨҡдёӘе®ўжҲ·жңәжҸҗдҫӣй—®зӯ”жңҚеҠЎзҡ„иҰҒжұӮпјҢдҪҶе…¶е®һ并дёҚе°Ҫ然гҖӮеҰӮжһңиҰҒеҗҢж—¶е“Қеә”жҲҗзҷҫдёҠеҚғи·Ҝзҡ„иҝһжҺҘиҜ·жұӮпјҢеҲҷж— и®әеӨҡзәҝзЁӢиҝҳжҳҜеӨҡиҝӣзЁӢйғҪдјҡдёҘйҮҚеҚ жҚ®зі»з»ҹиө„жәҗпјҢйҷҚдҪҺзі»з»ҹеҜ№еӨ–з•Ңе“Қеә”ж•ҲзҺҮпјҢиҖҢзәҝзЁӢдёҺиҝӣзЁӢжң¬иә«д№ҹжӣҙе®№жҳ“иҝӣе…ҘеҒҮжӯ»зҠ¶жҖҒгҖӮ
еҫҲеӨҡзЁӢеәҸе‘ҳеҸҜиғҪдјҡиҖғиҷ‘дҪҝз”ЁвҖңзәҝзЁӢжұ вҖқжҲ–вҖңиҝһжҺҘжұ вҖқгҖӮвҖңзәҝзЁӢжұ вҖқж—ЁеңЁеҮҸе°‘еҲӣе»әе’Ңй”ҖжҜҒзәҝзЁӢзҡ„йў‘зҺҮпјҢе…¶з»ҙжҢҒдёҖе®ҡеҗҲзҗҶж•°йҮҸзҡ„зәҝзЁӢпјҢ并让з©әй—Ізҡ„зәҝзЁӢйҮҚж–°жүҝжӢ…ж–°зҡ„жү§иЎҢд»»еҠЎгҖӮвҖңиҝһжҺҘжұ вҖқз»ҙжҢҒиҝһжҺҘзҡ„зј“еӯҳжұ пјҢе°ҪйҮҸйҮҚз”Ёе·Іжңүзҡ„иҝһжҺҘгҖҒеҮҸе°‘еҲӣе»әе’Ңе…ій—ӯиҝһжҺҘзҡ„йў‘зҺҮгҖӮиҝҷдёӨз§ҚжҠҖжңҜйғҪеҸҜд»ҘеҫҲеҘҪзҡ„йҷҚдҪҺзі»з»ҹејҖй”ҖпјҢйғҪиў«е№ҝжіӣеә”з”ЁеҫҲеӨҡеӨ§еһӢзі»з»ҹпјҢеҰӮ websphereгҖҒtomcat е’Ңеҗ„з§Қж•°жҚ®еә“зӯүгҖӮ
дҪҶжҳҜпјҢвҖңзәҝзЁӢжұ вҖқе’ҢвҖңиҝһжҺҘжұ вҖқжҠҖжңҜд№ҹеҸӘжҳҜеңЁдёҖе®ҡзЁӢеәҰдёҠзј“и§ЈдәҶйў‘з№Ғи°ғз”Ё IO жҺҘеҸЈеёҰжқҘзҡ„иө„жәҗеҚ з”ЁгҖӮиҖҢдё”пјҢжүҖи°“вҖңжұ вҖқе§Ӣз»Ҳжңүе…¶дёҠйҷҗпјҢеҪ“иҜ·жұӮеӨ§еӨ§и¶…иҝҮдёҠйҷҗж—¶пјҢвҖңжұ вҖқжһ„жҲҗзҡ„зі»з»ҹеҜ№еӨ–з•Ңзҡ„е“Қеә”并дёҚжҜ”жІЎжңүжұ зҡ„ж—¶еҖҷж•ҲжһңеҘҪеӨҡе°‘гҖӮжүҖд»ҘдҪҝз”ЁвҖңжұ вҖқ еҝ…йЎ»иҖғиҷ‘е…¶йқўдёҙзҡ„е“Қеә”规模пјҢе№¶ж №жҚ®е“Қеә”规模и°ғж•ҙвҖңжұ вҖқзҡ„еӨ§е°ҸгҖӮ
еҜ№еә”дёҠдҫӢдёӯзҡ„жүҖйқўдёҙзҡ„еҸҜиғҪеҗҢж—¶еҮәзҺ°зҡ„дёҠеҚғз”ҡиҮідёҠдёҮж¬Ўзҡ„е®ўжҲ·з«ҜиҜ·жұӮпјҢвҖңзәҝзЁӢжұ вҖқжҲ–вҖңиҝһжҺҘжұ вҖқжҲ–и®ёеҸҜд»Ҙзј“и§ЈйғЁеҲҶеҺӢеҠӣпјҢдҪҶжҳҜдёҚиғҪи§ЈеҶіжүҖжңүй—®йўҳгҖӮ
жҖ»д№ӢпјҢеӨҡзәҝзЁӢжЁЎеһӢеҸҜд»Ҙж–№дҫҝй«ҳж•Ҳзҡ„и§ЈеҶіе°Ҹ规模зҡ„жңҚеҠЎиҜ·жұӮпјҢдҪҶйқўеҜ№еӨ§и§„жЁЎзҡ„жңҚеҠЎиҜ·жұӮпјҢеӨҡзәҝзЁӢжЁЎеһӢ并дёҚжҳҜ***ж–№жЎҲгҖӮдёӢдёҖз« жҲ‘们е°Ҷи®Ёи®әз”Ёйқһйҳ»еЎһжҺҘеҸЈжқҘе°қиҜ•и§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
дҪҝз”Ёselect()жҺҘеҸЈзҡ„еҹәдәҺдәӢ件й©ұеҠЁзҡ„жңҚеҠЎеҷЁжЁЎеһӢ
еӨ§йғЁеҲҶ Unix/Linux йғҪж”ҜжҢҒ select еҮҪж•°пјҢиҜҘеҮҪж•°з”ЁдәҺжҺўжөӢеӨҡдёӘж–Ү件еҸҘжҹ„зҡ„зҠ¶жҖҒеҸҳеҢ–гҖӮдёӢйқўз»ҷеҮә select жҺҘеҸЈзҡ„еҺҹеһӢпјҡ
FD_ZERO(int fd, fd_set* fds) FD_SET(int fd, fd_set* fds) FD_ISSET(int fd, fd_set* fds) FD_CLR(int fd, fd_set* fds) int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout)
иҝҷйҮҢпјҢfd_set зұ»еһӢеҸҜд»Ҙз®ҖеҚ•зҡ„зҗҶи§ЈдёәжҢү bit дҪҚж Үи®°еҸҘжҹ„зҡ„йҳҹеҲ—пјҢдҫӢеҰӮиҰҒеңЁжҹҗ fd_set дёӯж Үи®°дёҖдёӘеҖјдёә 16 зҡ„еҸҘжҹ„пјҢеҲҷиҜҘ fd_set зҡ„第 16 дёӘ bit дҪҚиў«ж Үи®°дёә 1гҖӮе…·дҪ“зҡ„зҪ®дҪҚгҖҒйӘҢиҜҒеҸҜдҪҝз”Ё FD_SETгҖҒFD_ISSET зӯүе®Ҹе®һзҺ°гҖӮеңЁ select() еҮҪж•°дёӯпјҢreadfdsгҖҒwritefds е’Ң exceptfds еҗҢж—¶дҪңдёәиҫ“е…ҘеҸӮж•°е’Ңиҫ“еҮәеҸӮж•°гҖӮеҰӮжһңиҫ“е…Ҙзҡ„ readfds ж Үи®°дәҶ 16 еҸ·еҸҘжҹ„пјҢеҲҷ select() е°ҶжЈҖжөӢ 16 еҸ·еҸҘжҹ„жҳҜеҗҰеҸҜиҜ»гҖӮеңЁ select() иҝ”еӣһеҗҺпјҢеҸҜд»ҘйҖҡиҝҮжЈҖжҹҘ readfds жңүеҗҰж Үи®° 16 еҸ·еҸҘжҹ„пјҢжқҘеҲӨж–ӯиҜҘвҖңеҸҜиҜ»вҖқдәӢ件жҳҜеҗҰеҸ‘з”ҹгҖӮеҸҰеӨ–пјҢз”ЁжҲ·еҸҜд»Ҙи®ҫзҪ® timeout ж—¶й—ҙгҖӮ
дёӢйқўе°ҶйҮҚж–°жЁЎжӢҹдёҠдҫӢдёӯд»ҺеӨҡдёӘе®ўжҲ·з«ҜжҺҘ收数жҚ®зҡ„жЁЎеһӢгҖӮ
еӣҫ4.дҪҝз”Ёselect()зҡ„жҺҘ收数жҚ®жЁЎеһӢ
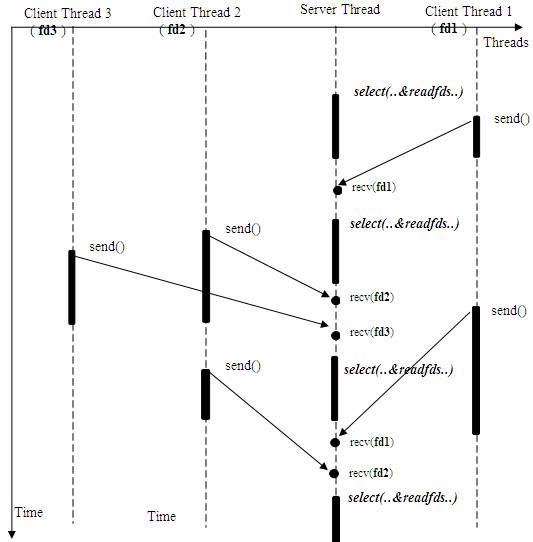
дёҠиҝ°жЁЎеһӢеҸӘжҳҜжҸҸиҝ°дәҶдҪҝз”Ё select() жҺҘеҸЈеҗҢж—¶д»ҺеӨҡдёӘе®ўжҲ·з«ҜжҺҘ收数жҚ®зҡ„иҝҮзЁӢпјӣз”ұдәҺ select() жҺҘеҸЈеҸҜд»ҘеҗҢж—¶еҜ№еӨҡдёӘеҸҘжҹ„иҝӣиЎҢиҜ»зҠ¶жҖҒгҖҒеҶҷзҠ¶жҖҒе’Ңй”ҷиҜҜзҠ¶жҖҒзҡ„жҺўжөӢпјҢжүҖд»ҘеҸҜд»ҘеҫҲе®№жҳ“жһ„е»әдёәеӨҡдёӘе®ўжҲ·з«ҜжҸҗдҫӣзӢ¬з«Ӣй—®зӯ”жңҚеҠЎзҡ„жңҚеҠЎеҷЁзі»з»ҹгҖӮ
еӣҫ5.дҪҝз”Ёselect()жҺҘеҸЈзҡ„еҹәдәҺдәӢ件й©ұеҠЁзҡ„жңҚеҠЎеҷЁжЁЎеһӢ
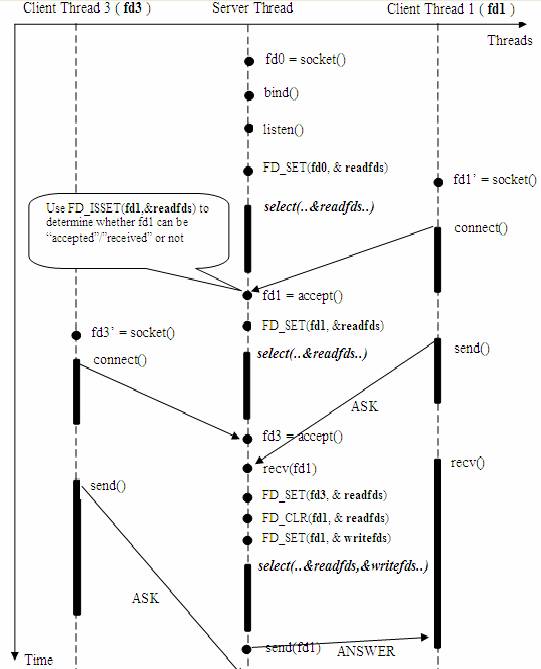
иҝҷйҮҢйңҖиҰҒжҢҮеҮәзҡ„жҳҜпјҢе®ўжҲ·з«Ҝзҡ„дёҖдёӘ connect() ж“ҚдҪңпјҢе°ҶеңЁжңҚеҠЎеҷЁз«ҜжҝҖеҸ‘дёҖдёӘвҖңеҸҜиҜ»дәӢ件вҖқпјҢжүҖд»Ҙ select() д№ҹиғҪжҺўжөӢжқҘиҮӘе®ўжҲ·з«Ҝзҡ„ connect() иЎҢдёәгҖӮ
дёҠиҝ°жЁЎеһӢдёӯпјҢжңҖе…ій”®зҡ„ең°ж–№жҳҜеҰӮдҪ•еҠЁжҖҒз»ҙжҠӨ select() зҡ„дёүдёӘеҸӮж•° readfdsгҖҒwritefds е’Ң exceptfdsгҖӮдҪңдёәиҫ“е…ҘеҸӮж•°пјҢreadfds еә”иҜҘж Үи®°жүҖжңүзҡ„йңҖиҰҒжҺўжөӢзҡ„вҖңеҸҜиҜ»дәӢ件вҖқзҡ„еҸҘжҹ„пјҢе…¶дёӯж°ёиҝңеҢ…жӢ¬йӮЈдёӘжҺўжөӢ connect() зҡ„йӮЈдёӘвҖңжҜҚвҖқеҸҘжҹ„пјӣеҗҢж—¶пјҢwritefds е’Ң exceptfds еә”иҜҘж Үи®°жүҖжңүйңҖиҰҒжҺўжөӢзҡ„вҖңеҸҜеҶҷдәӢ件вҖқе’ҢвҖңй”ҷиҜҜдәӢ件вҖқзҡ„еҸҘжҹ„ ( дҪҝз”Ё FD_SET() ж Үи®° )гҖӮ
дҪңдёәиҫ“еҮәеҸӮж•°пјҢreadfdsгҖҒwritefds е’Ң exceptfds дёӯзҡ„дҝқеӯҳдәҶ select() жҚ•жҚүеҲ°зҡ„жүҖжңүдәӢ件зҡ„еҸҘжҹ„еҖјгҖӮзЁӢеәҸе‘ҳйңҖиҰҒжЈҖжҹҘзҡ„жүҖжңүзҡ„ж Үи®°дҪҚ ( дҪҝз”Ё FD_ISSET() жЈҖжҹҘ )пјҢд»ҘзЎ®е®ҡеҲ°еә•е“ӘдәӣеҸҘжҹ„еҸ‘з”ҹдәҶдәӢ件гҖӮ
дёҠиҝ°жЁЎеһӢдё»иҰҒжЁЎжӢҹзҡ„жҳҜвҖңдёҖй—®дёҖзӯ”вҖқзҡ„жңҚеҠЎжөҒзЁӢпјҢжүҖд»ҘпјҢеҰӮжһң select() еҸ‘зҺ°жҹҗеҸҘжҹ„жҚ•жҚүеҲ°дәҶвҖңеҸҜиҜ»дәӢ件вҖқпјҢжңҚеҠЎеҷЁзЁӢеәҸеә”еҸҠж—¶еҒҡ recv() ж“ҚдҪңпјҢе№¶ж №жҚ®жҺҘ收еҲ°зҡ„ж•°жҚ®еҮҶеӨҮеҘҪеҫ…еҸ‘йҖҒж•°жҚ®пјҢ并е°ҶеҜ№еә”зҡ„еҸҘжҹ„еҖјеҠ е…Ҙ writefdsпјҢеҮҶеӨҮдёӢдёҖж¬Ўзҡ„вҖңеҸҜеҶҷдәӢ件вҖқзҡ„ select() жҺўжөӢгҖӮеҗҢж ·пјҢеҰӮжһң select() еҸ‘зҺ°жҹҗеҸҘжҹ„жҚ•жҚүеҲ°вҖңеҸҜеҶҷдәӢ件вҖқпјҢеҲҷзЁӢеәҸеә”еҸҠж—¶еҒҡ send() ж“ҚдҪңпјҢ并еҮҶеӨҮеҘҪдёӢдёҖж¬Ўзҡ„вҖңеҸҜиҜ»дәӢ件вҖқжҺўжөӢеҮҶеӨҮгҖӮдёӢеӣҫжҸҸиҝ°зҡ„жҳҜдёҠиҝ°жЁЎеһӢдёӯзҡ„дёҖдёӘжү§иЎҢе‘ЁжңҹгҖӮ
еӣҫ6. дёҖдёӘжү§иЎҢе‘Ёжңҹ
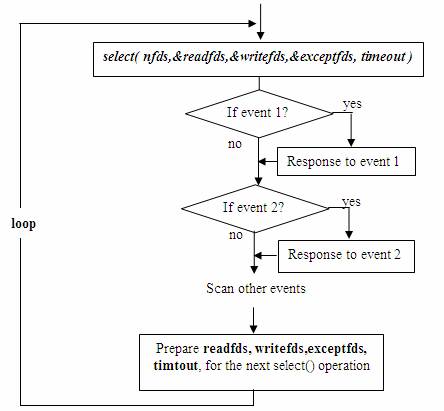
иҝҷз§ҚжЁЎеһӢзҡ„зү№еҫҒеңЁдәҺжҜҸдёҖдёӘжү§иЎҢе‘ЁжңҹйғҪдјҡжҺўжөӢдёҖж¬ЎжҲ–дёҖз»„дәӢ件пјҢдёҖдёӘзү№е®ҡзҡ„дәӢ件дјҡи§ҰеҸ‘жҹҗдёӘзү№е®ҡзҡ„е“Қеә”гҖӮжҲ‘们еҸҜд»Ҙе°Ҷиҝҷз§ҚжЁЎеһӢеҪ’зұ»дёәвҖңдәӢ件й©ұеҠЁжЁЎеһӢвҖқгҖӮ
зӣёжҜ”е…¶д»–жЁЎеһӢпјҢдҪҝз”Ё select() зҡ„дәӢ件й©ұеҠЁжЁЎеһӢеҸӘз”ЁеҚ•зәҝзЁӢпјҲиҝӣзЁӢпјүжү§иЎҢпјҢеҚ з”Ёиө„жәҗе°‘пјҢдёҚж¶ҲиҖ—еӨӘеӨҡ CPUпјҢеҗҢж—¶иғҪеӨҹдёәеӨҡе®ўжҲ·з«ҜжҸҗдҫӣжңҚеҠЎгҖӮеҰӮжһңиҜ•еӣҫе»әз«ӢдёҖдёӘз®ҖеҚ•зҡ„дәӢ件й©ұеҠЁзҡ„жңҚеҠЎеҷЁзЁӢеәҸпјҢиҝҷдёӘжЁЎеһӢжңүдёҖе®ҡзҡ„еҸӮиҖғд»·еҖјгҖӮ
дҪҶиҝҷдёӘжЁЎеһӢдҫқж—§жңүзқҖеҫҲеӨҡй—®йўҳгҖӮ
йҰ–е…ҲпјҢselect() жҺҘеҸЈе№¶дёҚжҳҜе®һзҺ°вҖңдәӢ件й©ұеҠЁвҖқзҡ„***йҖүжӢ©гҖӮеӣ дёәеҪ“йңҖиҰҒжҺўжөӢзҡ„еҸҘжҹ„еҖјиҫғеӨ§ж—¶пјҢselect() жҺҘеҸЈжң¬иә«йңҖиҰҒж¶ҲиҖ—еӨ§йҮҸж—¶й—ҙеҺ»иҪ®иҜўеҗ„дёӘеҸҘжҹ„гҖӮеҫҲеӨҡж“ҚдҪңзі»з»ҹжҸҗдҫӣдәҶжӣҙдёәй«ҳж•Ҳзҡ„жҺҘеҸЈпјҢеҰӮ linux жҸҗдҫӣдәҶ epollпјҢBSD жҸҗдҫӣдәҶ kqueueпјҢSolaris жҸҗдҫӣдәҶ /dev/poll …гҖӮеҰӮжһңйңҖиҰҒе®һзҺ°жӣҙй«ҳж•Ҳзҡ„жңҚеҠЎеҷЁзЁӢеәҸпјҢзұ»дјј epoll иҝҷж ·зҡ„жҺҘеҸЈжӣҙиў«жҺЁиҚҗгҖӮйҒ—жҶҫзҡ„жҳҜдёҚеҗҢзҡ„ж“ҚдҪңзі»з»ҹ***зҡ„ epoll жҺҘеҸЈжңүеҫҲеӨ§е·®ејӮпјҢжүҖд»ҘдҪҝз”Ёзұ»дјјдәҺ epoll зҡ„жҺҘеҸЈе®һзҺ°е…·жңүиҫғеҘҪи·Ёе№іеҸ°иғҪеҠӣзҡ„жңҚеҠЎеҷЁдјҡжҜ”иҫғеӣ°йҡҫгҖӮ
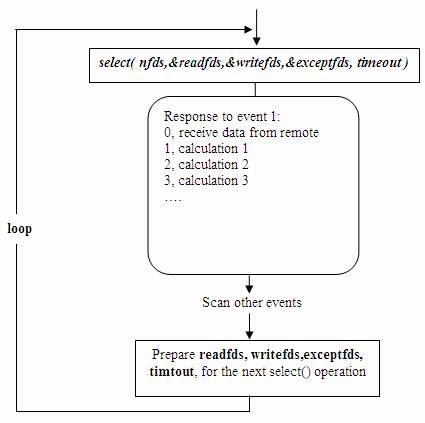
е…¶ж¬ЎпјҢиҜҘжЁЎеһӢе°ҶдәӢ件жҺўжөӢе’ҢдәӢ件е“Қеә”еӨ№жқӮеңЁдёҖиө·пјҢдёҖж—ҰдәӢ件е“Қеә”зҡ„жү§иЎҢдҪ“еәһеӨ§пјҢеҲҷеҜ№ж•ҙдёӘжЁЎеһӢжҳҜзҒҫйҡҫжҖ§зҡ„гҖӮеҰӮдёӢдҫӢпјҢеәһеӨ§зҡ„жү§иЎҢдҪ“ 1 зҡ„е°ҶзӣҙжҺҘеҜјиҮҙе“Қеә”дәӢ件 2 зҡ„жү§иЎҢдҪ“иҝҹиҝҹеҫ—дёҚеҲ°жү§иЎҢпјҢ并еңЁеҫҲеӨ§зЁӢеәҰдёҠйҷҚдҪҺдәҶдәӢ件жҺўжөӢзҡ„еҸҠж—¶жҖ§гҖӮ
еӣҫ7. еәһеӨ§зҡ„жү§иЎҢдҪ“еҜ№дҪҝз”Ёselect()зҡ„дәӢ件й©ұеҠЁжЁЎеһӢзҡ„еҪұе“Қ
е№ёиҝҗзҡ„жҳҜпјҢжңүеҫҲеӨҡй«ҳж•Ҳзҡ„дәӢ件й©ұеҠЁеә“еҸҜд»ҘеұҸи”ҪдёҠиҝ°зҡ„еӣ°йҡҫпјҢеёёи§Ғзҡ„дәӢ件й©ұеҠЁеә“жңү libevent еә“пјҢиҝҳжңүдҪңдёә libevent жӣҝд»ЈиҖ…зҡ„ libev еә“гҖӮиҝҷдәӣеә“дјҡж №жҚ®ж“ҚдҪңзі»з»ҹзҡ„зү№зӮ№йҖүжӢ©жңҖеҗҲйҖӮзҡ„дәӢ件жҺўжөӢжҺҘеҸЈпјҢ并且еҠ е…ҘдәҶдҝЎеҸ· (signal) зӯүжҠҖжңҜд»Ҙж”ҜжҢҒејӮжӯҘе“Қеә”пјҢиҝҷдҪҝеҫ—иҝҷдәӣеә“жҲҗдёәжһ„е»әдәӢ件й©ұеҠЁжЁЎеһӢзҡ„дёҚдәҢйҖүжӢ©гҖӮдёӢз« е°Ҷд»Ӣз»ҚеҰӮдҪ•дҪҝз”Ё libev еә“жӣҝжҚў select жҲ– epoll жҺҘеҸЈпјҢе®һзҺ°й«ҳж•ҲзЁіе®ҡзҡ„жңҚеҠЎеҷЁжЁЎеһӢгҖӮ
дҪҝз”ЁдәӢ件й©ұеҠЁеә“libevзҡ„жңҚеҠЎеҷЁжЁЎеһӢ
Libev жҳҜдёҖз§Қй«ҳжҖ§иғҪдәӢ件еҫӘзҺҜ / дәӢ件й©ұеҠЁеә“гҖӮдҪңдёә libevent зҡ„жӣҝд»ЈдҪңе“ҒпјҢе…¶***дёӘзүҲжң¬еҸ‘еёғдёҺ 2007 е№ҙ 11 жңҲгҖӮLibev зҡ„и®ҫи®ЎиҖ…еЈ°з§° libev жӢҘжңүжӣҙеҝ«зҡ„йҖҹеәҰпјҢжӣҙе°Ҹзҡ„дҪ“з§ҜпјҢжӣҙеӨҡеҠҹиғҪзӯүдјҳеҠҝпјҢиҝҷдәӣдјҳеҠҝеңЁеҫҲеӨҡжөӢиҜ„дёӯеҫ—еҲ°дәҶиҜҒжҳҺгҖӮжӯЈеӣ дёәе…¶иүҜеҘҪзҡ„жҖ§иғҪпјҢеҫҲеӨҡзі»з»ҹејҖе§ӢдҪҝз”Ё libev еә“гҖӮжң¬з« е°Ҷд»Ӣз»ҚеҰӮдҪ•дҪҝз”Ё Libev е®һзҺ°жҸҗдҫӣй—®зӯ”жңҚеҠЎзҡ„жңҚеҠЎеҷЁгҖӮ
пјҲдәӢе®һдёҠпјҢзҺ°еӯҳзҡ„дәӢ件еҫӘзҺҜ / дәӢ件й©ұеҠЁеә“жңүеҫҲеӨҡпјҢдҪңиҖ…д№ҹж— ж„ҸжҺЁиҚҗиҜ»иҖ…дёҖе®ҡдҪҝз”Ё libev еә“пјҢиҖҢеҸӘжҳҜдёәдәҶиҜҙжҳҺдәӢ件й©ұеҠЁжЁЎеһӢз»ҷзҪ‘з»ңжңҚеҠЎеҷЁзј–зЁӢеёҰжқҘзҡ„дҫҝеҲ©е’ҢеҘҪеӨ„гҖӮеӨ§йғЁеҲҶзҡ„дәӢ件й©ұеҠЁеә“йғҪжңүзқҖдёҺ libev еә“зӣёзұ»дјјзҡ„жҺҘеҸЈпјҢеҸӘиҰҒжҳҺзҷҪеӨ§иҮҙзҡ„еҺҹзҗҶпјҢеҚіеҸҜзҒөжҙ»жҢ‘йҖүеҗҲйҖӮзҡ„еә“гҖӮпјү
дёҺеүҚз« зҡ„жЁЎеһӢзұ»дјјпјҢlibev еҗҢж ·йңҖиҰҒеҫӘзҺҜжҺўжөӢдәӢ件жҳҜеҗҰдә§з”ҹгҖӮLibev зҡ„еҫӘзҺҜдҪ“з”Ё ev_loop з»“жһ„жқҘиЎЁиҫҫпјҢ并用 ev_loop( ) жқҘеҗҜеҠЁгҖӮ
void ev_loop( ev_loop* loop, int flags )
Libev ж”ҜжҢҒе…«з§ҚдәӢ件зұ»еһӢпјҢе…¶дёӯеҢ…жӢ¬ IO дәӢ件гҖӮдёҖдёӘ IO дәӢ件用 ev_io жқҘиЎЁеҫҒпјҢ并用 ev_io_init() еҮҪж•°жқҘеҲқе§ӢеҢ–пјҡ
void ev_io_init(ev_io *io, callback, int fd, int events)
еҲқе§ӢеҢ–еҶ…е®№еҢ…жӢ¬еӣһи°ғеҮҪж•° callbackпјҢиў«жҺўжөӢзҡ„еҸҘжҹ„ fd е’ҢйңҖиҰҒжҺўжөӢзҡ„дәӢ件пјҢEV_READ иЎЁвҖңеҸҜиҜ»дәӢ件вҖқпјҢEV_WRITE иЎЁвҖңеҸҜеҶҷдәӢ件вҖқгҖӮ
зҺ°еңЁпјҢз”ЁжҲ·йңҖиҰҒеҒҡзҡ„д»…д»…жҳҜеңЁеҗҲйҖӮзҡ„ж—¶еҖҷпјҢе°Ҷжҹҗдәӣ ev_io д»Һ ev_loop еҠ е…ҘжҲ–еү”йҷӨгҖӮдёҖж—ҰеҠ е…ҘпјҢдёӢдёӘеҫӘзҺҜеҚідјҡжЈҖжҹҘ ev_io жүҖжҢҮе®ҡзҡ„дәӢ件жңүеҗҰеҸ‘з”ҹпјӣеҰӮжһңиҜҘдәӢ件被жҺўжөӢеҲ°пјҢеҲҷ ev_loop дјҡиҮӘеҠЁжү§иЎҢ ev_io зҡ„еӣһи°ғеҮҪж•° callback()пјӣеҰӮжһң ev_io иў«жіЁй”ҖпјҢеҲҷдёҚеҶҚжЈҖжөӢеҜ№еә”дәӢ件гҖӮ
ж— и®әжҹҗ ev_loop еҗҜеҠЁдёҺеҗҰпјҢйғҪеҸҜд»ҘеҜ№е…¶ж·»еҠ жҲ–еҲ йҷӨдёҖдёӘжҲ–еӨҡдёӘ ev_ioпјҢж·»еҠ еҲ йҷӨзҡ„жҺҘеҸЈжҳҜ ev_io_start() е’Ң ev_io_stop()гҖӮ
void ev_io_start( ev_loop *loop, ev_io* io ) void ev_io_stop( EV_A_* )
з”ұжӯӨпјҢжҲ‘们еҸҜд»Ҙе®№жҳ“еҫ—еҮәеҰӮдёӢзҡ„вҖңдёҖй—®дёҖзӯ”вҖқзҡ„жңҚеҠЎеҷЁжЁЎеһӢгҖӮз”ұдәҺжІЎжңүиҖғиҷ‘жңҚеҠЎеҷЁз«Ҝдё»еҠЁз»ҲжӯўиҝһжҺҘжңәеҲ¶пјҢжүҖд»Ҙеҗ„дёӘиҝһжҺҘеҸҜд»Ҙз»ҙжҢҒд»»ж„Ҹж—¶й—ҙпјҢе®ўжҲ·з«ҜеҸҜд»ҘиҮӘз”ұйҖүжӢ©йҖҖеҮәж—¶жңәгҖӮ
еӣҫ8. дҪҝз”Ёlibevеә“зҡ„жңҚеҠЎеҷЁжЁЎеһӢ
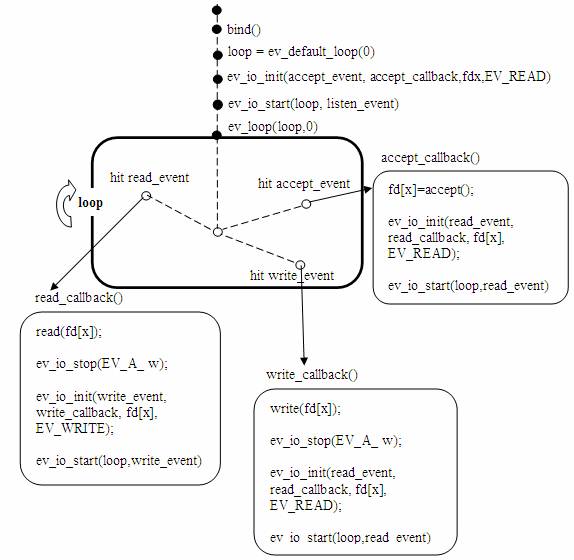
дёҠиҝ°жЁЎеһӢеҸҜд»ҘжҺҘеҸ—д»»ж„ҸеӨҡдёӘиҝһжҺҘпјҢдё”дёәеҗ„дёӘиҝһжҺҘжҸҗдҫӣе®Ңе…ЁзӢ¬з«Ӣзҡ„й—®зӯ”жңҚеҠЎгҖӮеҖҹеҠ© libev жҸҗдҫӣзҡ„дәӢ件еҫӘзҺҜ / дәӢ件й©ұеҠЁжҺҘеҸЈпјҢдёҠиҝ°жЁЎеһӢжңүжңәдјҡе…·еӨҮе…¶д»–жЁЎеһӢдёҚиғҪжҸҗдҫӣзҡ„й«ҳж•ҲзҺҮгҖҒдҪҺиө„жәҗеҚ з”ЁгҖҒзЁіе®ҡжҖ§еҘҪе’Ңзј–еҶҷз®ҖеҚ•зӯүзү№зӮ№гҖӮ
з”ұдәҺдј з»ҹзҡ„ web жңҚеҠЎеҷЁпјҢftp жңҚеҠЎеҷЁеҸҠе…¶д»–зҪ‘з»ңеә”з”ЁзЁӢеәҸйғҪе…·жңүвҖңдёҖй—®дёҖзӯ”вҖқзҡ„йҖҡи®ҜйҖ»иҫ‘пјҢжүҖд»ҘдёҠиҝ°дҪҝз”Ё libev еә“зҡ„вҖңдёҖй—®дёҖзӯ”вҖқжЁЎеһӢеҜ№жһ„е»әзұ»дјјзҡ„жңҚеҠЎеҷЁзЁӢеәҸе…·жңүеҸӮиҖғд»·еҖјпјӣеҸҰеӨ–пјҢеҜ№дәҺйңҖиҰҒе®һзҺ°иҝңзЁӢзӣ‘и§ҶжҲ–иҝңзЁӢйҒҘжҺ§зҡ„еә”з”ЁзЁӢеәҸпјҢдёҠиҝ°жЁЎеһӢеҗҢж ·жҸҗдҫӣдәҶдёҖдёӘеҸҜиЎҢзҡ„е®һзҺ°ж–№жЎҲгҖӮ
е…ідәҺвҖңUnix/LinuxжҺҘеҸЈе®һдҫӢеҲҶжһҗвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶзӮ№гҖӮ





